python实战爬取起点中文网自制小说阅读器
Posted 一条IT
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python实战爬取起点中文网自制小说阅读器相关的知识,希望对你有一定的参考价值。
哈喽,大家好,我是一条。
相信有很多爱看小说的朋友,一定也有很多爱听小说的朋友。
今天就教大家先爬取起点中文网,再自制小说阅读器。
起点中文网爬虫
一条从初中开始看小说,那时3G刚普及,wifi更没有现在这么常见,所以都是把小说下载下来看,所以找一个免费的下载源就尤为重要。
直到接触到爬虫,简直太爽了!
1.涉及知识点
requests请求- 利用
lxml进行xpath解析 - python文件操作
2.实现步骤
url
百度搜索起点中文网,得到所有小说的url:https://www.qidian.com/all
解析网页
通过开发者工具,分析小说名字的xpath路径
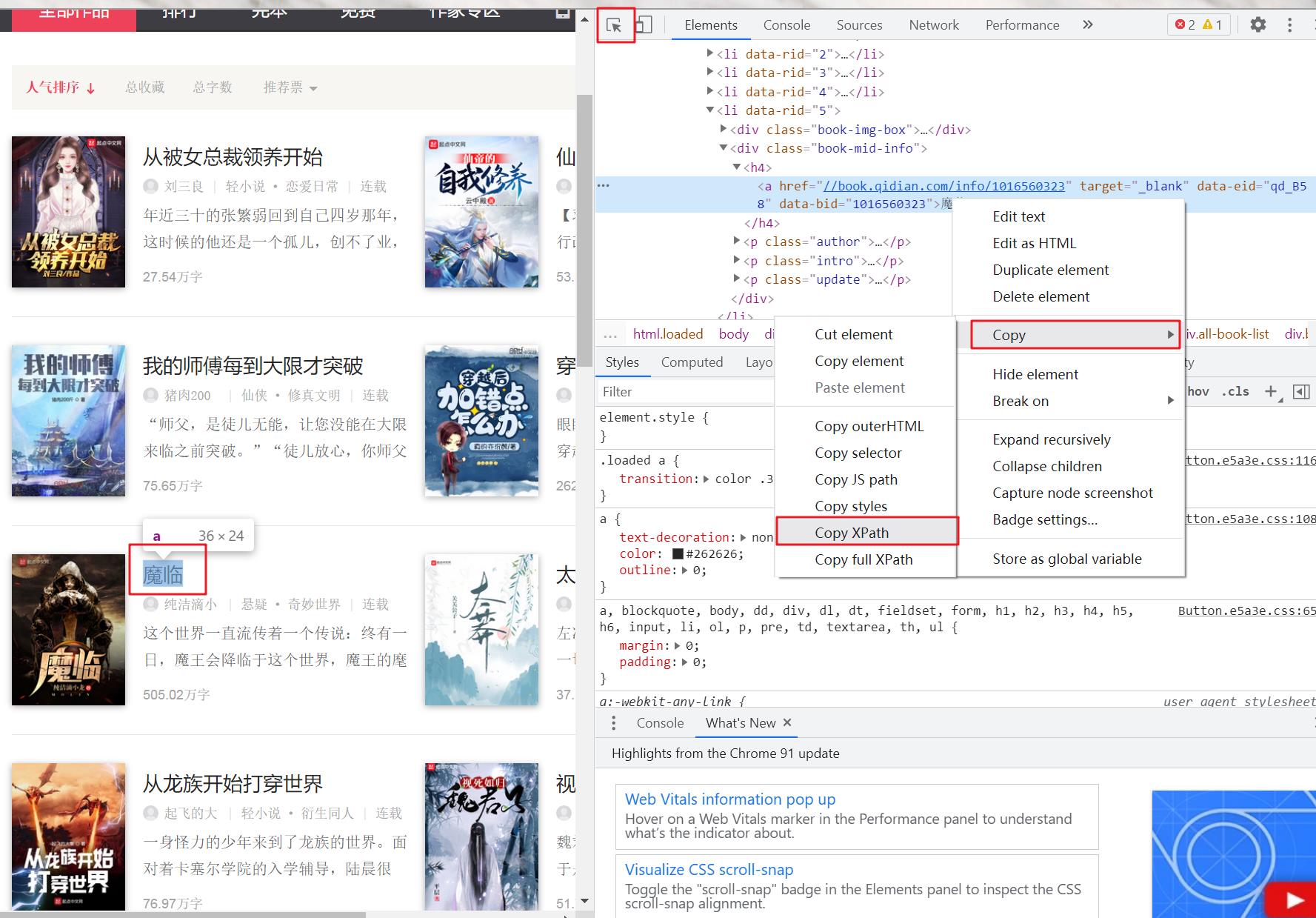
写入文件
3.代码实现
import requests
import os
from lxml import etree
url="https://www.qidian.com/all"
rep=requests.get(url)
html=etree.HTML(rep.text)
name=html.xpath('//div[@class="book-mid-info"]/h4/a/text()')
src=html.xpath("//div[@class='book-mid-info']/h4/a/@href")
#拉链
for i,j in zip(name,src):
if os.path.exists(i)==False:
os.mkdir(i)
rep1=requests.get("http:"+j+"#Catalog")
html1=etree.HTML(rep1.text)
zhname=html1.xpath('//ul[@class="cf"]/li/a/text()')
zhsrc=html1.xpath('//ul[@class="cf"]/li/a/@href')
for zi,zj in zip(zhname,zhsrc):
print(zi,zj)
zhreq=requests.get("http:"+zj)
zhhtml=etree.HTML(zhreq.text)
consrc="\\n".join(zhhtml.xpath('//div[@class="read-content j_readContent"]/p/text()'))
filename=i+"\\\\"+zi+".txt"
print(filename)
with open(filename,"a",encoding="utf-8") as f:
f.write(consrc)
4.效果展示


自制小说阅读器
1.涉及知识点
- 百度人工智能API
- python打包
2.实现步骤
从文件或键盘获取文本
利用百度API将文字合成语音
3.代码实现
from aip import AipSpeech
def reader():
app_id="your app_id"
api_key="api_key"
secret_key="secret_key"
client=AipSpeech(app_id,api_key,secret_key)
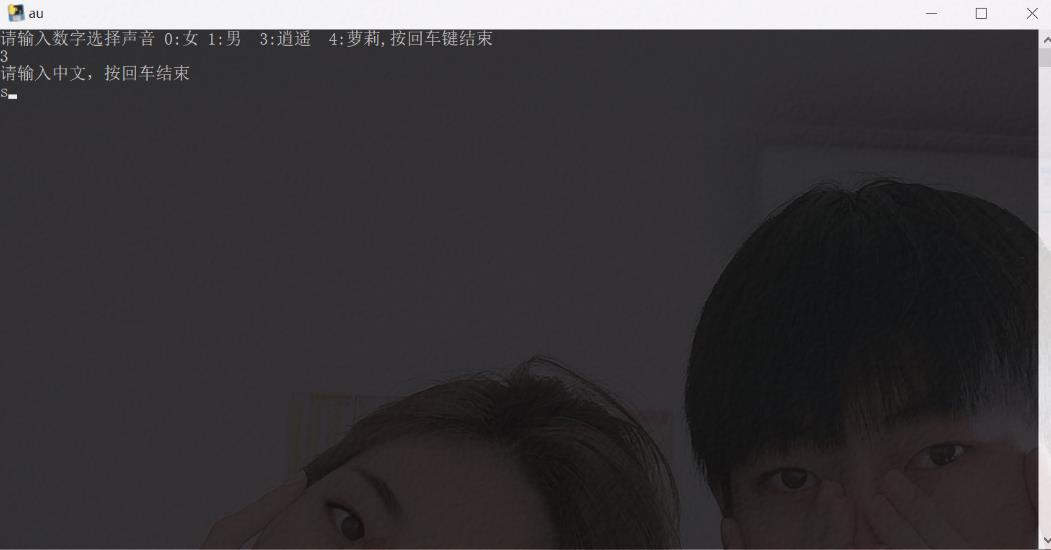
print("请输入数字选择声音 0:女 1:男 3:逍遥 4:萝莉,按回车键结束")
num=input()
print("请输入中文,按回车结束")
strr="大奉京兆府,监牢。许七安幽幽醒来,嗅到了空气中潮湿的腐臭味,令人轻微的不适,胃酸翻涌。这扑面而来的臭味是怎么回事,家里的二哈又跑床上拉屎来了....根据熏人程度,怕不是在我头顶拉的....许七安家里养了一条狗,品种哈士奇,俗称二哈。"
result=client.synthesis(strr,"zh",1,{
'vol': 5, #音量
'spd': 5, #语速
'pit': 9, #语调
'per': int(num), #音色
#0:女 1:男 3:逍遥 4:萝莉
})
with open("./audio.wav","wb") as f:
f.write(result)
if __name__ == '__main__':
reader()
4.效果展示
我是一条,一个在互联网摸爬滚打的程序员。
道阻且长,行则将至。大家的 【点赞,收藏,关注】 就是一条创作的最大动力,我们下期见!
注:关于本篇博客有任何问题和建议,欢迎大家留言!
以上是关于python实战爬取起点中文网自制小说阅读器的主要内容,如果未能解决你的问题,请参考以下文章