FLINK重点原理与机制:内存网络流控及反压机制剖析
Posted 秋华
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了FLINK重点原理与机制:内存网络流控及反压机制剖析相关的知识,希望对你有一定的参考价值。
4 Flink Credit-based 反压机制(since V1.5)
4.1. TCP-based 反压的弊端
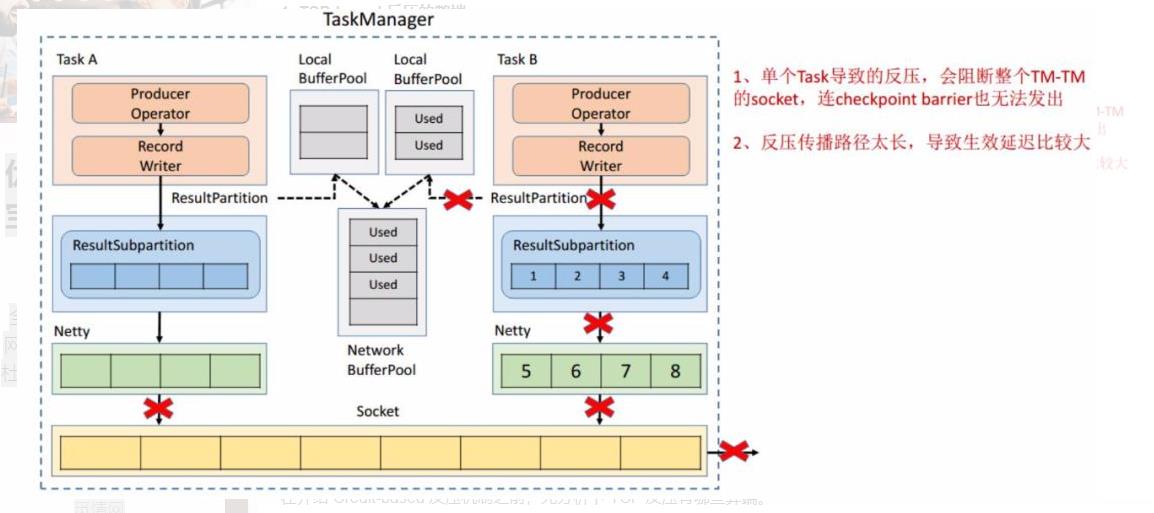
在介绍 Credit-based 反压机制之前,先分析下 TCP 反压有哪些弊端。
-
在一个 TaskManager 中可能要执行多个 Task,如果多个 Task 的数据最终都要传输到下游的同一个 TaskManager 就会复用同一个 Socket 进行传输,这个时候如果单个 Task 产生反压,就会导致复用的 Socket 阻塞,其余的 Task 也无法使用传输,checkpoint barrier 也无法发出导致下游执行 checkpoint 的延迟增大。
-
依赖最底层的 TCP 去做流控,会导致反压传播路径太长,导致生效的延迟比较大。
4.2. 引入 Credit-based 反压
这个机制简单的理解起来就是在 Flink 层面实现类似 TCP 流控的反压机制来解决上述的弊端,Credit 可以类比为 TCP 的 Window 机制。
4.3. Credit-based 反压过程
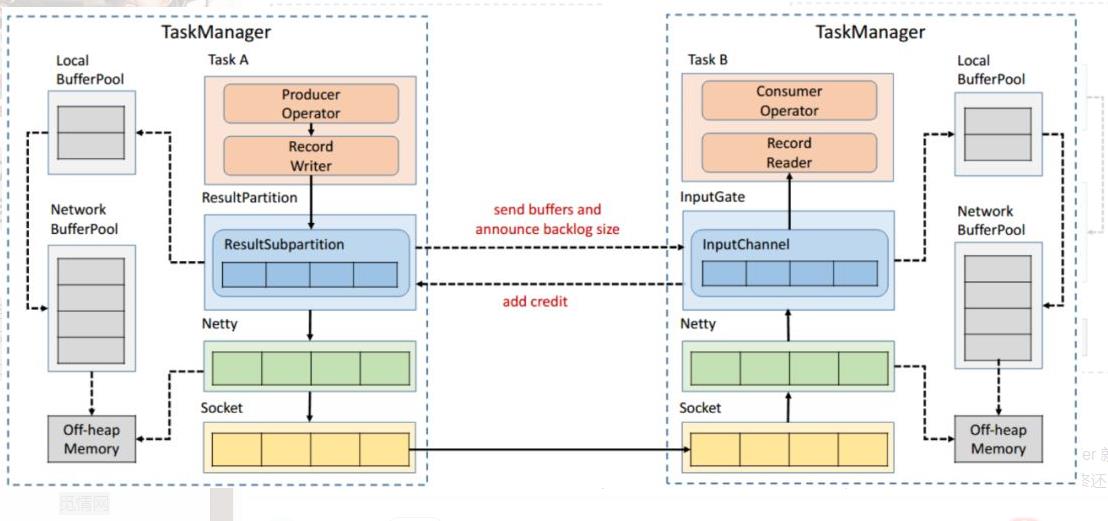
如图所示在 Flink 层面实现反压机制,就是每一次 ResultSubPartition 向 InputChannel 发送消息的时候都会发送一个 backlog size 告诉下游准备发送多少消息,下游就会去计算有多少的 Buffer 去接收消息,算完之后如果有充足的 Buffer 就会返还给上游一个 Credit 告知他可以发送消息(图上两个 ResultSubPartition 和 InputChannel 之间是虚线是因为最终还是要通过 Netty 和 Socket 去通信),下面我们看一个具体示例。
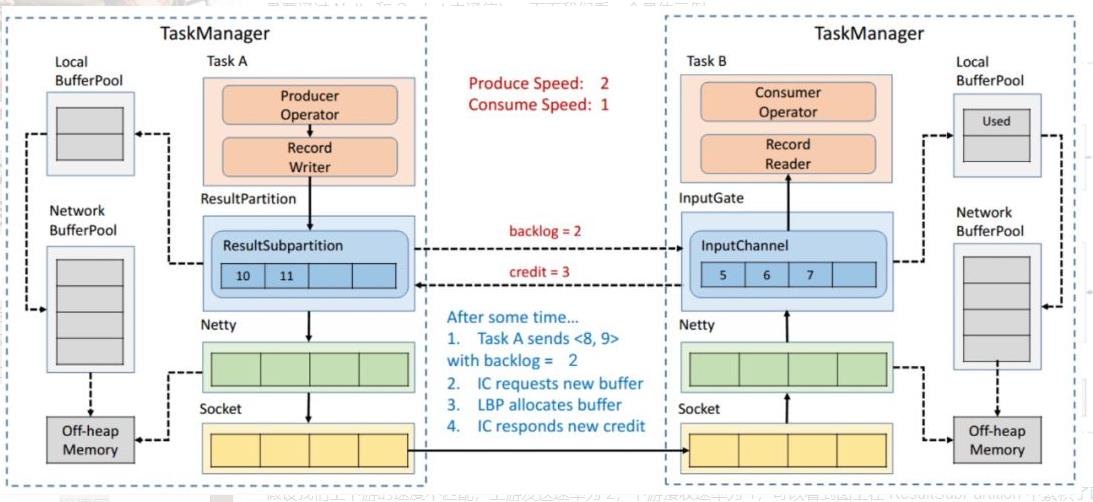
假设我们上下游的速度不匹配,上游发送速率为 2,下游接收速率为 1,可以看到图上在 ResultSubPartition 中累积了两条消息,10 和 11, backlog 就为 2,这时就会将发送的数据 <8,9> 和 backlog = 2 一同发送给下游。下游收到了之后就会去计算是否有 2 个 Buffer 去接收,可以看到 InputChannel 中已经不足了这时就会从 Local BufferPool 和 Network BufferPool 申请,好在这个时候 Buffer 还是可以申请到的。
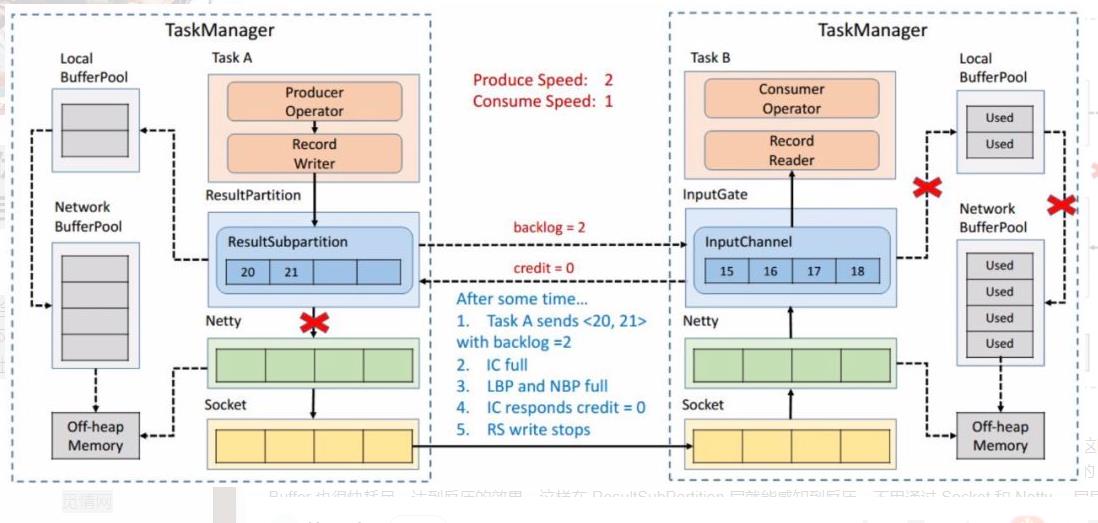
过了一段时间后由于上游的发送速率要大于下游的接受速率,下游的 TaskManager 的 Buffer 已经到达了申请上限,这时候下游就会向上游返回 Credit = 0,ResultSubPartition 接收到之后就不会向 Netty 去传输数据,上游 TaskManager 的 Buffer 也很快耗尽,达到反压的效果,这样在 ResultSubPartition 层就能感知到反压,不用通过 Socket 和 Netty 一层层地向上反馈,降低了反压生效的延迟。同时也不会将 Socket 去阻塞,解决了由于一个 Task 反压导致 TaskManager 和 TaskManager 之间的 Socket 阻塞的问题。
5 总结与思考
5.1. 总结:
-
网络流控是为了在上下游速度不匹配的情况下,防止下游出现过载。
-
网络流控有静态限速和动态反压两种手段。
-
Flink 1.5 之前是基于 TCP 流控 + bounded buffer 实现反压。
-
Flink 1.5 之后实现了自己托管的 credit - based 流控机制,在应用层模拟 TCP 的流控机制。
5.2. 思考:有了动态反压,静态限速是不是完全没有作用了?
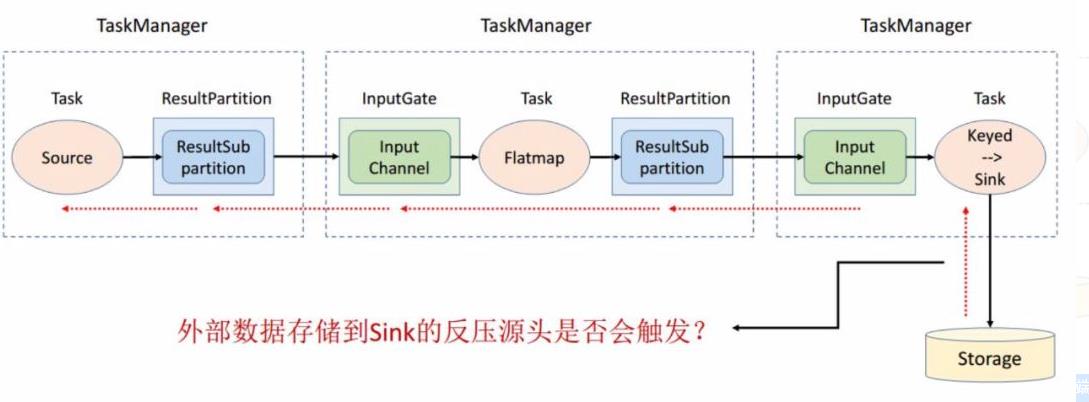
实际上动态反压不是万能的,我们流计算的结果最终是要输出到一个外部的存储(Storage),外部数据存储到 Sink 端的反压是不一定会触发的,这要取决于外部存储的实现,像 Kafka 这样是实现了限流限速的消息中间件可以通过协议将反压反馈给 Sink 端,但是像 ES 无法将反压进行传播反馈给 Sink 端,这种情况下为了防止外部存储在大的数据量下被打爆,我们就可以通过静态限速的方式在 Source 端去做限流。
所以说动态反压并不能完全替代静态限速的,需要根据合适的场景去选择处理方案。
以上是关于FLINK重点原理与机制:内存网络流控及反压机制剖析的主要内容,如果未能解决你的问题,请参考以下文章