瀚高数据库内存结构
Posted 瀚高PG实验室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了瀚高数据库内存结构相关的知识,希望对你有一定的参考价值。
目录
文档用途
详细信息
文档用途
了解瀚高数据库的内存结构,调整相关内存参数的大小以适应当前的运行环境。
详细信息
瀚高数据库的内存结构如下:
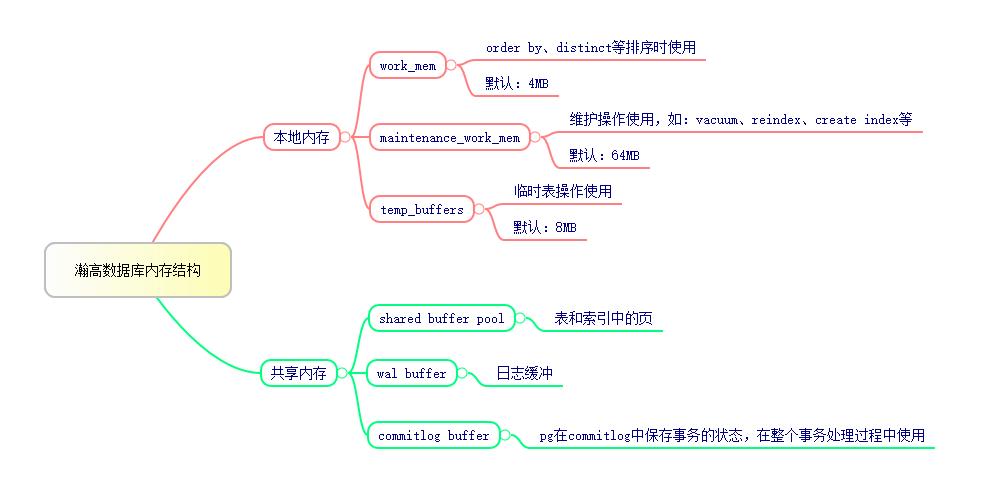
下面将详细介绍这些内存结构。
在瀚高数据库中,内存大概被分为两大类:
(1)本地内存(Local memory area): 为每一个后端进程(backend process)分配的内存
(2)共享内存(Shared memory area):数据库服务端所有的后台进程(backgroud process)使用的内存
(一)本地内存:
每一个后端进程都会分配一块本地内存,每一块区域又分为三个子区域。
1.1 work_mem
配置文件中的参数名是“work_mem”,默认是4MB
设置在写入临时磁盘文件之前,查询操作(如排序或哈希表)所使用的最大内存量。如果指定的值没有单位,则使用千字节(kilobytes)。默认值是 4兆字节(4MB)。注意,对于一个复杂的查询,可能会并行运行几个排序(sort)或散列(hash)操作;在开始将数据写入临时文件之前,允许每个操作使用此值指定的所有内存(PS.就是说一个查询,可能分成几个操作,每个操作单独配有一块 work_mem指定大小的内存)。另外,几个正在运行的会话可能同时执行这些操作。因此,使用的总内存可能是 work_mem值的许多倍;在选择值时,有必要记住这一点。排序操作用于 ORDER BY、DISTINCT和合并连接(merge joins)。哈希表(hash tables)用于哈希连接(hash joins)、基于哈希的聚合(hash-based aggregation)和基于哈希(hash-based)的 IN子查询处理。
1.2 maintenance_work_mem
配置文件中的参数名是“maintenance_work_mem”,默认是64MB
指定维护操作(如:VACUUM、CREATE INDEX和 ALTER TABLE ADD FOREIGN KEY)所使用的最大内存量。如果指定的值没有单位,则使用千字节(kilobytes)。它的默认值是 64兆字节(64MB)。由于数据库会话一次只能执行其中的一个操作,而且一个安装通常不会同时运行许多操作,因此可以将这个值设置为比 work_mem大得多的值。较大的设置(值)可能提高清理(vacuuming)和恢复数据库转储(restoring database dumps)的性能。
注意,在运行 autovacuum(自动清理)时,可能会分配相当于 autovacuum_max_workers乘以该内存(maintenance_work_mem),所以要注意不要将该默认值设置得太高。通过单独设置 autovacuum_work_mem来进行控制可能会很有用。
1.3 temp_buffers
配置文件中的参数名是“temp_buffers”,默认是8MB
设置每个数据库会话中临时缓冲区使用的最大内存量。这些是仅用于访问临时表的会话本地缓冲区。如果指定的值没有单位,则将其作为块,即 BLCKSZ字节,通常为8kB。默认值是8MB。(如果 BLCKSZ不是 8kB,则默认值会与之成比例伸缩。)此设置可以在单个会话内更改,但仅限于在会话内第一次使用临时表之前;后续更改该值的尝试将不会对该会话产生影响。
会话将根据需要分配临时缓冲区,上限由 temp_buffers指定。在实际上不需要很多临时缓冲区的会话中设置较大值的代价只是一个缓冲区描述符,或者在 temp_buffers中每增加一个缓冲区大约 64字节。但是,如果实际上真使用了缓冲区,则会为它消耗额外的 8192字节(通常是一个 BLCKSZ字节)。
(二)共享内存:
这块区域在服务端启动的时候分配,这块区域也是分为好几个子区域。
数据库启动后,会生成一块共享内存,共享内存主要用做数据块的缓冲区,以便提高读写性能。WAL日志缓冲区和CLOG缓冲区也存在共享内存中。除此以外还有一些全局信息也保存在共享内存中,如进程信息、锁的信息、全据统计信息,等等。
2.1 shared buffer pool
将表或者索引的page从磁盘加载到shared buffer,然后在shared buffer操作。
配置文件中的参数名是“shared_buffers”,默认是8MB。
设置数据库服务端用于共享内存缓冲区的内存量。默认值通常为 128兆字节(128MB),但如果内核设置不支持它,则可能会更小(内核设置在 initdb期间确定)。此参数设置必须至少为 128KB。但是,为了获得良好的性能,通常需要设置为比最小值高得多的值。如果指定的值没有单位,则将它视为块(blocks),即 BLCKSZ字节(块字节),通常为 8kB。(BLCKSZ的非默认值更改了最小值的大小。PS:最小值与块大小有关系)此参数只能在服务端启动时设置。
如果你有一个具有 1GB或更多 RAM的专用数据库服务器(PS.是否指该服务器只用来一个数据库集簇使用),合理的 shared_buffers起始值是系统中内存的 25%。在某些工作负载中,shared_buffers的更大设置是高效的,但由于 PostgreSQL也依赖于操作系统缓存,因此将超过 40%的 RAM分配给 shared_buffers不太可能比分配较小的内存更优。对于 shared_buffers,较大的设置通常需要相应地增加 max_wal_size,以便在较长一段时间内分散写入大量新数据或更改数据的过程。
在RAM小于1GB的系统上,较小的 RAM百分比是合适的,以便为操作系统留下足够的空间。
2.2 wal buffer
在服务端出现问题的时候,确保数据不会丢失,在写到磁盘之前,wal buffer是wal log的缓存区域
配置文件中的参数名是“wal_buffers”,默认是16MB。
用于尚未写入磁盘的WAL数据的共享内存量。默认设置-1时,选择的大小等于shared_buffers的1/32(大约3%),但不小于64kB,也不大于一个WAL段的大小,通常为16MB。如果自动选取的值太大或太小,可以手动设置该值,但是任何小于32kB的正数值将被视为32kB。如果指定的值没有单位,则将“WAL块”作为单位,即“XLOG_BLCKSZ”字节,通常为 8kB。此参数只能在服务端启动时设置。
在每次事务提交时,WAL缓冲区的内容都被写到磁盘上,因此非常大的值不太可能提供显著的性能益处。但是,将这个值设置为至少几兆字节可以提高在许多客户机同时提交的繁忙服务端上的写性能。在大多数情况下,通过默认设置-1选择的自动调优应该会给出合理的结果。
2.3 commitlog buffer
为了并发控制所有事物的状态的保持而分配的区域
通过clog(commit log)存储每个事务的状态,在数据库启动时,clog文件会加载到共享内存中,checkpoint时会把共享内存中的事务状态信息刷新到磁盘上。
另外,瀚高数据库还分配一些其他的内存区域:
为访问控制分配的子区域,比如轻量级锁,共享或者专有锁。
为其他backgroud process提供的子区域,比如检查点,vacuum。
为事物处理提供的子区域,比如事物中的保存点,和二阶段事物提交。
以上是关于瀚高数据库内存结构的主要内容,如果未能解决你的问题,请参考以下文章