因果推断笔记——CV机器人领域因果推断案例集锦
Posted 悟乙己
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了因果推断笔记——CV机器人领域因果推断案例集锦相关的知识,希望对你有一定的参考价值。
之前一篇是写在数据科学领域使用因果推断的案例,因果推断笔记——数据科学领域因果推断案例集锦(九)
主要应用的领域在:智能营销、一些机制干预的有效性、智能补贴等,那么可以看看在不常见领域的案例,拓宽一下视野。
文章目录
- 1 自治代理和多代理系统
- 2 因果表征学习在CV领域的应用
- 2.1 Visual Commonsense R-CNN——改造Loss
- 2.2 Causal Intervention for Weakly-Supervised Semantic Segmentation
- 2.3 Two Causal Principles for Improving Visual Dialog
- 2.4 Long-Tailed Classification by Keeping the Good and Removing the Bad Momentum Causal Effect
- 2.5 Causal Imitation Learning with Unobserved Confounders
- 2.6 机械臂操纵任务,旨在解决强泛化问题
- 3 话题:多任务学习和持续学习
- 4 话题:因果强化学习 - Causal RL
1 自治代理和多代理系统
参考文章:
因果推理实战(1)——借助因果关系从示教中学习任务规则
因果推理实战(3)——利用因果方法学习工具的可供性
非常有意思的一个研究,当人类演示一个来自于内心构想的运动时,他们不仅仅是想表达这一条单一轨迹的路径,更会潜在地表达一些内在的习惯和规则,这条单一的轨迹只是具有相同规则特征的一类轨迹中的一个样本而已
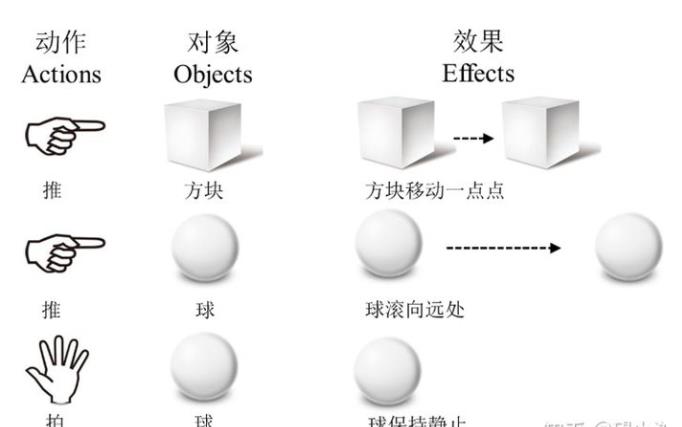
来简单看一下实验场景:

笔者标了一下,如何将机器人手里的瓶子放在另外一个瓶子旁边。
那么抽象成因果关系模型:
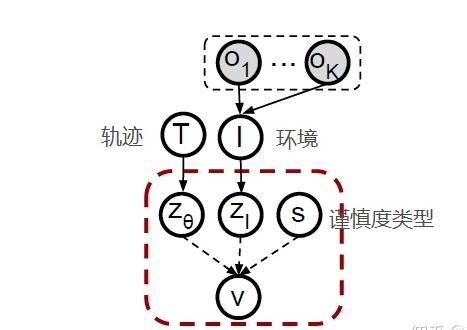
- 轨迹信息Zθ
- 环境信息Zi
- 用户偏好类型s(仔细,粗心,正常)
- o代表桌子上不同的物体(容器,盘子,碗,杯子)
- V表示轨迹所属的可行性的聚类

对于模型的因果分析,作者通过增加图片以涵盖特定新物体的方式进行干预,然后评价不同的用户类型会产生怎样不同的轨迹策略。
选择三种不同的用户类型时,在某场景下执行某轨迹可行的概率的期望。所以越“仔细”的用户,可行的概率越小,越“粗心”的用户,可行的概率越大(最大期望值为1,表示无论什么轨迹在什么场景下都可行)。

图7给出了三种不同的用户类型对应的轨迹及可行性聚类。
可以看到,这三条相同的轨迹在不同的用户类型下,被聚类的结果是不同的。 - “仔细”的情形下有两条都被聚类为不可行,
- “正常”的情形下有一条被聚类为不可行,
- “粗心”的情形下三条轨迹都被聚类为可行。

对于“仔细”的用户,无论增加什么新物品,都会让可行性降低,因为“仔细”的用户倾向于避开所有物品,所以只要增加了物品不管是什么,都会让可行空间变小。“正常”的用户则只倾向于避开玻璃杯,所以只有在增加了玻璃杯时才会对可行性有一个降低。“粗心”的用户心宽体胖,随便你加什么东西他都不在乎,任意轨迹都百分之百可行,所以最后一行全为1。
2 因果表征学习在CV领域的应用
这篇是一篇综述,会讲解几篇因果表征学习在 CV 领域的应用,各篇文章从动机、因果干预方法、具体实现方法三块介绍。
大致“套路”是:
- 1)从数据和现象出发,分析基线模型的因果图假设和混杂因子;
- 2)建立新的因果图(opt);
- 3)因果干预;
- 4)近似 do 算子网络计算;
- 5)效果提升。
话说回来,虽然脉络大致相同,但每个工作也都能给人新奇的感觉,尤其 [5] 想到从优化器的角度切入。
2.1 Visual Commonsense R-CNN——改造Loss
作者认为观察偏差(observational bias)导致模型会倾向于根据共现信息做任务预测,而忽略一些常识性的因果关系。因此本文希望通过因果干预训练一个蕴含常识的视觉特征,新的视觉表征可以方便应用于如 VQA、Caption 之类的下游任务。这里的视觉表征期望能学到一些知识,如“椅子可以坐”,而不是简单的根据观察得到的“桌子和椅子”的共现关系。
训练目标为预测指定 ROI 的类别,Loss 包括两部分任务,
- 1)Self Predict:直接 ROI 特征 x 通过全连接层预测其 label
- 2)Context Predict:基于待识别物体 y 的 ROI 以及其上下文物体 ROI 特征,预测 y 的 label,一张图片中 K 个上下文物体特征求和取评价。


另外一篇比较好的文章是:无监督的视觉常识特征学习——因果关系上的一点探索(CVPR 2020)
2.2 Causal Intervention for Weakly-Supervised Semantic Segmentation
文章通过通过 image classification 模型进行 CAM 种子扩张的方法存在明显的问题,得到的伪标签各物体边界并不清晰,影响分割模型的训练效果。文章认为这里的上下文(其他物体、背景)是混杂因子,误导图像级别的分类模型学到了像素与 label 之间的伪相关关系。举例来说,图像分类模型预测“沙发”的时候也会考虑与“沙发”经常一起出现的“地板”特征,并将“地板”的特征也作为预测“沙发”的相关依据。因此本文的目标则通过因果干预的方法消除混杂因子(上下文特征)对模型的影响。

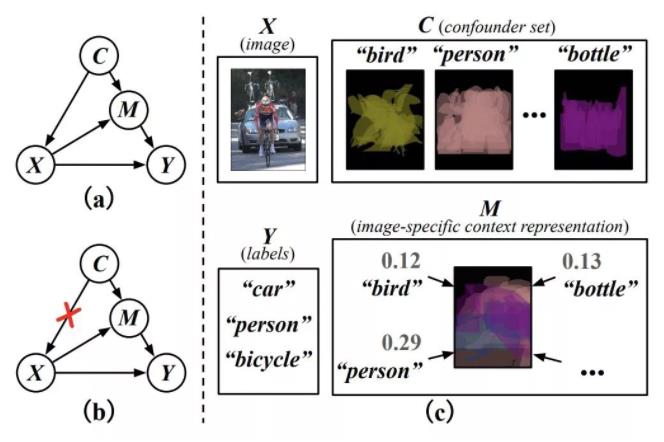
下图(a)是文章“设计“的结构化因果关系图:
C:上下文先验,这里为数据集所有的类别特征表示的集合,各类别特征表示为数据集中各类别所有特征的平均。
X:输入图像。
M:输入图像 X 在 C 下的具体表示,可以理解为以 C 集合中的类别特征表示为基表示 X,如 X=0.12“bird” + 0.13“bottle” + … + 0.29“person”。
Y:图像对应的标签。
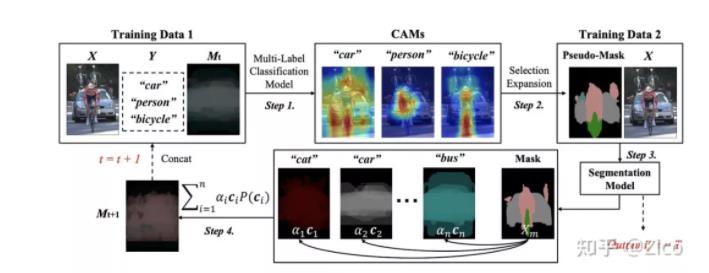
具体实现是一个循环的过程:
- 首先,通过初始化弱监督语义分割模型获取图像的 mask 信息;
- 然后,构建 Confounder set 并去除 confounder;
- 最后将去除 confounder 后的 M 拼接到下一轮的分类模型的 backbone 中以产生更高质量的CAM。
产生的 CAM 又可以用来产生更高质量的 M,以此形成一个良性循环。
如下图,P© 为先验的 1/n,T+1 时刻的 M 可以看作是一个 Confounder set 对 T 时刻 image Mask 的一个 Attention 表示。
题外CAM是什么?
CAM(类激活映射),CAM是一个帮助我们可视化CNN的工具。使用CAM,我们可以清楚的观察到,网络关注图片的哪块区域。比如,我们的网络识别出这两幅图片,一个是在刷牙,一个是在砍树。通过CAM这个工具,我们可以清楚的看到网络关注图片的哪一部分,根据哪一部分得到的这个结果。

2.3 Two Causal Principles for Improving Visual Dialog
主流的 VQA、VisDial 领域主流模型一般采用 Encoder-Decoder 结构,以 VisDial模 型为例:先是 Encoder 将 <I,Q, H> 编码为向量,然后利用 Decoder 解码得到 A(答案),Baseline 因果图如下:

其中 H 为历史问答、I 为图像、Q 为当前问题、V 是视觉知识表征、A 为答案。这样 VisDial 很像是带 History 的 VQA,而本文作者强调:VisDial 本质上并非带有 History 的 VQA,并提出两个因果原则给予修正:

- P1: 删除链接 H—>A:直接使用 History 作为输入建模 A 时,模型会过度关注历史问答的词汇和句式,二者不应该直接链接。
- P2:添加一个新的节点 U(标注偏好)和三条新的链接:U<—H, U—>Q, U—>A,答案标注者基于 History 进行标注会有一定偏好,倾向于标注历史问答中出现过的表达,是因果图中的混杂因子,且不可观测。
2.4 Long-Tailed Classification by Keeping the Good and Removing the Bad Momentum Causal Effect
如题,本文将因果推断应用于数据不均衡的长尾分类问题。文章先介绍了样本不均衡带来的预测偏置问题,而后分析了常用解决长尾问题的方法,如 re-sampling、re-weighting 以及目前比较优秀的 2-stage 模式的 Decoupling 方法(原始数据的长尾分布用 backbone 学,分类器用 re-balancing 后的数据学)。
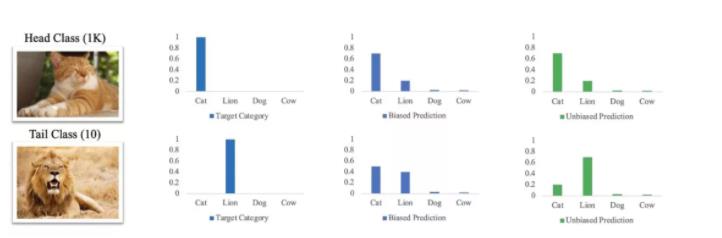
作者希望用更简单的方法 end2end 地实现长尾问题的优化,指出优化器的动量项在训练数据时会引入数据分布(混杂因子),是模型对头部类目偏好的一大原因。
但直接去除动量项,又会使模型收敛难度增加。因为动量可以大大提升训练的稳定性,其带来的好处要高于其带来的损失。
由此,文章另辟蹊径,提出用因果推断中的技术,尝试在保持动量项的同时,训练阶段引入因果干预,并在测试阶段进一步剔除预测偏置,做到取其精华,去其糟粕。
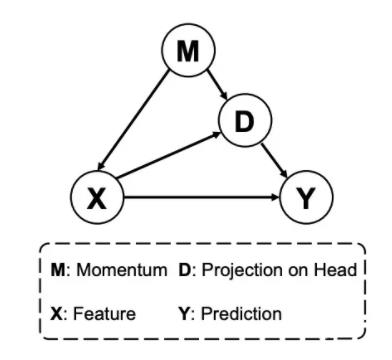
其中 M 就是优化器的动量,X 是模型提取的特征,Y 是预测值。
D 是 X 在动量特征下的带偏置的表示(基于 M 和 X 的特性 D 更偏好头部类别)。优化器的动量 M 包含了数据集的分布信息,他的动态平均会显著地将优化方向倾向于多数类,这也就造成了模型中的参数会有生成头部类特征的倾向,该部分偏好则体现在 D 中。
类似的,消除混淆因子 M 带来的头部类别偏置的方法也比较明确,即通过后门调整进行因果干预
2.5 Causal Imitation Learning with Unobserved Confounders
文章链接:https://causalai.net/r66.pdf
因果推断与模仿学习结合。
论文主要描述了在示教者和模仿者能够获得的观测信息不一致的条件下的模仿学习。
在Oracle-type的模仿学习中,示教者常常不是人,而是能够获得更得传感器信息的同类agent,示教者比模仿者多获得的传感信息作为混杂因子,同时影响示教者的行动和奖励。因此,即使是完美的模仿者,即使拥有无限量的示教数据,模仿者仍然无法达到示教者同样性能。这篇论文描述了存在混在因子的条件下的imitability——模仿可行性判别准则以及潜在的奖励的可识别性identifiability,而且给出了当模仿不可行时的解决方案。
2.6 机械臂操纵任务,旨在解决强泛化问题
文章:CausalWorld: A Robotic Manipulation Benchmark for Causal Structure and Transfer Learning
结合机械臂操纵任务,旨在解决强泛化问题,提供了开源github代码。
论文描述了通过干预不同因素(如块位置、目标位置、摩擦力、尺寸、位姿)等,结合课程学习实现泛化能力。实验分析了不同等级的随机化课程学习引起泛化能力的不同。
CausalWorld给出了一个可以干预多个不同因变量/因果因子的模拟实验框架,适合测试算法的各种泛化性能。
论文主要从强化学习领域出发,基本没有涉及到具体因果推断公式,对于强化学习研究者来说比较清晰易懂,提供的开源代码也方便实操,提供了一种便于研究泛化能力/隐变量RL的实验环境。
3 话题:多任务学习和持续学习
这个话题只是抛出来,是一个非常热门的趋势,但目前还没有特别好的应用。
我们已经在不考虑因果的情况下处理多任务问题很久了,并且取得了很多成果。于是一个关键的问题提出:“为什么我们不能训练一个巨大模型来学习环境的动力学,并且包含所有可能的干预呢?毕竟如果我们训练了大量的干预且我们期望神经网络可以在他们中泛化的话,分布式表征就可以泛化到没有见过的例子中”。
对此,有以下几点需要考虑。
- 首先,如果数据不够多样,最差情形误差总是会任意的高。尽管在短期内可以通过更大的模型和数据集来通过非OOD的基准测试,因果总是提供了一个重要的补充。
- 模型的泛化性能是和它的假设(结构及如何训练)紧密相关的,而因果提供了更明确以及符合物理和人类认知的假设,例如ICM原则。如果这些假设是有效的,使用这些假设模型理应比没有使用的要好。
- 更进一步,如果我们有一个对特定环境的所有干预都有效的模型,我们自然想要将它运用在动力学相似大不完全相同其他环境中。
因果方法恰好指出了,这样组需要将知识分解为独立可重组的机制。所以我们应该在模块化机器学习或者其他遵循ICM原则的机器学习方法上做更多的工作。
4 话题:因果强化学习 - Causal RL
参考:
Causal RL的基本setting
大致分为3种任务:
- online learning:主动去干预(do)来学习干预后分布p(y|do(x))
- off policy learning:看别人干预的数据来学习干预后分布p(y|do(x))
- Do-calculus learning:观测数据,不主动干预,但需要从观测数据中学习干预后分布p(y|do(x))
几个特别任务:
任务1:我们能不能借助观测数据来加速强化学习的过程呢?
毕竟观测数据是很容易得到的,但是干预的数据是非常少的。显然,如果你知道因果结构,并且该因果结构满足一定假设(X变量不存在confounder连接其直接孩子),那么从观测数据中计算出干预后的分布是可以实现的
然而,当因果结构不满足这样的假设时就不行了。如下图右边是真实结构,U是一个观测不到的confounder,此时我们没有办法计算干预后的分布的

虽然我们无法具体算出干预后分布的值,但是根据观测变量,我们是可以计算出干预后分布的bound的,换句话说,我们可以根据这个bound,来做一个类似reject的操作,如果落在外面就可以reject掉:

任务2:我们应该如何去干预?
我们需要对所有policy中的action同时进行干预吗?到底该如何去干预呢?是否有一个合适干预的时机呢?对于第一个问题,实际上很多工作都是这样做的,但从因果的角度来讲,同时干预是不需要的,并且同时干预会反而会使得最优的结果无法出现。
任务3:通过反事实来进行决策
我们不能仅仅去简单的干预,还要进一步考虑agent的真实意图,并利用这些意图来推导出conterfactural,并基于counterfactural的结果来给出最优的行为决策。
以上是关于因果推断笔记——CV机器人领域因果推断案例集锦的主要内容,如果未能解决你的问题,请参考以下文章