Python简单爬虫第六蛋!(完结撒花)
Posted 星辰戟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python简单爬虫第六蛋!(完结撒花)相关的知识,希望对你有一定的参考价值。
第六讲:
今天我们来实战一个项目,我本人比较喜欢看小说,有一部小时叫《圣墟》不知道大家有没有听说过,个人觉得还是不错的,现在联网的时候,都可以随时随地用手机打开浏览器搜索查看,但是有时候也会遇到没有网络的情况,这个就很扎心了,有什么办法呢?所以这个项目基于这么一个现实背景来分析实现一下,把我们前几次讲到一些技术方法都运用一遍。
(有人可能会说直接下载一个txt格式的小说文本文件不就好了,虽然是挺方便的,但是懒惰是不好的习惯,而且也没有运用到所学的知识,那么我们何必要学习呢?为什么要学,看完实例就知道了!)
现在开始我们的实战项目,首先我们想到我们的爬虫可以访问到一个网站,能把网站的HTML文本内容中有用的信息提取处理,如果我们需要的小说的内容都在这个文本里面就好了,那么我们实现起来就比较容易,毕竟我们之前都学过怎么爬取,假如我们爬取到了内容,这些内容又应该怎么保存起来呢,这里就想到了文件处理,把小说内容都转储到一个txt文件里面。
首先有了这么一个大概思路:
① 爬取小说网页的内容
② 转储到一个txt文件里面
我们来详细分析第一个步骤,既然是要爬取小说的网页,那么我们就要选择一个比较容易爬取的网站,这里我们经过多次审查,最终确定了一个网 站:http://www.biqiuge.com/book/4772/
名字叫笔趣阁,这个网页有所有章节的网站,那么我们就可以根据每个章节对应的一个网页进行内容爬取,简单来说就是第一大步骤里面又分为两个小步骤,首先是爬取所有章节的url链接,然后根据每个url链接再爬取相应章节的内容。
下面对网页html进行详细分析,

由图可以看出在<div class=”listmain”>标签里面包含了所有我们要提取章节url链接的信息,但是有点小麻烦就是有一个最新章节的列表和正文列表是同一个等级排列,如果我们直接用BeautifulSoup中的find_all()方法的话,会把最新章节列表的内容也包含进来,这里就需要我们能把最新章节列表和正文列表的url进行分离了。
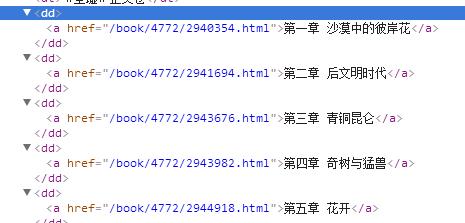
通过前五章的url链接我们可以清楚看到,每个章节不同的只是4472/后面的数字,那么我们是不是可以用re模块创建一个正则表达式对象来提取呢?
好的,带着想法我们进入IDE环境,进行我们的编码:
首先搭建好我们的代码框架
1 import requests 2 3 4 5 from bs4 import BeautifulSoup 6 7 import bs4 8 9 import re 10 11 12 13 def getHTML_Text(url): 14 15 return \'\' 16 17 18 19 def Get_Catalog(ulist,url): 20 21 return \'\' 22 23 24 25 def Get_Content(ulist,url): 26 27 return \'\' 28 29 30 31 def Save_file(ulist): 32 33 return \'\' 34 35 36 37 def main(): 38 39 url = \'http://www.biqiuge.com/book/\' 40 41 catalog_url = [] 42 43 Get_Catalog(catalog_url,url+\'4772/\') 44 45 for i in catalog_url: 46 47 str_temp = \'\' 48 49 Get_Content(str_temp,url+i) 50 51 Save_file(str_temp) 52 53 54 55 if __name__ == \'__main__\': 56 57 main()
在main()函数中,首先是获取所有的url链接到我们的catalog_url列表中,然后用一个for循环迭代每一个url链接,然后对其爬取章节的内容,爬取完之后保存到txt文件中。
其中getHTML_Text()已经用了很多遍了,直接套用前几期讲到的通用代码框架就好了,接下来我们看Get_Catalog()函数:
1 def Get_Catalog(ulist,url): 2 3 html = getHTML_Text(url) 4 5 for i in re.findall(r\'4772/\\d+.html\',html): 6 7 ulist.append(i) 8 9 for j in range(9): 10 11 del ulist[0]
爬取到每个章节的专属url链接的部分之后,我们发现其实有多余重复的部分,就用del把前面8个url链接删除掉。

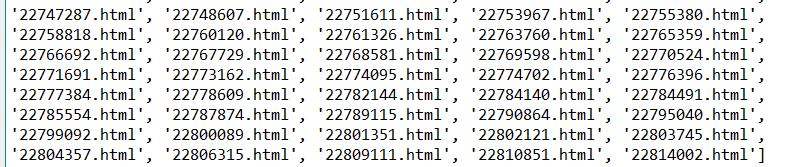
我们一共获取了1049个url链接,我们来核对一下数量到底对不对,


由82开始到1130结束,1130-82+1=1049,刚刚好获取到了每个章节特有的url链接,后面使用的时候只需要用字符串+就构造好我们需要的各个章节的url链接了。
然而事情并不是想象中那么顺利。。。

这个网站的服务器居然能识别出我这只小小爬虫了,我#!¥!%
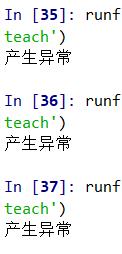

即使不是产生异常,那也只有小说里面的一句话作为返回,真的是气死老夫了!
这时候要转移目标了,虽然很心痛,但是前面积累了经验,到后面就可以很快就用得上了,问题不大。(默默流泪,技术还是不过关,菜鸟一枚)不断失败,不断尝试,不断进步!
我们重新搭建框架:
1 import requests 2 3 import re 4 5 6 7 def getHTML_Text(url): 8 9 return ‘’ 10 11 def Get_Catalog(ulist,url): 12 13 return ‘’ 14 15 def Get_Content(str_temp,url): 16 17 return ‘’ 18 19 def Save_file(f,str_temp): 20 21 return ‘’ 22 23 def main(): 24 25 url = \'http://www.liushuba.com/files/article/html/60/60255/\' 26 27 catalog_url = [] 28 29 Get_Catalog(catalog_url,url) 30 31 32 33 for i in catalog_url: 34 35 str_temp = \'\' 36 37 Get_Content(str_temp,url+i) 38 39 40 41 if __name__ == \'__main__\': 42 43 main() 44 45
这里我们用的是新网站,也就是上面代码的url链接,分析过程与笔趣阁网站的分析一样,这里就跳过了。
getHTML_Text()函数仍然是通用的代码框架,而我们的Get_Catalog()函数就发生了改变,因为我们新找到的网站结构更简单了!
看函数:
1 def Get_Catalog(ulist,url): 2 3 html = getHTML_Text(url) 4 5 for i in re.findall(r\'\\d+.html\',html): 6 7 ulist.append(i)
用正则表达式\\d+.html 就能直接找到所有的各个章节的url链接了!
接着就是获取每个章节的内容和保存本章节内容的函数了:
1 def Get_Content(str_temp,url): 2 3 html = getHTML_Text(url) 4 5 6 7 for i in re.findall(u\'[\\u4e00-\\u9fa5\\(\\)\\《\\》\\——\\;\\,\\。\\:\\“\\”\\!\\?]+<br\',html): 8 9 str_temp = str_temp+i[:-3] 10 11 str_temp = str_temp+\'\\n\' 12 13 14 15 with open(\'圣墟.txt\', \'a\') as f: 16 17 18 19 Save_file(f,str_temp) 20 21 22 23 def Save_file(f,str_temp): 24 25 f.write(str_temp)
这里我们用了一个比较复杂的正则表达式,简单来说就是匹配所有的中文文字和中文的一些常用标点符号,我们这里匹配的最后是以<br为特征的字符串,然后用字符串的截取功能,把最后的<br去掉,就可以得到每个章节的内容了,最后加上写文件的功能,用with结构,可以自动的调用文件对象的close()方法而不用我们手动去写了,注意这里我们是用’a’模式,就是在圣墟.txt这个文件后面继续添加内容。
最后我爬取的小说内容大家可以看看:

还有不足的地方就是我们这个还没有目录,于是我们把获取各章节的那个函数再改造一下,我们用BeautifulSoup的强大功能!
根据网页中的html文本结构,很容易用BeautifulSoup把需要的信息提取出来。

1 def Get_Catalog(ulist,url): 2 3 html = getHTML_Text(url) 4 5 soup = BeautifulSoup(html,\'html.parser\') 6 7 for td in soup(\'tbody\'): 8 9 if isinstance(td,bs4.element.Tag): 10 11 for i in td(\'a\'): 12 13 if isinstance(i,bs4.element.Tag): 14 15 ulist.append([i.get(\'href\'),i.get(\'title\')])
我们把tbody中的所有的<a>标签用get()函数获取href和title的属性值,就是对应我们每个章节的专属url链接和章节名。
1 def Get_Content(str_temp,url,title): 2 3 html = getHTML_Text(url) 4 5 6 7 str_temp = str_temp + title +\'\\n\' 8 9 for i in re.findall(u\'[\\u4e00-\\u9fa5\\(\\)\\《\\》\\——\\;\\,\\。\\:\\“\\”\\!\\?]+<br\',html): 10 11 str_temp = str_temp+i[:-3] 12 13 str_temp = str_temp+\'\\n\' 14 15 with open(\'圣墟.txt\', \'a\') as f: 16 17 Save_file(f,str_temp)
相应的保存到文件的时候也需要保持我们爬取的章节名!
最后看看我们的成品结果:
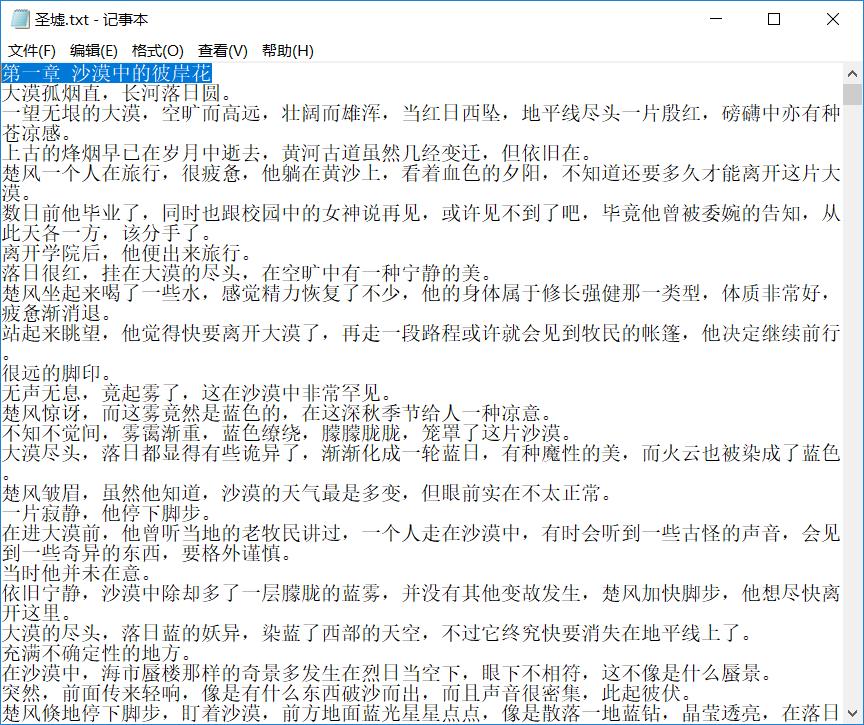
已经有了章节名字,哈哈哈,这个项目的效果就达到了,但是速度上还是有点慢,这个还需要优化一下,但总体上已经实现了我们想要的功能。
本讲全代码:
第一版(没有章节名)
1 import requests 2 3 import re 4 5 6 7 def getHTML_Text(url): 8 9 try: 10 11 r = requests.get(url,timeout = 20) 12 13 r.raise_for_status() #如果状态不是200,则产生异常 14 15 r.encoding = r.apparent_encoding 16 17 return r.text 18 19 except: 20 21 return \'产生异常\' 22 23 24 25 def Get_Catalog(ulist,url): 26 27 html = getHTML_Text(url) 28 29 for i in re.findall(r\'\\d+.html\',html): 30 31 ulist.append(i) 32 33 def Get_Content(str_temp,url): 34 35 html = getHTML_Text(url) 36 37 38 39 for i in re.findall(u\'[\\u4e00-\\u9fa5\\(\\)\\《\\》\\——\\;\\,\\。\\:\\“\\”\\!\\?]+<br\',html): 40 41 str_temp = str_temp+i[:-3] 42 43 str_temp = str_temp+\'\\n\' 44 45 46 47 with open(\'圣墟.txt\', \'a\') as f: 48 49 50 51 Save_file(f,str_temp) 52 53 54 55 def Save_file(f,str_temp): 56 57 f.write(str_temp) 58 59 60 61 def main(): 62 63 url = \'http://www.liushuba.com/files/article/html/60/60255/\' 64 65 catalog_url = [] 66 67 Get_Catalog(catalog_url,url) 68 69 70 71 for i in catalog_url: 72 73 str_temp = \'\' 74 75 Get_Content(str_temp,url+i) 76 77 78 79 if __name__ == \'__main__\': 80 81 main()
第二版(有章节名)
1 import requests 2 3 from bs4 import BeautifulSoup 4 5 import bs4 6 7 import re 8 9 10 11 def getHTML_Text(url): 12 13 try: 14 15 r = requests.get(url,timeout = 20) 16 17 r.raise_for_status() #如果状态不是200,则产生异常 18 19 r.encoding = r.apparent_encoding 20 21 return r.text 22 23 except: 24 25 return \'产生异常\' 26 27 28 29 30 31 def Get_Catalog(ulist,url): 32 33 html = getHTML_Text(url) 34 35 soup = BeautifulSoup(html,\'html.parser\') 36 37 for td in soup(\'tbody\'): 38 39 if isinstance(td,bs4.element.Tag): 40 41 for i in td(\'a\'): 42 43 if isinstance(i,bs4.element.Tag): 44 45 ulist.append([i.get(\'href\'),i.get(\'title\')]) 46 47 48 49 def Get_Content(str_temp,url,title): 50 51 html = getHTML_Text(url) 52 53 54 55 str_temp = str_temp + title +\'\\n\' 56 57 for i in re.findall(u\'[\\u4e00-\\u9fa5\\(\\)\\《\\》\\——\\;\\,\\。\\:\\“\\”\\!\\?]+<br\',html): 58 59 str_temp = str_temp+i[:-3] 60 61 str_temp = str_temp+\'\\n\' 62 63 with open(\'圣墟.txt\', \'a\') as f: 64 65 Save_file(f,str_temp) 66 67 68 69 def Save_file(f,str_temp): 70 71 f.write(str_temp) 72 73 74 75 def main(): 76 77 url = \'http://www.liushuba.com/files/article/html/60/60255/\' 78 79 catalog_url = [] 80 81 Get_Catalog(catalog_url,url) 82 83 84 85 for i in catalog_url: 86 87 str_temp = \'\' 88 89 Get_Content(str_temp,url+i[0],i[1]) 90 91 92 93 if __name__ == \'__main__\': 94 95 main()
本讲到此结束,也就标志着Python简单爬虫就到此结束了,我只是简单讲述了爬虫的一些代码运用和一些实战项目,还有爬虫的运行机理,希望对大家有帮助,谢谢观看。
以上是关于Python简单爬虫第六蛋!(完结撒花)的主要内容,如果未能解决你的问题,请参考以下文章