多领域中文语音识别数据集 WenetSpeech 正式发布——有效下载教程
Posted 墨理学AI
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了多领域中文语音识别数据集 WenetSpeech 正式发布——有效下载教程相关的知识,希望对你有一定的参考价值。
❤️【专栏:数据集整理】❤️ 之【有效拒绝假数据】
👋 Follow me 👋,一起学更多有趣 AI、冲冲冲 🚀 🚀
文章目录
🥇 数据集介绍

🔴 基础信息
西北工业大学音频语音和语言处理研究组(ASLP Lab)、出门问问、希尔贝壳联合发布1万小时多领域中文语音识别数据集 WenetSpeech
- 对应论文 :https://arxiv.org/pdf/2110.03370.pdf
- 官方主页:https://wenet-e2e.github.io/WenetSpeech/
- 该部分介绍主要参考该文:
https://mp.weixin.qq.com/s/lR22WmI5G2mPSuloZUcWVA - 追求排版体验的同学,可自行复制跳转原文【上面链接】进行查阅

🔵 WenetSpeech 简介
WenetSpeech 除了含有 10000+ 小时的高质量标注数据之外,还包括2400+ 小时弱标注数据和 22400+ 小时的总音频,覆盖各种互联网音视频、噪声背景条件、讲话方式,来源领域包括有声书、解说、纪录片、电视剧、访谈、新闻、朗读、演讲、综艺和其他等10大场景,领域详细统计数据如下图所示。

🟣 WenetSpeech 收集过程

下图中给出该 OCR 系统在不同场景下的几个典型示例。图中绿色的框为检测到的所有文字区域,红色的框为判定为字幕的文字区域,红色框上方的文本为 OCR 的识别结果。 可以看到,该系统正确的判定了字幕区域,并准确的识别了字幕文本,同时经过我们测试,发现该系统也可以准确判定字幕的起始和结束时间。

🟡 数据校验
WenetSpeech 中选取置信度>=95%的数据作为高质量标注数据,选取置信度在0.6和0.95之间的数据作为弱监督数据。

🔴 经典算法对比

📘 下载正确打开方式
该下载方式记录时间:【2021-10-22记录】
🟧 下载主页

🟨 填写邮箱信息

🟦 提交成功界面如下

🟧 很快邮箱收到下载方式说明
让准备,500G 磁盘空间

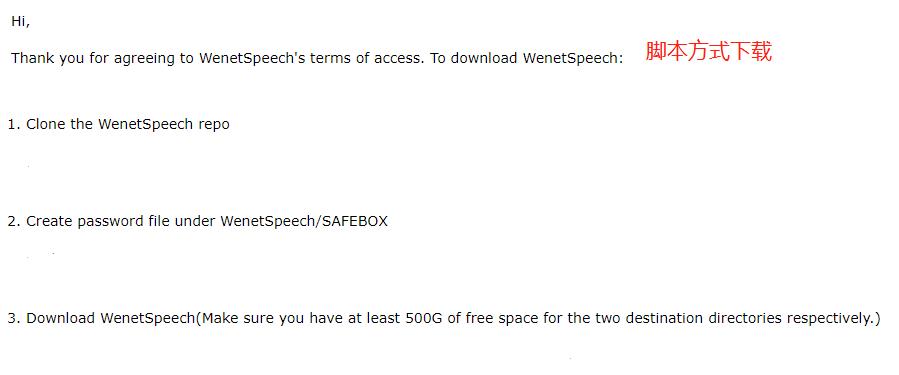
🟨 开始下载

根据网速情况,下载大致需要 大半天吧
du -sh数据集压缩包大小:309Gtree -L 3查看数据集结构如下

📙 致敬大佬
WenetSpeech 是目前最大的开源普通话语音语料库,适用于产业级语音识别的研究
全人类的人工智能事业大概就是这样一步一步向前推动的吧


语音数据集总结博文如下
近期经典有趣博文推荐
- ❤️ 高效入门目标检测之YOLO实战系列精选——【1024专刊】
- ❤️ 初识超分重建——如何让女神更清晰,我的白月光【ICCV, 2021 超分重建之 BSRGAN】
- ❤️ 多阶段渐进式图像恢复 | 去雨、去噪、去模糊 | 有效教程(附源码)|【❤️CVPR 2021❤️】
- ❤️ 【深度学习入门项目】给学妹换个风格【❤️CVPR 2020 风格迁移之NICE-GAN❤️】
- ❤️ 【深度学习入门项目】将学妹的照片转换为铅笔素描 |【❤️Pattern Recognition 2020 之 U Square Net❤️】

以上是关于多领域中文语音识别数据集 WenetSpeech 正式发布——有效下载教程的主要内容,如果未能解决你的问题,请参考以下文章