MongoDB——explain执行计划详解
Posted 小志的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MongoDB——explain执行计划详解相关的知识,希望对你有一定的参考价值。
目录
一、explain执行计划使用的前提条件
- 查询是否使用了索引
- 索引是否减少了扫描的记录数量
- 是否存在低效的内存排序
二、explain执行计划的语法
-
explain()方法的形式
db.collection.find().explain(<verbose>) -
verbose 可选参数
表示执行计划的输出模式,默认queryPlanner模式名字 描述 queryPlanner 执行计划的详细信息,包括查询计划、集合信息、查询条件、最佳执行计划、查询方式和 MongoDB 服务信息等 exectionStats 最佳执行计划的执行情况和被拒绝的计划等信息 allPlansExecution 选择并执行最佳执行计划,并返回最佳执行计划和其他执行计划的执行情况
三、explain执行计划的示例
3.1、数据准备
-
准备数据集,执行脚本
var tags = ["nosql","mongodb","document","developer","popular"]; var types = ["technology","sociality","travel","novel","literature"]; var books=[]; for(var i=0;i<50;i++) var typeIdx = Math.floor(Math.random()*types.length); var tagIdx = Math.floor(Math.random()*tags.length); var tagIdx2 = Math.floor(Math.random()*tags.length); var favCount = Math.floor(Math.random()*100); var username = "xx00"+Math.floor(Math.random()*10); var age = 20 + Math.floor(Math.random()*15); var book = title: "book-"+i, type: types[typeIdx], tag: [tags[tagIdx],tags[tagIdx2]], favCount: favCount, author: name:username,age:age ; books.push(book) db.books1.insertMany(books);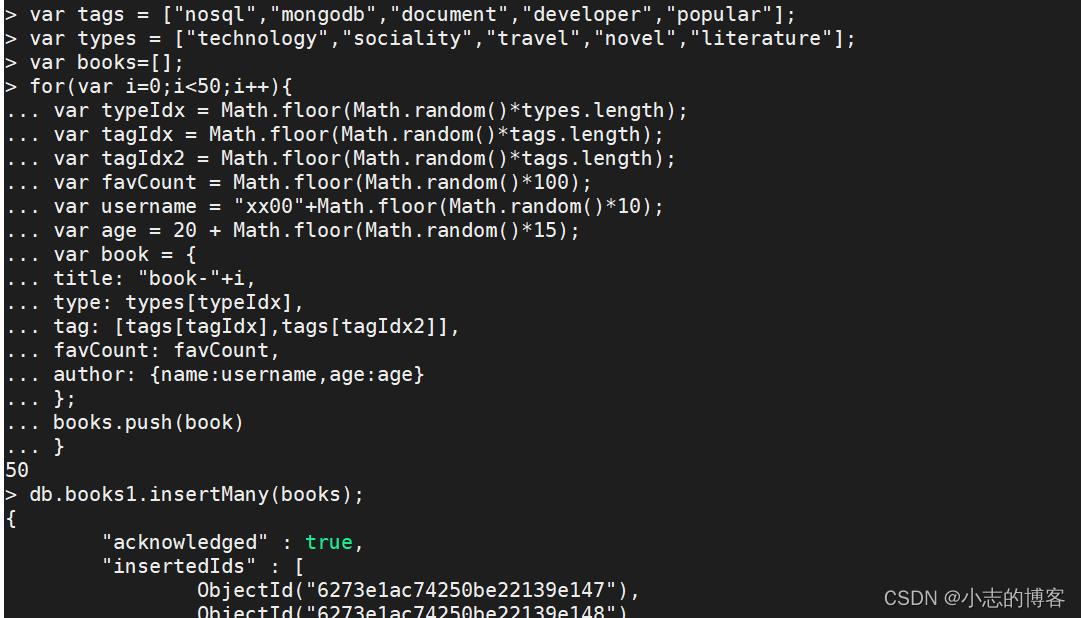
-
查看初始化的数据
db.books1.find()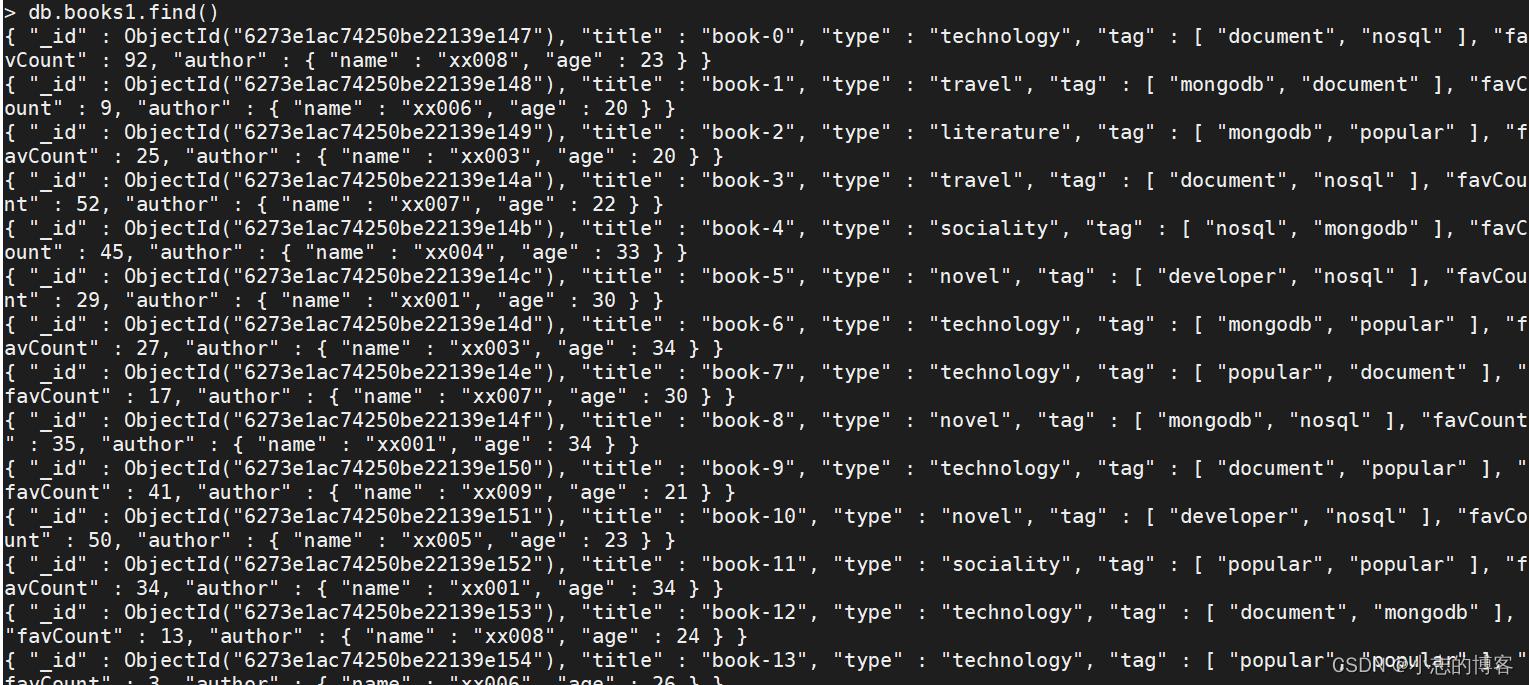
3.2、执行explain执行计划指定queryPlanner参数
-
未创建title的索引,执行explain指定queryPlanner参数
db.books1.find(title:"book-1").explain("queryPlanner")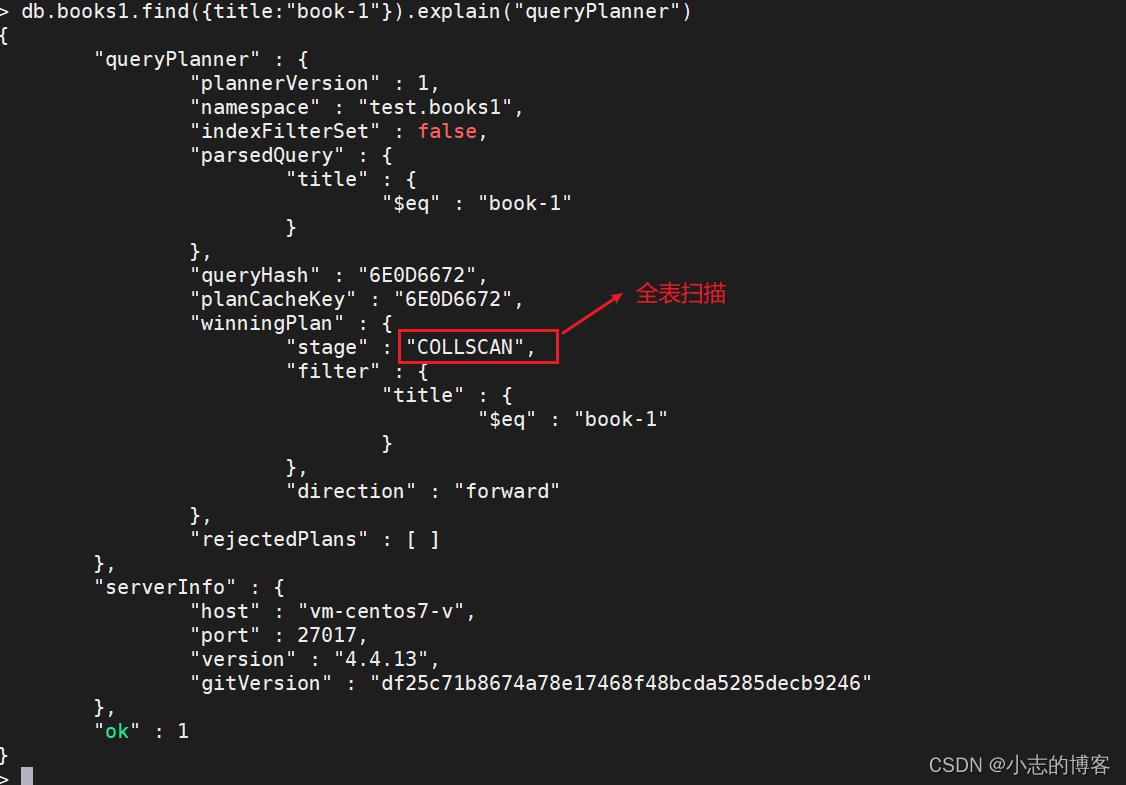
-
explain执行中字段的解释
字段名称 描述 plannerVersion 执行计划的版本 namespace 查询的集合 indexFilterSet 是否使用索引 parsedQuery 查询条件 winningPlan 最佳执行计划 stage 查询方式 filter 过滤条件 direction 查询顺序 rejectedPlans 拒绝的执行计划 serverInfo mongodb服务器信息
3.3、执行explain执行计划指定executionStats参数
-
executionStats 模式的返回信息中包含了 queryPlanner 模式的所有字段,并且还包含了最佳执行计划的执行情况
-
创建title索引
db.books1.createIndex(title:1)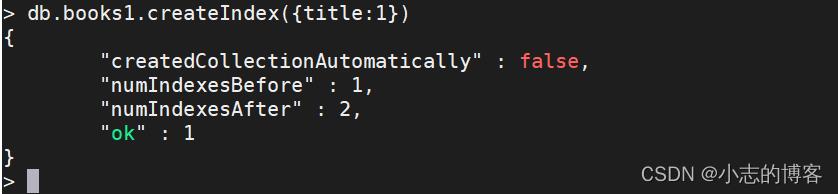
-
执行explain指定executionStats参数
db.books1.find(title:"book-1").explain("executionStats")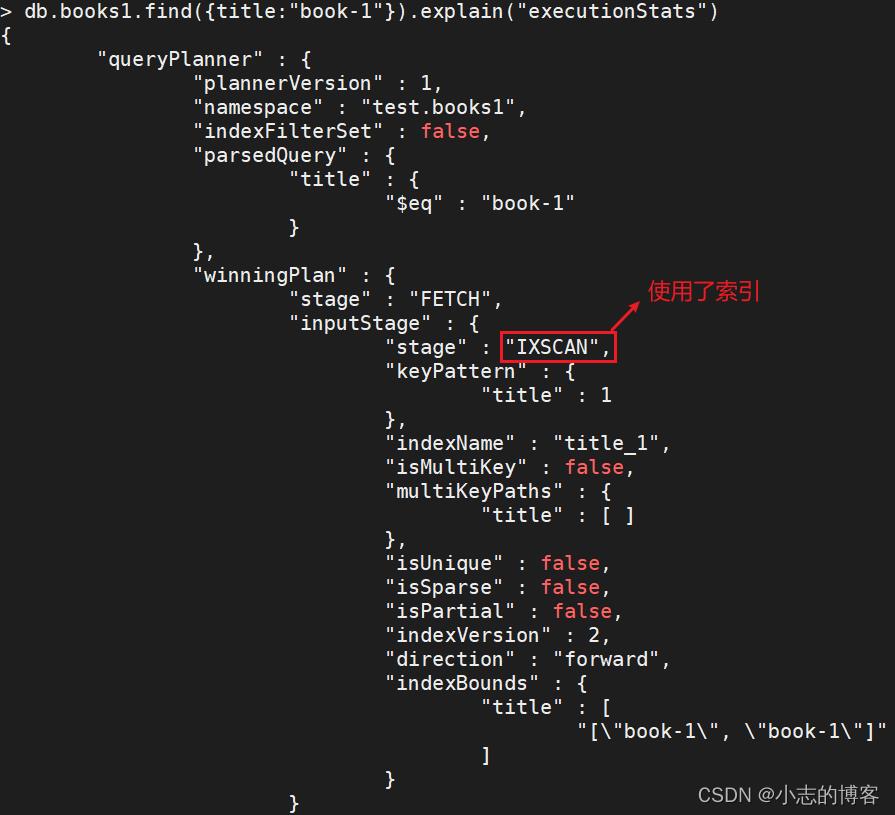
-
explain执行中字段的解释
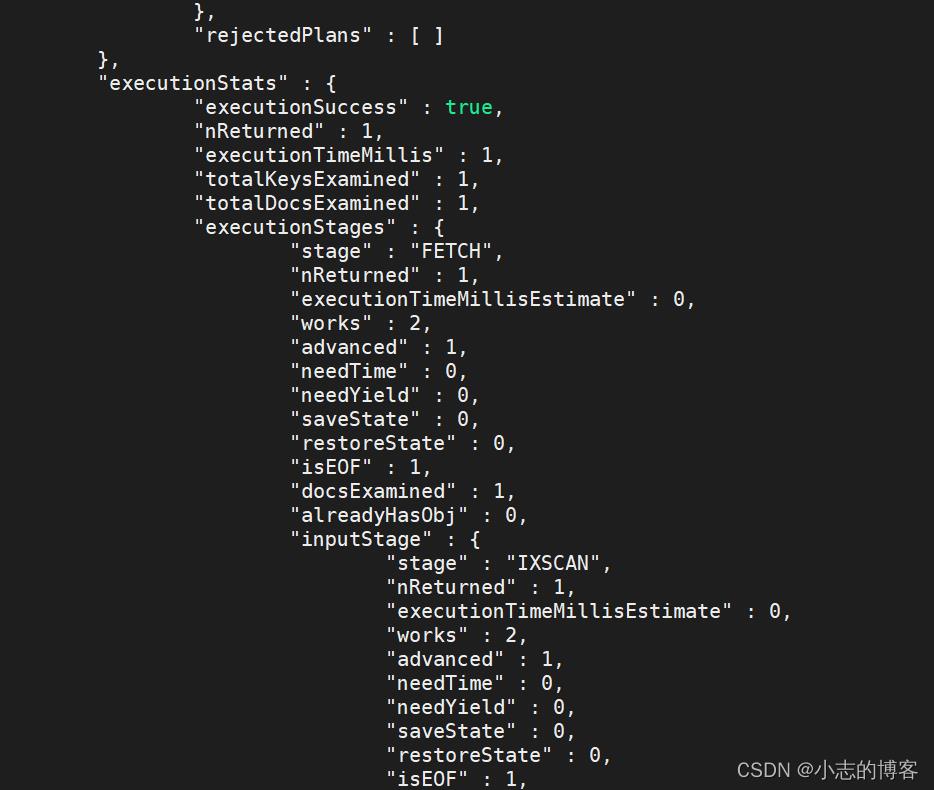
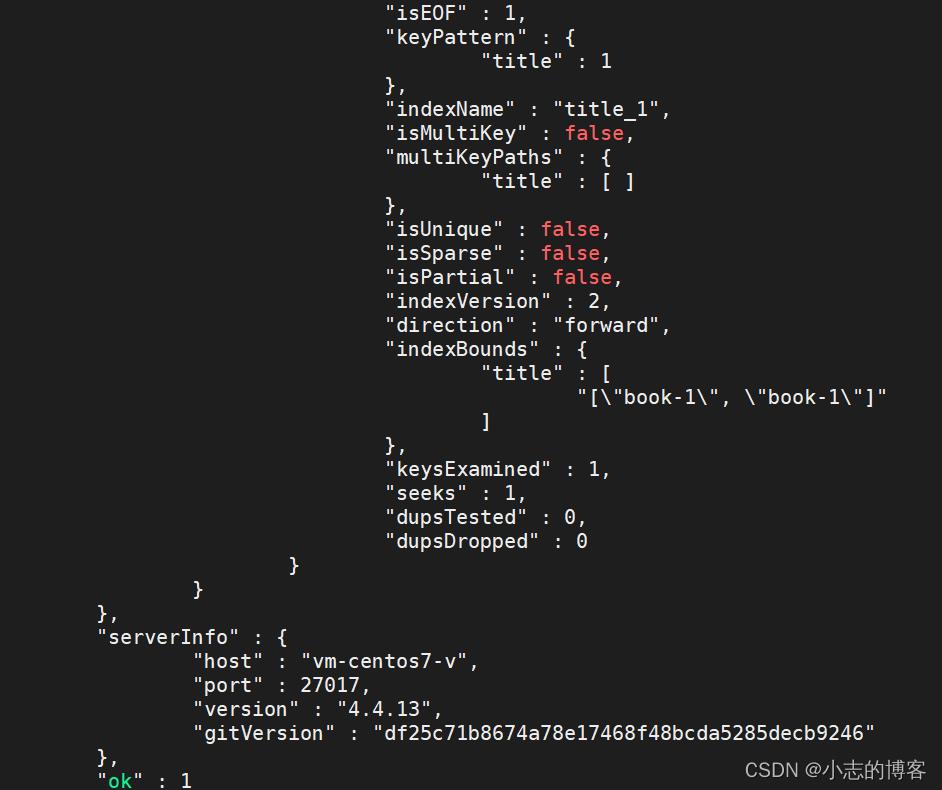
字段名称 描述 winningPlan.inputStage 用来描述子stage,并且为其父stage提供文档和索引关键字 winningPlan.inputStage.stage 子查询方式 winningPlan.inputStage.keyPattern 所扫描的index内容 winningPlan.inputStage.indexName 索引名 winningPlan.inputStage.isMultiKey 是否是Multikey。如果索引建立在array上,将是true executionStats.executionSuccess 是否执行成功 executionStats.nReturned 返回的个数 executionStats.executionTimeMillis 这条语句执行时间 executionStats.executionStages.executionTimeMillisEstimate 检索文档获取数据的时间 executionStats.executionStages.inputStage.executionTimeMillisEstimate 扫描获取数据的时间 executionStats.totalKeysExamined 索引扫描次数 executionStats.executionStages.isEOF 是否到达 steam 结尾,1 或者 true 代表已到达结尾 executionStats.executionStages.works 工作单元数,一个查询会分解成小的工作单元 executionStats.executionStages.advanced 优先返回的结果数 executionStats.executionStages.docsExamined 文档检查数
3.4、执行explain执行计划指定allPlansExecution参数
-
allPlansExecution返回的信息包含 executionStats 模式的内容,且包含allPlansExecution:[]块
"allPlansExecution" : [ "nReturned" : <int>, "executionTimeMillisEstimate" : <int>, "totalKeysExamined" : <int>, "totalDocsExamined" :<int>, "executionStages" : "stage" : <STAGEA>, "nReturned" : <int>, "executionTimeMillisEstimate" : <int>, ... , ... ]
3.5、 stage状态
| 状态 | 描述 |
|---|---|
| COLLSCAN | 全表扫描 |
| IXSCAN | 索引扫描 |
| FETCH | 根据索引检索指定文档 |
| SHARD_MERGE | 将各个分片返回数据进行合并 |
| SORT | 在内存中进行了排序 |
| LIMIT | 使用limit限制返回数 |
| SKIP | 使用skip进行跳过 |
| IDHACK | 对_id进行查询 |
| SHARDING_FILTER | 通过mongos对分片数据进行查询 |
| COUNTSCAN | count不使用Index进行count时的stage返回 |
| COUNT_SCAN | count使用了Index进行count时的stage返回 |
| SUBPLA | 未使用到索引的$or查询的stage返回 |
| TEXT | 使用全文索引进行查询时候的stage返回 |
| PROJECTION | 限定返回字段时候stage的返回 |
3.6、执行计划的返回结果中尽量不要出现以下stage
- COLLSCAN(全表扫描)
- SORT(使用sort但是无index)
- 不合理的SKIP
- SUBPLA(未用到index的$or)
- COUNTSCAN(不使用index进行count)
以上是关于MongoDB——explain执行计划详解的主要内容,如果未能解决你的问题,请参考以下文章