如何通过MongoDB自带的Explain功能提高检索性能?
Posted AI前线
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何通过MongoDB自带的Explain功能提高检索性能?相关的知识,希望对你有一定的参考价值。
本文作者最近分析了一些 MongoDB 的性能问题,发现 MongoDB 自带的 Explain 有很强大的分析功能。根据 Explain 的运行结果可以得到 find 语句执行过程中每一个步骤的执行时间以及扫描 Document 所使用得索引细节。下面作者将根据几个具体的场景来分析如何利用 explain 了解语句执行的效率,如何通过创建索引提高 find 语句的性能。
更多精彩文章请添加微信“AI 前线”(ID:ai-front)
每当大家谈到数据库检索性能的时候,首先提及的就是索引,对此,MongoDB 也不例外。就像大家读一本书,或者查字典一样,索引是书的目录,让你方便的能够在上百页的书中找到自己感兴趣的内容。那么,有多少人了解索引的底层原理呢?相信大部分人,至少与数据库打过交道的都知道如何使用,但是牵扯到底层的技术实现可能研究过的人就不多了。在此我给大家一个 MongoDB 索引的底层实现原理分析,之后会根据一个具体实例来看看如何通过索引提高 collection 的检索性能。
在没有创建任何索引的 collection 中,MongoDB 会对查询语句执行一次整体扫描,这个过程在 MongoDB 中叫 collection scan。collection scan 会根据查询语句中的检索条件,与 collection 中每一个 document 进行比较,符合条件的 document 被选出来。可以想像,对一个包含几百万条纪录数据库表来说,查询的效率会相当底,执行时间也会很长。就像你在一个没有目录的书中查找一段相关内容一样,也许你会快速浏览这本书的每一页,才能找到想要的结果。对于有索引的 collection 来说,情况会好很多。由于创建了索引,MongoDB 会限制比较的纪录个数,这样大大降低了执行时间。
MongoDB 采用 B-tree 作为索引数据结构,B-tree 数据结构的基本概念并不在本篇文章所要讨论的范围之内,有兴趣的读者可以查阅一些相关文章和书籍。在 MongoDB 里面,B-tree 中的一个节点被定义成一个 Bucket。Bucket 中包含一个排过续的数组,数组中的元素指向 document 在 collection 中的位置。如下图所示:
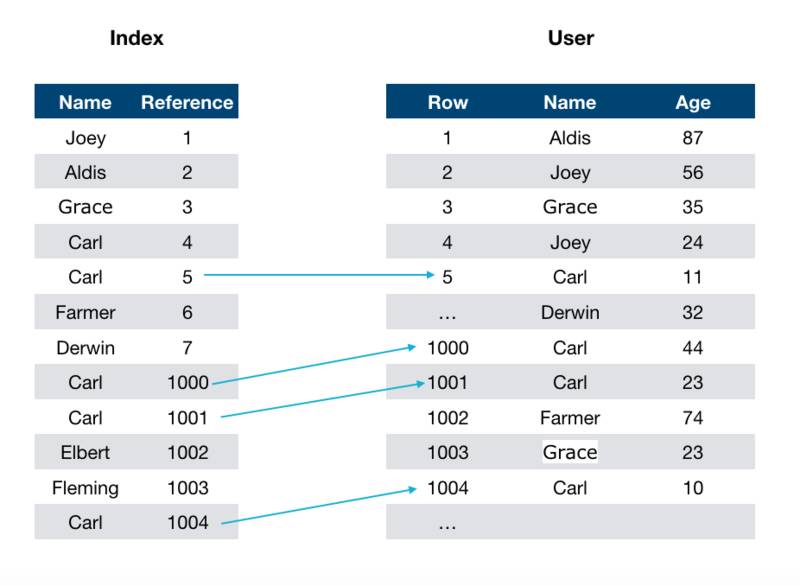
假设我们有一个叫 User 的数据库表,里面有两个字段,Name 和 Age。每条记录的位置由 Row 表示。在左边这张图上,每一条索引记录包括一个索引主键(Name)以及一个指向 User 表中记录的引用。通过这个引用,我们可以找到记录在 Collection 中的位置。例如:如果你想找到所有叫 Carl 的用户,通过引用的位置我们可以得到 5,1000,1001,1004 四个匹配的纪录位置。
MongoDB 支持多种索引类型,常用的有Single Field, Compound Index, Multikey Index, Text Indexes, Hashed Indexes,等。这里我就不对每一种 Index 做过多的解释了,有兴趣的读者可以参考 MongoDB 官方文档:Indexes-Basics。
上面介绍了一下 MongoDB 索引的基本结构以及存储类型,接下来我们看看如果使用索引来提高检索性能。本文不是一个入门级文章,关于 explain 的基本用法、参数等信息可以参考 MongoDB 的官方文档:
https://docs.mongodb.com/manual/reference/explain-results/
我们知道 Explain 支持三种执行参数,queryPlanner, executionStats and allPlansExecution, 他们之间具体的区别可以参考上面列出的文档,为了进行详细的性能分析,本文不考虑使用queryPlanner, 而另外两个参数的执行没有太多区别,所以本文只采用executionStats。
首先准备数据,在学习如何分析数据库性能的同时,我们最头疼的莫过于如何准备数据,如何模拟数据的执行效率。幸运的是 mtools
https://github.com/rueckstiess/mtools
为我们提供了方便的 MongoDB 实例化,以及插入任意格式的 json 数据结构。(截止到目前为止,mtools 的官方 release 还不支持 windwos 操作系统,但是我的一个 PR 已经 merge 到 master,所以使用 windows 的同学可以直接从 master 上面手动安装 mtools,需要 python2.7 的支持)。运行下面的mlaunch命令来启动一个 MongoDB 单例 server(他会启动一个监听 27017 端口的 server,如果可以设置不同的参数来使用其他端口):
mlaunch init --single
数据库启动以后,我们来创建一些用于测试的 json 数据,定义下面的 json 格式:
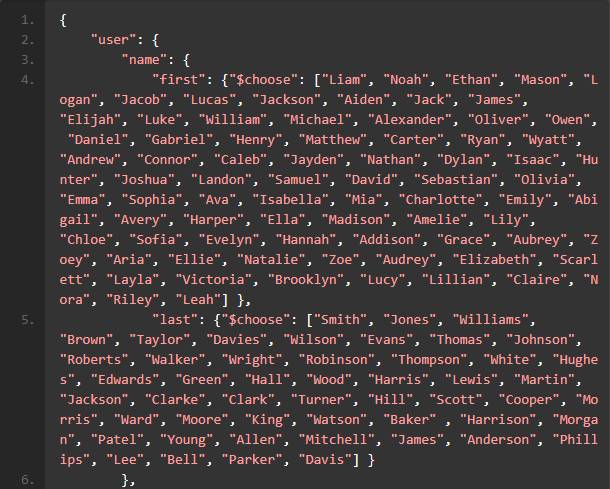
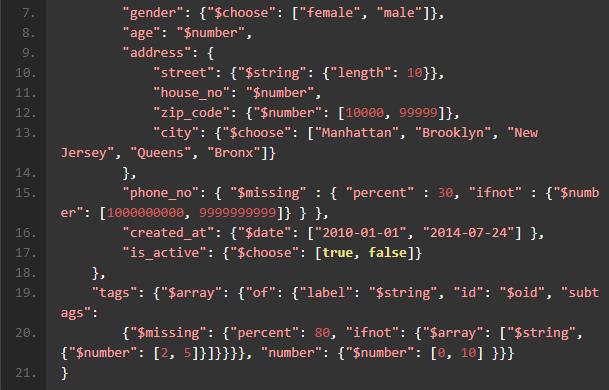
把它保存为一个叫user.json的文件中,然后使用mgenerate插入十万条随机数据。随机数据的格式就按照上面json文件的定义。你可以通过调整 --num的参数来插入不同数量的 Document。
https://github.com/rueckstiess/mtools/wiki/mgenerate
mgenerate user.json --num 1000000 --database test --collection users
上面的命令会像test数据库中users collection 插入一百万条数据。在有些机器上,运行上面的语句可能需要等待一段时间,因为生成一百万条数据是一个比较耗时的操作,之所以生成如此多的数据是方便后面我们分析性能时,可以看到性能的显著差别。当然你也可以只生成十万条数据来进行测试,只要能够在你的机器上看到不同 find 语句的执行时间差异就可以。
连接到 MongoDB 查看一下刚刚创建好的数据:
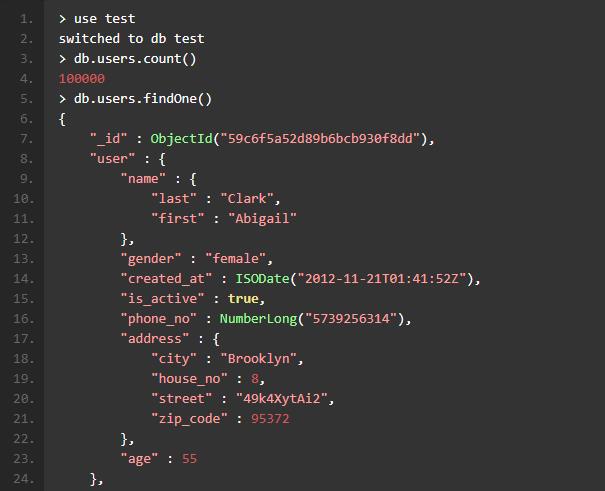
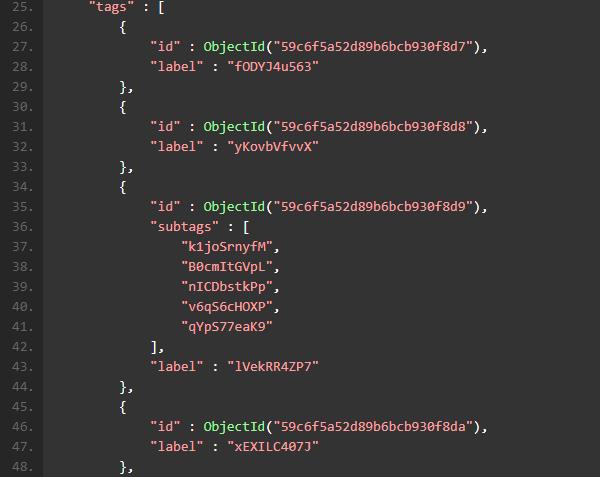
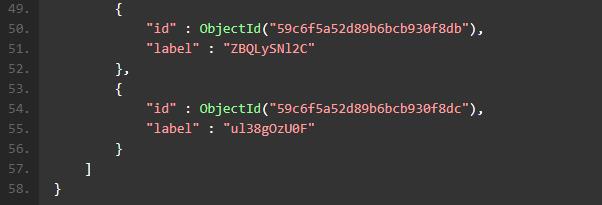
对于不太熟悉 Mongo Shell 的同学,不要着急,这里我为大家推荐一款强大的 MongoDB IDE
https://www.dbkoda.com
这款 IDE 可以替代 Mongo Shell 全部功能,并且提供了图形化的方式来查看 MongoDB 的各种性能指标。例如下面显示了users collection 的数据结构:
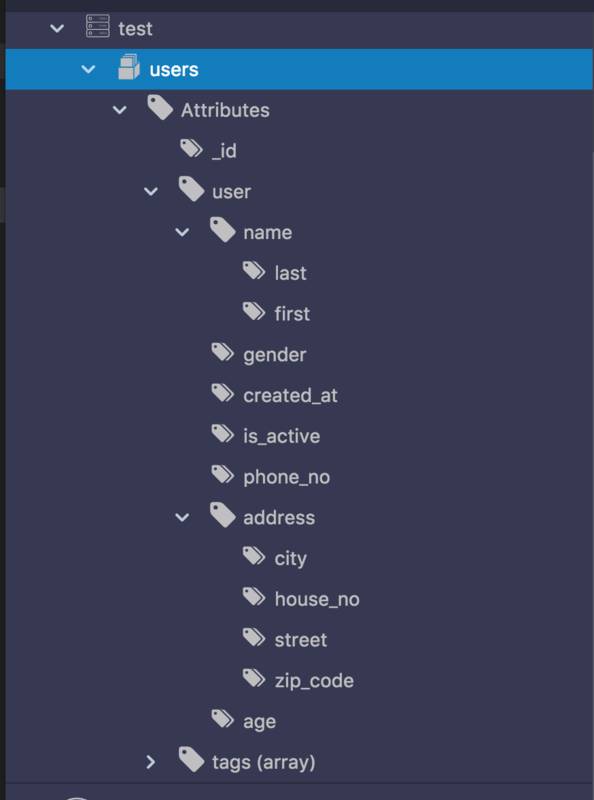
数据创建好以后,我们就完成了所有的准备工作。
连接到 MongoDB 以后,我们执行一些基本的find操作看看效率如何。比如,我想查找所有未到上学年龄的学生的纪录,例如下面的语句很快就返回了希望的结果:
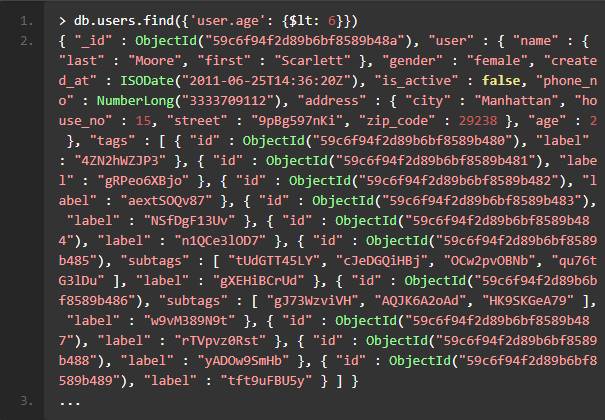
可能你看不出来这条语句具体执行了多长时间,以及执行的过程中扫描了多少个文档,此时强大的explain就派上用场了,你可以在上面的语句中加上 .explain("executionStats"),会得到 json 格式的explain输出。
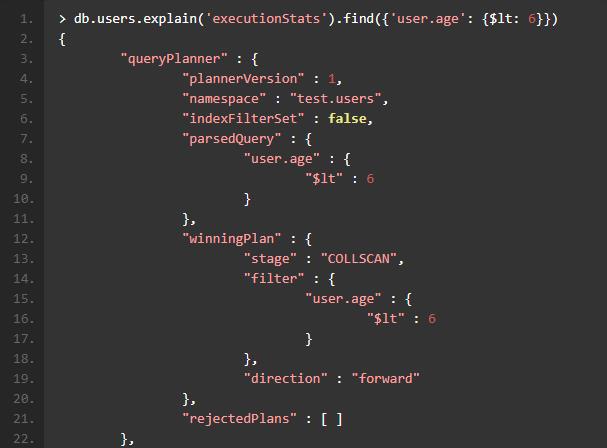
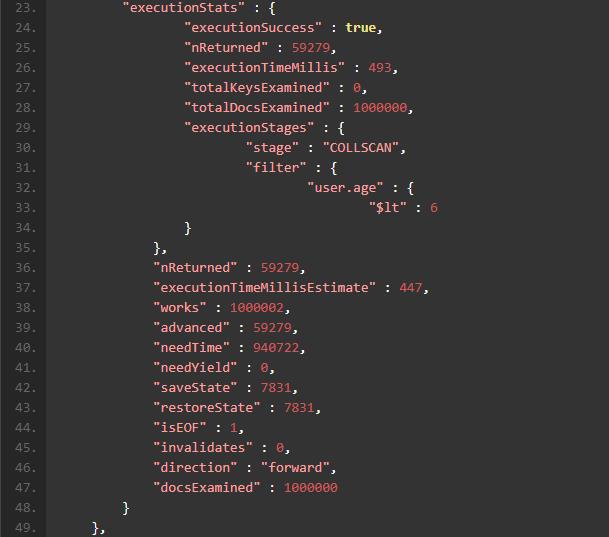
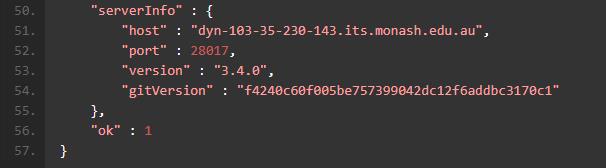
在 Mongo Shell 中浏览这些输出也许不是一件令人愉快的行为,全部文本界面,没有高亮提示,不能查询等等都是困扰我们的地方。幸运的是dbKoda这款强大的 IDE 为我们提供了可视化的分析方法。好打开dbKoda, 输入上面的find,然后运行工具栏中的问号,选择Execution Stats,会看到下面的输出结果:
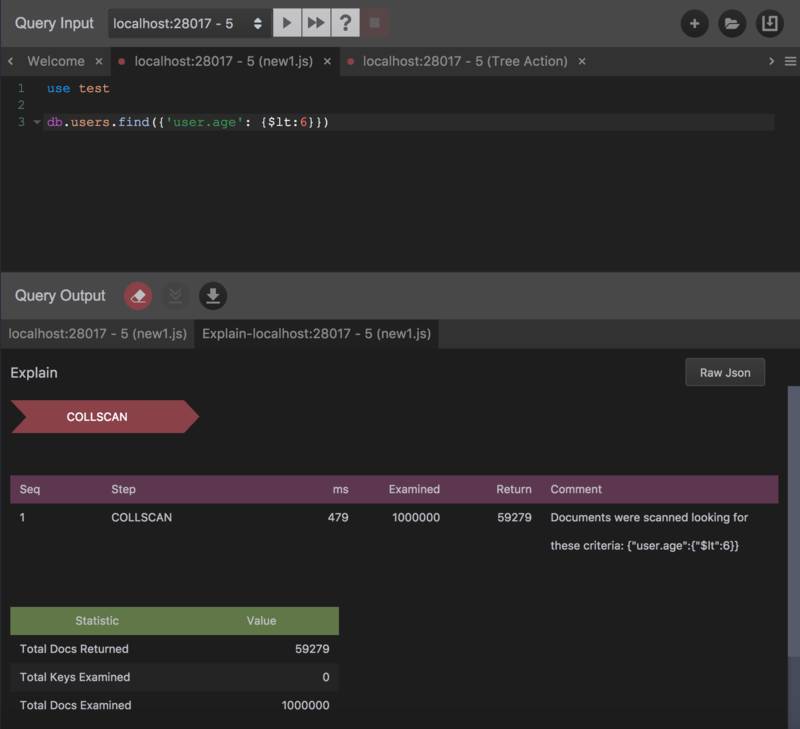
我来对这个输出进行一些解释。这个find方法包含了一个explain step,COLLSCAN,共有 59279 个符合条件的 Document,为了找出这些 Document 我们需要扫描一百万条记录,总共耗费的时间是 479 毫秒。熟悉 MongoDB 的同学们可能都会比较清楚,COLLSCAN是我们尽量避免的查询过程,因为他会对整个 Collection 进行一次全盘扫描,很多时候只是为了得到很少量的数据。正如上面的例子那样,为了得到六万条记录,我们需要检索全部一百万条 Document,可以不客气的说,这样的数据库设计是一个很糟糕的实践,因为我们进行了 90 多万次多余的检索比较。
没关系,对于初学者来说这正好是一个学习最佳实践的好机会。我会一步一步的告诉大家如何提高检索的效率。
刚才执行的find操作是针对用户年龄进行的,下面我们就对这个字段创建一个索引,我对 Mongo Shell 的命令不是很熟悉,所以下面的操作都是在dbKoda上进行。右键单机想要创建索引的 Collection,点Create Index打开创建索引界面,在上面选择希望创建索引的字段,这里的选择是age,如下图。当你在左边的界面上进行选择的时候,右边直接会出现对应的 Mongo Shell 命令,真的是非常方便。
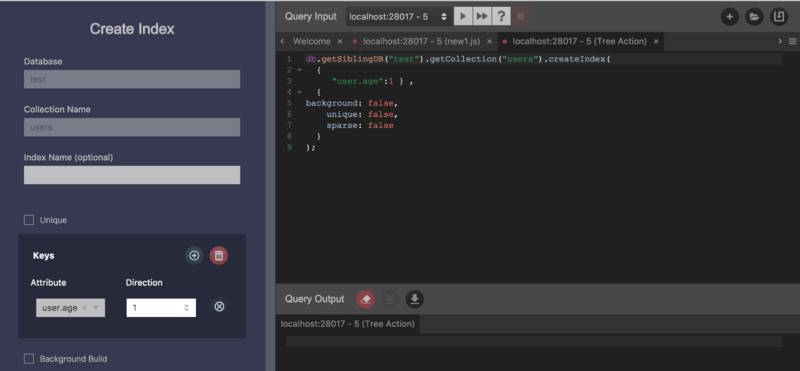
点击Execute按钮,创建成功后,刷新一下左边的 Tree View,会看到新建的索引已经显示在界面上了,user.age_1。
接下来我们再进行一遍刚才同样的explain操作:
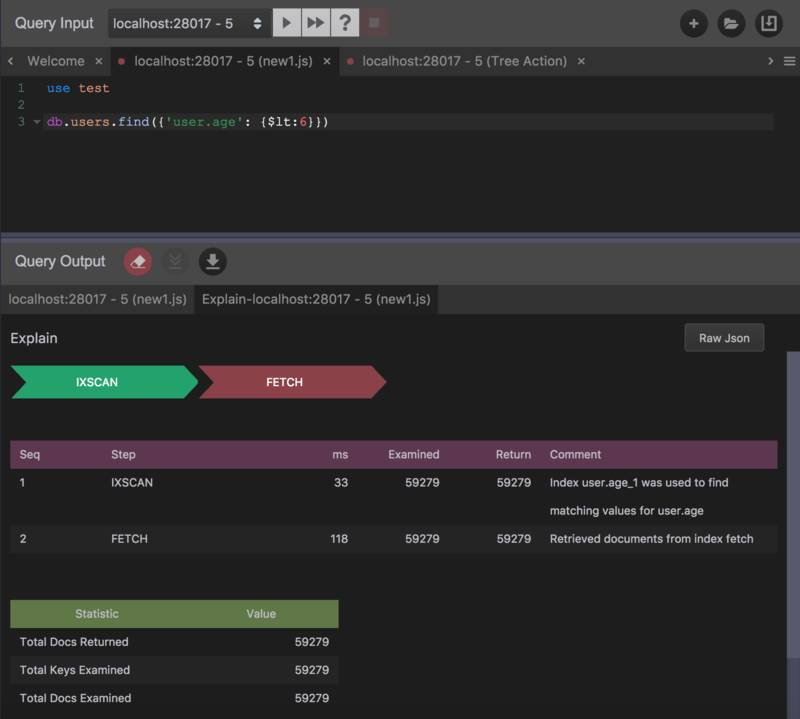
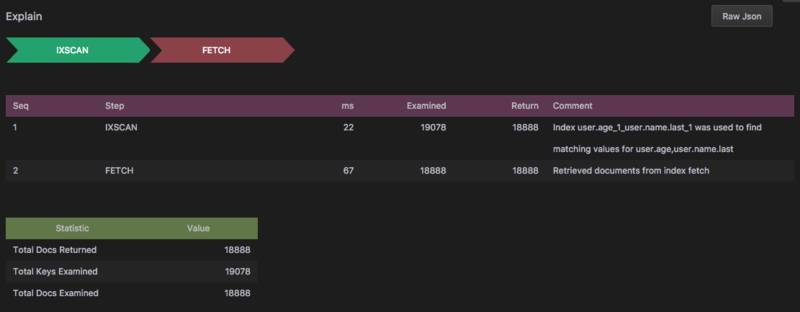
可以看到,新的结果里面包含了两次 step。IXSCAN和FETCH。
IXSCAN:在 explain 表格中可以看到,IXSCAN耗时 33 毫秒,扫描了 59279 个记录,并返回了 59279 条记录。在 Comment 列看到他使用了刚刚创建的user.age_1索引。FETCH:耗时 118 毫秒,将IXSCAN返回的纪录全部获取出来。
两个 step 总共耗时 151 毫秒,对比,刚才的 479 毫秒提高了将近 70%。
经过前面的优化以后,你可能对 MongoDB 的 Index 有了一定的了解,现在我们可以看一下在进行多个检索条件的时候如何查看他们的执行性能。
在刚才的检索基础上,我们加一个用户姓名条件:
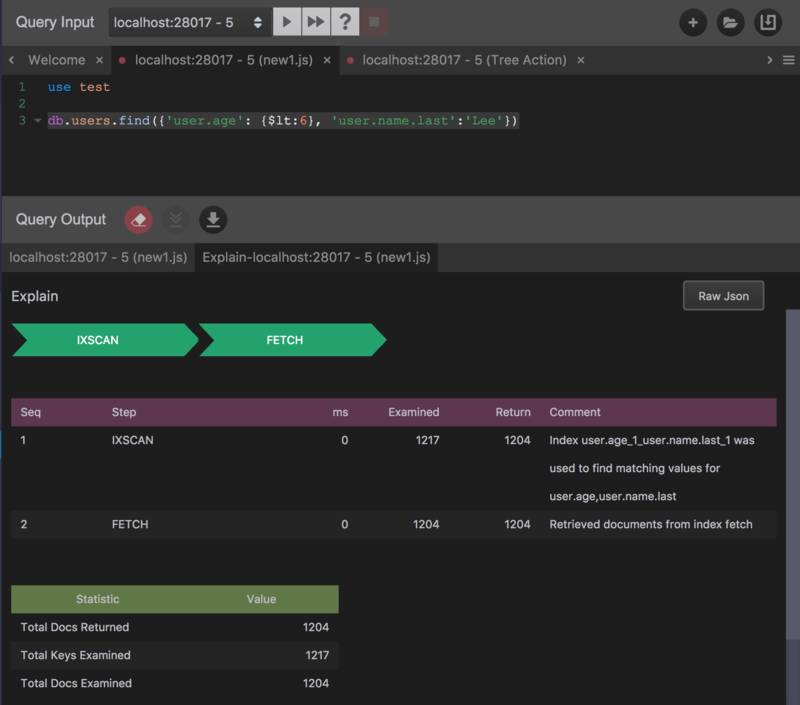
db.users.find({'user.age': {$lt:6}, 'user.name.last':'Lee'})。
下面是这个检索语句的 Explain 输出:
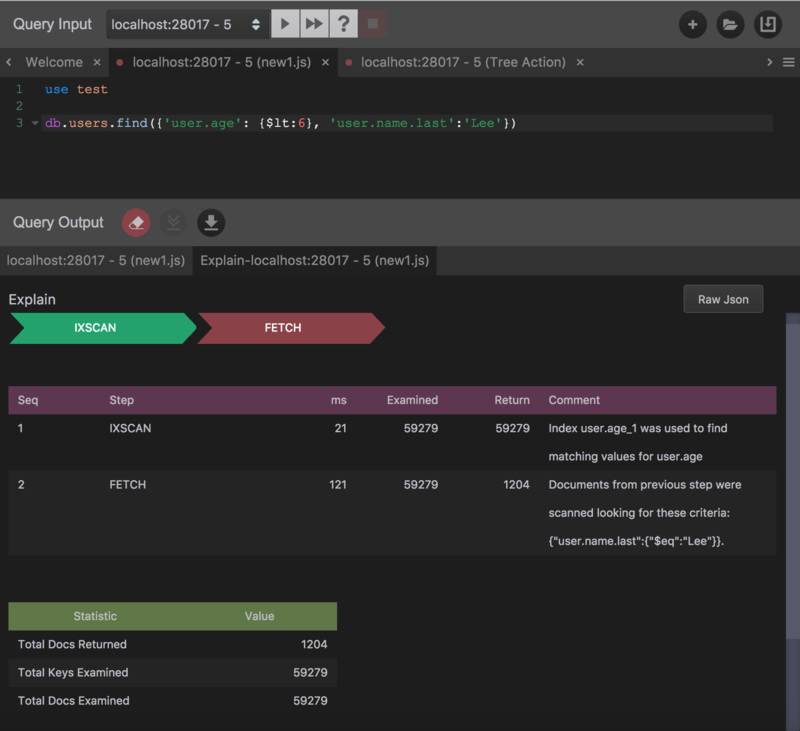
同样是出现了两次 Step,IXSCAN和FETCH,IXSCAN的返回结构和上次也是一样的,59279 条记录。不同的是,这次FETCH返回了 1204 条记录,过滤了 59279 - 1204 = 58075条,也就是说浪费了 58075 次 Document 检索。为什么会出现这样的情况?我们再来检查一下检索条件,上面包括两个逻辑与关系的条件,一个是用户年龄小于 6 岁,另一个是用户姓名叫Lee。对于第一个条件,我们已经知道,符合的纪录数是 59279,并且我们已经为用户年龄创建了一条索引,所以第一个IXSCAN没有任何不同。但是我们并没有对用户姓名做索引,所以第二个FETCH语句在 59279 条记录的基础上在此进行一次扫描,在符合年龄的用户中过滤掉不叫Lee的用户。此时,你可能会意识到58075这个数字是如何来的。看看下面的命令输出:
> db.users.find({'user.age': {$lt: 6},
'user.name.last': {$ne:'Lee'}}).count()
58075查询年龄在 6 岁以下,姓名不叫 Lee 的用户数正好是 58075。这样我们就清楚了这次 Explain 的结果。并且,聪明的你应该知道如何创建索引来解决这个多余的 58075 次比较了吧。在看下面的语句之前,我建议你现在自己的环境下运行一下你的索引,争取把这个 58075 变成 0。
如果你创建了下面的索引:
db.users.createIndex({'user.name.last':1})
然后对刚才的语句执行一次 Explain,可能得到的并不是你想要的结果:
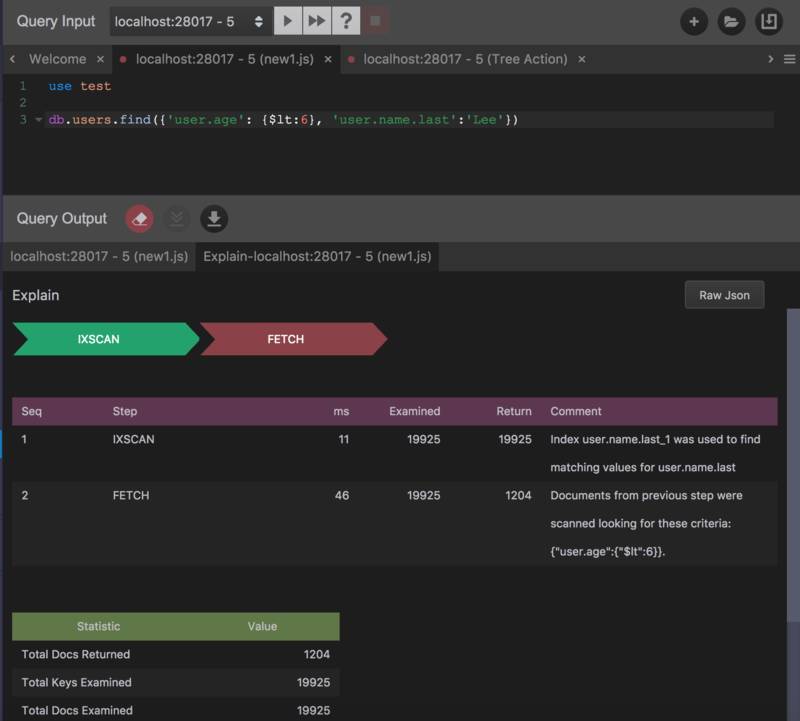
可以看到这次的结果同样是两个 Step,并且第一个IXSCAN用的 Index 是刚刚创建的用户姓名 (这一点可以通过 Step Comment 中看到),并不是年龄和用户姓名的组合。这是为什么呢?原因是 MongoDB 不会自动组合索引,我们刚才创建的只是两个独立的索引,一个是user.age, 一个是user.name.last;也就是说,我们需要创建一个用户年龄和姓名的组合索引。
db.users.createIndex({'user.age': 1, 'user.name.last':1'})
然后对查询语句执行 Explain 操作如下:
基本上整个执行过程的耗费时间是 0ms,可以说这样的检索算是一个非常好的索引查询。
通过上面的例子大家会对组合索引有一些了解,那么组合索引和单字段索引的区别在哪里呢?
对于一个基于年龄的索引来说,{'user.age': 1}, MongoDB 对这个字段创建一个生序的索引排序,索引数据放到一个年龄轴上,会是下面显示的样子:
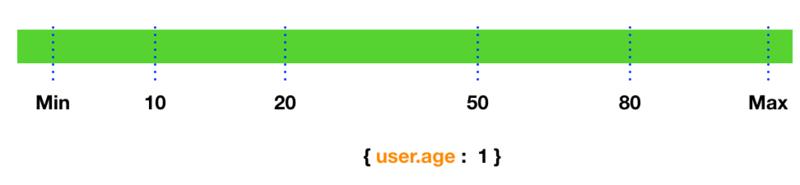
你也可以创建一个降序的索引,{'user.age': -1 },但是对于单字段索引来说,生序和降序对性能没有任何影响因为 MongoDB 可以按照任何方向检索数据。
在组合索引的情况下,结构比单字段索引要复杂一些,以上面的索引为例,db.users.createIndex({'user.age': 1, 'user.name.last':1'}),如下图所示:
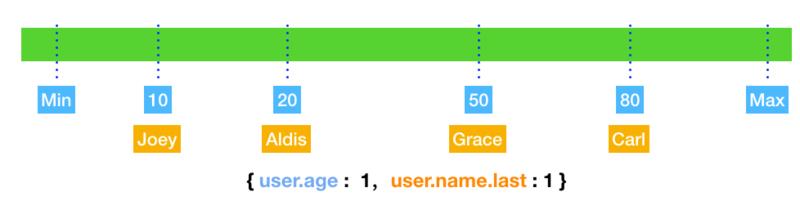
浅蓝色部分是user.age索引字段,橘黄色指的是user.name.last字段,可以看到 MongoDB 会把索引中的字段组合在一起创建。其中有一点与单字段索引不同的是生序和降序。刚才提到在单字段索引中,升降序并不会影响检索的性能,但是在组合索引的情况下,升降序的设置对排序sort有很大的影响。
首先是索引字段的顺序,当我们创建一个组合索引时,{'user.age': 1, 'user.name.last':1}, 里面的两个索引字段user.age和user.name.last的顺序要和sort语句中的顺序保持一致。例如:这样的排序顺序是不能被索引所覆盖到的:.sort{'user.name.last':1, 'user.age':1},原因是字段的前后顺序和创建的索引不同。看一下这个查询语句的 Explain 结果就清楚了:db.users.find({'user.age': {$gt: 5}, 'user.name.last': 'Lee'}).sort({'user.name.last':1, 'user.age': 1})。找到姓名叫 Lee 并且年龄大于 5 岁,并且按照姓名和年龄生序排序,得到下面的 explain 输出:
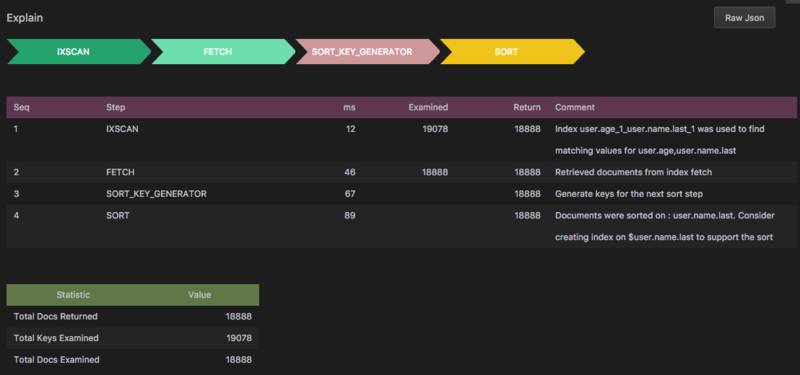
在 Explain 输出中我们可以看到共有 4 个执行步骤,前两个大家已经清楚了,一个是索引查询,另一个是获取查询到的纪录。那么从第三个开始就是我们的排序语句的执行步骤,生成用来排序的 key,并进行排序。从排序的 Comment 中可以看到dbKoda建议我们为user.name.last创建索引,但是我们明明已经创建过索引,为什么还提示创建呢,其实这就是创建索引时字段的顺序在影响我们的执行结果。很显然,后面两个排序的步骤是多余的。那如果我们按照索引的顺序来执行会得到什么样的结果呢?
db.users.find({'user.age': {$gt: 5}, 'user.name.last': 'Lee'}).sort({'user.age': 1, 'user.name.last':1})
从上面的输出可以看到,只要调整一下排序的字段顺序,就可以得到高效的索引执行过程。多余的那两个步骤已经被排除在外了。
再一点就是字段的升序和降序,如果在定义索引时字段都是生序,那么排序时只能用生序排序索引才能起作用,像这个排序是不会用到索引的:
.sort{'user.name.last':1, 'user.age': -1}。
有兴趣的同学可以通过上面的方法来验证一下升降序不同的情况下 Explain 的结果有多大的区别。
经过上面的分析我想大家对 MongoDB 中 Explain 的执行过程已经有了一定的了解,在开发过程中如果遇到类似的问题我们完全有能力通过 MongoDB 的内置功能来解决性能瓶颈。当然这篇文章只是一个开端,具体问题可能会比本文中的例子复杂很多,在今后的文章中我还会为大家介绍更多关于 MongoDB 查询性能方面的最佳实践。
https://www.dbkoda.com/
Use Indexes to Sort Query Results:
https://docs.mongodb.com/manual/tutorial/sort-results-with-indexes/
作者介绍
赵翼,从北京理工大学毕业以后从事IT工作已经10余年,接触过的项目种类繁多,有Web,Mobile,医疗器械,社交网络,大数据存储等。目前就职于SouthbankSoftware,从事NoSQL,MongoDB方面的开发工作。曾在GE,ThoughtWorks,元气兔担任前后端开发,技术总监等职位。
今日荐文
为什么阿里会选择 Flink 作为新一代流式计算引擎?
深度学习零基础,如何在 9 周时间内,学会利用卷积网络实现对话 / 地主机器人,用 tensorflow 进行图片分类/人脸识别/模仿大师画作风格等实战技能?
我们邀请到资深大数据专家高扬和高级软件架构师卫峥两位老师开讲「深度学习,从入门到精通实战」课程,同学们将通过最浅显易懂的方式入门进阶深度学习。想了解更多,请扫海报二维码,点击阅读原文直接进入「课程链接」。
以上是关于如何通过MongoDB自带的Explain功能提高检索性能?的主要内容,如果未能解决你的问题,请参考以下文章