内存映射数据结构
Posted liushoudong
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了内存映射数据结构相关的知识,希望对你有一定的参考价值。
内存映射数据结构是一系列经过特殊编码的字节序列,创建它们所消耗的内存通常比作用类似的内部数据结构要少得多,如果使用得当,内存映射数据结构可以为用户节省大量的内存。
不过,因为内存映射数据结构的编码和操作方式要比内部数据结构要复杂得多,所以内存映射数据结构所占用的CPU时间会比作用类似的内部数据结构要多
Redis目前正在使用的两种内存映射数据结构:整数集合,压缩列表
整数集合
整数集合(intset)用于有序、无重复地保存多个整数值,它会根据元素的值,自动选择该用什 么长度的整数类型来保存元素。
举个例子,如果在一个 intset 里面,最长的元素可以用 int16_t 类型来保存,那么这个 intset 的所有元素都以 int16_t 类型来保存。
另一方面,如果有一个新元素要加入到这个 intset ,并且这个元素不能用 int16_t 类型来保存 ——比如说,新元素的长度为 int32_t ,那么这个 intset 就会自动进行“升级”:先将集合中现 有的所有元素从 int16_t 类型转换为 int32_t 类型,接着再将新元素加入到集合中。根据需要,intset 可以自动从 int16_t 升级到 int32_t 或 int64_t ,或者从 int32_t 升级到 int64_t 。
整数集合的应用-->Intset是集合键的底层实现之一,如果一个集合:只保存着整数元素;元素的数量不多。那么Redis就会使用intset来保存集合元素。
1 //intset.h 2 3 typedef struct intset { 4 // 保存元素所使用的类型的长度 5 uint32_t encoding; 6 7 //元素个数 8 uint32_t length; 9 10 //保存元素的数组 11 int8_t contents[]; 12 13 //contents数组是实际保存元素的地方,数组中的元素有以下两个特性:没有重复元素;元素在数组中从小到大排列 14 } intset;
encoding的值可以是以下三个常量的其中一个(定义位于intset.c):
#define INTSET_ENG_INT16(sizeof(int16_t))
#define INTSET_ENG_INT32(sizeof(int32_t))
#define INTSET_ENG_INT64(sizeof(int64_t))
contents数组是实际保存元素的地方,数组中的元素有以下两个特性:
没有重复元素
元素在数组中从小到大排列
contents 数组的 int8_t 类型声明比较容易让人误解,实际上,intset 并不使用 int8_t 类型 来保存任何元素,结构中的这个类型声明只是作为一个占位符使用:在对 contents 中的元素 进行读取或者写入时,程序并不是直接使用 contents 来对元素进行索引,而是根据 encoding 的值,对 contents 进行类型转换和指针运算,计算出元素在内存中的正确位置。在添加新元 素,进行内存分配时,分配的容量也是由 encoding 的值决定。
1 //创建新intset 2 3 intset *is = intsetNew(); 4 5 //intset->encoding = INTSET_ENC_INT16; 6 //intset->length 0; 7 //intset->contents = []; 8 9 //encoding使用INTSET_ENC_INT16作为初始值
添加新元素到intset
添加新元素到 intset 的工作由 intset.c/intsetAdd 函数完成,它需要处理以下三种情况:
1. 元素已存在于集合,不做动作;
2. 元素不存在于集合,并且添加新元素并不需要升级;
3. 元素不存在于集合,但是要在升级之后,才能添加新元素;
并且,intsetAdd 需要维持 intset->contents 的以下性质:
1. 确保数组中没有重复元素; 2. 确保数组中的元素按从小到大排序;
添加操作在升级和不升级两种情况下的执行过程
添加新元素到intset(不需要升级)
如果 intset 现有的编码方式适用于新元素,那么可以直接将新元素添加到 intset ,无须对 intset 进行升级。
添加新元素到intset(需要升级)
当要添加新元素到 intset ,并且 intset 当前的编码并不适用于新元素的编码时,就需要对 inset 进行升级。
在添加新元素时,如果 intsetAdd 发现新元素不能用现有的编码方式来保存,它就会将升级集 合和添加新元素的任务转交给 intsetUpgradeAndAdd 来完成
intsetUpgradeAndAdd 需要完成以下几个任务:
1. 对新元素进行检测,看保存这个新元素需要什么类型的编码;
2. 将集合 encoding 属性的值设置为新编码类型,并根据新编码类型,对整个 contents 数组进行内存重分配。
3. 调整 contents 数组内原有元素在内存中的排列方式,让它们从旧编码调整为新编码。
4. 将新元素添加到集合中。
关于升级操作,需要注意:
1,从较短整数到较长整数的转换,并不会更改元素里面的值
在 C 语言中,从长度较短的带符号整数到长度较长的带符号整数之间的转换(比如从 int16_t 转换为 int32_t )总是可行的(不会溢出)、无损的。 另一方面,从较长整数到较短整数之间的转换可能是有损的(比如从 int32_t 转换为 int16_t )。 因为 intset 只进行从较短整数到较长整数的转换(也即是,只“升级”,不“降级”),因此,“升 级”操作并不会修改元素原有的值。
2,集合编码元素的方式,由元素中长度最大的那个值来决定
在进行升级的过程中,需要对数组内的元素进行“类型转换”和“移动”操作。 其中,移动不仅出现在升级(intsetUpgradeAndAdd)操作中,还出现其他对 contents 数组内 容进行增删的操作上,比如 intsetAdd 和 intsetRemove ,因为这种移动操作需要处理 intset 中的所有元素,所以这些函数的复杂度都不低于 O(N) 。
Intset 不支持降级操作。 Intset 定位为一种受限的中间表示,只能保存整数值,而且元素的个数也不能超过 redis.h/REDIS_SET_MAX_INTSET_ENTRIES (目前版本值为 512 )这些条件决定了它被保 存的时间不会太长,因此对它进行太复杂的操作,没有必要。
• Intset 用于有序、无重复地保存多个整数值,它会根据元素的值,自动选择该用什么长度 的整数类型来保存元素。
• 当一个位长度更长的整数值添加到 intset 时,需要对 intset 进行升级,新 intset 中每个 元素的位长度都等于新添加值的位长度,但原有元素的值不变。
• 升级会引起整个 intset 进行内存重分配,并移动集合中的所有元素,这个操作的复杂度 为 O(N) 。
• Intset 只支持升级,不支持降级。
• Intset 是有序的,程序使用二分查找算法来实现查找操作,复杂度为 O(lgN) 。
压缩列表
Ziplist-->由一系列特殊编码的内存块构成的列表,一个ziplist可以包含多个节点(entry),每个节点可以保存一个长度受限的字符数组(不以o结尾的char数组)或者整数
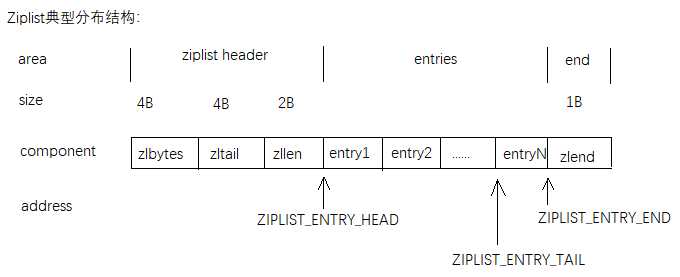
ziplist的构成:ziplist header + entries + end
ziplist header(4B zlbytes + 4B zltail + 2B zllen)
entries(entry1, entry2, ......,entryN)
end(1B zlend)
因为 ziplist header 部分的长度总是固定的(4 字节 + 4 字节 + 2 字节),因此将指针移动到表 头节点的复杂度为常数时间;除此之外,因为表尾节点的地址可以通过 zltail 计算得出,因 此将指针移动到表尾节点的复杂度也为常数时间。
域:zlbytes-->长度/类型:uint32_t-->域的值:整个ziplist占用的内存字节数,对ziplist进行内存重分配,或者计算末端时使用
域:zltail-->长度/类型:uint32_t-->域的值:到达ziplist表尾节点的偏移量。通过这个偏移量,可以在不遍历整个ziplist的前提下,弹出表尾节点
域:zllen-->长度/类型:uint16_t-->域的值:ziplist中节点的数量。当这个值小于UINT16_MAX(65535)时,这个值就是ziplist中节点的数量;当这个值等于UINT16_MAX时,节点的数量需要遍历整个ziplist才能计算得出
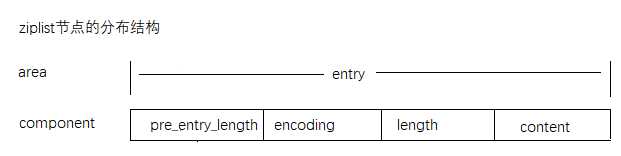
节点entry的构成
每个节点可以划分为:pre_entry_length + encoding + length + content
pre_entry_length记录了前一个节点的长度,通过这个值,可以进行指针计算,从而跳转到上一个节点。根据编码方式的不同,pre_entry_length域可能占用1字节或者5字节,1字节:如果前一节点的长度小于254字节,那么只使用一个字节保存它的值;5字节:如果前一节点的长度大于等于254字节,那么将第1个字节的值设为254,然后用接下来的4个字节保存实际长度
encoding和length:这两部分一起决定了content部分所保存的数据的类型(以及长度)
其中,encoding域的长度为两个bit,值可以是00、01、10和11
00、01和10表示content部分保存着字符数组
11表示content部分保存着整数
content:这部分保存着节点的内容,它的类型和长度由encoding和length决定
创建新ziplist
添加节点-->
将节点添加到末端:
- 记录到达 ziplist 末端所需的偏移量(因为之后的内存重分配可能会改变 ziplist 的地址, 因此记录偏移量而不是保存指针)
- 根据新节点要保存的值,计算出编码这个值所需的空间大小,以及编码它前一个节点的长度所需的空间大小,然后对 ziplist 进行内存重分配。
- 设置新节点的各项属性:pre_entry_length 、encoding 、length 和 content 。
- 更新 ziplist 的各项属性,比如记录空间占用的 zlbytes ,到达表尾节点的偏移量 zltail ,以及记录节点数量的 zllen 。
将节点添加到某个/某些节点的前面:
比起将新节点添加到 ziplist 的末端,将一个新节点添加到某个/某些节点的前面要复杂得多, 因为这种操作除了将新节点添加到 ziplist 以外,还可能引起后续一系列节点的改变。
假设要将一个新节点new添加到节点prev和next之间:
首先为新节点扩大ziplist的空间;然后设置new节点的各项值;
现在新的new节点取代原来的prev节点,成为了next节点的新前驱节点,不过因为这时next节点的pre_entry_length域编码的仍然是prev节点的长度,所以程序需要将new节点的长度编码进next节点的pre_entry_length域里,这里会出现三种可能:
1.next的pre_entry_length域的长度正好能够编码new的长度(都是1字节或者都是5字节)
2.next的pre_entry_length只有1字节长,但编码new的长度需要5字节
3.next的pre_entry_length有5字节长,但编码new的长度只需要1字节
对于情况1和情况3,程序直接更新next的pre_entry_length域
如果是第二种情况,那么程序必须对ziplist进行内存重分配,从而扩展next的空间。然而,因为next的空间长度改变了,所以程序又必须检查next的后继节点next+1,看它的pre_entry_length能否编码next的新长度,如果不能的话,程序又需要继续对next+1进行扩容
这就是说,在某个/某些节点的前面添加新节点之后,程序必须沿着路径一个个检查后续的节点是否满足新长度的编码要求,直到遇到一个能满足要求的节点(如果有一个能满足,那么这个节点之后的其他节点也满足),或者到达ziplist的末端zlend为止,这种检查操作的复杂度为O(N**2)
因为只有在新添加节点的后面有连续多个长度接近254的节点时,这种连锁更新才会发生,所以可以普遍地认为,这种连锁更新发生的概率非常小,在一般情况下,将添加操作看成是O(N)复杂度也是可以的
执行完这三种情况的其中一种后,程序更新ziplist的各项属性,至此,添加操作完成。
在第三种情况中,程序实际上是可以执行类似于情况二的动作的:它可以一个个地检 查新节点之后的节点,尝试收缩它们的空间长度,不过 Redis 决定不这么做,因为在一些情况 下,比如前面提到的,有连续多个长度接近 254 的节点时,可能会出现重复的扩展——收缩 ——再扩展——再收缩的抖动(?apping)效果,这会让操作的性能变得非常差。
删除节点-->
定位目标节点,并计算节点的空间长度target-size;进行内存移位,覆盖target原本的数据,然后通过内存重分配,收缩多余空间;检查next、next+1等后续节点能否满足新前驱节点的编码。和添加操作一样,删除操作也可能会引起连锁更新
遍历-->
可以对ziplist进行从前向后的遍历,或者从后向前的遍历
当进行从前向后的遍历时,程序从指向节点e1的指针p开始,计算节点e1的长度(e1-size), 然后将 p 加上 e1-size ,就将指针后移到了下一个节点 e2 。一直这样做下去,直到 p 遇到 ZIPLIST_ENTRY_END 为止,这样整个 ziplist 就遍历完了
当进行从后往前遍历的时候,程序从指向节点eN的指针p出发,取出eN的pre_entry_length 值,然后用 p 减去 pre_entry_length ,这就将指针移动到了前一个节点 eN-1 。一直这样做下去,直到 p 遇到 ZIPLIST_ENTRY_HEAD 为止,这样整个 ziplist 就遍历完了。
查找元素、根据值定位节点-->这两个操作和遍历的原理基本相同
ziplist 是由一系列特殊编码的内存块构成的列表,它可以保存字符数组或整数值,它还是哈希键、列表键和有序集合键的底层实现之一。
添加和删除ziplist节点有可能会引起连锁更新,因此,添加和删除操作的最坏复杂度为O(n**2),不过因为连锁更新的出现概率并不高,所以一般可以将添加和删除操作的复杂度视为O(N)
以上是关于内存映射数据结构的主要内容,如果未能解决你的问题,请参考以下文章
Linux 内核 内存管理内存管理系统调用 ⑤ ( 代码示例 | 多进程共享 mmap 内存映射示例 )
EF添加关联的提示问题:映射从第 260 行开始的片段时有问题:
如何使用模块化代码片段中的LeakCanary检测内存泄漏?
14.VisualVM使用详解15.VisualVM堆查看器使用的内存不足19.class文件--文件结构--魔数20.文件结构--常量池21.文件结构访问标志(2个字节)22.类加载机制概(代码片段