因果推断笔记——入门学习因果推断在智能营销补贴的通用框架
Posted 悟乙己
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了因果推断笔记——入门学习因果推断在智能营销补贴的通用框架相关的知识,希望对你有一定的参考价值。
废话文学一下:入门学习因果推断三周,总算是入了个门…
本篇先总结一下之前三周的学习成果,然后就着智能权益方面的两个问题(给什么人发券? + 发什么券?)简单总结一下两个问题的通用框架
来集结一下前十篇分别是:
因果推断笔记——因果图建模之微软开源的dowhy(一)
因果推断笔记—— 相关理论:Rubin Potential、Pearl、倾向性得分、与机器学习异同(二)
因果推断笔记——python 倾向性匹配PSM实现示例(三)
因果推断笔记——双重差分理论、假设、实践(四)
因果推断笔记——因果图建模之微软开源的EconML(五)
因果推断笔记——工具变量、内生性以及DeepIV(六)
因果推断笔记——自整理因果推断理论解读(七)
因果推断笔记——uplift建模、meta元学习、Class Transformation Method(八)
因果推断笔记——数据科学领域因果推断案例集锦(九)
因果推断笔记——CV、机器人领域因果推断案例集锦(十)
这是本系列的第十一篇,算是一个中期阶段的汇总篇:
- 第二+七是理论贴,一开始看各种合集教程会发现大家用的名词相当混乱,特别是核心的假定(Ignorability、Unconfoundedness )。后面慢慢捋,又写了第七篇。
- 三+四+六+八都是因果推断中比较重要的方法,尤其是uplift是工业界兵家必备;
- 一+五是因果推断中比较成体系的开源项目,这里不得不佩服这些开源的作者,好的开源项目真的是最好的学习材料,包括之前学习生存分析的lifelines,这些项目把 完整全面的理论、代码实践都融入到项目之中,而且高度凝练成为理论框架,dowhy + econml(或uber的CasualML )组合是YYDS!
- 九+十,是两篇收集而来的案例集锦,收益良多,绝对给力。
后续可能会继续学习的方向:
- 把 EconML 、 CasualML 这两个非常赞项目的案例都过一遍;
- 一些更细方法的学习,比如断点回归、uplift的tree based 、 NN-Based的方法等
- 因果推断与A/B 实验平台
- 一些新领域的关注:因果强化学习、多任务学习、因果表征学习等
接下来,主要结合各类案例来简单总结一下因果推断在数据科学方面的应用,主要参考:
因果推断笔记——数据科学领域因果推断案例集锦(九)
1 分析型:因果推断在智能决策中应用
从腾讯看点的『观测数据因果推断应用-启动重置体验分析』,QQ浏览器的『QQ 浏览器:PUSH配额优化实践』,还有快手的『快手因果推断与实验设计』
里面都用因果推断在智能决策中进行应用落地,在这个方向中,可以使用的方法非常多,直接抄一下腾讯看点团队总结了非常给力的通用框架:

当然还有从政策评估角度出发的整理,不过只有四类:

在是否有实验数据下,进行拆分,特别是实验数据可获得性非常差,所以这个时间,IV 、 DID、PSM的matching的方式就异常重要,比如:
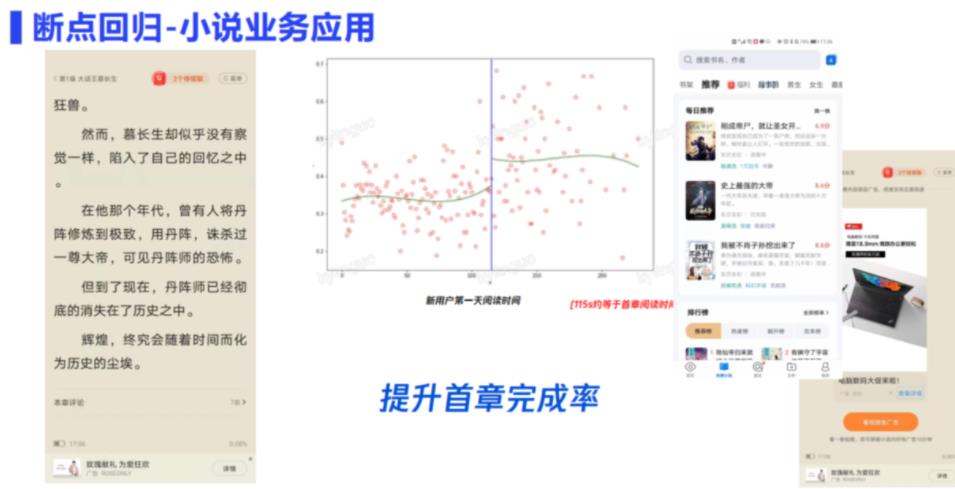
断点回归在首章提升上的作用
改良的DID 在天气资讯分析上的作用

启动重置问题阐述:短期、长期、异质


快手的 快手直播网页版对快手APP直播观看行为的影响

2 因果推断与A/B实验

随机实验是能够消除各类因果推断假定最好的方式,但是现实中困难点较多。
当然,在流量充足的情况下,是值得去做的。关于因果推断与A/B 实验,后续会专门用心再学一下。
贴一下比较好的
2.1 快手:双边实验设计
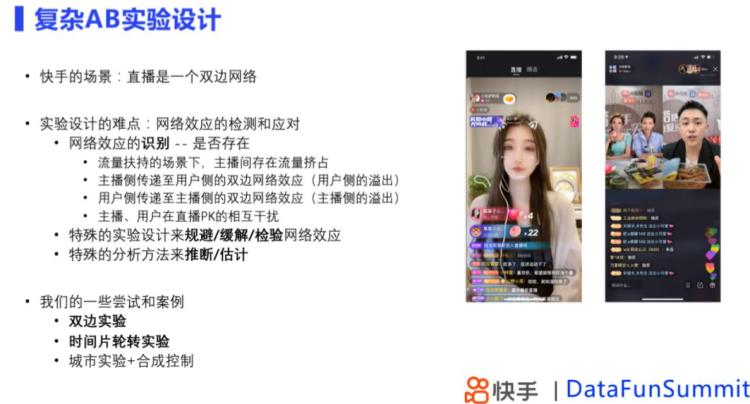

在双边实验中,同时进行了主播侧和观众侧的分流,主播侧一部分是上了挂件,观众侧一部分能看到一部分看不到,双边实验的优点是可以同时检测两端的效果,同时可以帮助检测到组间的转移和溢出。在了解到组间溢出和干扰下,通过双边实验我们可以更加准确的测算处理效应,在挂件场景下,我们认为N3是代表完全没有处理过的效果,Y代表处理后的结果,N3和Y进行差分,计算产品功能推全后的影响,而且,双边实验能够更好的帮助我们归因。

然而双边实验只能描述简单的组间溢出,在个体和个体之间存在干扰的复杂情况下,双边实验是无法帮助我们判断实验效果,例如直播PK暴击时刻这种情况下,我们通过时间片轮转实验解决,即在一定实验对象上进行实验组策略和对照组策略的反复切换。
2.2 快手:时间片轮转实验

时间片轮转的核心在于:
-
时间片的选择
-
实验总周期选择
-
随机切换时间点是什么样子的
当时间粒度约粗糙,时间上的干扰造成的偏差会越小,但是方差会越大,影响实验的检验效果,针对这个问题,采取的方案是最优设计。

最优设计的核心假设是: -
Outcome有一个绝对上界
-
用户无法知晓下一个时间是否是实验组
-
如果时间片之间存在干扰,干扰的影响是固定且有限的
当我们不知道一个时间片实验时间节点如何设计时,通常采取的步骤是,预估一个时间,通过实验确定carry over的阶数下限是多少,根据阶数下限,找到最优切换时间点,再进行一次实验,通过实验组和对照组的选择来进行因果效应的估计。其缺点在于,实验周期长,没有办法观测到HTE (heterogeneous treatment estimation)。
2.3 快手:城市实验 + 合成控制
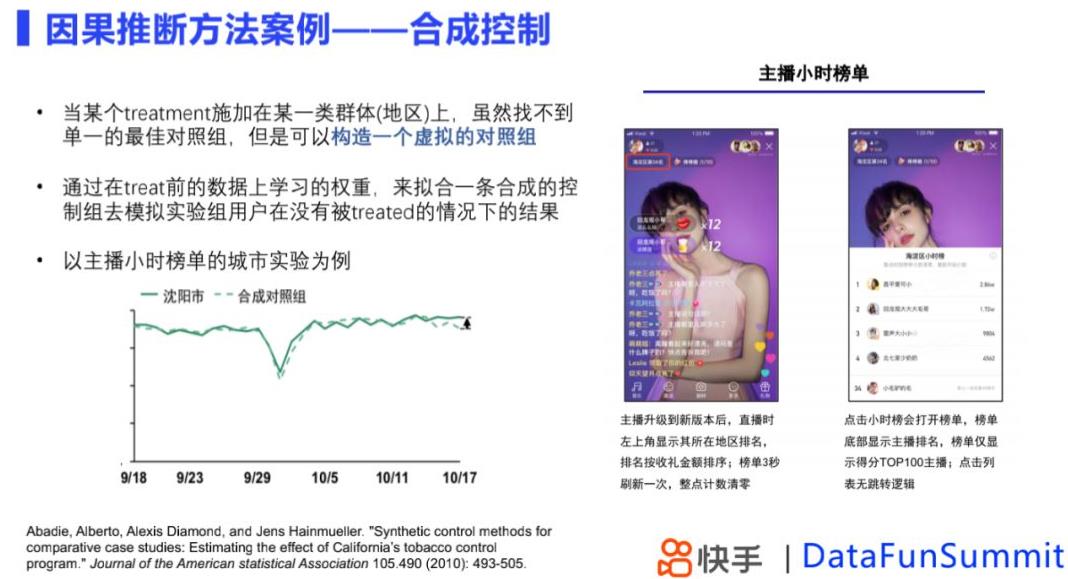
当treatment施加到一个群体或者地区上时,很难找到单一的对照组,这种时候采用合成控制方法构造虚拟对照组进行比较,原理是构造一个虚拟的对照组,通过treatment前的数据上学习的权重,拟合实验组在实验开始前的数据,模拟实验组用户在没有接受实验情况下的结果,构造合成控制组,实验开始后,评估实验组和合成控制组之间的差异。
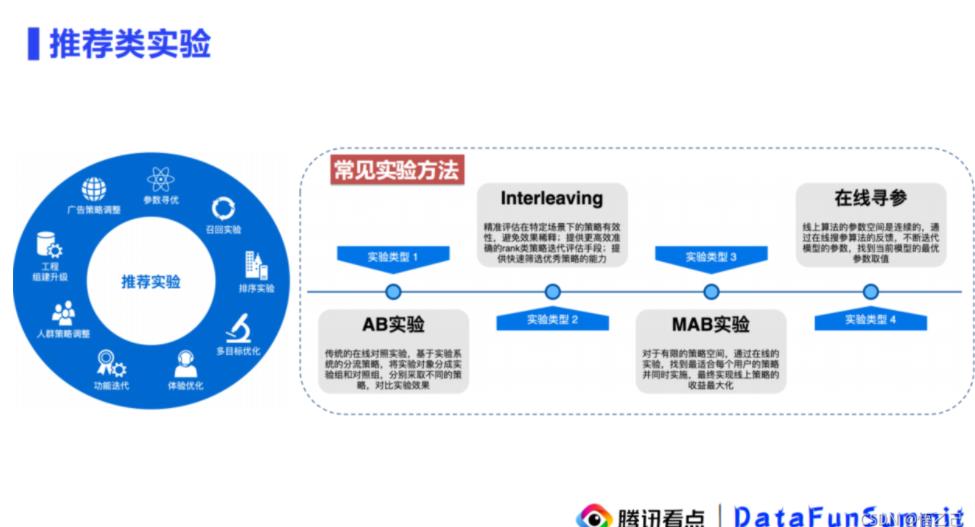
2.4 腾讯看点推荐类实验
3 落地工程化:因果推断在智能营销、权益中的通用框架
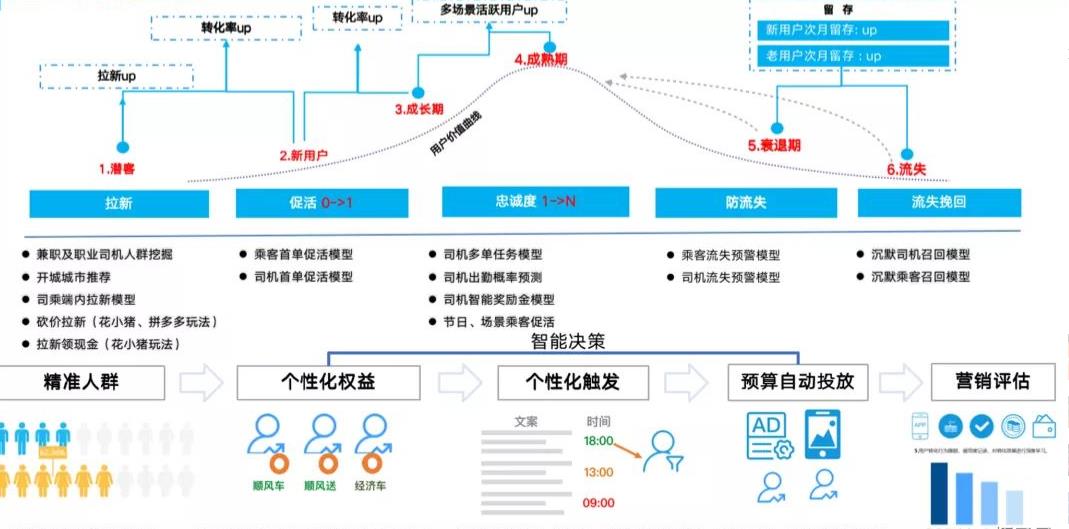 (借一张哈罗顺风车的图,如上)
(借一张哈罗顺风车的图,如上)
第三个部分是本节的重点,可以从很多已经落地工程化的案例中看到,在智能补贴或智能营销场景,常常需要解决两个递进的问题以及各自的解决方式,这里就是一个通用框架(这个套路又有点像之前学的预算分配的通用框架:A Unified Framework for Marketing Budget Allocation):
| 类型 | 解法 |
|---|---|
| 什么样的人值得给他发权益(补贴、优惠券等) | Uplift model |
| 这个人应该发什么类型的权益 | 线性规划、贪心分配、背包问题 |
3.1 选人、圈人

很显然,活跃转化是最主要的人群,大多的方法都是uplift model,那么uplift model也有几类:
- uplift方法一:元学习方法(Meta-learning methods)
- Conditional Outcome Modeling (COM) / S-learner
- Grouped COM (GCOM) / T-Learner
- X-Learner
- R-learner
- 特殊meta学习:The Class Transformation Method
- uplift方法二:Tree-Based Method(增量直接建模)
- 分布散度下的Uplift-Tree
- CausalForest
- 对uplift直接建模的CTS Tree
- NN-Based Method
还有uplift model评估问题也很关键后面可以再看看。
3.1.1 腾讯看点的meta learning

3.1.2 滴滴的国际化外卖团队 meta Learning
在实践中使用的方法是用一个新的LightGBM去拟合离线评估最优模型产出的【预测增量】,并用这个新模型的特征重要度来近似评估各个维度特征的重要性,以此来决策是否加入和剔除特征。选择LightGBM的原因是我们对于这个模型的精度并没有太高的要求,相反我们希望它能够比较快速地在训练流程中对新加入特征的给出反馈。LightGBM高效地训练速度和不需要过多特征工程的优点比较契合我们的需求。

3.1.3 阿里飞猪广告应用的 NN -Based
例如广告的CTR/CVR预估模型;该类模型对广告效率的预估,会预先将原始的复杂特征做汇总。基于此,整体的思想就是基于原生的广告搜索模型做迁移学习。
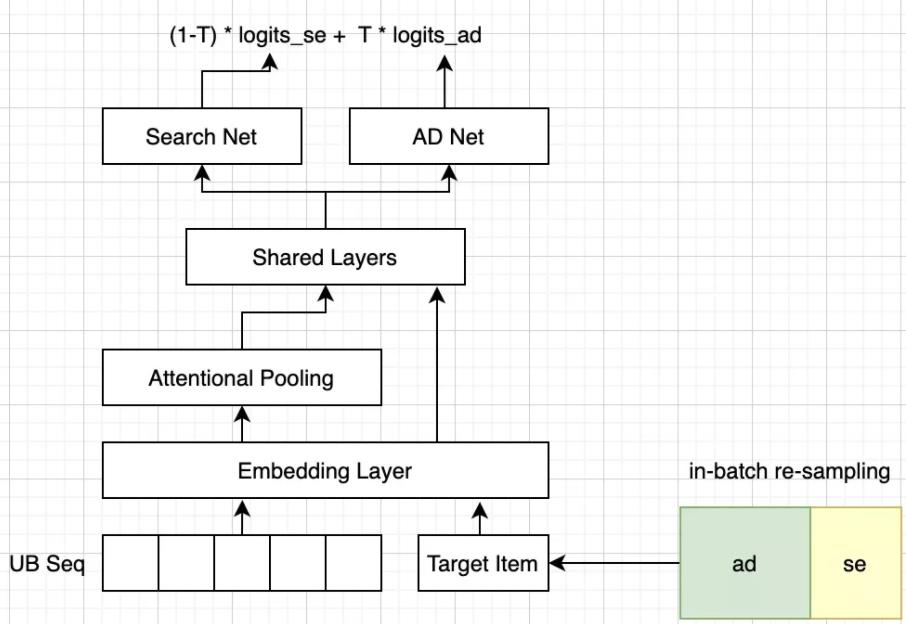
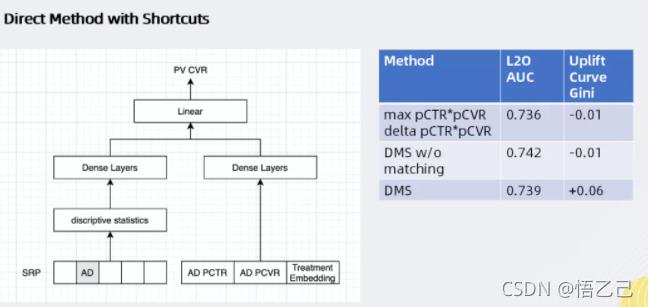
将所有特征都连到一个DNN里面,采用了ResNets的思想,如上图所示:左侧网络对用户搜索请求预期的转换效率进行建模,右侧网络对“广告是否投放”产生的影响进行建模,最后通过线性模型加以合并。对于广告效应的推断方面,这种模型相比于DNN会有一定的提升(uplift Qini指数提升至0.6)。
3.1.4 哈啰顺风车的meta-Learning

除了meta-learning外还尝试了Tree-Based,uplift model 下的树模型通过对增量直接建模,对特征点进行分裂, 将 X 划分到一个又一个 subspace 中,那划分准则与传统的决策树信息熵或者基尼系数不一样,这边主要是采用分布散度或者CTS分裂准则。
nn-based我们还没有尝试,他是将propensity score估计即倾向性得分和uplift score估计合并到一个网络实现。
3.1.5 阿里文娱的meta-learning

3.2 每个人发什么券
这里基本是线性规划占主导了
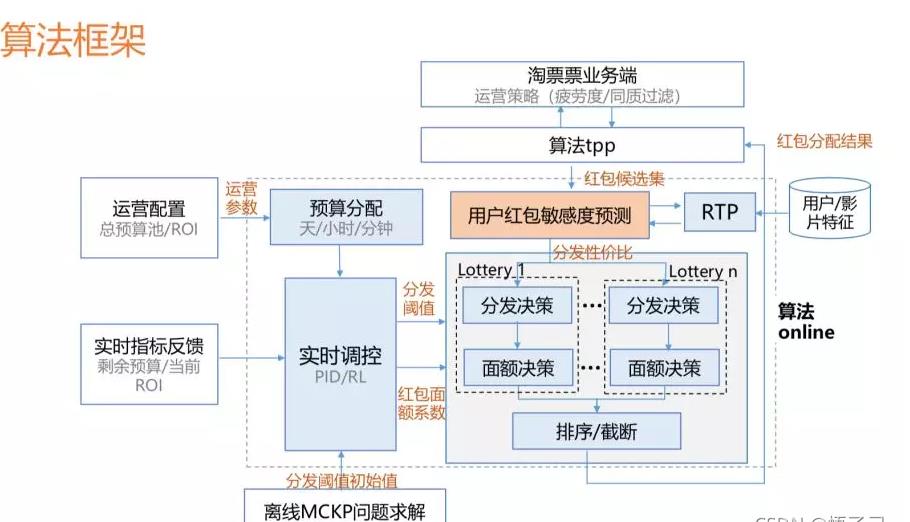
3.2.1 阿里文娱的:背包问题

黄色区域是基于uplift model的实时预测的模块,当一条用户的请求过来的时候,我们会实时去数据库中取用户的特征以及影片的特征,同时结合当前的环境特征预测用户在当前状态下真实的敏感度,基于这个敏感度可以进行后续分发的面额决策等。
3.2.2 滴滴的国际化外卖团队的 整数规划
对增量预估完毕后,接下来就需要具体地为用户池中用户分配补贴券。在基于增量预估的基础上,我们尝试了两种分发策略:
贪心分配
很多时候,运营对于使用的券类别和每个券类别的预算分配都有比较大的限制和约束。在这样的约束下,我们的做法是按照券值面额从低到高,为每个券类别计算可支配数量,然后对用户池所有用户按照预估出的Uplift值和计算出的可发放数量倒排截断,并将分配完毕的用户从备选用户池中移除。这样一个用户如果在各种券类别下uplift都很高时,我们将会优先为他/她配置券值较低的补贴券。这样做法的好处是简洁明了实现简单,在人工干预较强的时候对于运营的可解释性也比较强。缺点当然就是在自由度更高情况下,显然不能达到全局最优。
整数规划
而当我们对于预算和券种的设置拥有了更多的自主权时,我们也尝试了在预算约束下的最大化求解,具体的求解公式如下:

3.2.3 哈啰顺风车的智能权益
v3版本有提到,要借由运筹学给不同人配不同券 :
比如xij 代表第i个用户是否发放第j种券,那约束条件是:每个用户至多发一种劵,以及所有用户的发券总和不能超过实际预算,优化目标可以是所有用户的增益值最大,也可以是gmv最大或者roi最大等
运筹优化的求解主要是整数规划,整数规划目前采用谷歌的ortools来求解。但是优化器当求解参数上千万时,性能就出问题了,要算十个小时左右,这是不能接受的。目前的解决方案是分而治之,通过分城市来求解优化器,因为每个城市间的用户相对来说是相互独立的,互不干扰。
以上是关于因果推断笔记——入门学习因果推断在智能营销补贴的通用框架的主要内容,如果未能解决你的问题,请参考以下文章