通过添加索引提高应用系统性能
Posted 瀚高PG实验室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了通过添加索引提高应用系统性能相关的知识,希望对你有一定的参考价值。
目录
环境
文档用途
详细信息
环境
系统平台:Microsoft Windows (64-bit) 2012
版本:5.6.5
文档用途
数据库性能=应用程序性能,但通常情况下,应用程序性能由底层数据库及其配置决定,这是因为许多应用程序及其ORM(对象关系映射)都不知道运行在ORM调用后面的SQL。
缺少索引是会导致数据库性能问题,现实中导致数据库性能问题的最常见错误是开发人员忘记添加索引。本文就介绍了如何发现索引缺失的方法,并介绍了如何通过创建索引来提高性能
详细信息
在HGDB中查看查询性能,实现这一点的一个重要工具是HGDB中的pg_stat_statements扩展。使用pg_stat_statements查找执行时间慢的查询:
下面是一个标准查询,您可以在数据库上运行,从pg_stat_statements中获取查询统计信息
SELECT queryid, calls, mean_time, substring(query for 100) FROM pg_stat_statements
ORDER BY total_time DESC LIMIT 10;
这将给我们一个如下列表,最慢的查询在上面:

需要注意的一点是,pg_stat_statements从安装时开始记录其统计信息,或者从您上次重置统计信息时开始记录。
重要提示:当使用pg_stat_statements而没有pganalyze这样的监视产品时,可以使用pg_stat_statements_reset()函数重置统计信息。
分析特定慢速查询的性能
让我们看看上面的查询输出。我们如何才能找出SELECT „backend_wait_events“查询速度慢的原因?
首先,让我们通过查询这个queryid获取pg_stat_statements存储的完整查询文本:

这里我们可以看到,pg_stat_statements记录的不是查询的特定调用,而是查询的聚合、规范化形式。
类似的查询基于queryid分组在一起,文本被规范化,因此如果在原始SQL中有“backend_id=‘something’”,它将存储“backend_id=$1”。这主要是为了用户的利益,但也有缺点,我们无法对查询文本运行EXPLAIN:
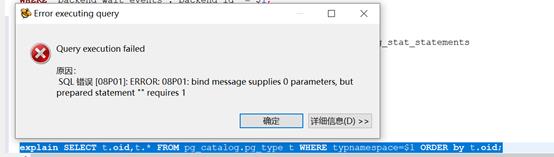
因为HGDB的执行计划依赖于您要查询的特定值需要知道$1的值才能运行EXPLAIN。
EXPLAIN让您可以通过显示HGDB如何执行查询来确定查询的执行计划,例如,让您知道它是要进行索引扫描(通常是好的)还是顺序扫描(通常是慢的,除了在非常小的表上)。现在,我们可能正好知道backend_id的值并自己替换它,这样我们就可以运行EXPLAIN,但通常,我们不知道这些参数的值,这就引出了下一个问题:如何确定pg_stat_statements中查询的绑定参数值?查找慢速查询的绑定参数值,为了得到完整的查询文本,我们有两个选择:首先我们可以使用HGDB的pg_stat_uactivity表,它显示当前正在运行的查询。如果不在自己的应用程序代码中使用参数(即在查询文本本身中发送所有值),这将起作用,但需要通过频繁地对该表进行采样来进行一些额外的工作。作为一种更通用的方法,我们既可以处理pg_stat_statements的绑定参数值,也可以处理应用程序单独发送的绑定参数值
理解HGDB日志系统
HGDB会生成大量的日志事件,查看和解析日志文件需要花费大量的精力。但是,对于这个特定的示例,我们只查看一个日志事件,即由log min_duration_statement控制的慢速查询日志输出。
log_min_duration_statement vs log_statement:对于熟悉Postgres配置选项的人,您可能会想知道为什么我们建议使用log_min_duration_statement而不是log_statement。虽然您可以利用log_statement=all为每个运行的语句获取完整的查询文本,但这在生产中很少有意义,因为它可能会占用生产系统,因为在非常快的查询中日志输出的开销很大。因此,我们建议仅在生产系统上使用log_min_uduration_statement。
我们可以将log_min_duration_statement设置为特定的阈值,任何运行时间超过该阈值的SQL查询都会将完整的查询文本记录到Postgres日志文件中。通常,从一个1000 ms的阈值开始是有意义的,如果需要的话可以稍微降低一点,因为这里的目标不是记录每个查询,而是为离群查询找到特定的查询文本。
一旦启用,输出如下:

如您所见,我们可以获取客户机发送的参数,如果pg_stat_statements将替换任何值,这些值也将正确地反映在日志事件中。我们现在可以对此运行EXPLAIN,生成正确的查询计划:
使用auto_explain自动收集EXPLAIN计划
上面的过程可以运行一些EXPLAINs,但是系统地运行它太费劲了。此外,如果一两天后只查看日志文件,可能会得到一个不同于慢速查询时实际发生的执行计划。
因此,我们转向另一个非常有用的Postgres扩展:auto_explain。
auto_explain也与contrib包中的Postgres捆绑在一起,比如pg_stat_statement,必须在数据库中启用。请参阅文档中的安装指南。启用后,auto_uexplain.log_min_duration设置将确定哪些查询将其EXPLAIN计划记录下来。首先,我们建议将其设置为1000毫秒,并根据需要降低它。
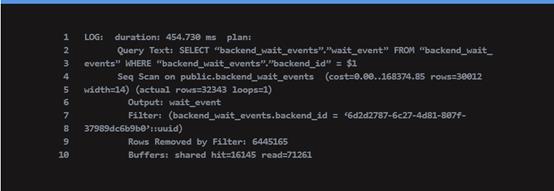
然后,当缓慢的查询发生时,您将把这样的计划放入日志文件中:
基于EXPLAIN计划确定缺失指标
现在,让我们回顾一下之前的EXPLAIN计划,并尝试了解如何提高性能。我们可以使用ANALYZE和BUFFERS选项运行EXPLAIN,以获取有关查询执行的完整详细信息:

在阅读解释计划时,把注意力集中在计划中最昂贵的部分是有意义的。这里的计划很简单,因为我们只有一个计划节点——Seq Scan节点。顺序扫描按顺序读取表数据(因此命名),而不使用任何索引。
您可以看到HGDB正在使用它正在查找的特定后端id筛选扫描,因此它必须丢弃许多行,如由筛选器移除的行所示:。HGDB还加载了大量数据,如缓冲区:information – specifically具体来说,它从磁盘加载680 MB数据(读取86989个缓冲区,乘以默认的HGDB块大小8KB)。
现在,下一步是理解HGDB为什么要进行顺序扫描——也许没有索引?
用标准工具检查这个问题的最简单方法是简单地查看HGDB客户机psql中的表,然后使用-d命令:
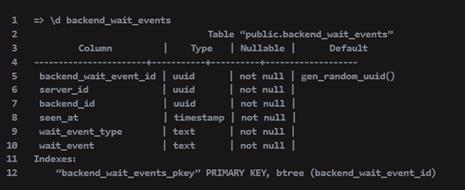
我们可以看到表上有一个索引,在主键上。我们正在查询的字段上没有索引,因此需要进行顺序扫描。
现在,我们创建这样一个索引:

然后重新EXPLAIN:

我们现在使用Bitmap索引扫描而不是顺序扫描。我们可以看到,基于该索引,性能提高了2倍。现在我们仍在从表本身加载26451块(207mb),以便获得我们正在寻找的wait_event列的值。如果我们只是将该列包含在索引中呢?在旧的HGDB版本中,可以创建如下多列索引。但是,由于我们在这里测试HGDB V6,我们还可以使用新的INCLUDE关键字来指定我们希望在索引中显示的非键列:

新计划现在如下所示(见下文):
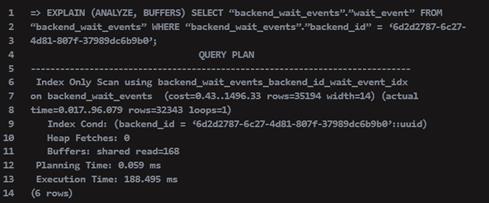
这又使性能提高了1.5倍。此外,我们还将从磁盘加载的数据量减少到了1.3 MB,与最初的计划相差500倍!加载数据的减少将减少磁盘上的压力,并允许其他查询使用现在释放的I/O带宽。
以上是关于通过添加索引提高应用系统性能的主要内容,如果未能解决你的问题,请参考以下文章