因果推断笔记——数据科学领域因果推断案例集锦
Posted 悟乙己
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了因果推断笔记——数据科学领域因果推断案例集锦相关的知识,希望对你有一定的参考价值。
文章目录
这部分只是抛砖引玉贴一些看到的非常好的业内方案。
因果推断在很多领域都有很有意思的应用,值得收藏。
1 腾讯看点:启动重置问题
来自datafuntalk -【2-1观测数据因果推断应用-启动重置体验分析】
1.1 观测数据 、 实验数据的理论介绍

前提假设,用户是随机分配的;
ATE是在实验数据中,Y(1)-Y(0)
rubin potitential outcome -> 实验数据
DAG,因果图 -> 观测数据,不过观测数据比较麻烦

工具变量、IV变量、断点回归 -> 绕开了混杂银子,在业务层面更容易满足 -> 准实验方法
实在不行,才是PSM,IPTW


曝光天气与未曝光,本身就有有偏的,曝光的人本来要比未曝光要更容易接受,或者在有干预
所以,不能直接使用次留的结论,
那么,DID这里需要满足平行性,就可以进行对比
二次差分得到一个效应

为了因果效应的正确性,就是要看,天气内容之后的转化路径,就是次留提升不够,
还要看内容有没有配套的文章资讯,天气的点击率;
今天发了天气内容 -(验证的方式)> 第二天天气资讯内容的点击率如何
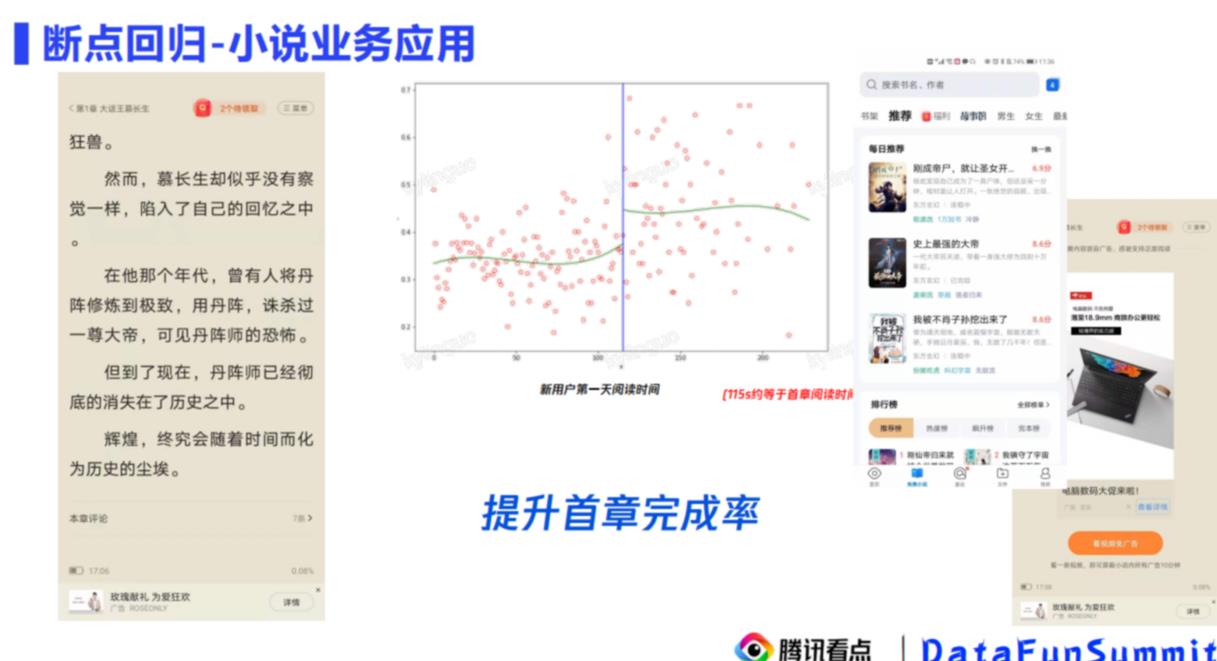
横轴是首章阅读时长,纵轴是次留数据;
115s连续邻域左右,混淆因子作用差别不大,如果这个点有很大的差异,那么说明确实是有因果关系的
提升 首章阅读时长 -> 提升次留
措施:
- 第一次推荐的,是比较容易读的
- 里面的广告啥的,都关掉
2.2 启动重置问题阐述:短期、长期、异质
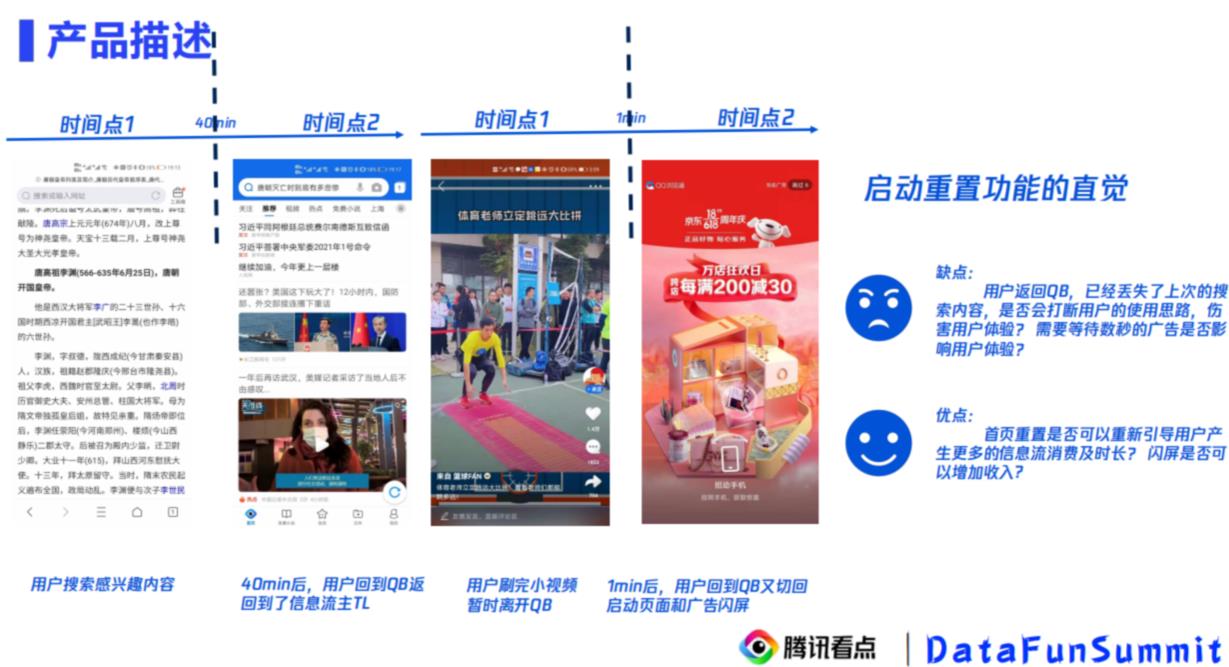
浏览器里面,你刷起来APP里面去了,过了40分钟回来,又让你重新搜一遍,
app里面,你离开了1min,又有闪屏
当然,有闪屏说明可以很好的有商业收入

分析框架:
-
短期表现捕捉方式:被打断之后,下一次使用的使用时长、跳出率等指标,是否会有波动
-
长期表现捕捉方式:一段时间的打开次数
-
是否存在一些人群(异质性人群),对广告不敏感,有or没有闪屏都无所谓
-
短期影响,访问间隔是在40min左侧,还是在右侧,那么可以使用断点回归
-
长期影响,有可能受很多混淆变量影响,PSM,混淆控制的方式去处理;
但是PSM,matching的方式,很容易被挑战,有很多混淆因子,那咋解决?
异质性用户,一般会用uplife的方法,但是Uplife方法是实验方法,那在观测数据中如何进行实验?
2.3 短期影响的解决

横轴,跳出时长;纵轴:session使用时长 、 session搜索时长
观察在跳出时长40min,前后是否有明显的差异
2.4 长期影响构造准实验

很难控制混杂因子,因为你可能不知道还有什么因子被遗漏了,PSM问题:
- 局部性,样本只代表一部分,不是整体
- 遗漏混杂因子
如果,我们控制了一段时间内,活跃度(访问次数一致),
- user1属于高频低日活,每次来访问,停留时长比较长,各种切换;但不是每天都来
- user2属于低频高日活,每天都来,但是每次就一会儿就走了
那么每天都来,但是来一会就走的人,有没有重置,没有关系
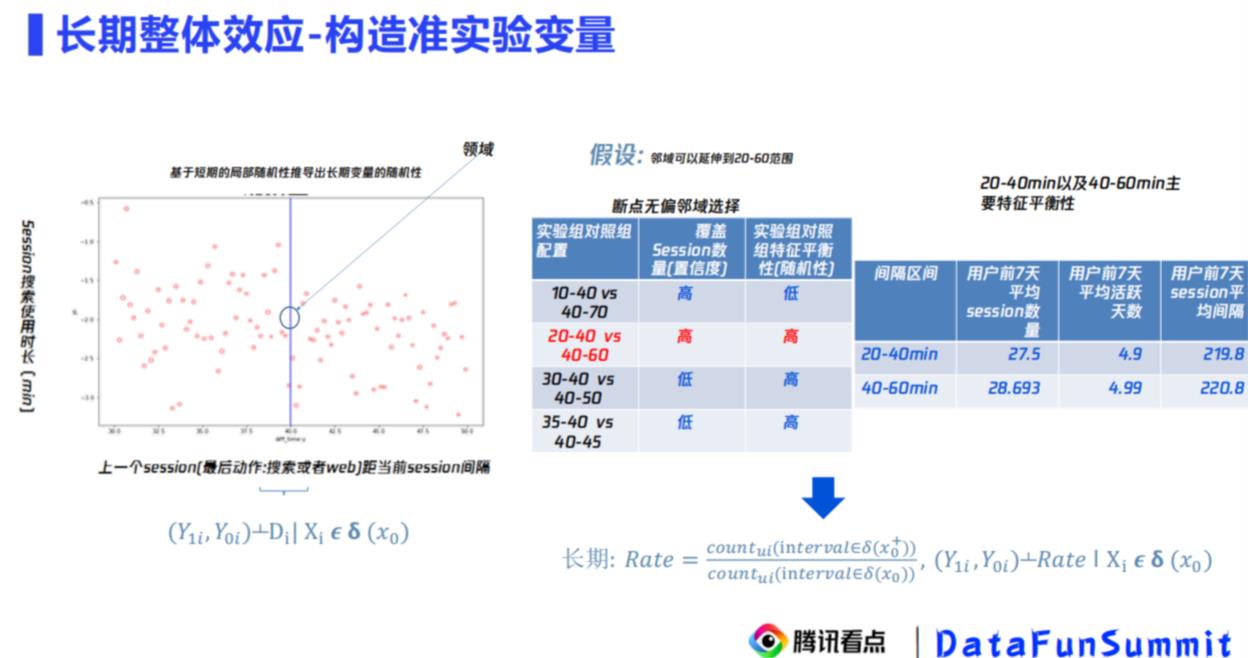
解决遗漏混杂因子的问题,这里构造了准实验变量,
如果我们在40min作为一个实验点来观察40min以内与40min以外,
用户是很难感知,这个40min是个什么时间段的,那就把40min这个点变成领域(时间段)
如果找领域范围呢? 越大,实验越多,但越不精准;所以这里考察了两个指标:
- 覆盖session数量:数量也比较多
- 特征平衡性:几个时间特征都差不多
这样用户行为落在[20,40] ,[40,60]是随机事件,可以构造一个长期时间变量rate(生存分析里面有时变函数,构造一个跟着时间走的变量)
这个准实验变量:Rate = (40-60min) / (0-60min)
现实含义是?
- 长时间跳出的比例(低使用时长)
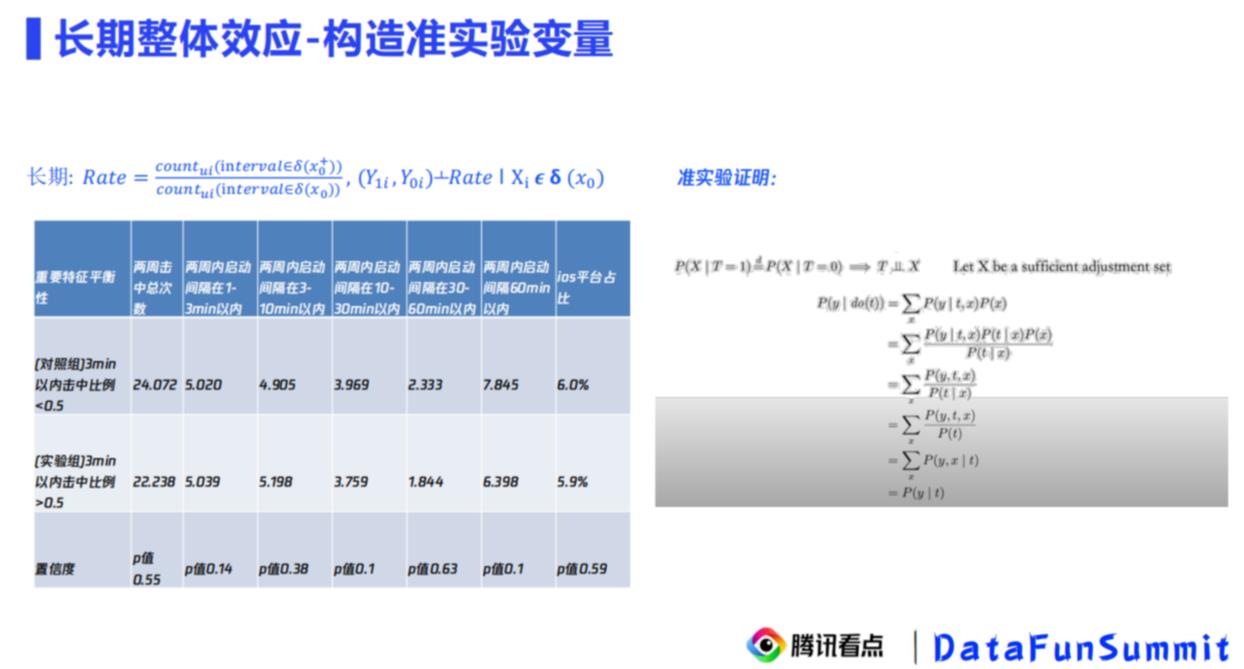
特征平衡性检验,就是要看,这个IV变量 -> X是独立的,可以后续进行使用

Rate ~ 活跃天数Y的关系
rate ~Y的相关性就是因果性,
击中率Rate,经常长时间跳出的,越大;活跃天数越大
被启动重置打断的次数越多,那么活跃天数的比例就低
2.5 异质性用户

整个异质性的探究,其实是相当于对人群进行细分,然后针对不同的人群进行不同的策略;
这里每个人身上的行为标签非常多。
需要针对,不同行为下,是否主动打断,造成了最终活跃度/收入/信息流时长/搜索时长 有改变(多种行为 -(干预:打断)> 多结果 )

方法的调研,从四个方向去调研方法论,从下钻分析(从大区分析 -> 城市)与建模对比,肯定是建模好;
那么建模又分为mete-learner / direct uplift model / transform outcome / mr-uplift(不可逆),这里沿着transfrom outcome进行改造。

算法目标以及流程:
- 数据处理之后,tranform转化Y(时长)/G(使用天数)
- 两个模型:Y 、 G分别拟合模型,modelY~(X,Y*)
- 输出模型的重要特征top15
- 画出象限,得到定性的结论
- 根据定性,进行定量

评估准确性的方法,gini面积,catboost比线性好

搜索时长、总时长是两个模型,Y/G,根据两个模型的结果画出:搜索时长、总时长的象限,
四个象限其实就代表着不同人群分类,1-无影响人群,3-严重影响人群,2/4-分别影响人群
同时对四个象限进行下钻分析,找到不同象限的不同指标的差异,结论:
- 1~2象限对比,会减少搜索时长的因素里面,发现第二象限搜索占比指标高,说明在干预重置下,影响搜索时长的是搜索占比,也就是页面重置 会对搜索的人产生影响
- 1~3象限对比,第1象限打开方式多种,第三象限主要是主打打开,也就是如果是主动打开的人,重置会有影响
前面的看细粒度维度的指标是一种定性的方式,现在针对是否主动打开,可以跑出这些Outcome指标,看一下是否有均值统计量的差异(这里可以根据数据,构造一些简单的均值检验)
这里有人问,为什么要定性解释和定量解释?
演讲者解释的是,定性解释,会受异常值影响,毕竟象限分析比较粗粒度,有好的样本,有坏的样本;定量是辅助解释 + 排除定性解释的问题,并且定量可以更加准确 + 多维度的解释
这里,笔者觉得就是,估计效应有了,要具体计量出ATE估计量一样

得到了一些结论,异质性分析可以帮助拆分行为,进行精细化策略。
同时发现,重置对搜索用户影响非常大,如果搜索的用户,需要产品设计上进行改动,告诉用户,之前查看的内容放在了哪里。
1.6 总结

2 滴滴的国际化外卖团队DiDi Food:智能补贴
2.1 补贴问题的定义
与机器学习传统三大方向【推荐,搜索,广告】不同,补贴问题中最核心和最关键的一点是补贴这个行为需要付出【成本】。这个概念的引入使得我们必须要将对这部分【成本】的使用效率作为一个核心指标,也就是所谓的「ROI」。

也就是衡量增加的补贴【成本】所带来【增量】指标收益。
对于这个指标的优化,一个直观的解法就是随机AB实验,通过足够多的,设计逻辑严密的,随机性完美的AB实验,我们一定可以在这个指标的优化上取得令人满意的结果。但是这个方法在具体业务中的问题是它太过于奢侈了,无论是在预算还是在时间上。
因此,为了可以高效低廉地求解这个问题,我们可以将优化目标拆解为两个子问题:
- 预估干预的Action相比于没有干预时带来的【增量】
- 在存在多种干预【Action】和已预估了它们【增量】的情况下,如何为每个用户合理分配【Action】以期望达到全局最优
如何判定合理的用户,就需要区分:

补贴敏感:
没有补贴就不下单,有补贴才会下单;补贴敏感人群。
自然转化:
有没有补贴都会下单;自然转化人群。
无动于衷:
有没有补贴都不会下单;
反作用:
无补贴时会下单,有补贴时反而不会下单;补贴活动带来反作用。
这块可参考:智能营销增益(Uplift Modeling)模型——模型介绍(一)
2.2 如果进行因果推断建模
与智能补贴相关的工程架构如图:

使用方法是mete-model系列,具体可看:因果推断笔记——uplift建模、meta元学习、Class Transformation Method(八)
补贴活动提升的购买意愿 = P(Y = 1|X,W = 1) − P(Y = 1|X,W = 0)
模型选择:LightGBM
在实践中使用的方法是用一个新的LightGBM去拟合离线评估最优模型产出的【预测增量】,并用这个新模型的特征重要度来近似评估各个维度特征的重要性,以此来决策是否加入和剔除特征。选择LightGBM的原因是我们对于这个模型的精度并没有太高的要求,相反我们希望它能够比较快速地在训练流程中对新加入特征的给出反馈。LightGBM高效地训练速度和不需要过多特征工程的优点比较契合我们的需求。
对于因果推断三大假设的思考:

其中,针对其中第二条假设,我们的个人理解是我们虽然允许有影响分配机制的特征存在,但是我们需要将这些特征也纳入我们的观察。在模型干预的数据样本中,影响干预分配机制的往往是模型产出的【预测增量】。这个特征我们没有也无法将其纳入我们的观察。因此,我们将这部分样本从训练和测试样本中剔除了。
这点在数据结果上也可以看出,对于同一个批次的样本,同一套参数同一套模型,评估样本中【干预后样本】的存在会导致离线评估的结果大相径庭,从而影响我们离线评估和判断模型优劣。
另外在同一个测试样本上,有该类【干预后样本】样本参与训练的模型的离线效果也出现了比较明显的下降。
这里有点疑惑,感觉有干预的人群有太多的混杂因素、人为规则判定是“有潜力的”;所以接下来是补贴实验都是基于无干预的人群。
从他们实验结果大概也看到,S-Learner比较好,且无干预比较准确

2.3 在干预下的全局最优解问题
这个部分很少有人提及,有点像是归因 -> 预算分配这样的,将模型的效用更大化。
对增量预估完毕后,接下来就需要具体地为用户池中用户分配补贴券。在基于增量预估的基础上,我们尝试了两种分发策略:
贪心分配
很多时候,运营对于使用的券类别和每个券类别的预算分配都有比较大的限制和约束。在这样的约束下,我们的做法是按照券值面额从低到高,为每个券类别计算可支配数量,然后对用户池所有用户按照预估出的Uplift值和计算出的可发放数量倒排截断,并将分配完毕的用户从备选用户池中移除。这样一个用户如果在各种券类别下uplift都很高时,我们将会优先为他/她配置券值较低的补贴券。这样做法的好处是简洁明了实现简单,在人工干预较强的时候对于运营的可解释性也比较强。缺点当然就是在自由度更高情况下,显然不能达到全局最优。
整数规划
而当我们对于预算和券种的设置拥有了更多的自主权时,我们也尝试了在预算约束下的最大化求解,具体的求解公式如下:

2.4 有意思的地方:如何定义业务指标
这里是我看到比较有意思的,业务 - 技术团队的博弈后的指标产物
在解决补贴问题时,时常会困惑如何能合理地解释策略干预的结果,尤其是在与前线运营同学交流的时候。ROI固然是正确且合理的指标,但是我们可以设想这样一个场景,客单价为100,空白组GMV为1000,补贴为0,策略组发放了一个抵扣面额为10的券,最终核销了2张,GMV为1200,补贴为20。那么通过ROI计算公式可得,策略组ROI为200/20=10。与此同时,运营同学发放了一个抵扣面额为20的券,最终核销了10张,GMV为1800,补贴为200,那么运营组的ROI就是800/200=4。从钱效角度出发,当然是策略组干预策略更优秀,但是对于运营同学而言,这次活动确实是他们的策略带来了更多的GMV和单量。

而且,运营同学会自然想到的一个原因是因为策略组使用的券种抵扣额度更低,所以ROI会更高,而一旦有了这样的思路,整个过程就不可避免的走向了设计更为复杂且需要运营侧策略侧高度配合的实验。这与我们想高效低廉的解决这个问题就完全背道而驰了。
因此,我们在这个问题上最后的结论是,ROI是一个非常优秀的业务指标,但为了保证策略的可解释性,它不能作为唯一指标。
我们锚定了运营同学更为关注的直接指标【规模:GMV,单量】【成本:补贴】,并通过加入约束条件和人工干预的手段,使其中一个维度与运营组策略对齐的同时,观察另一维度指标的提升,也既前面提到了两个大的目标方向【相同单量,更少补贴】和【相同补贴,更多单量】。
也就是说,我们只会在【相同补贴】或者【相同单量/GMV】这样的条件下,才去谈论ROI。
也只有在这样的情况下,ROI这个指标的说服力才会显得更加强大。
这里也是一种干预的思路,在券 -> ROI里面,单量/GMV是混杂因子,然后要控制住,进行分层。
2.5 有意思的地方:如何定义模型指标 AUUC
AUUC是一个很重要且奇怪的指标。说重要,是因为它几乎是Uplift Model在离线阶段唯一一个直观的,可解释的评估模型优劣的指标。说奇怪,是因为它虽然本质上似乎借鉴了分类模型评价指标AUC的一些思想,但是习惯了AUC的算法工程师们在初次接触的时候一定会被它搞得有点迷糊。
作为在分类模型评估上的标杆,AUC的优秀不用过多赘述。其中最优秀的一点是它的评价结果稳定到可以超越模型和样本本身而成立,只要是分类问题:
AUC0.5是随机线,0.6的模型还需要迭代一下找找提升的空间,0.6-0.8是模型上线的标准,而0.9以上的模型就需要考虑一下模型是否过拟合和是否有未知强相关特征参与了模型训练。
一法抵万法,我们可以抛开特征,样本和模型构建的细节而直接套用这套准则。
然而这个特点对于AUUC就完全是奢望了。
通过AUUC的公式可以看出,AUUC最终形成的指标的绝对值大小是取决于样本的大小的。也就是说,在一套测试样本上,我们的AUUC可能是0到1W,而换了一套样本,这个值可能就变成了0到100W。
这使得不同测试样本之间模型的评估变为了不可能。
也使得每次模型离线的迭代的前提必须是所有模型都使用同一套测试样本。
当我们训练完一个新的模型,跑出一个40万的auuc,我们完全无从得知这个值背后代表着模型精度如何,我们只能拿出旧的模型在同样测试集上跑出auuc然后相互比较。这无疑让整个训练迭代过程变得更痛苦了一点。
我们也尝试了从多个角度去解决这个问题,希望在增量预估模型中建立一套类似auc的标准,但无一例外都没能成功。
包括像AUC那样除以曲线的理论最大面积,但是看公式就可以知道,这个理论的最大面积其实就是样本个数的平方而这么一除之后得到的AUUC也失去了比较的价值了。
2.6 他们接下来想优化啥
- 更好的模型指标,能否在增量预估模型中建立一套类似auc的标准
- 离线 -> 线上,把离线的决策模块部分推至线上并引入更多的实时特征和接入更多的发券场景(首页天降红包,进店未下单等等),并将其直接包装为一个简单可解释的运营工具
- 优化模型,在增量预估模块,我们会持续迭代优化模型。在尝试引入更多维度,信息更丰富的特征的同时,与深度学习模型融合,提高模型精度。
- 用户在其整个生命周期探索,当前框架下的算法策略几乎只是针对每一次活动希望求得全局的最优化。而在实际运营中,一个健康的补贴生态一定是去优化用户在其整个生命周期的收益的,所以对用户长期价值(LTV)的建模也是个值得规划和探索的方向
3 QQ 浏览器:PUSH配额优化实践
参考:基于Uplift-Model的QQ 浏览器PUSH配额优化实践

PUSH系统 -> uplife的使用,这里的干预是PUSH下发的条数,outcome 是转化增量收益

不同活跃度人群(1/2/3/4/7日活跃)在PUSH数量下的UTR,大致看到9条以上UTR会有所下降

这里使用的meta-learning模型,因果增强模型,比较少见的将偏序关系、metric learning增强用户特征表示用到模型之中。

这篇的来看,考察的业务指标还是CTR/UTR 这类的。
文章可以看:Push Notification Volume Optimization Based on Uplift Model at Tencent Mobile QQ
Browser
笔者一时没找到,后续看到了再研读一下。
4 腾讯
4.1 腾旭看点:信息流实验分析
来自:【信息流实验分析实践】的演讲,其中少量章节提到了uplift modeling,这里简单贴一下相关的几页:
信息流的实验背景:
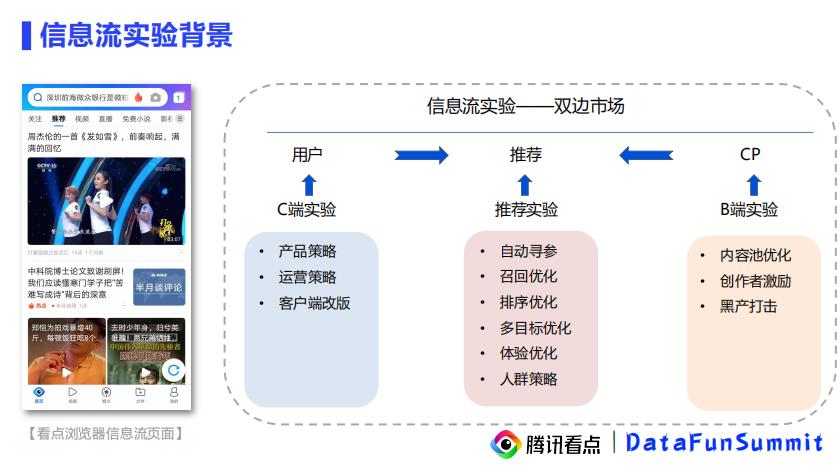


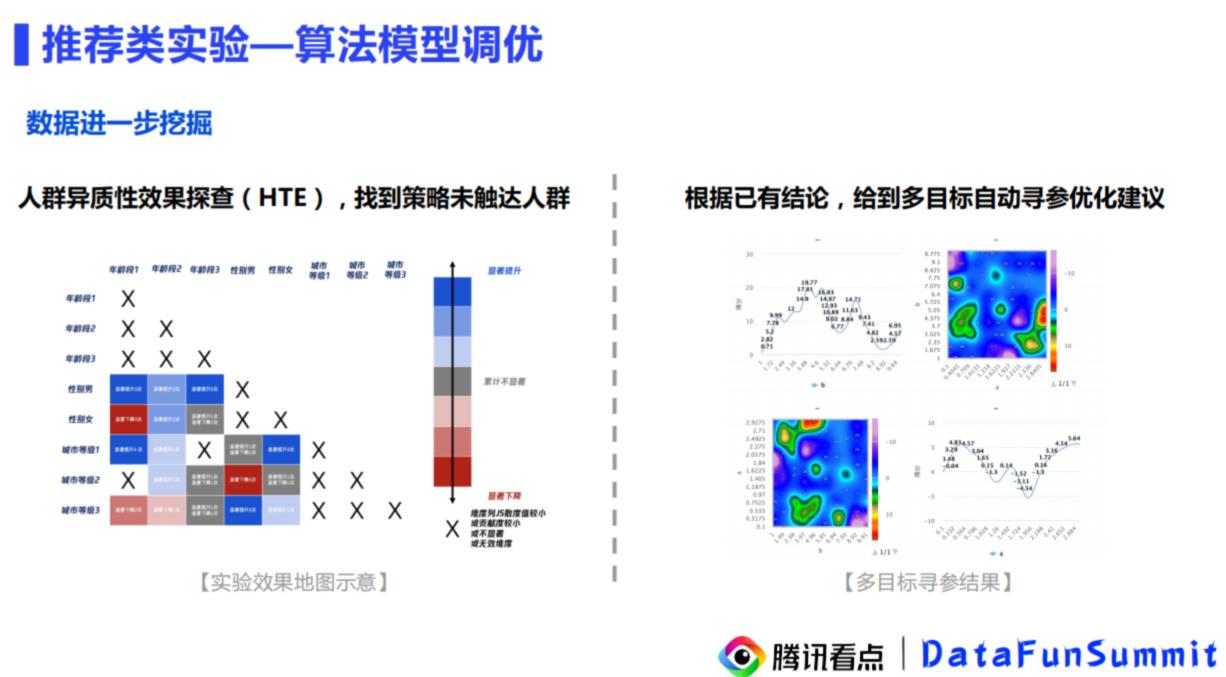
来仔细看一下分析角度:

将性别 、 年龄、城市进行拆分。
4.2 腾讯微视:数据算法驱动的用户增长
来自2020先行者大会:数据算法驱动的用户增长



5 滴滴
5.1 因果建模在滴滴的应用实践
来自演讲【大数据驱动的因果建模在滴滴的应用实践】
这篇主要偏科普因果推理知识为主。
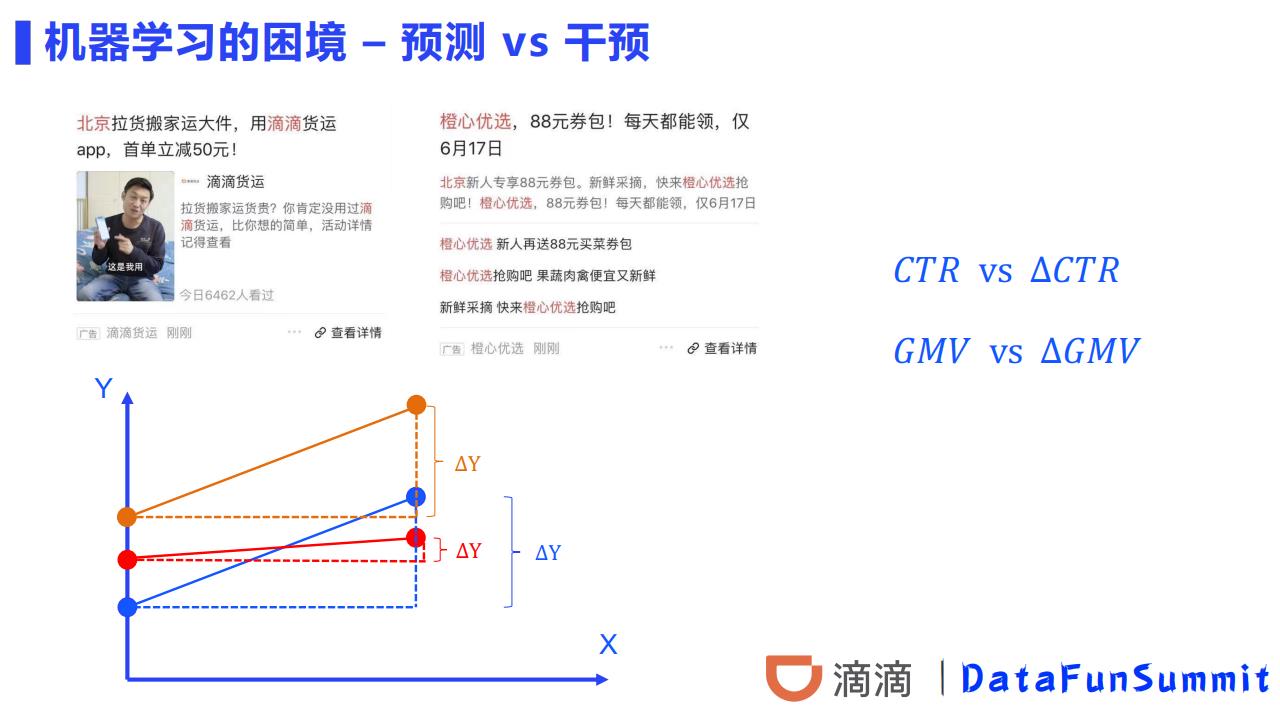

观测数据和实验数据各有优劣

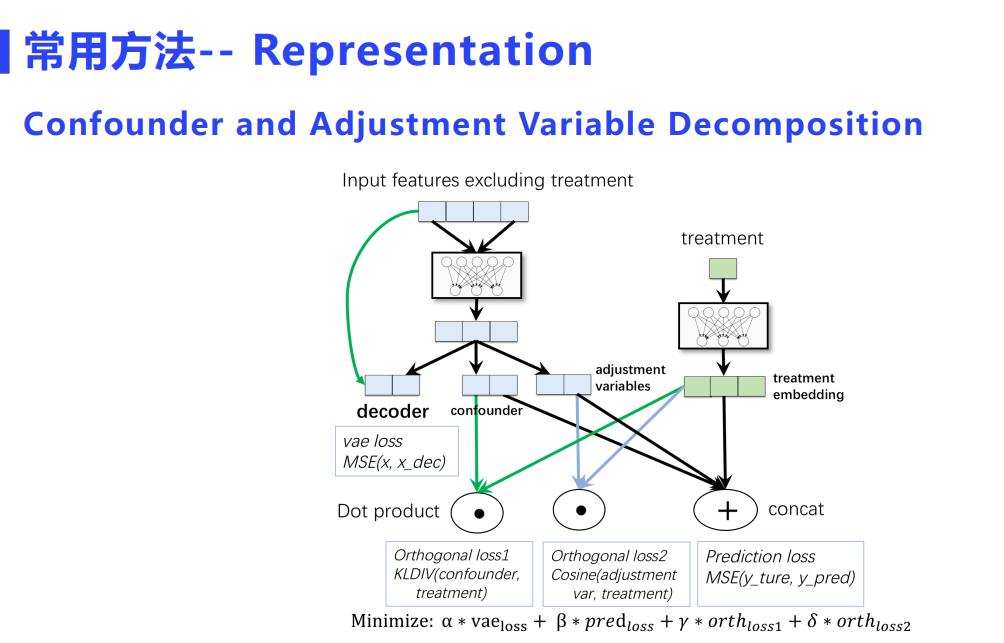
这里有一些表示学习的介绍。

5.2 网约车供需策略技术基础能力团队
来自文章:滴滴是如何构造连续因果森林模型并应用在交易市场策略上的?
该篇主要是针对Uplift中,Tree-Based的因果森林模型,且主要就,干预从二分类 -> 多分类 -> 连续进行讨论: 连续因果树
目前市面上大多数流行的增益模型框架(如CausalML, pylift, grf),都很好地支持了二元处理变量(如发券或不发券,吃药或不吃药)的效应估计。
但在多元/连续处理变量方面,尚未有很好的支持。然而,在广大的应用场景中,多元或连续的处理变量更为普遍。在二元因果森林的基础上,我们扩展研发了连续因果森林
因果森林(Causal Forest)是由Susan Athey、Stefan Wager等人开发,专门估计异质处理效应的机器学习模型,是当前增益模型领域最为流行的算法之一。
因果森林以随机森林为基础,通过对特征空间进行重复划分(Recursive Partitioning),以达到局部特征空间的数据同质/无混淆。在一定的假设下[1],我们就可以得到各个维度上异质处理效应(Heterogeneous Treatment Effect)的无偏估计。
5.2.1 二元因果森林

即我们希望从协变量中,找到一个最优分裂节点,最大化子节点间处理效应差异。
在节点内,我们认为所有样本同质,因此可以应用公式(1)进行处理效应的计算。如此重复分裂,直到满足一些预设的停止条件(节点最小样本值、处理变量不平衡度、最小信息增益等),完成一棵树的构造。
二元因果森林的多元处理效应估计:

优点
- 易于实现,无需额外开发;所有二元处理效应模型均适用;
缺点
- 当处理变量值较多时,会产生大量模型,增加训练和部署成本;
- 数据利用不充分,单个模型只用到部分(2/(k+1))数据;
- 不同处理效应间无关联。这在部分场景中并不合理,例如我们认为价格和供需存在单调关系;
- 无法对未出现在数据集中的对照变量值进行推断。
5.2.2 连续因果森林
在定价策略中,所有的模型归根结底都在拟合价格曲线。在需求侧,我们可以合理假设价格曲线具有如下特征:
- 单调性:价格越高,需求越低 ;
- 局部线性:在局部价格区间内,价格与需求呈线性关系。

树模型的一个优点在于,在节点内部我们可以自定义统计量的计算方式。
利用价格需求曲线的特性,我们对节点内的样本(W1,Y1),(W2,Y2),…进行线性回归,然后以线性回归得到的斜率代表连续处理效应。
在模型的预估/推断阶段,为了跳脱出线性假设的约束, 在估计各个对照处理效应的时候,我们退回之前的定义,仅选取对应的对照/参照变量值样本计算对应的处理效应。
因此在我们的连续因果森林模型中,整体的CAPE仅被用作分裂,不会用于效应估计。
优点:
- 考虑了不同处理效应间的关系
- 充分利用数据,不同处理变量间可以互相学习
- 单一模型,减少训练/部署成本
缺点:
- 使用中需考察线性假设的合理性
5.3 数据驱动下经济学与因果推断
来自文章:双边平台的增长,与因果推断的应用
这边主要从经济学以及整体数据驱动视角,来看因果推断如何在数据驱动中进行。
之前很少从经济学的角度来看数据科学、因果推断,所以值得一读。

** 一个新定义:多边平台 **
经济学家把平台类商业模式,或者说撮合供需两(多)端交易的商业模式统称多边平台(Multisided Platform)。
科学的分析框架:KPI (主要是规模、体验)= f(供给量) + g(需求量) + u(匹配效率)。
现在平台,大部分精力会放在:需求量 + 匹配效率,供给量会次于前两者。
6 优酷:推荐系统与因果推断
6.1 面向用户增长的信息流分发机制
文章来源讲座【面向用户增长的信息流分发机制】
主要内容是信息流:

简单摘录一些跟因果推断相关的。

Youtube net的问题:user embedding average pooling导致本质上其实依然是item-based。
后续的诸多改进没有本质解决消偏问题。

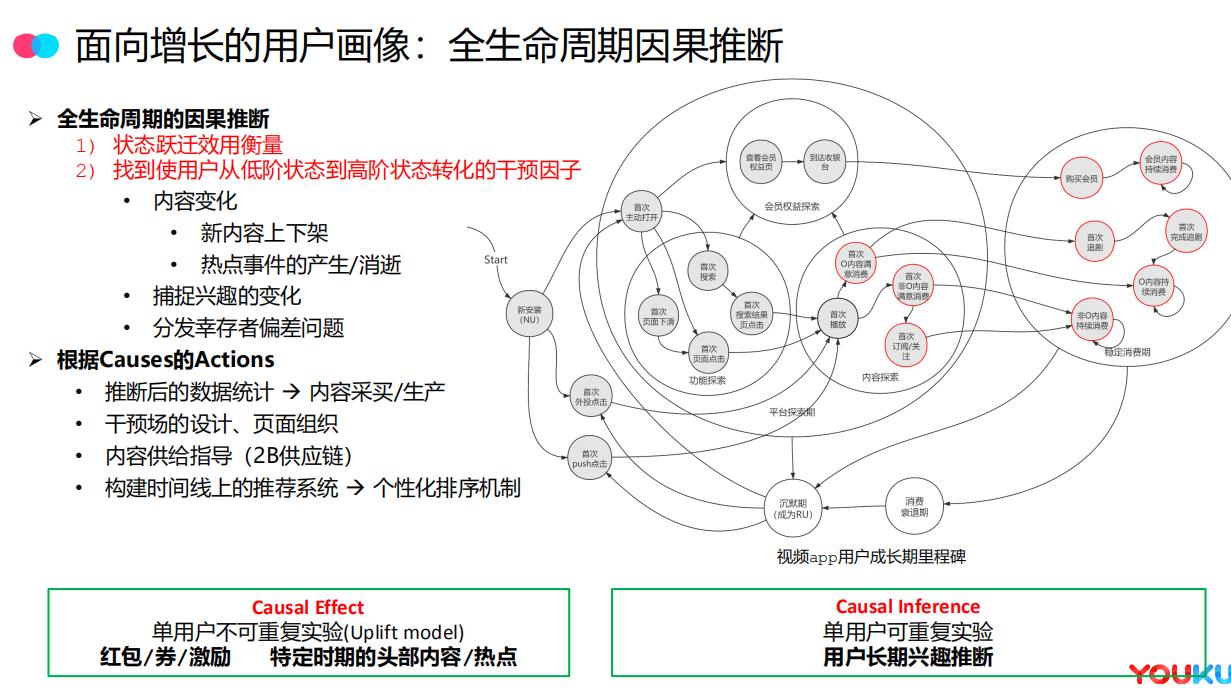
全生命周期的因果推断这个概念蛮赞,找到使用户从低阶状态到高阶状态转化的干预因子(热点、兴趣等),可以优化的目标和场景也很多(内容采买、设计页面组织等)
两个用途:
- 单用户不可重复实验(Uplift model,可RCT):红包/券/激励 特定时期的头部内容/热点
- 单用户可重复实验(观测数据):用户长期兴趣推断
6.2 因果推断在阿里文娱用户增长中的应用
来自文章:因果推断在阿里文娱用户增长中的应用
用户增长和智能营销算法的目标
刚刚已经介绍了优酷用户增长的业务打法和构思,其中已经提到,个性化的分发算法是实现用户增长的主战场。其中有两大目标:
- 目标1:用户状态建模。深度建模用户状态和行为,从大数据集中找到使用户从低阶状态到高阶状态转化的干预因子。
- 目标2:个性化算法的升级。将用户行为建模后,在多个场景将这些干预动作落地为个性化推荐算法和营销算法,满足和刺激用户的视频内容消费需求。
6.2.1 用户画像与状态表示法
传统的用户画像表示技术要么服务于运营可解释性,要么服务于推荐或广告系统的模型预估,通常建模成向量 ( 离散高维或低维稠密 )。而我们在深入研究在线视频和付费会员业务后,发现状态转移图是更有力地建模该业务下用户画像的数据结构,原因如下:
- 用户从非会员到购买会员并逐步进入高阶会员的阶段,本质属于一种强规则定义的状态。
- 在线视频,尤其是长视频领域具备长时间、连续型消费 ( 追剧、追网红 )
等特点,对比传统的图文推荐系统、电商推荐系统和广告系统,用户的消费行为可以在连续的时间上进行切分,状态表示法是对向量表示法的有力补充。 - 新用户的承接和推荐策略是用户增长中"促留存",建立心智的重要阶段。

首先是多目标的排序机制,对于在不同状态下的用户,个性化算法的机制目标会不同 ( 跃迁至目标态 );其次启发我们从更前沿的算法高度来研究状态跃迁的干预手段问题,进而解决推荐系统中长期难解的"可解释性"、“幸存者偏差”、"兴趣探索"等问题。
针对干预手段的研究,在2019年用户增长 & 智能营销团队组建之后,对因果推断 ( Causal Inference ) 算法率先进行了研究和落地,目前在个性化推送、外投 DSP 应用了基于 matching 的无偏 user-cf 算法,智能红包发放场景应用了 uplift model,取得了显著的核心业务指标提升,并得到了业务方和兄弟团队的一致认可。
6.2.2 基于因果推断的无偏 user-cf 设计
因果推断的核心研究课题:
- 从众多观测到/未观测到的变量中找出致因 ( causes )
- 预估某个行为/因素的影响力/效益 ( causal effect )
① 构建 Counterfactual 镜像人:
利用无偏信息构造相似度量,构造低活 user 到高活 user 的 matching:
- 基础人口属性、安装的长尾 app 信息等
- 主动搜索行为 ( 非被动推荐 ),尤其是长尾 query
② 去除低活用户的 leave causes,推荐相似高活用户的 stay causes。对于推荐系统来说,这些 causes 包括:
- item 本身:但缺少泛化容易推出老内容
- item 的泛化特征:标签、时效性、质量

由于使用了 matching 方法,这里的算法非常类似传统的 user-cf 类算法,但是和传统 user-cf 核心的区别在于: - matching 不使被动推荐数据,个性化推送、站内推荐、运营推荐的内容都不使用。
- 只匹配低活到高活,活跃度相同的用户之间不进行匹配。
该算法落地后,在两个 baseline 相对较高的算法场景中取得了较大的收益:其中个性化推送 ( push ),在沉默用户中获得了 50%+ ctr 和 50%+ click 的双增长,在外投 dsp 业务中,拉活量对比峰值接近翻倍。
7 阿里飞猪:因果推断在广告算法中的实践
来自文章:
因果推断在阿里飞猪广告算法中的实践
我们通过引入因果推断技术,将广告投放建模为对搜索产品的干预 ( intervention ),直接预测广告投放与否对业务目标产生的uplift效应,作为下游优化问题的线性奖励 ( rewards ) 或约束 ( constraints ),以支持各类线上策略。

7.1 三种解决CIA问题的方式
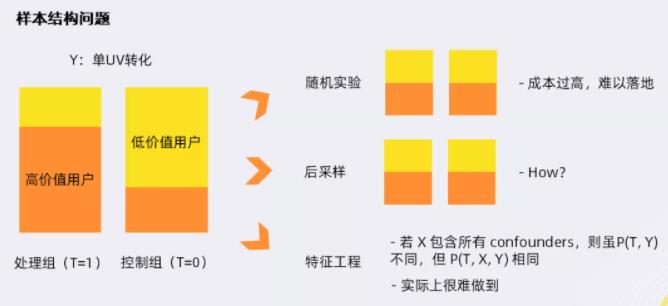
有3种方法可以解决这类问题:
① 随机实验
- 选取部分流量,线上广告随机投放,不采用任何策略
- 成本过高,难以落地
② 后采样
- 通过重采样方法,使两组样本分布一致
③ 特征工程
- 机器学习常用方法
- 假设X包含所有的confounders,则虽然两组样本的P(T,Y)不相同,但P(T,X,Y)相同
- 实际很难做到,且对样本也有较高要求
7.2 解决方式一:找到所有混杂因子
针对CIA假定,目标是捕捉到所有的confounders(即影响到广告是否投放,以及影响到我们的平台效率的所有特征)。
这里文章里面把消除假定的方法叫做:特征工程
例如广告的CTR/CVR预估模型;该类模型对广告效率的预估,会预先将原始的复杂特征做汇总。基于此,整体的思想就是基于原生的广告搜索模型做迁移学习。

除了刚刚详细介绍的CTR/CVR,特征工程还包括广告系统中常用的Search Rank Queue(原生产品队列)、用户画像等,在此不做赘述。
7.2 样本重采样 —— Matching
这里文章把matching叫做观测数据重采样
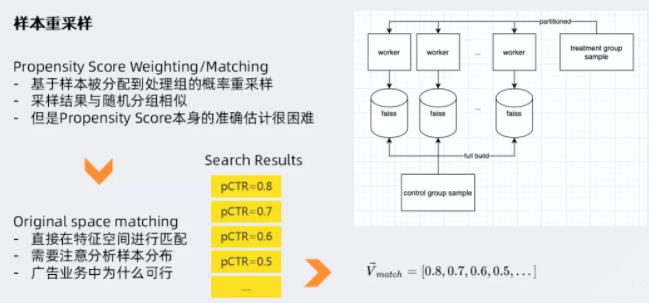
样本重采样常用的方法包括:
- ① Propensity Score Weighting/Matching(倾向评分加权/配比法)
- ② Original Space Matching(原始空间匹配法)等
7.3 uplift模型的评估——barplot + AUUC
因果效应模型的评估,和常见其他用户模型的评估相比,最大的难点在于,每个样本都没有相反label。
对于这类问题,业界常用分位数分析法进行评估,即对于每一类样本,按照广告效应的预测值,从大到小来进行分桶(上图左侧,分了十个桶);每个桶内聚集广告效应的预测值相近的样本(包含不同的label);将每组样本内的label的平均值相减,得到该组样本的uplift。

上图是个理想的情况:左侧贡献比较大,右侧贡献比较小,甚至是负的。基于柱状图做累计分布计算,得到下图:

这个图和常规预估模型中的ROC曲线形似;同样,曲线下的面积(AUC)越大,模型预估效果越好。
7.4 NN-Base的uplift 模型

将所有特征都连到一个DNN里面,采用了ResNets的思想,如上图所示:左侧网络对用户搜索请求预期的转换效率进行建模,右侧网络对“广告是否投放”产生的影响进行建模,最后通过线性模型加以合并。对于广告效应的推断方面,这种模型相比于DNN会有一定的提升(uplift Qini指数提升至0.6)。
还有几个不列了。。
8 哈啰顺风车从推荐 -> 智能营销
这篇里面提到了哈罗主要的ML平台架构,如下:

8.1 用户运营周期

对于平台的用户来说,一般都会经历拉新,促活,防流失,召回挽留等阶段。对于每个阶段来说,我们希望有对应的营销算法和触达手段来激发用户在平台的活跃度与忠诚度,同时也能提升公司的钱效,用好每一笔钱。
这里面涉及3个问题,
- 第1个问题是:给什么样的人发券,即圈人阶段;
- 第2个问题是:圈的人给什么样的权益,比如是5块钱还是10块钱;
- 第3个问题是:通过什么样的文案来触达用户,这里面就涉及智能文案的问题。
8.2 给什么样的人发券——Uplift model

整个模型迭代的三个版本:
- v1版本,是从response model开始。去预测用户的出行概率,然后根据出行概率来制定不同的发券策略。
这里面会出现自然转化的用户也发放了优惠券,导致钱效不高。 - v2版本,我们通过v1版本发券积累的数据,来尝试了uplift增益模型,对发券和不发券对用户带来的增量进行建模,然后根据这个增量来实施发券策略。
这里面有个缺点是,发券的金额仍然没有做到用模型cover住,钱效仍然不是很高。 - v3版本,我们通过预测不同券的核销概率,与使用不同券的增益值,来通过运筹优化的问题解决券金额发放千人千面的问题。
v2版本开始关注人群细分:
- 第一类是营销敏感的人群,这类人是下单犹豫不决,需要券来刺激一把。
- 第二类是自然转化的用户,不管发没发券,这个人第二天都是有出行需要的。
- 第三类是无动于衷,发不发券都没反应,
- 第4类是发券可能会起反作用,比如券可能是站内push的方式来发送,用户可能觉得太烦了,直接app关闭推送功能。
这4类人中我们要抓住的就是第一类人,营销活动的重点人群。
这里有针对uplift model有一些实验:

除了meta-learning外还尝试了Tree-Based,uplift model 下的树模型通过对增量直接建模,对特征点进行分裂, 将 X 划分到一个又一个 subspace 中,那划分准则与传统的决策树信息熵或者基尼系数不一样,这边主要是采用分布散度或者CTS分裂准则。
nn-based我们还没有尝试,他是将propensity score估计即倾向性得分和uplift score估计合并到一个网络实现。
8.3 圈的人给什么样的权益
v3版本有提到,要借由运筹学给不同人配不同券 :
比如xij 代表第i个用户是否发放第j种券,那约束条件是:每个用户至多发一种劵,以及所有用户的发券总和不能超过实际预算,优化目标可以是所有用户的增益值最大,也可以是gmv最大或者roi最大等
运筹优化的求解主要是整数规划,整数规划目前采用谷歌的ortools来求解。但是优化器当求解参数上千万时,性能就出问题了,要算十个小时左右,这是不能接受的。目前的解决方案是分而治之,通过分城市来求解优化器,因为每个城市间的用户相对来说是相互独立的,互不干扰。
9 阿里文娱:智能营销增益模型 ( Uplift Model ) 技术实践
一些细节也可参考:智能营销增益(Uplift Modeling)模型——模型介绍(一)
文章来源:阿里文娱智能营销增益模型 ( Uplift Model ) 技术实践
9.1 Uplift Model建模评估

uplift评估最大的难点在于我们并没有单个用户uplift的ground truth,因此传统的评估指标像AUC是无法直接使用的,解决的一个思路是通过构造镜像人群的方式来间接拿到uplift的ground truth,比如说经典的AUUC的指标就是这样去计算的,假设现在有两个满足CIA条件假设的样本组,我们可以对两群人分别预估他们的uplift score,之后将人群按照uplift score进行降序排列,通过score分数这一桥梁,可以把两组人群进行镜像人群的对齐,之后分别截取分数最高的比如10%的用户出来,计算这一部分人转化率的差异,这个差异就可以近似地认为是分数最高的这群人真实的uplift,类似地,我们可以计算前20%,40%一直到100%的点上面的值,连线就能得到uplift curve。理论上如果模型对uplift的识别比较准确,我们预测uplift比较高的区间段,真实的uplift也较高,uplift curve就会呈现上凸的形式,我们也可以计算曲线下的面积度量不同模型的表现差异。
9.2 Uplift Model在淘票票智能票补中的应用

该项目的目标是希望对进入到首页的用户个性化地发送红包,实现在预算和ROI的双重约束下提升平台总体购票转化率。我们的权益就是首页的红包,红包的使用规则、红包类型、预算和交互样式由产品运营设计,算法的作用是实现人和权益的精准匹配,我们需要确定应该给哪些用户发放以及发放哪种类型的权益。

因此问题就精细化到如何对用户进行个性化的面额发放上,这可以通过经典的背包问题来抽象,如图所示,第一个公式是我们的目标,最大化的是红包撬动效率,下面的约束条件一个是ROI约束,一个是预算约束。
9.3 如何uplift建模
建模中control组我们取的是随机化实验中的基准组,这部分用户是不进行红包发放的,而treatment组选用的是随机化实验中专为uplift model建模预留的一小部分随机探测的流量,之所以没有用有算法干预下的样本是因为用户的发放的面额与用户的特征是强相关的,并不满足CIA条件,因此这一部分样本虽然量较大,但是不能用于训练。
