《RefineMask:Towards High-Quality Instance Segmentation with Fine-Grained Features》论文笔记
Posted m_buddy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《RefineMask:Towards High-Quality Instance Segmentation with Fine-Grained Features》论文笔记相关的知识,希望对你有一定的参考价值。
参考代码:RefineMask
1. 概述
导读:在这篇文章中针对以Mask-RCNN为代表的实例分割模型存在实例分割mask掩膜边界补贴合的问题进行探究,文章指出由于网络存在下采样操作以及RoI Pooling的操作使得进行mask预测的特征图丢失了很多细节信息,进而导致了实例分割结果边界较差的问题。对此文章从如下几个方面对实例分割头部分进行改进:
1)直接使用FPN网络特征图输出的 P 2 P2 P2特征图添加几个卷积之后进行语义分割,从而辅助实例分割部分;
2)采用级联优化的形式,逐渐增加mask预测的分辨率;
3)对于边缘部分采用额外预测的形式,增强对mask边界的监督能力,从而起到进一步优化实例分割边界的作用;
在下图中对比了原始的Mask-RCNN方法、deeplabv3+为代表的语义分割,以及文章的实例分割结果:

从上图可以看到文章的方法相比原来的Mask-RCNN在mask部分呢是存在较大的改善的。
2. 方法设计
2.1 网络结构
文章的方法是在Mask-RCNN的基础上进行改进得到的,主要的改进便是在实例分割头的部分上,其对应的实例分割头见下图所示:

其对应的代码实现可以参考:
class RefineMaskHead(nn.Module)
结合上图其主要的作用可以划分为3个作用:
- 1)使用FPN网络特征图输出的 P 2 P2 P2特征图得到语义分割的mask和特征图,之后在不同的实例分割优化stage上使用RoI Pooling操作对实例分割进行优化。
对语义分割RoI Pooling:
ins_semantic_masks = roi_align(
_semantic_pred, fake_rois, instance_feats.shape[-2:], 1.0 / self.semantic_out_stride, 0, 'avg', True)
对语义分割特征RoI Pooling:
# instance-wise semantic feats
semantic_feat = self.relu(self.semantic_transform_in(semantic_feat))
ins_semantic_feats = self.semantic_roi_extractor([semantic_feat,], rois)
ins_semantic_feats = self.relu(self.semantic_transform_out(ins_semantic_feats))
concat_tensors.append(ins_semantic_feats)
- 2)使用级联优化策略将实例分割mask从分辨率从 14 ∗ 14 14*14 14∗14优化到 112 ∗ 112 112*112 112∗112;
- 3)使用BAR模对实例分割的mask边界进行优化;
2.2 mask级联优化策略
除了使用上述提到的语义分割分支的mask和feat之外,在级联的过程中还引入了SFM模块,其对特征图的操作流程见下图所示:

语义分割mask、语义分割feat、示例feat和上一个stage的实例mask组合起来进行融合,这里的融合采取的是带膨胀卷积的模块:
class MultiBranchFusion(nn.Module):
def __init__(self, feat_dim, dilations=[1, 3, 5]):
super(MultiBranchFusion, self).__init__()
for idx, dilation in enumerate(dilations):
self.add_module(f'dilation_conv_{idx + 1}', ConvModule(
feat_dim, feat_dim, kernel_size=3, padding=dilation, dilation=dilation))
self.merge_conv = ConvModule(feat_dim, feat_dim, kernel_size=1, act_cfg=None)
之后再将fuse_feat、语义分割mask、实例分割mask去和起来送入下一个stage,最后得到分辨率为 112 ∗ 112 112*112 112∗112分辨率的实例分割图。
SFM模块组成对性能的影响:

2.3 实例边界策略(BAR模块)
文章中将实例mask的边界取出之后但对进行回归预测,从而的得到更加精细化的边界效果,对于边界文章是采用如下的卷积核进行卷积。

在上图中定义的是
d
i
j
=
1
d_{ij}=1
dij=1的卷积核(这个参数是可以调整的,training和infer可以采用不同的值),那么进行卷积之后边界区域是通过如下方式确定:
B
k
(
i
,
j
)
=
{
1
,
if
d
i
,
j
≤
d
0
,
otherwise
B^k(i,j) = \\begin{cases} 1, & \\text{if $d_{i,j}\\le d$} \\\\ 0, & \\text{otherwise} \\end{cases}
Bk(i,j)={1,0,if di,j≤dotherwise
那么在图像中对应的描述如下图所示:
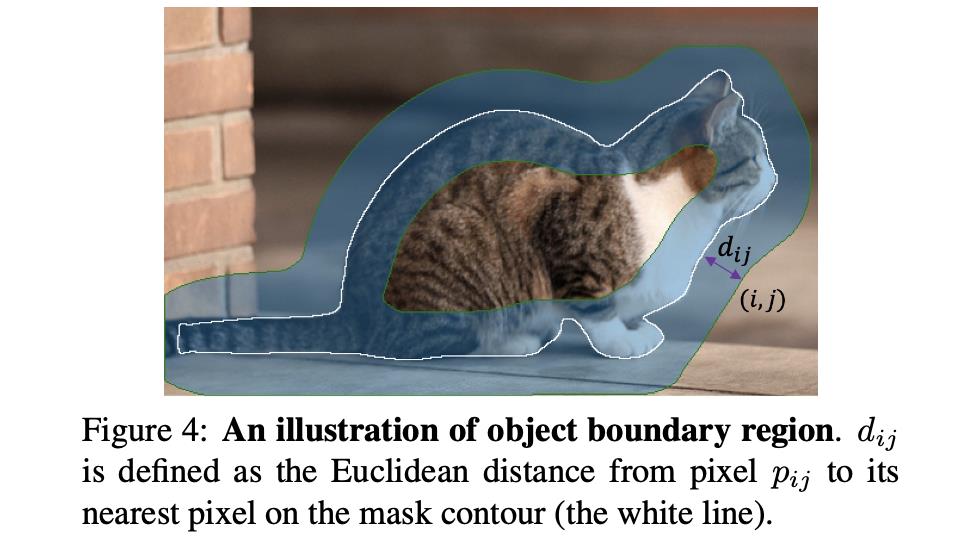
training过程:
在训练的过程中上述的边界mask除了采用GT之外还考虑上一层级的实例结果,则将边界mask描述为下面并集的形式:
R
k
=
f
u
p
(
B
G
k
−
1
∨
B
P
k
−
1
)
R^k=f_{up}(B^{k-1}_G\\vee B^{k-1}_P)
Rk=fup(BGk−1∨BPk−1)
那么loss的计算也只是考虑对应mask标记出来的像素:
L
k
=
1
δ
n
∑
n
=
0
N
−
1
∑
i
=
0
S
k
−
1
∑
j
=
0
S
k
−
1
R
n
i
j
k
⋅
l
n
i
j
L^k=\\frac{1}{\\delta_n}\\sum_{n=0}^{N-1}\\sum_{i=0}^{S_k-1}\\sum_{j=0}^{S_k-1}R_{nij}^k\\cdot l_{nij}
Lk=δn1n=0∑N−1i=0∑Sk−1j=0∑Sk−1Rnijk⋅lnij
infer过程:
在测试的时候其运算的过程可以参考下图:
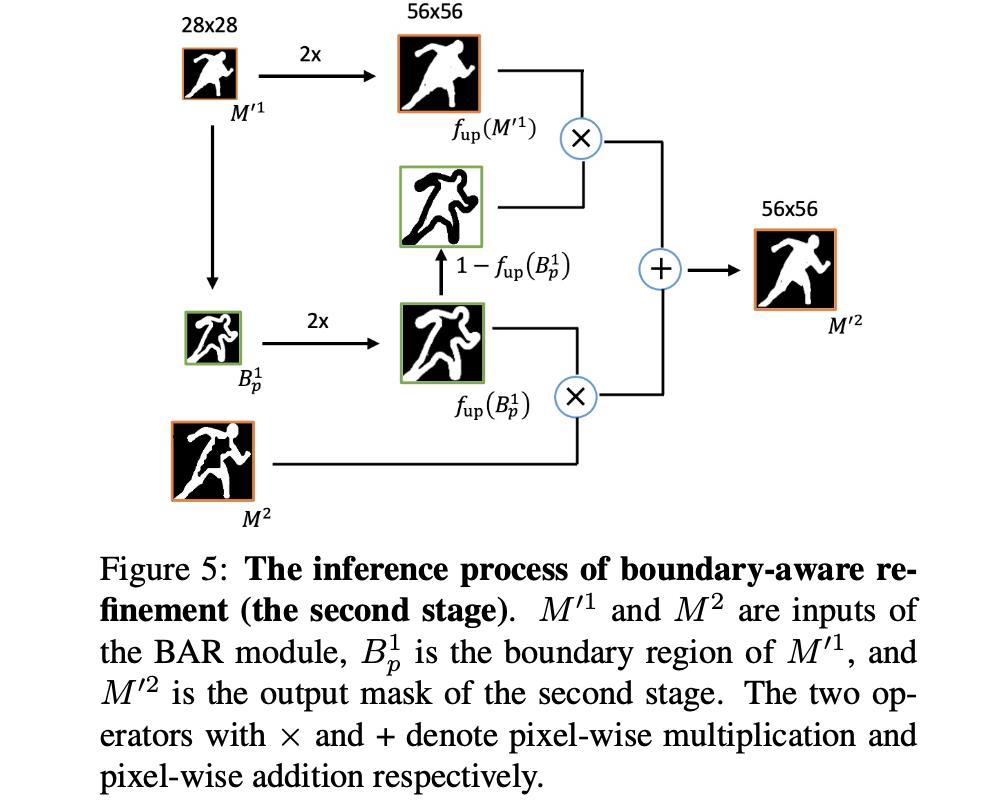
在上图中也就是将上一层的实例分割输出与当前层级的实例边界输出组合起来,数学表达为:
M
′
k
=
f
u
p
(
B
P
k
−
1
⨂
M
k
+
(
1
−
f
u
p
(
B
P
k
−
1
)
)
⨂
f
u
p
(
M
′
k
−
1
)
)
M^{'k}=f_{up}(B_P^{k-1}\\bigotimes M^k+(1-f_{up}(B_P^{k-1}))\\bigotimes f_{up}(M^{'k-1}))
M′k=fup(BPk−1⨂Mk+(1−fup(BPk−1))⨂fup(M′k−1))
上述级联优化stage数量对于性能的影响:
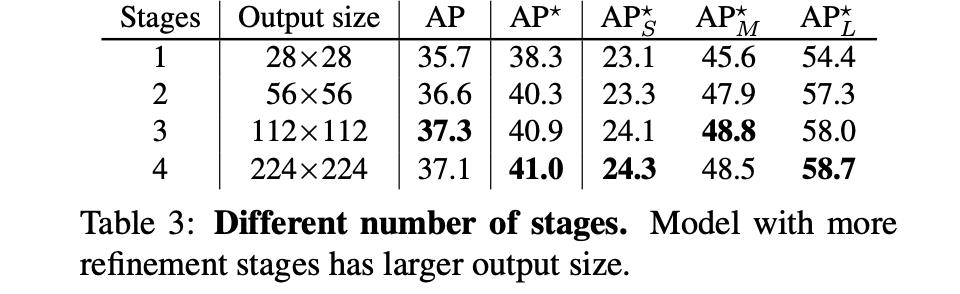
3. 实验结果
COCO2017 性能比较:
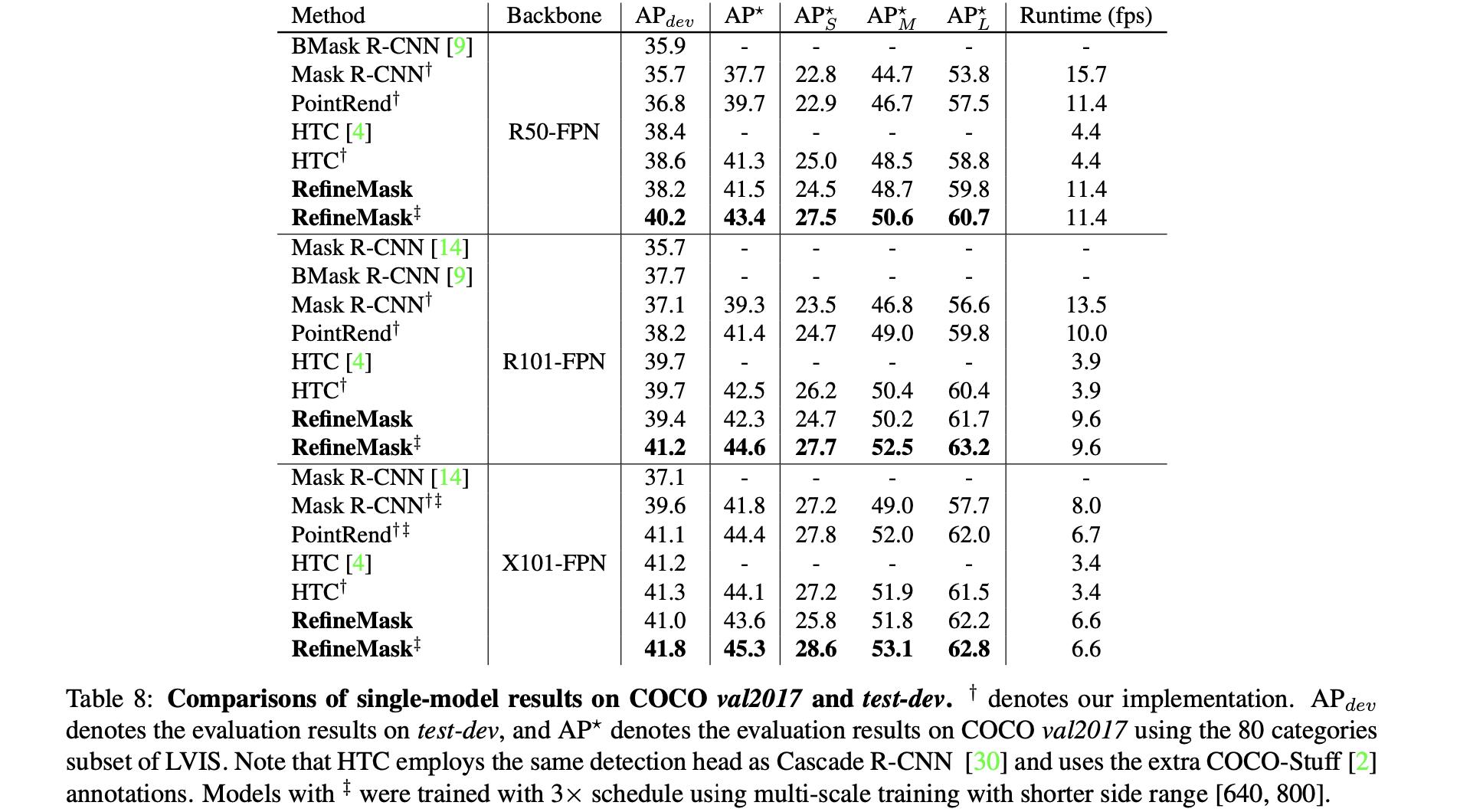
以上是关于《RefineMask:Towards High-Quality Instance Segmentation with Fine-Grained Features》论文笔记的主要内容,如果未能解决你的问题,请参考以下文章
Towards Deep Learning Models Resistant to Adversarial Attacks
Evolutionary approaches towards AI: past, present, and future
论文阅读 Towards Unified Surgical Skill Assessment
论文阅读CodeTrans: Towards Cracking the Language of Silicon‘s Code......
论文阅读CodeTrans: Towards Cracking the Language of Silicon‘s Code......