Spark学生答题情况分析
Posted 赵广陆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark学生答题情况分析相关的知识,希望对你有一定的参考价值。
目录
1 流程分析
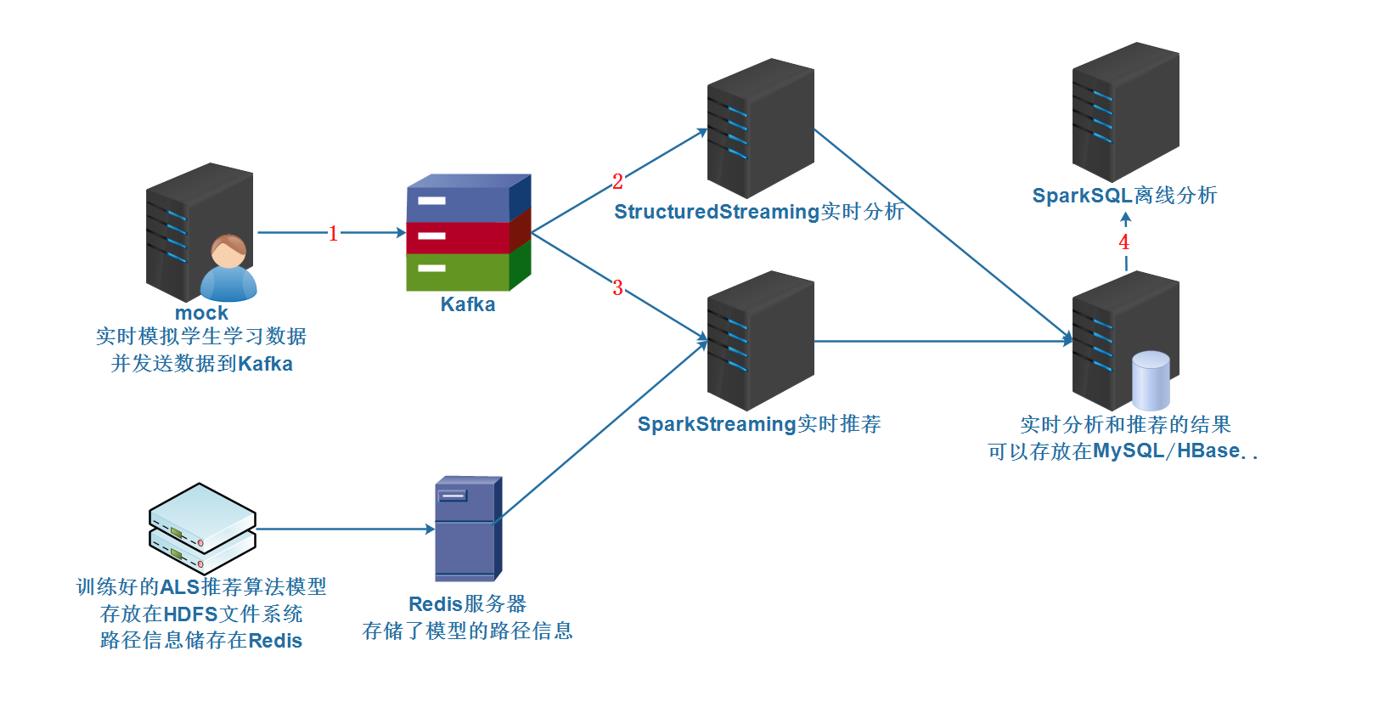
注意: 重点做的 2 3 4 部分
2 业务模块划分

准备工作
3 创建模块包结构

4 准备Kafka主题
#查看topic信息
/export/server/kafka/bin/kafka-topics.sh --list --zookeeper node1:2181
#删除topic
/export/server/kafka/bin/kafka-topics.sh --delete --zookeeper node1:2181 --topic edu
#创建topic
/export/server/kafka/bin/kafka-topics.sh --create --zookeeper node1:2181 --replication-factor 1 --partitions 3 --topic edu
#模拟消费者
/export/server/kafka/bin/kafka-console-consumer.sh --bootstrap-server node1:9092 --topic edu --from-beginning
4.1 测试发送数据到Kafka
启动


{
"student_id":"学生ID_31",
"textbook_id":"教材ID_1",
"grade_id":"年级ID_6",
"subject_id":"科目ID_2_语文",
"chapter_id":"章节ID_chapter_3",
"question_id":"题目ID_1003",
"score":7,
"answer_time":"2021-01-09 14:53:28",
"ts":"Jan 9, 2021 2:53:28 PM"
}
学生答题情况实时分析
5 需求

5.1 代码实现
package cn.itcast.edu.analysis.streaming
import cn.itcast.edu.bean.Answer
import com.google.gson.Gson
import org.apache.spark.SparkContext
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
/**
* Author itcast
* Desc 实时的从Kafka的edu主题消费数据,并做实时的统计分析,结果可以直接输出到控制台或mysql
*/
object StreamingAnalysis {
def main(args: Array[String]): Unit = {
//TODO 0.准备环境
val spark: SparkSession = SparkSession.builder().appName("StreamingAnalysis").master("local[*]")
.config("spark.sql.shuffle.partitions", "4")//本次测试时将分区数设置小一点,实际开发中可以根据集群规模调整大小,默认200
.getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
import spark.implicits._
import org.apache.spark.sql.functions._
//TODO 1.加载数据
val kafkaDF: DataFrame = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "node1:9092")
.option("subscribe", "edu")
.load()
val valueDS: Dataset[String] = kafkaDF.selectExpr("CAST(value AS STRING)").as[String]
//{"student_id":"学生ID_31","textbook_id":"教材ID_1","grade_id":"年级ID_6","subject_id":"科目ID_2_语文","chapter_id":"章节ID_chapter_3","question_id":"题目ID_1003","score":7,"answer_time":"2021-01-09 14:53:28","ts":"Jan 9, 2021 2:53:28 PM"}
//TODO 2.处理数据
//---数据预处理
//解析json-方式1:
/*valueDS.select(
get_json_object($"value", "$.student_id").as("student_id"),
//.....
)*/
//解析json-方式2:将每一条json字符串解析为一个样例类对象
val answerDS: Dataset[Answer] = valueDS.map(josnStr => {
val gson = new Gson()
//json--->对象
gson.fromJson(josnStr, classOf[Answer])
})
//---实时分析
//TODO ==实时分析需求1:统计top10热点题
//SQL
/*
val result1 = spark.sql(
"""SELECT
| question_id, COUNT(1) AS frequency
|FROM
| t_answer
|GROUP BY
| question_id
|ORDER BY
| frequency
|DESC
|LIMIT 10
""".stripMargin)
*/
//DSL
val result1: Dataset[Row] = answerDS.groupBy('question_id)
//.agg(count('question_id) as "count")
.count()
.orderBy('count.desc)
.limit(10)
//TODO ==实时分析需求2:统计top10答题活跃年级
/*
val result2 = spark.sql(
"""SELECT
| grade_id, COUNT(1) AS frequency
|FROM
| t_answer
|GROUP BY
| grade_id
|ORDER BY
| frequency
|DESC
|LIMIT 10
""".stripMargin)
*/
val result2: Dataset[Row] = answerDS.groupBy('grade_id)
.count()
.orderBy('count.desc)
.limit(10)
//TODO ==实时分析需求3:统计top10热点题并带上所属科目
/*
注意:select...group语句下,select 后面的字段要么是分组字段,要么是聚合字段
val result1 = spark.sql(
"""SELECT
| question_id,first(subject_id), COUNT(1) AS frequency
|FROM
| t_answer
|GROUP BY
| question_id
|ORDER BY
| frequency
|DESC
|LIMIT 10
""".stripMargin)
*/
val result3: Dataset[Row] = answerDS.groupBy('question_id)
.agg(
first('subject_id) as "subject_id",
count('question_id) as "count"
)
.orderBy('count.desc)
.limit(10)
//TODO ==实时分析需求4:统计每个学生的得分最低的题目top10并带上是所属哪道题
/*
val result4 = spark.sql(
"""SELECT
| student_id, FIRST(question_id), MIN(score)
|FROM
| t_answer
|GROUP BY
| student_id
|order by
| score
|limit 10
""".stripMargin)
*/
val result4: Dataset[Row] = answerDS.groupBy('student_id)
.agg(
min('score) as "minscore",
first('question_id)
)
.orderBy('minscore)
.limit(10)
//TODO 3.输出结果
result1.writeStream
.format("console")
.outputMode("complete")
.start()
result2.writeStream
.format("console")
.outputMode("complete")
.start()
result3.writeStream
.format("console")
.outputMode("complete")
.start()
result4.writeStream
.format("console")
.outputMode("complete")
//TODO 4.启动并等待结束
.start()
.awaitTermination()
//TODO 5.关闭资源
spark.stop()
}
}
实时推荐易错题
6 需求

6.1 准备模型-直接训练并使用

6.2 代码实现
package cn.itcast.edu.analysis.streaming
import cn.itcast.edu.bean.Answer
import cn.itcast.edu.utils.RedisUtil
import com.google.gson.Gson
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.ml.recommendation.ALSModel
import org.apache.spark.{SparkContext, streaming}
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import redis.clients.jedis.Jedis
/**
* Author itcast
* Desc
* 从Kafka消费消息(消息中有用户id),
* 然后从Redis中获取推荐模型的路径,并从路径中加载推荐模型ALSModel
* 然后使用该模型给用户推荐易错题
*/
object StreamingRecommend {
def main(args: Array[String]): Unit = {
//TODO 0.准备环境
val spark: SparkSession = SparkSession.builder().appName("StreamingAnalysis").master("local[*]")
.config("spark.sql.shuffle.partitions", "4") //本次测试时将分区数设置小一点,实际开发中可以根据集群规模调整大小,默认200
.getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
val ssc: StreamingContext = new StreamingContext(sc, streaming.Seconds(5))
import spark.implicits._
import org.apache.spark.sql.functions._
//TODO 1.加载数据
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "node1:9092", //kafka集群地址
"key.deserializer" -> classOf[StringDeserializer], //key的反序列化规则
"value.deserializer" -> classOf[StringDeserializer], //value的反序列化规则
"group.id" -> "StreamingRecommend", //消费者组名称
"auto.offset.reset" -> "latest",
"auto.commit.interval.ms" -> "1000", //自动提交的时间间隔
"enable.auto.commit" -> (true: java.lang.Boolean) //是否自动提交
)
val topics = Array("edu") //要订阅的主题
val kafkaDStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topics, kafkaParams)
)
//TODO 2.处理数据
val valueDStream: DStream[String] = kafkaDStream.map(record => {
record.value()
})
//{"student_id":"学生ID_47","textbook_id":"教材ID_1","grade_id":"年级ID_3","subject_id":"科目ID_3_英语","chapter_id":"章节ID_chapter_3","question_id":"题目ID_534","score":7,"answer_time":"2021-01-09 15:29:50","ts":"Jan 9, 2021 3:29:50 PM"}
valueDStream.foreachRDD(rdd => {
if (!rdd.isEmpty()) {
//该rdd表示每个微批的数据
//==1.获取path并加载模型
//获取redis连接
val jedis: Jedis = RedisUtil.pool.getResource
//加载模型路径
// jedis.hset("als_model", "recommended_question_id", path)
val path: String = jedis.hget("als_model", "recommended_question_id")
//根据路径加载模型
val model: ALSModel = ALSModel.load(path)
//==2.取出用户id
val answerDF: DataFrame = rdd.coalesce(1).map(josnStr => {
val gson = new Gson()
gson.fromJson(josnStr, classOf[Answer])
}).toDF
//将用户id转为数字,因为后续模型推荐的时候需要数字格式的id
val id2int = udf((student_id: String) => {
student_id.split("_")(1).toInt
})
val studentIdDF: DataFrame = answerDF.select(id2int('student_id) as "student_id")
//==3.使用模型给用户推荐题目
val recommendDF: DataFrame = model.recommendForUserSubset(studentIdDF, 10)
recommendDF.printSchema()
/*
root
|-- student_id: integer (nullable = false) --用户id
|-- recommendations: array (nullable = true)--推荐列表
| |-- element: struct (containsNull = true)
| | |-- question_id: integer (nullable = true)--题目id
| | |-- rating: float (nullable = true)--评分/推荐指数
*/
recommendDF.show(false)
/*
+----------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|student_id|recommendations |
+----------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|12 |[[1707, 2.900552], [641, 2.8934805], [815, 2.8934805], [1583, 2.8934805], [1585, 2.8774242], [1369, 2.8033295], [906, 2.772558], [2129, 2.668791], [1661, 2.585957], [1978, 2.5290453]] |
|14 |[[1627, 2.8925943], [446, 2.8925943], [1951, 2.8925943], [1412, 2.8925943], [1812, 2.8925943], [1061, 2.8816805], [1661, 2.874632], [1453, 2.8682063], [1111, 2.8643343], [1797, 2.7966104]]|
*/
//处理推荐结果:取出用户id和题目id拼成字符串:"id1,id2,id3..."
val recommendResultDF: DataFrame = recommendDF.as[(Int, Array[(Int, Float)])].map(t => {
//val studentId: Int = t._1
//val studentIdStr: String = "学生ID_"+ studentId
//val questionIdsAndRating: Array[(Int, Float)] = t._2
//val questionIds: Array[Int] = questionIdsAndRating.map(_._1)
//val questionIdsStr: String = questionIds.mkString(",")
val studentIdStr: String = "学生ID_" + t._1
val questionIdsStr: String = t._2.map("题目ID_" + _._1).mkString(",")
(studentIdStr, questionIdsStr)
}).toDF("student_id", "recommendations")
//将answerDF和recommendResultDF进行join
val allInfoDF: DataFrame = answerDF.join(recommendResultDF, "student_id")
//==4.输出结果到MySQL/HBase
if (allInfoDF.count() > 0) {
val properties = new java.util.Properties()
properties.setProperty("user", "root")
properties.setProperty("password", "root")
allInfoDF
.write
.mode(SaveMode.Append)
.jdbc("jdbc:mysql://localhost:3306/edu?useUnicode=true&characterEncoding=utf8", "t_recommended", properties)
}
//关闭redis连接
jedis.close()
}
}
)
//TODO 3.输出结果
//TODO 4.启动并等待停止
ssc.start()
ssc.awaitTermination()
//TODO 5.关闭资源
ssc.stop(stopSparkContext = true, stopGracefully = true) //优雅关闭
}
}
7 学生答题情况离线分析


7.1 代码实现

package cn.itcast.edu.analysis.batch
import breeze.linalg.*
import cn.itcast.edu.bean.AnswerWithRecommendations
import org.apache.spark.SparkContext
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
/**
* Author itcast
* Desc 离线分析学生学习情况
*/
object BatchAnalysis {
def main(args: Array[String]): Unit = {
//TODO 0.准备环境-SparkSession
val spark: SparkSession = SparkSession.builder().appName("BatchAnalysis").master("local[*]")
.config("spark.sql.shuffle.partitions", "4")//本次测试时将分区数设置小一点,实际开发中可以根据集群规模调整大小,默认200
.getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
import spark.implicits._
import org.apache.spark.sql.functions._
//TODO 1.加载数据-MySQL
val properties = new java.util.Properties()
properties.setProperty("user", "root")
properties.setProperty("password", "root")
val allInfoDS: Dataset[AnswerWithRecommendations] = spark.read.jdbc(
"jdbc:mysql://localhost:3306/edu?useUnicode=true&characterEncoding=utf8",
"t_recommended",
properties
).as[AnswerWithRecommendations]
//TODO 2.处理数据/分析数据
//TODO ===SQL
//TODO: 需求:1.各科目热点题分析
// 找到Top50热点题对应的科目,然后统计这些科目中,分别包含这几道热点题的条目数
/*
题号 热度
1 10
2 9
3 8
*/
/*
题号 热度 科目
1 10 语文
2 9 数学
3 8 数学
*/
/*
科目 热点题数量
语文 1
数学 2
*/
//1.统计Top50热点题--子查询t1
//2.将t1和原始表t_answer关联,并按学科分组聚合统计各个学科包含的热点题的数量
//==================写法1:SQL风格================
/*spark.sql(
"""SELECT
| subject_id, count(t_answer.question_id) AS hot_question_count
| FROM
| (SELECT
| question_id, count(*) AS frequency
| FROM
| t_answer
| GROUP BY
| question_id
| ORDER BY
| frequency
| DESC LIMIT
| 50) t1
|JOIN
| t_answer
|ON
| t1.question_id = t_answer.question_id
|GROUP BY
| subject_id
|ORDER BY
| hot_question_count
| DESC
""".stripMargin)
.show()*/
以上是关于Spark学生答题情况分析的主要内容,如果未能解决你的问题,请参考以下文章