R语言使用Rasch模型分析学生答题能力
Posted tecdat
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言使用Rasch模型分析学生答题能力相关的知识,希望对你有一定的参考价值。
原文链接:http://tecdat.cn/?p=10175
几个月以来,我一直对序数回归与项目响应理论(IRT)之间的关系感兴趣。 在这篇文章中,我重点介绍Rasch分析。
最近,我花了点时间尝试理解不同的估算方法。三种最常见的估算方法是:
-
联合最大似然(JML)
-
条件逻辑回归,在文献中称为条件最大似然(CML)。
-
标准多级模型,在测量文献中称为边际最大似然(MML)。
阅读后,我决定尝试进行Rasch分析,产生多个Rasch输出。
示范
进行此演示之后,可能需要ggplot2和dplyr的知识才能创建图表。
library(eRm) # Standard Rasch analysis with CML estimation
library(Epi) # For conditional logistic regression with contrasts
library(lme4) # For glmer
library(ggplot2) # For plotting
library(ggrepel) # For plot labeling
library(dplyr) # For data manipulation
library(scales) # For formatted percent on ggplot axes
数据。
raschdat1 <- as.data.frame(raschdat1)
CML估算
res.rasch <- RM(raschdat1)
系数。
coef(res.rasch)
beta V1 beta V2 beta V3 beta V4 beta V5
1.565269700 0.051171719 0.782190094 -0.650231958 -1.300578876
beta V6 beta V7 beta V8 beta V9 beta V10
0.099296282 0.681696827 0.731734160 0.533662275 -1.107727126
beta V11 beta V12 beta V13 beta V14 beta V15
-0.650231959 0.387903893 -1.511191830 -2.116116897 0.339649394
beta V16 beta V17 beta V18 beta V19 beta V20
-0.597111141 0.339649397 -0.093927362 -0.758721132 0.681696827
beta V21 beta V22 beta V23 beta V24 beta V25
0.936549373 0.989173502 0.681696830 0.002949605 -0.814227487
beta V26 beta V27 beta V28 beta V29 beta V30
1.207133468 -0.093927362 -0.290443234 -0.758721133 0.731734150
使用回归
raschdat1.long <- raschdat1
raschdat1.long$tot <- rowSums(raschdat1.long) # Create total score
c(min(raschdat1.long$tot), max(raschdat1.long$tot)) # Min and max score
[1] 1 26
raschdat1.long$ID <- 1:nrow(raschdat1.long) # create person ID
raschdat1.long <- tidyr::gather(raschdat1.long, item, value, V1:V30) # Wide to long
# Make item a factor
raschdat1.long$item <- factor(
raschdat1.long$item, levels = paste0("V", 1:30), ordered = TRUE)
有条件最大似然
# Regression coefficients
coef(res.clogis)
item1 item2 item3 item4 item5
0.051193209 0.782190560 -0.650241362 -1.300616876 0.099314453
item6 item7 item8 item9 item10
0.681691285 0.731731557 0.533651426 -1.107743224 -0.650241362
item11 item12 item13 item14 item15
0.387896763 -1.511178125 -2.116137610 0.339645555 -0.597120333
item16 item17 item18 item19 item20
0.339645555 -0.093902568 -0.758728000 0.681691285 0.936556599
item21 item22 item23 item24 item25
0.989181510 0.681691285 0.002973418 -0.814232531 1.207139323
item26 item27 item28 item29
-0.093902568 -0.290430680 -0.758728000 0.731731557
请注意,item1是V2而不是V1,item29是V30。要获得第一个项目V1的难易程度,只需将项目1到项目29的系数求和,然后乘以-1。
sum(coef(res.clogis)[1:29]) * -1
[1] 1.565278
# A few more things to confirm both models are equivalent
res.rasch$loglik # Rasch log-likelihood
[1] -1434.482
# conditional logsitic log-likelihood, second value is log-likelihood of final model
res.clogis$loglik
[1] -1630.180 -1434.482
# One can also compare confidence intervals, variances, ...
# clogistic allows you to check the actual sample size for the analysis using:
res.clogis$n
[1] 3000
显然,所有数据(30 * 100)都用于估算。这是因为没有一个参与者在所有问题上都得分为零,在所有问题上都得分为1(最低为1,最高为30分中的26分)。所有数据都有助于估计,因此本示例中的方差估计是有效的
联合极大似然估计
# Standard logistic regression, note the use of contrasts
res.jml
# First thirty coefficients
coef(res.jml)[1:30]
(Intercept) item1 item2 item3 item4
-3.688301292 0.052618523 0.811203577 -0.674538589 -1.348580496
item5 item6 item7 item8 item9
0.102524596 0.706839644 0.758800752 0.553154545 -1.148683041
item10 item11 item12 item13 item14
-0.674538589 0.401891360 -1.566821260 -2.193640539 0.351826379
item15 item16 item17 item18 item19
-0.619482689 0.351826379 -0.097839229 -0.786973625 0.706839644
item20 item21 item22 item23 item24
0.971562267 1.026247034 0.706839644 0.002613624 -0.844497142
item25 item26 item27 item28 item29
1.252837340 -0.097839229 -0.301589647 -0.786973625 0.758800752
item29与V30相同。差异是由估算方法的差异引起的。要获得第一个项目V1的难易程度,只需将项目1到项目29的系数求和,然后乘以-1。
sum(coef(res.jml)[2:30]) * -1
[1] 1.625572
多级逻辑回归或MML
我希望回归系数是项目到达时的难易程度,并且glmmTMB()不提供对比选项。我要做的是运行glmer()两次,将第一次运行的固定效果和随机效果作为第二次运行的起始值。
使用多级模型复制Rasch结果
提供人员-物品映射:
plotPImap(res.rasch)
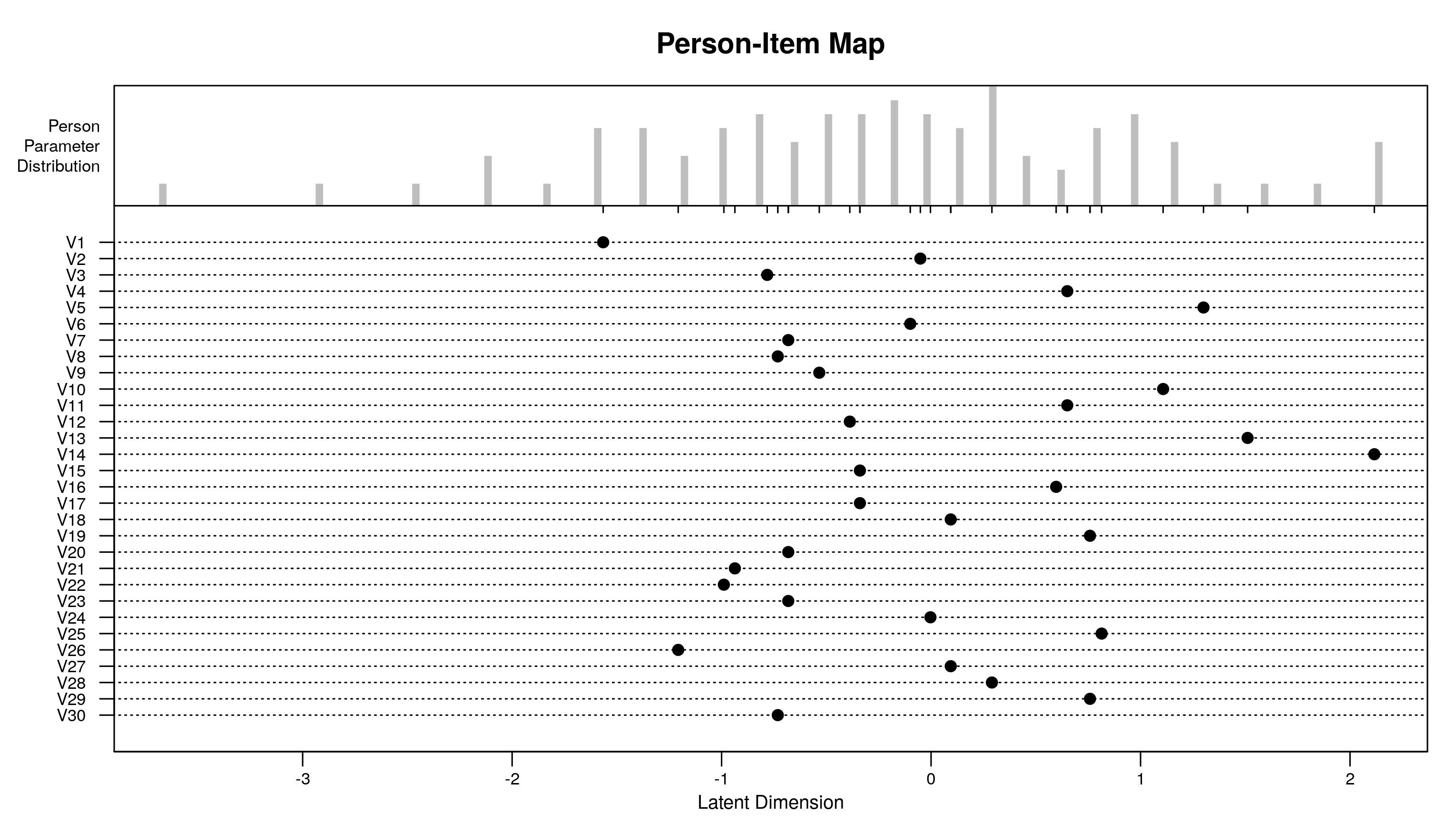
![]() ?
?
要创建此图,我们需要项目难度(回归系数* -1)和人员能力(随机截距)。
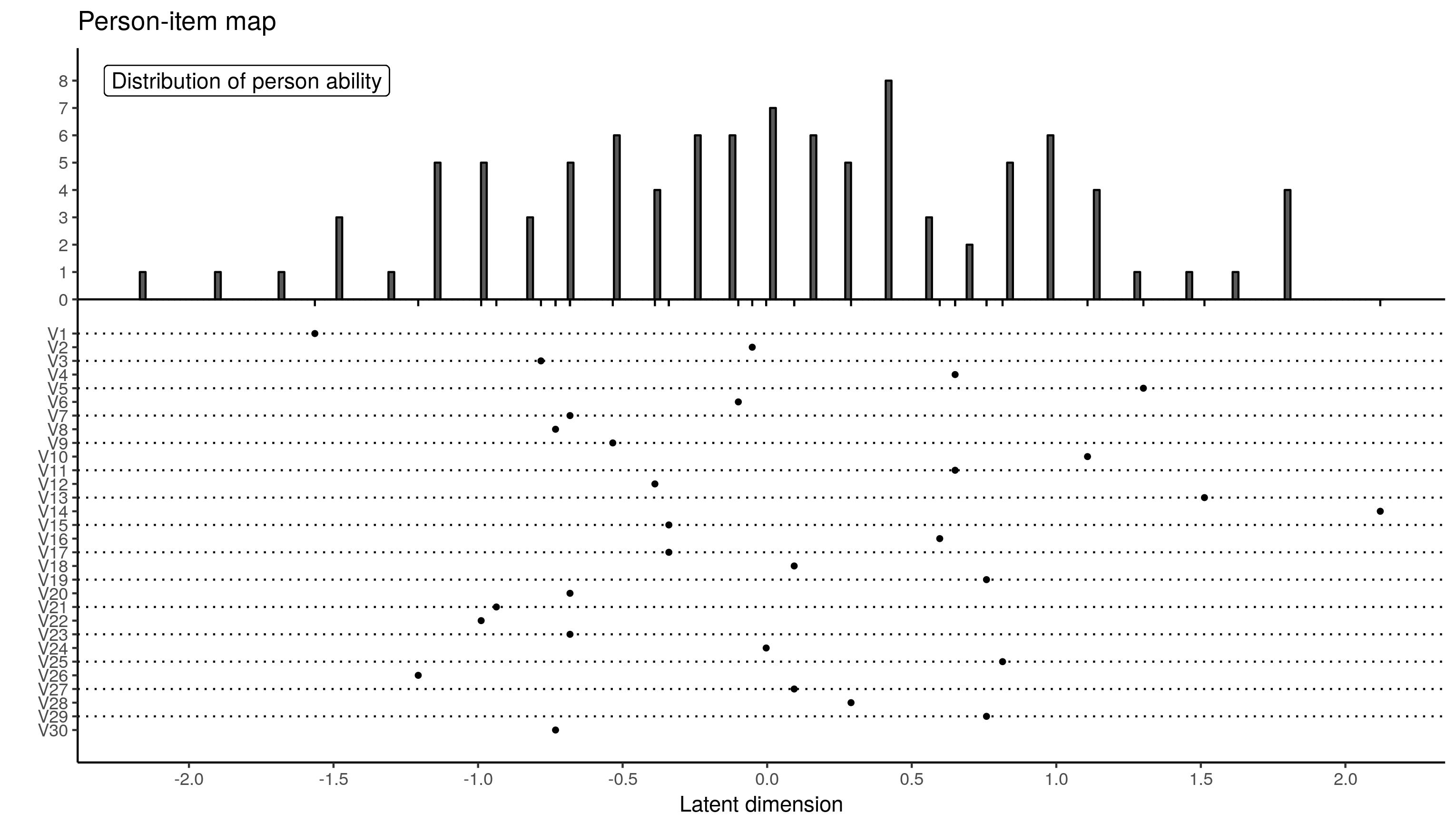
![]() ?
?
极端的分数是不同的。这归因于MML的差异。由于CML不提供人为因素,因此必须使用两步排序过程。
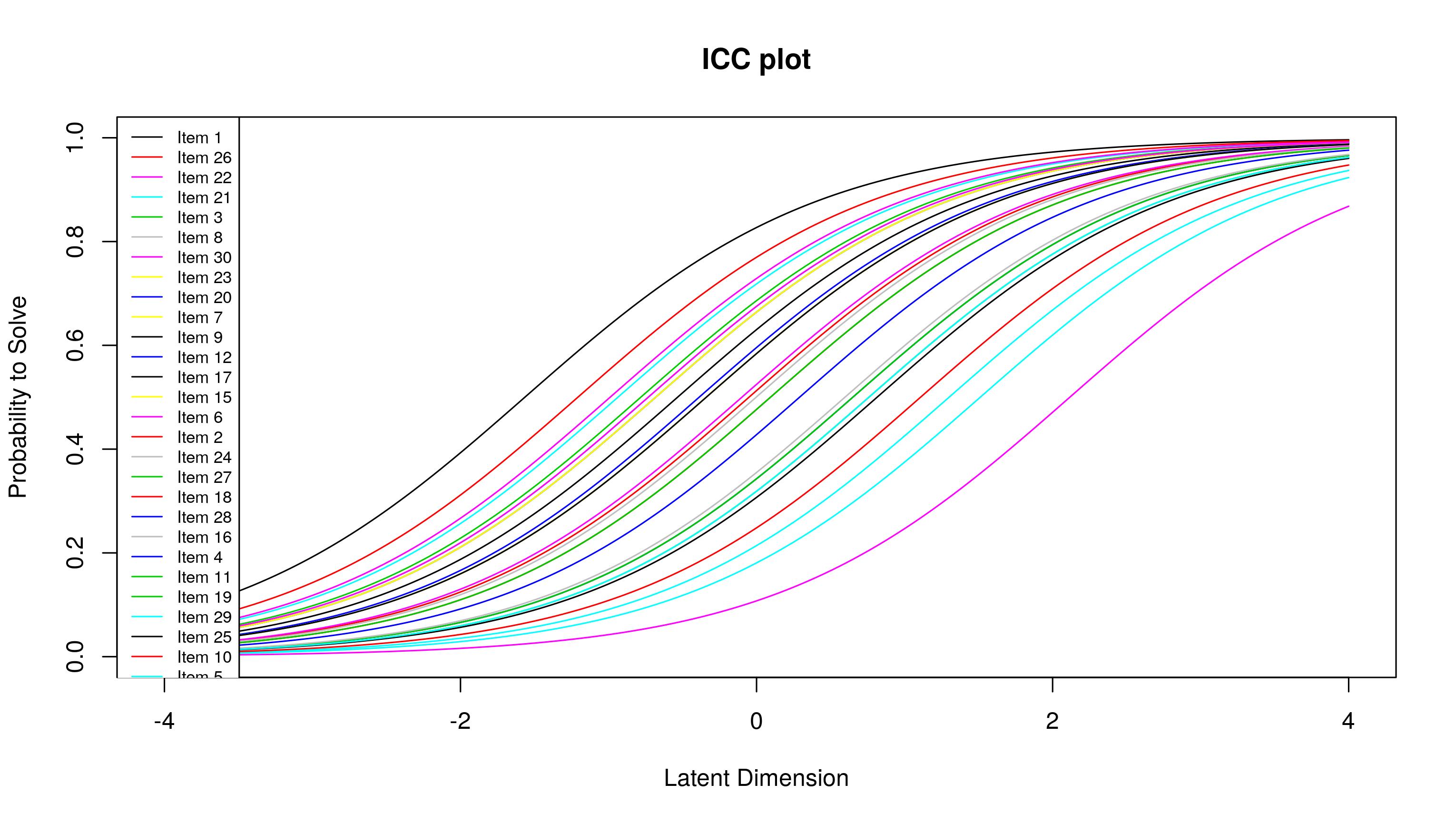
项目特征曲线
eRm用一条线提供项目特征曲线:
plotjointICC(res.rasch)
![]() ?
?
在这里,我们需要能够根据学生的潜能来预测学生正确答题的概率。我所做的是使用逻辑方程式预测概率。一旦获得该对数奇数,就很容易计算预测概率。由于我使用循环来执行此操作,因此我还要计算项目信息,该信息是预测概率乘以1-预测概率。
## GGPLOT-ING
ggplot(test.info.df, aes(x = theta, y = prob, colour = reorder(item, diff, mean))) +
geom_line() +
scale_y_continuous(labels = percent) +
scale_x_continuous(breaks = -6:6, limits = c(-4, 4)) +
labs(x = "Person ability", y = "Probability of correct response", colour = "Item",
title = "Joint item characteristic plot") +
theme_classic()
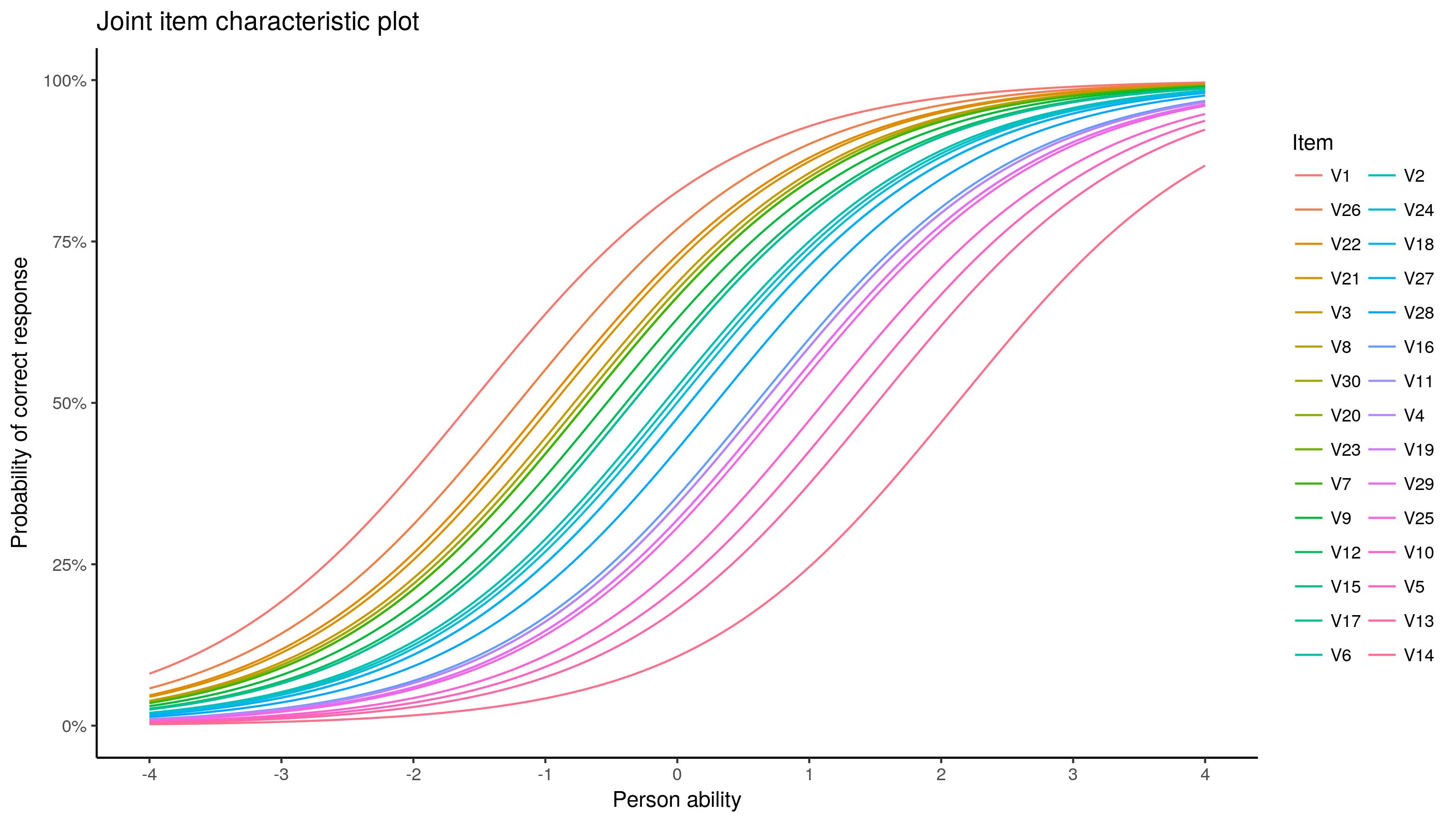
![]() ?
?
下面将逐项绘制
ggplot(test.info.df, aes(x = theta, y = prob)) + geom_line() +
scale_x_continuous(breaks = seq(-6, 6, 2), limits = c(-4, 4)) +
scale_y_continuous(labels = percent, breaks = seq(0, 1, .25)) +
labs(x = "Person ability", y = "Probability of correct response",
title = "Item characteristic plot",
subtitle = "Items ordered from least to most difficult") +
facet_wrap(~ reorder(item, diff, mean), ncol = 10) +
theme_classic()
人员参数图
plot(person.parameter(res.rasch))
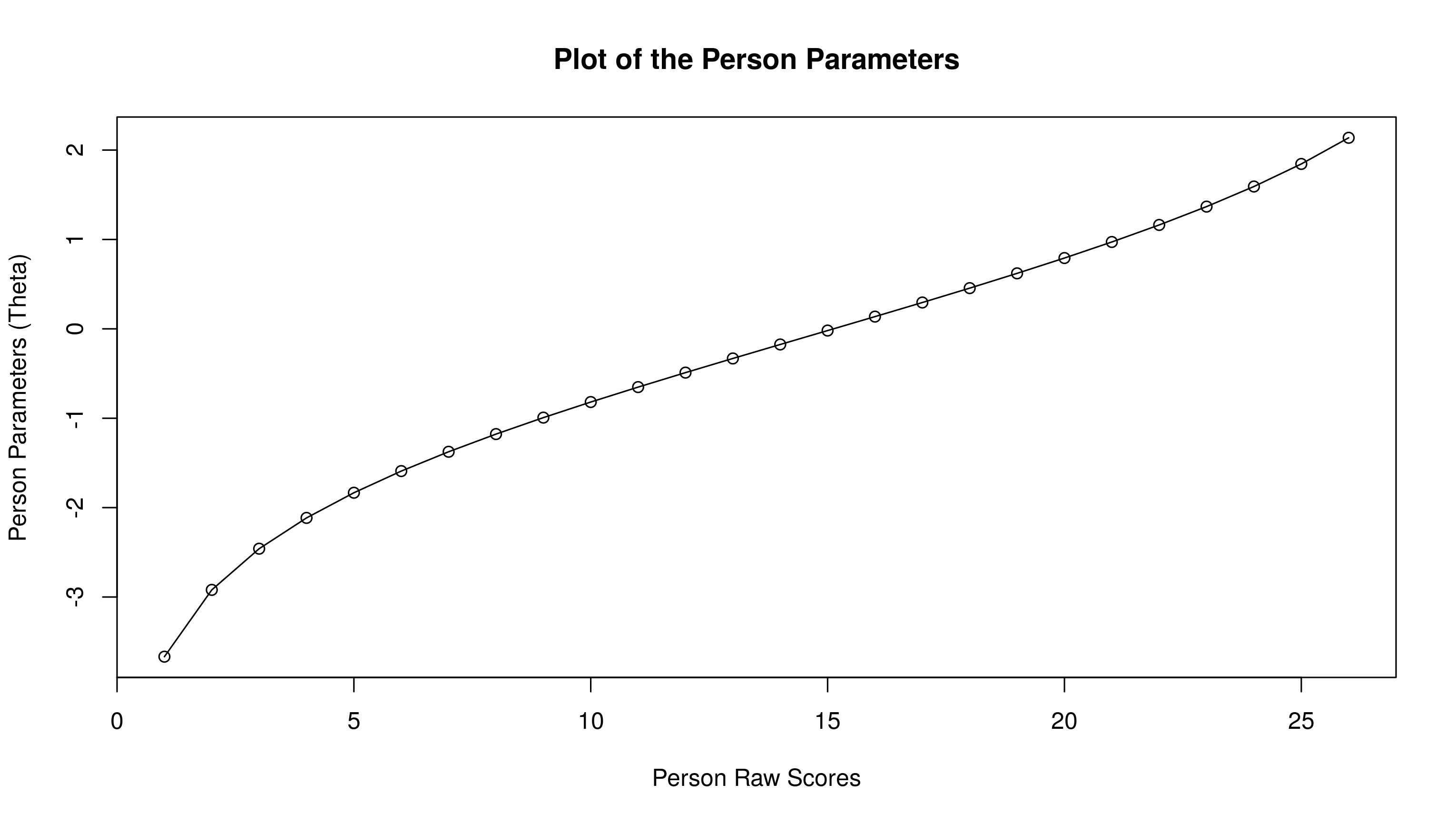
![]() ?
?
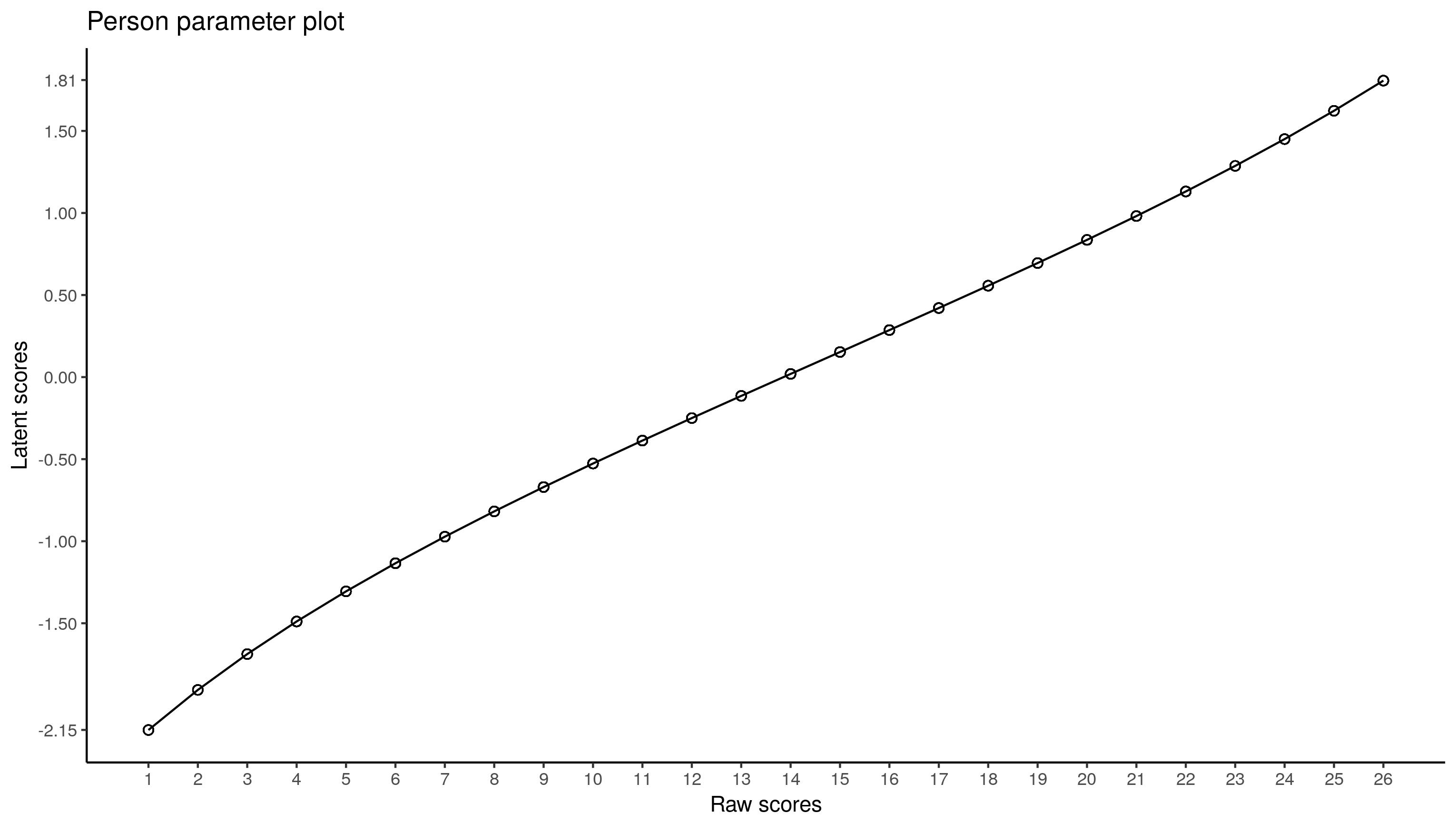
与其他人相比,这非常简单。我们需要估计的人员能力:
ggplot(raschdat1.long, aes(x = tot, y = ability)) +
geom_point(shape = 1, size = 2) + geom_line() +
scale_x_continuous(breaks = 1:26) +
scale_y_continuous(breaks = round(c(
min(raschdat1.long$ability),seq(-1.5, 1.5, .5),
max(raschdat1.long$ability)), 2)) +
labs(x = "Raw scores", y = "Latent scores", title = "Person parameter plot") +
theme_classic()
![]() ?
?
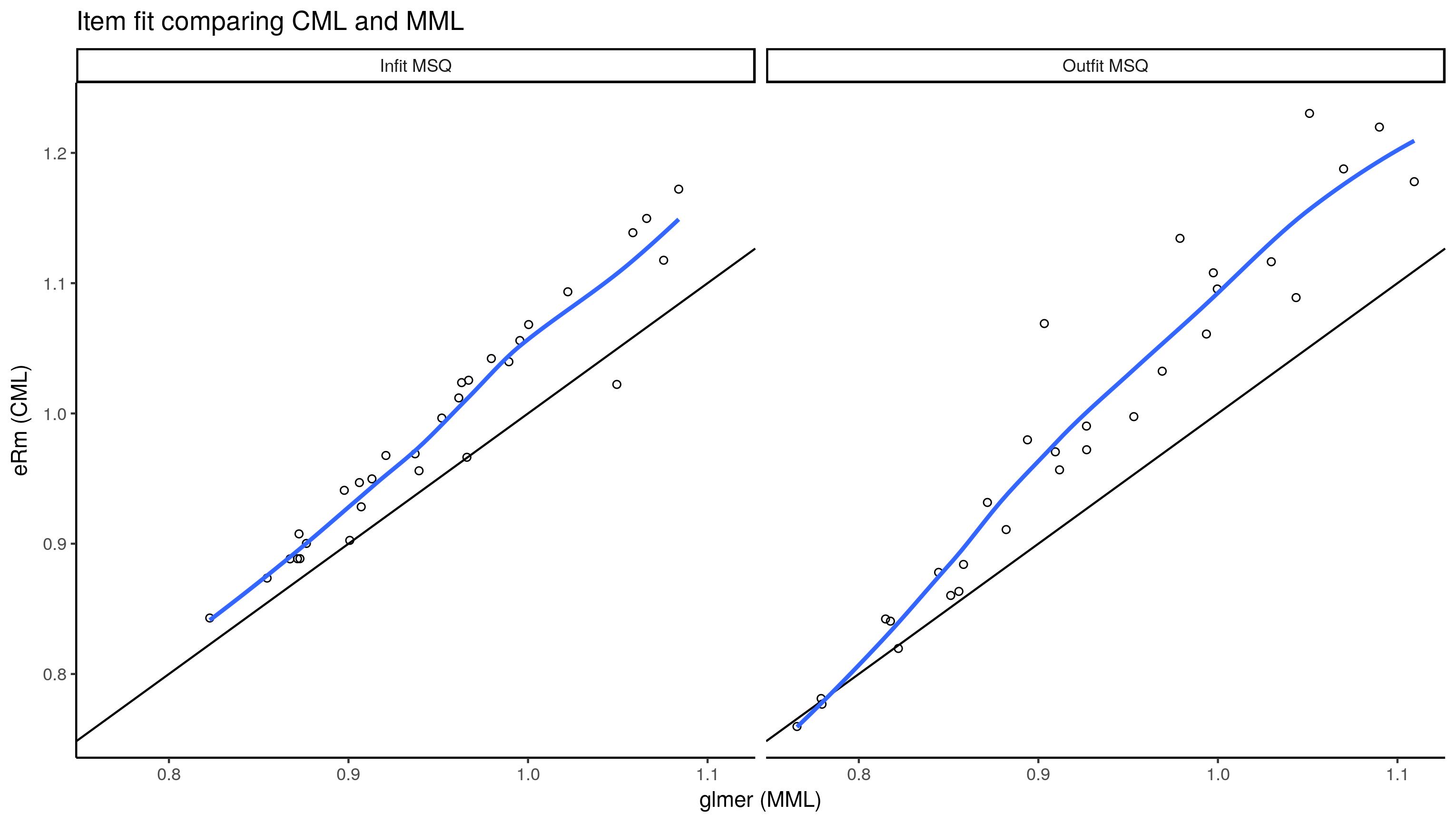
项目均方拟合
对于infit MSQ,执行相同的计算。
eRm:
ggplot(item.fit.df, aes(x = mml, y = cml)) +
scale_x_continuous(breaks = seq(0, 2, .1)) +
scale_y_continuous(breaks = seq(0, 2, .1)) +
geom_point(shape = 1) + geom_abline(slope = 1) + theme_classic() +
geom_smooth(se = FALSE) + facet_wrap(~ method, ncol = 2) +
labs(x = "glmer (MML)", y = "eRm (CML)", title = "Item fit comparing CML and MML")
![]() ?
?
似乎CML的MSQ几乎总是比多级模型(MML)的MSQ高。
eRm:
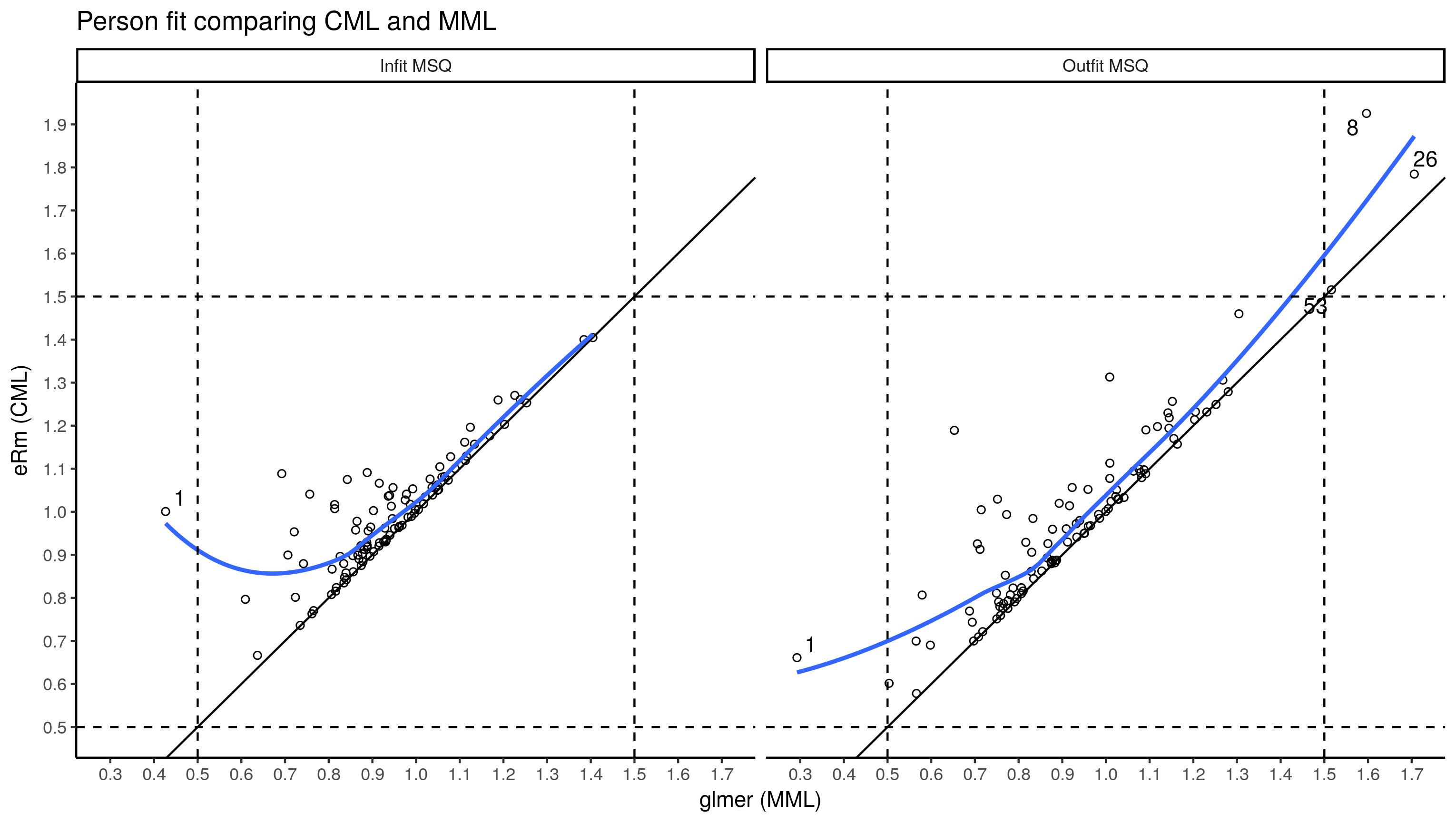
![]() ?
?
来自CML的MSQ几乎总是比来自多层次模型(MML)的MSQ高。我使用传统的临界值来识别不适合的人。身材矮小的人MSQ只有一个正确的问题,无法回忆起8、26和53的问题。
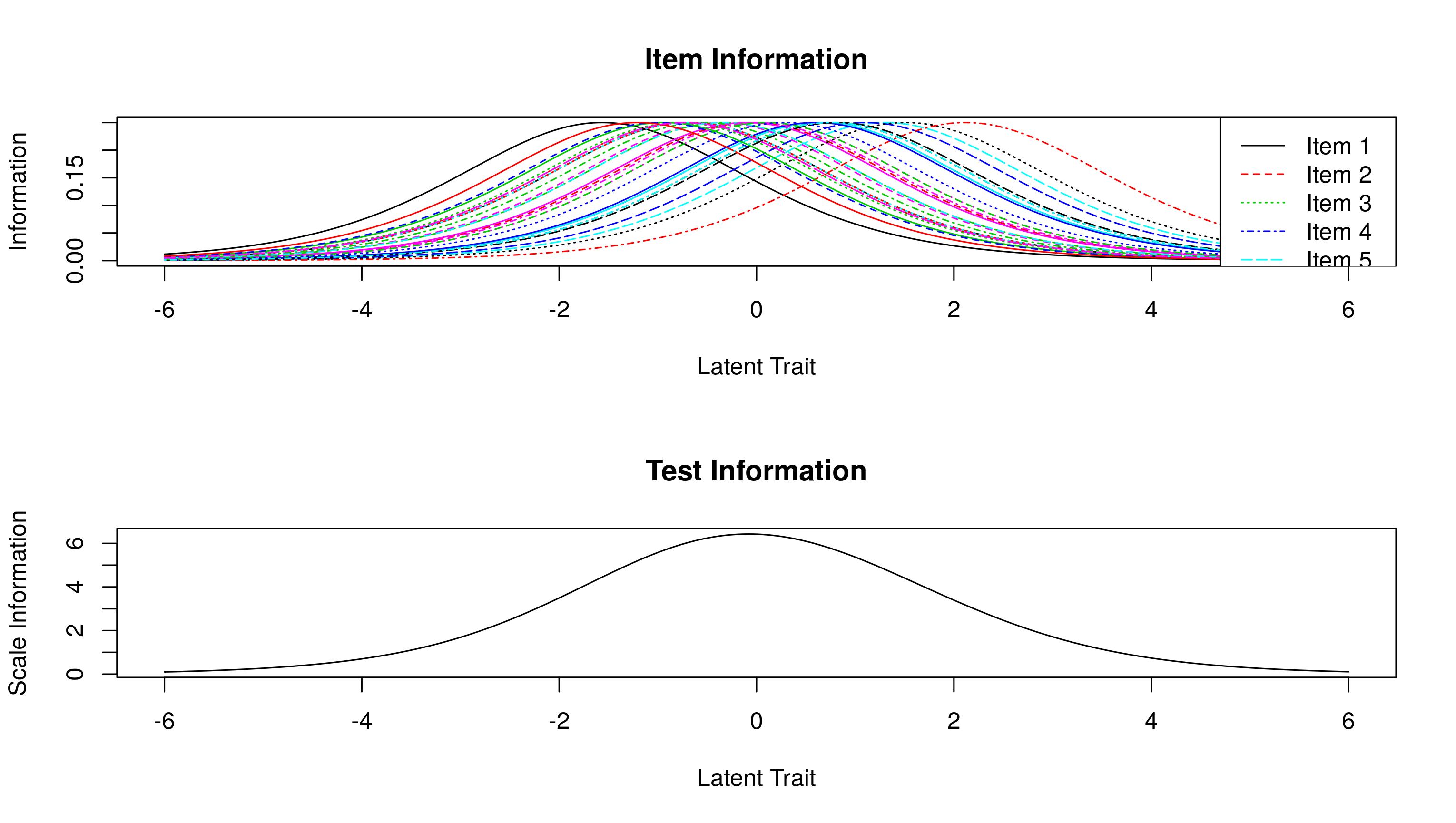
测试信息
eRm:
plotINFO(res.rasch)
![]() ?
?
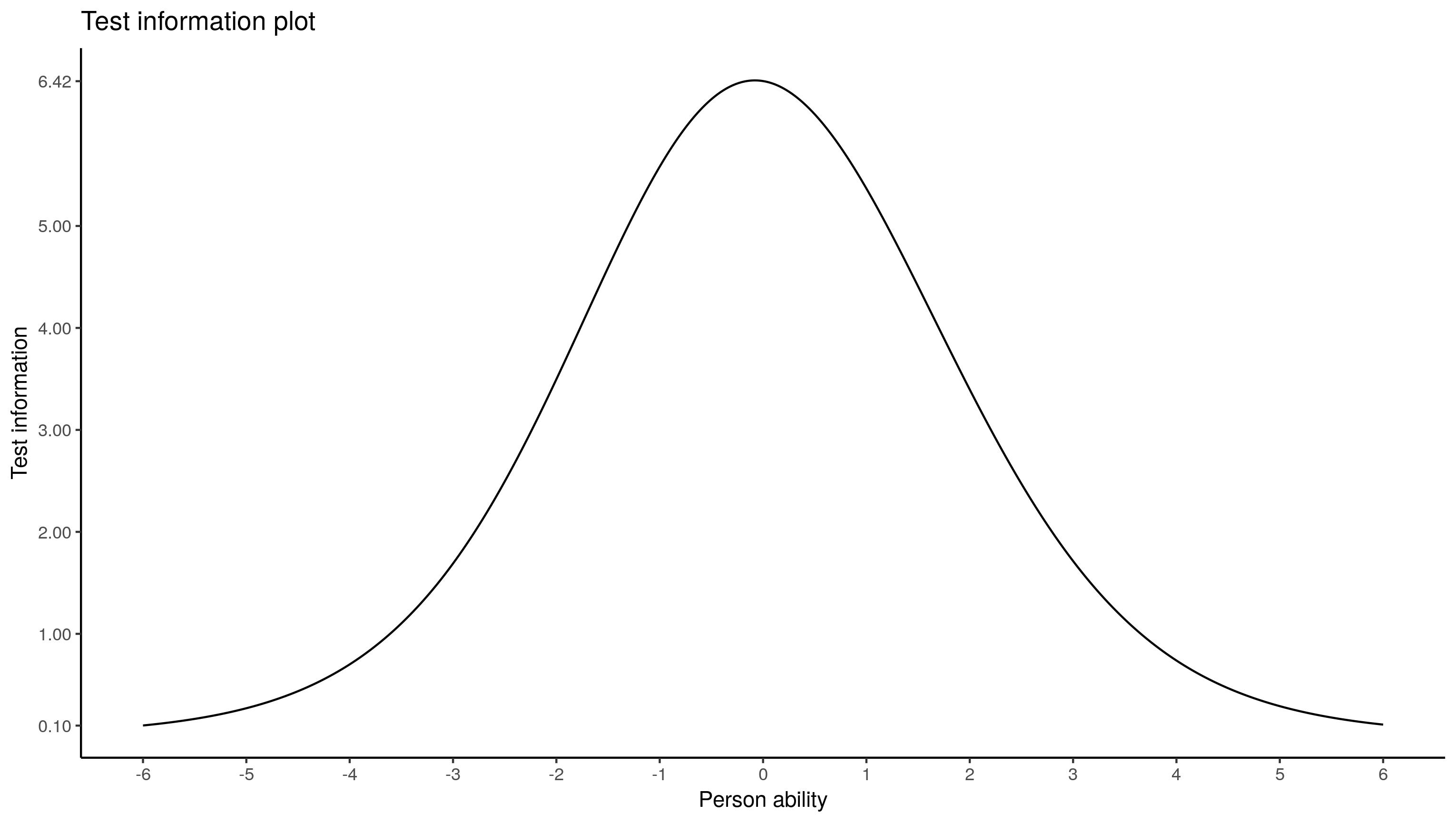
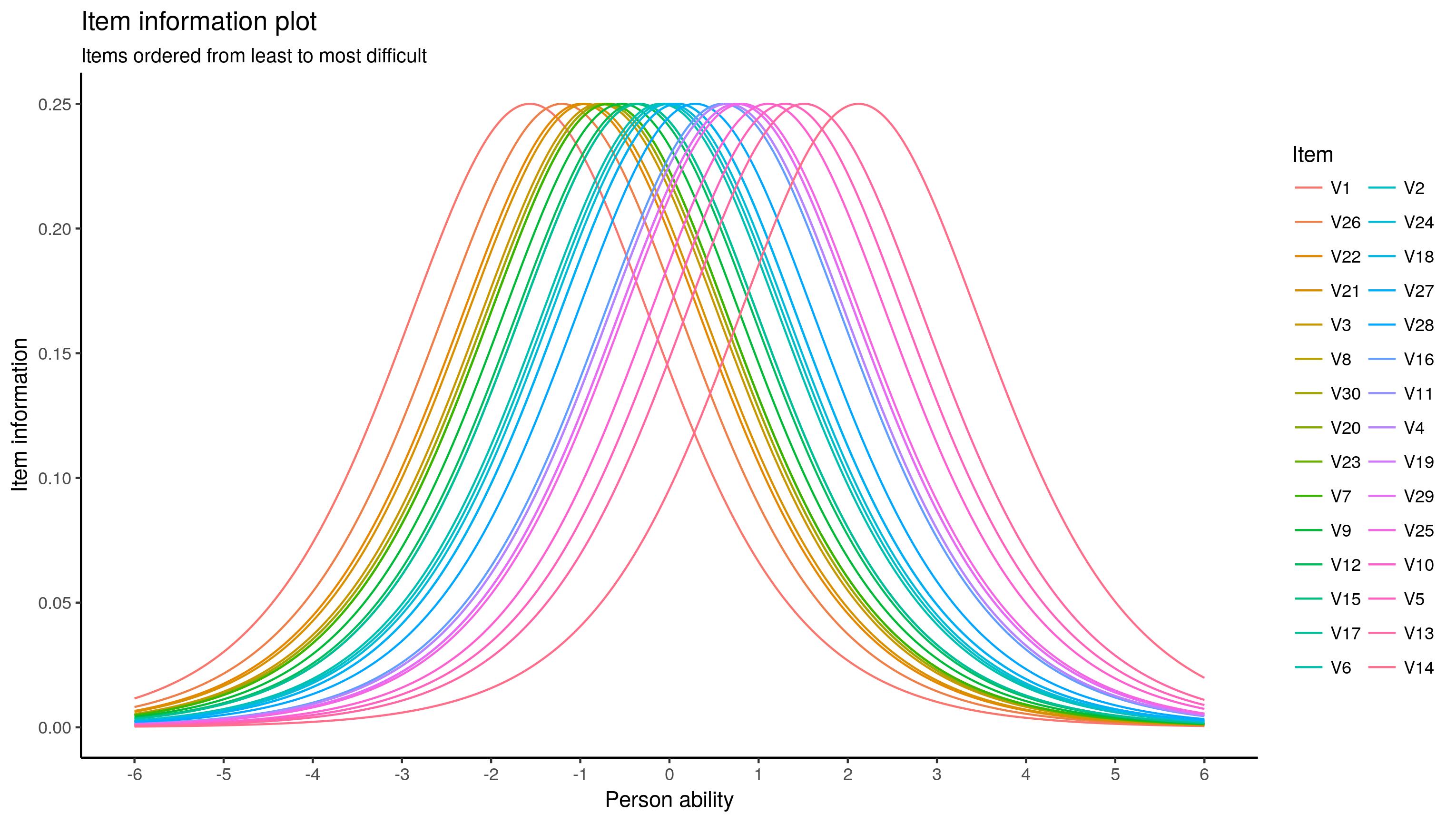
创建ICC计算测试信息时,我们已经完成了上述工作。对于总体测试信息,我们需要对每个项目的测试信息进行汇总:
![]() ?
?
![]() ?
?
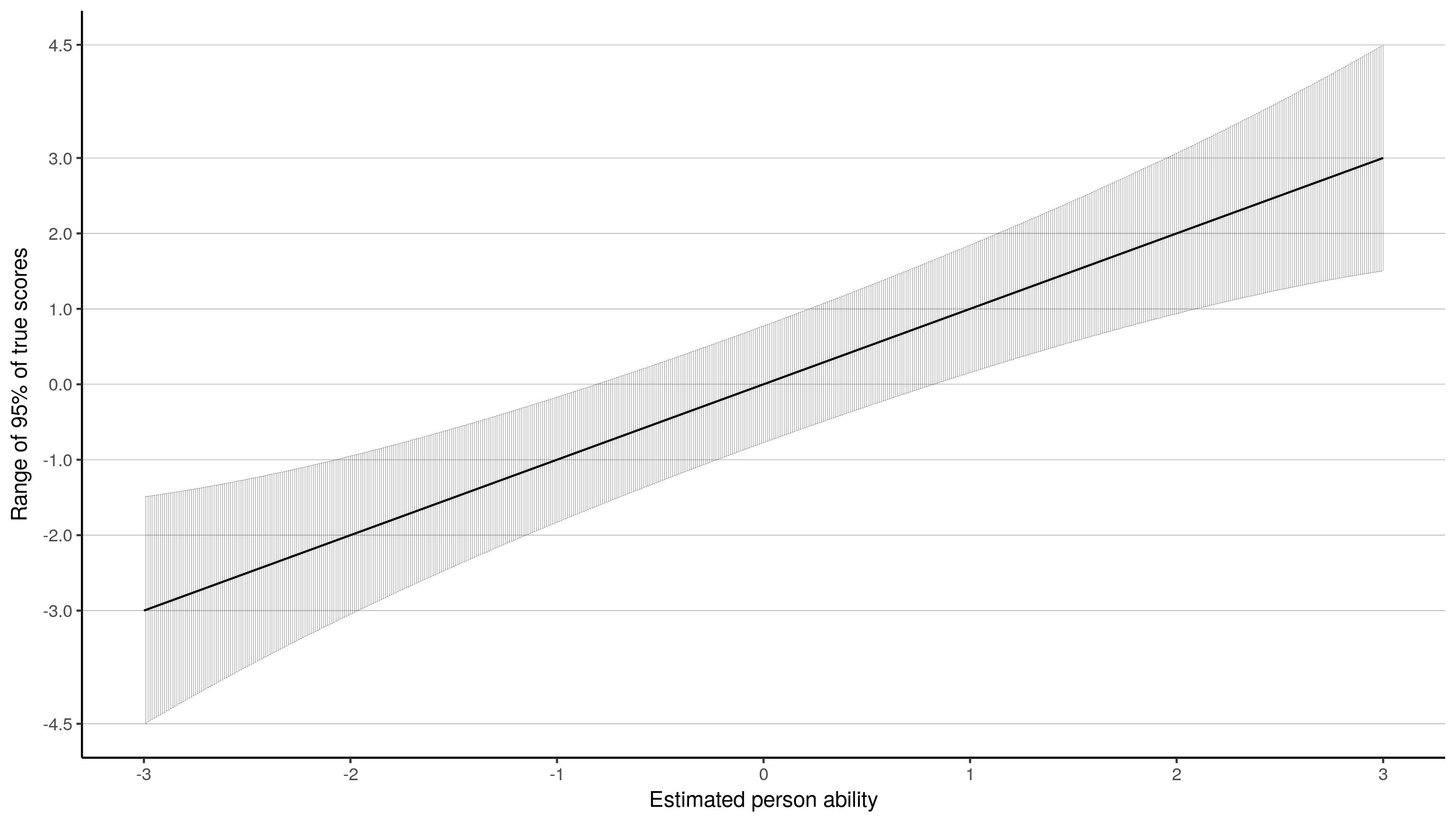
最后,我认为使用标准测量误差(SEM),您可以创建一个置信度带状图。SEM是测试信息的反函数。
![]() ?
?
该图表明,对于一个估计的能力为-3的孩子,他们的能力的估计精度很高,他们的实际分数可能在-1.5和-4.5之间。
经过这一工作,我觉得我可以更好地理解该模型试图要求一系列项目的内容,以及其中的一些内容诊断。
如果您有任何疑问,请在下面发表评论。
大数据部落 -中国专业的第三方数据服务提供商,提供定制化的一站式数据挖掘和统计分析咨询服务
统计分析和数据挖掘咨询服务:y0.cn/teradat(咨询服务请联系官网客服)
![]() ?
?![]() QQ:3025393450
QQ:3025393450
![]() ?QQ交流群:186388004
?QQ交流群:186388004 
【服务场景】
科研项目; 公司项目外包;线上线下一对一培训;数据爬虫采集;学术研究;报告撰写;市场调查。
【大数据部落】提供定制化的一站式数据挖掘和统计分析咨询



欢迎选修我们的R语言数据分析挖掘必知必会课程!

以上是关于R语言使用Rasch模型分析学生答题能力的主要内容,如果未能解决你的问题,请参考以下文章