python爬虫实战—喜欢下载什么小说,由自己说了算,超详细小说下载爬虫教程
Posted autofelix
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫实战—喜欢下载什么小说,由自己说了算,超详细小说下载爬虫教程相关的知识,希望对你有一定的参考价值。
〝 古人学问遗无力,少壮功夫老始成 〞
python爬虫实战—喜欢下载什么小说,由自己说了算,超详细小说下载爬虫教程,使用python下载小说,小说随时随地想看就看,难道不舒服吗?学习python下载小说的思路才是最重要的,希望能给想学习爬虫的小伙伴们打开独立思考的门窗,引导你们独立分析问题的思路。如果这篇文章能给你带来一点帮助,希望给飞兔小哥哥一键三连,表示支持,谢谢各位小伙伴们。
注意:源码已上传,请点击这里开源python下载小说,欢迎大家work、fork、star三连,里面还有隐藏福利哦~
目录
一、分析小说下载流程
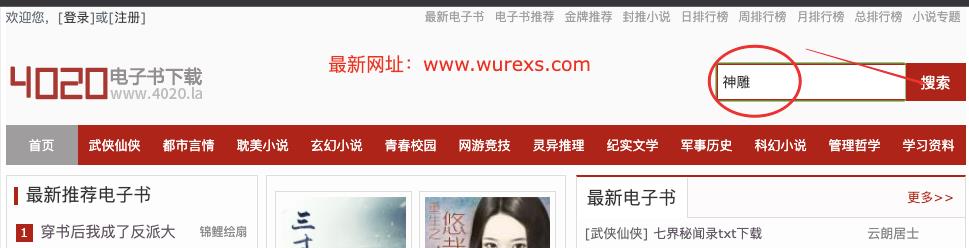
- 下载小说,我们需要去找一个小说网站进行下载逻辑分析
- 这里我们选择的小说网站是:4020电子书
- 因为小说内容很容易被检测违规,导致网站被封,如果你访问的时候已经无法访问,请选择其他平台,分析的下载逻辑是互通的,因为万法归一
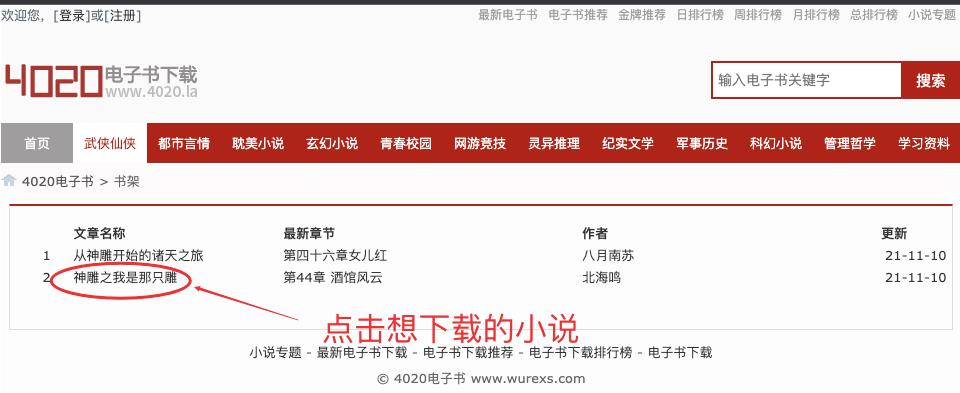
- 小说下载逻辑应该是:选择搜索框、输入关键字、搜索小说、在搜索结果中选择自己想要下载的小说、然后将小说的每一个章节下载到本地的同一个文件中即可
二、分析搜索链接
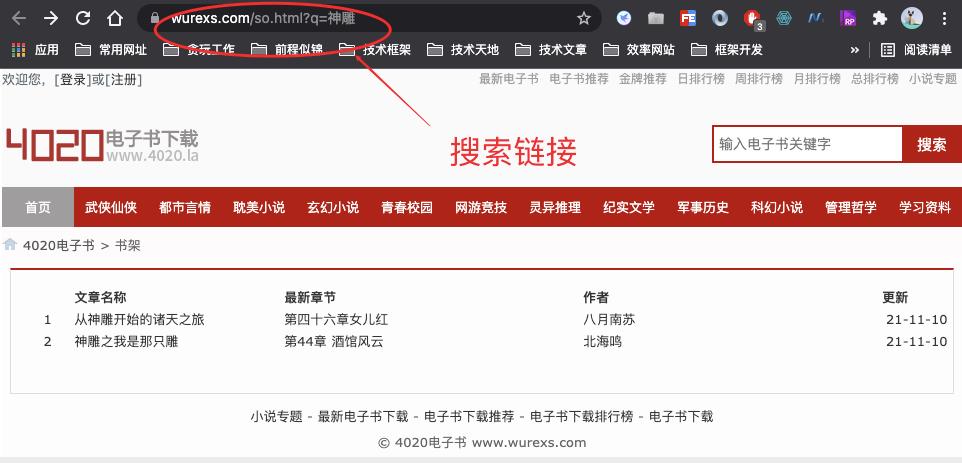
- 因为我们需要找到搜索结果页,查看有多少本关键字小说
- 可以看出 www.wurexs.com/so.html?q=关键字 就是搜索结果页
- 那我们通过python代码可以这样写
keywords = input('请输入关键词:') or "神雕"
response = requests.get('https://www.wurexs.com/so.html?q={}'.format(keywords))三、获取小说列表
- 获取搜索结果页面有多少本小说和小说对应的地址
- 使用BeautifulSoup分析搜索页的Html文档结构
fictionsList = []
response = requests.get('https://www.wurexs.com/so.html?q={}'.format(keywords))
offset = 0
soup = BeautifulSoup(response.content, 'lxml')
for fiction in soup.find('table', class_='grid').find_all('tr'):
offset += 1
if offset != 1:
fictionDom = fiction.find('td', class_='even')
fictionName = fictionDom.a.string
MenuUrl = fictionDom.a['href']
fictionsList.append(fictionName + "#" + MenuUrl)
print('---搜索结果,共{}本小说...' . format(len(fictionsList)))四、选择小说序号
- 选择想要下载的小说序号
- 默认选择第一本下载
for i in range(len(fictionsList)):
print('{} {}' .format(i, fictionsList[i].split('#')[0]))
k = input('---请选择你想要下载的小说序号:')
k = int(k) if k else 0五、获取小说章节地址
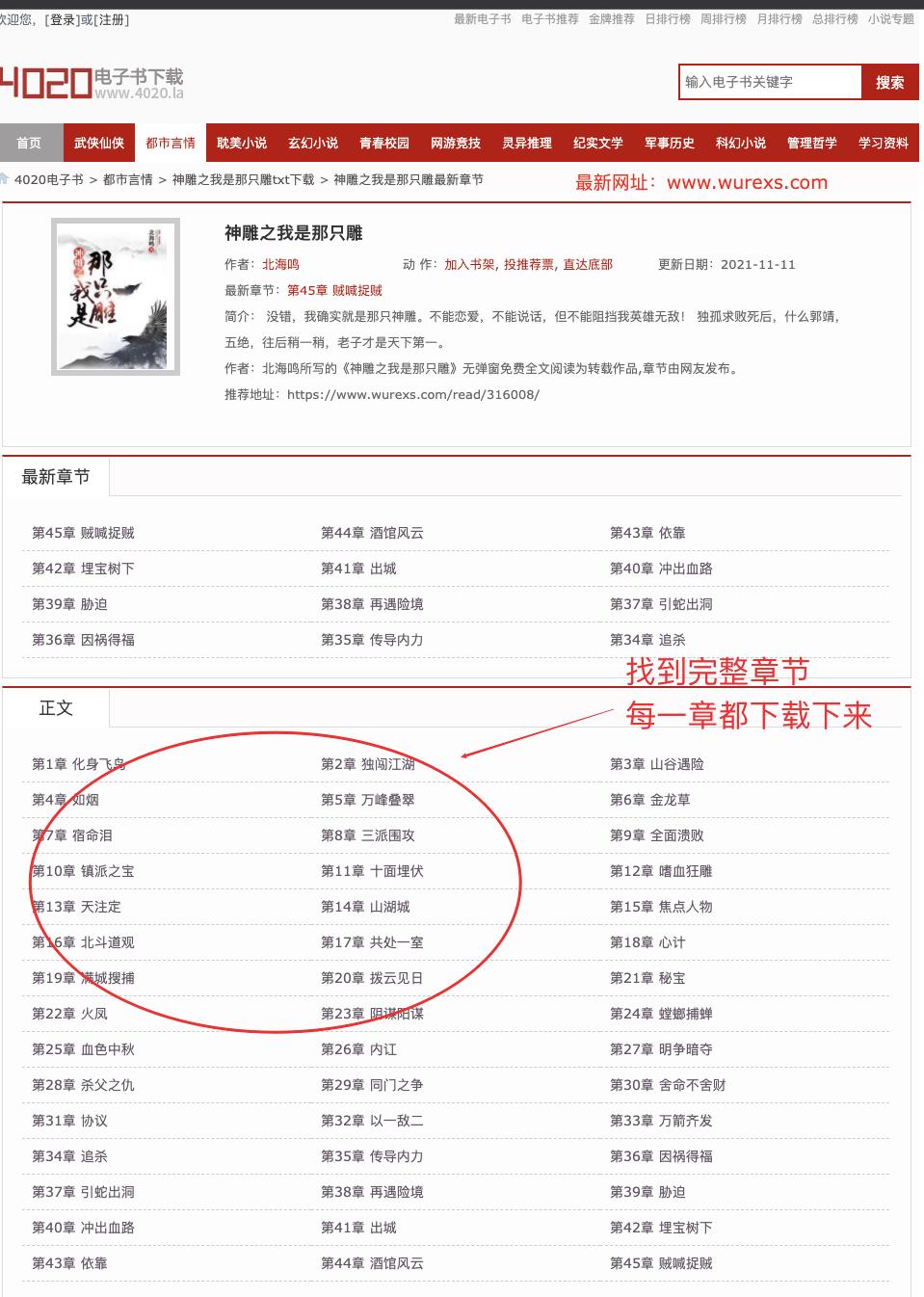
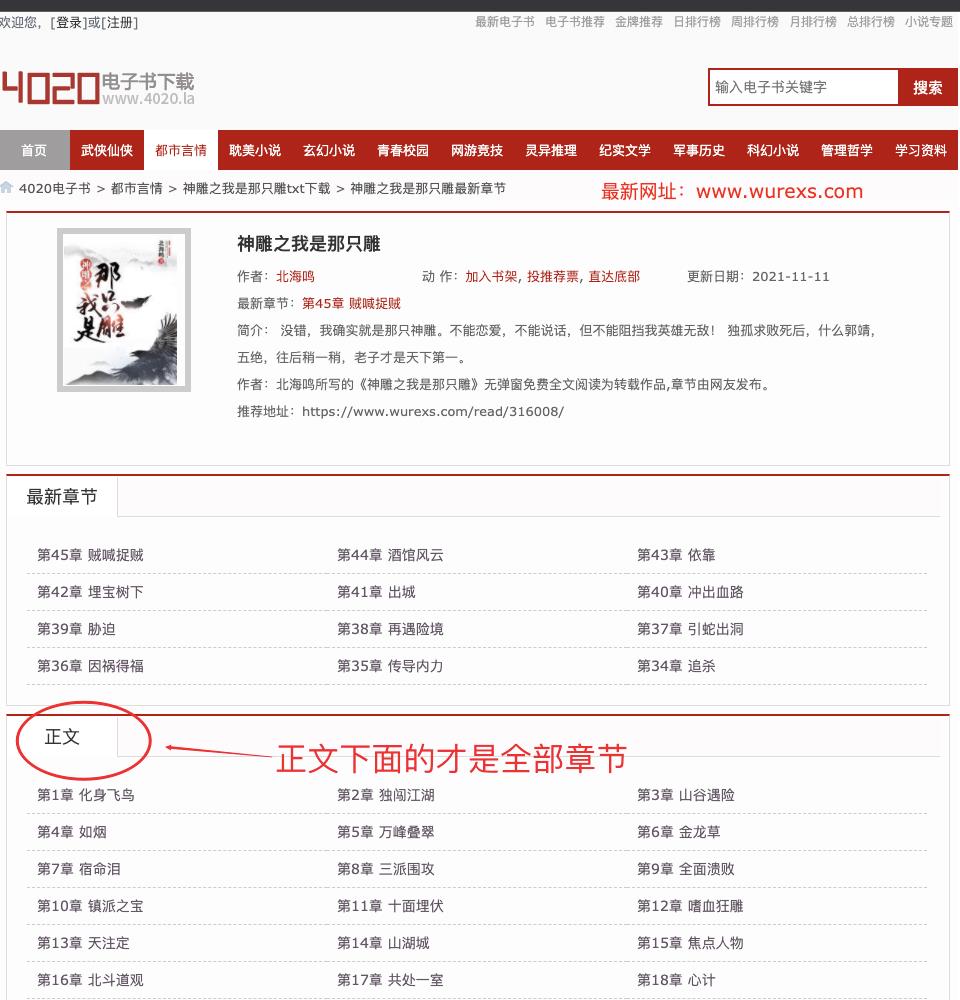
- 进入小说详情页,获取小说每一个章节的地址
- 因为正文下面才是所有章节,所以我们可以通过正文来定位每个章节的详情
chapterList = []
response = self.request(self.rootUrl + MenuUrl)
soup = BeautifulSoup(response.content, 'lxml')
allChapterUrl = soup.find(text='正文').find_parent("div", class_='showBox').find_all('li')
if allChapterUrl:
for chapter in allChapterUrl:
chapterName = chapter.a.string
chapterUrl = chapter.a['href']
chapterList.append(chapterName + "#" + MenuUrl + chapterUrl)
return chapterList六、下载每个章节内容
- 获取到每个章节和章节地址后
- 我们需要将章节详情下载下来保存到同一个文件中
- 详细代码请访问飞兔小哥的开源库 开源python下载小说
offset = 0
for chapter in chapterList:
offset += 1
chapterName, chapterUrl = [item for item in chapter.split('#')]
response = self.request(self.rootUrl + chapterUrl)
soup = BeautifulSoup(response.content, 'lxml')
with open('{}/{}.txt' . format(savePath, fictionName), "a", encoding="utf-8") as f:
f.write(chapterName + '\\n')
for str in soup.find(id='content').strings:
if 'www.wrlwx.com' in str:
continue
if 'www.shukuai.com' in str:
continue
f.writelines(str)
f.write('\\n\\n')
print("{} 正在下载, 当前{}, 进度{}/{}" 七、下载预览
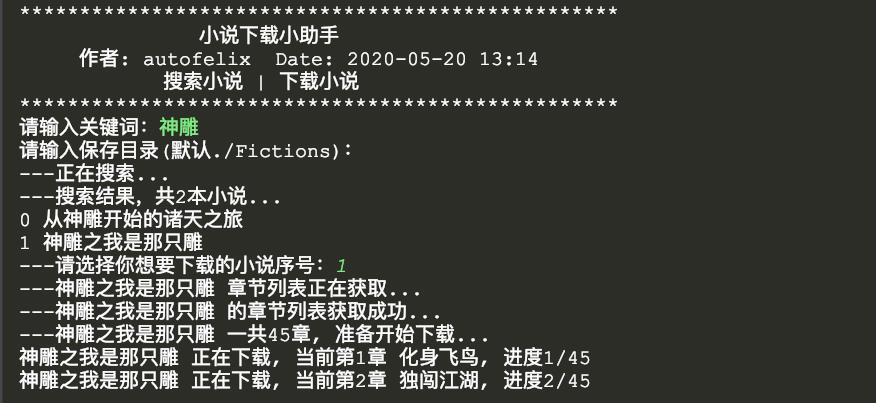
- 我们将代码运行起来后,输入关键字即可下载
以上是关于python爬虫实战—喜欢下载什么小说,由自己说了算,超详细小说下载爬虫教程的主要内容,如果未能解决你的问题,请参考以下文章