[ZZ] 多领域视觉数据的转换关联与自适应学习
Posted 点滴
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[ZZ] 多领域视觉数据的转换关联与自适应学习相关的知识,希望对你有一定的参考价值。
哈工大左旺孟教授:多领域视觉数据的转换、关联与自适应学习
http://blog.sciencenet.cn/home.php?mod=space&uid=3291369&do=blog&quickforward=1&id=1074540
整理:苟超
1.基于多领域视觉数据学习
我们首先讨论多领域的视觉数据。对于现在来说,它应该是我们可以用各种不同传感器,比如RGB和深度摄像机、红外、超光谱等来获取的数据。另外一个就是可以从不同视角去拍摄获取。此外,我们可以用语言来描述某个场景或者物体,也可以用声音、视频去记录。同样我们也可以用真实物理世界、VR、AR等方式去重现展示,从而形成视觉数据描述。
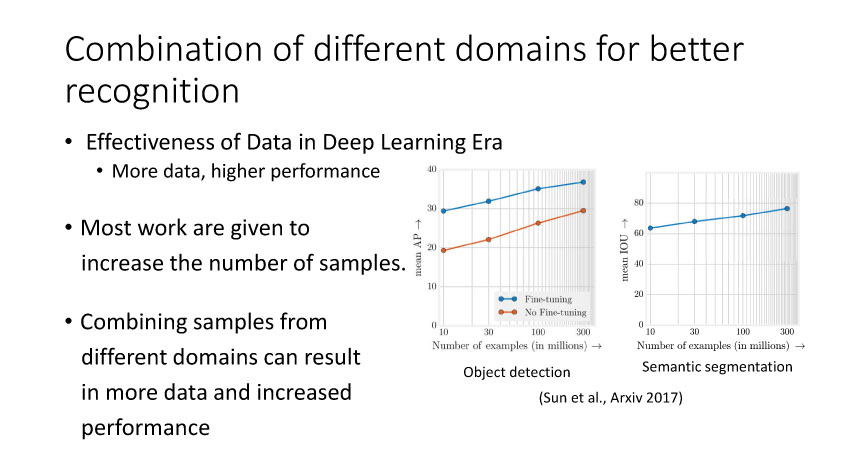
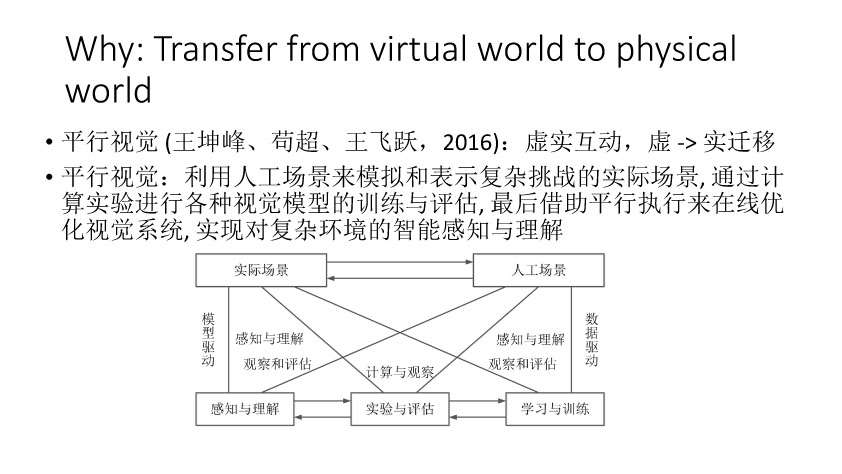
那么我们怎么去利用这些多领域视觉数据来更有效率的去解决问题?第一个就是我们可以把不同领域的数据融合在一起,然后来做一些事情。如果这种融合是在这种学习识别和分类这种融合的话,那么它肯定会对识别和分类的性能会有帮助。此外这种融合可以让它在原始数据基础上得到一些比较好的视觉效果,或者是得到一些就是我们想要的一些视觉特效。例如Suwajanakorn等人在今年Siggraph上的文章实现输入音频和奥巴马图像,输出合成的视频,使得嘴型和音频匹配。另外一个融合可以通过迁移学习实现。今年李开复在一个talk就提出过,深度学习之后是增强学习,然后就是迁移学习。王坤峰等提出的平行视觉也可以从该角度来理解,就相当于说我们先模拟得到一个场景,在这个场景训练一个模型,然后最后再把这个实验的模型在应用到实际,中间再会有一些交互平行执行使得模型优化。
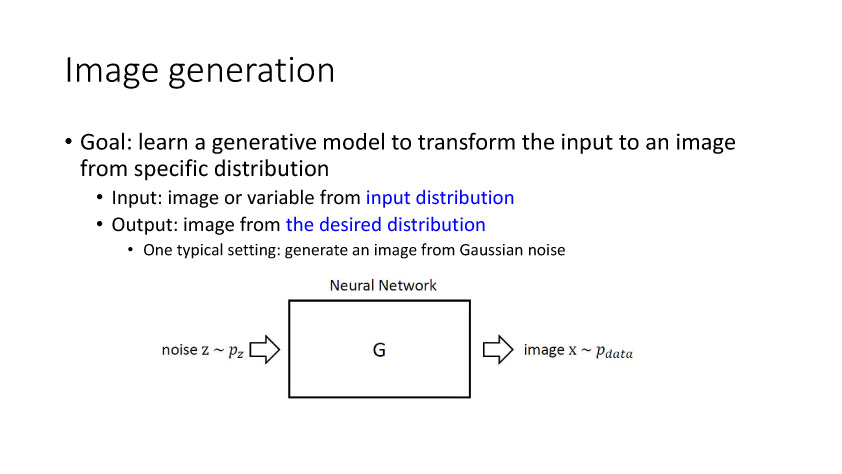
基于学习的方法需要大量的训练数据,而手动标注耗时费力,我们可以融合仿真的带标注信息三维数据和无标签信息的虚拟数据来解决问题。在迁移学习中,为了减小真实数据和仿真数据之间的偏差,生成对抗网络(GANs)提供了一种有效的解决方式。此外,GAN还可以按照真实数据分布来生成对应的逼真图像,从而改善训练模型的泛化能力。
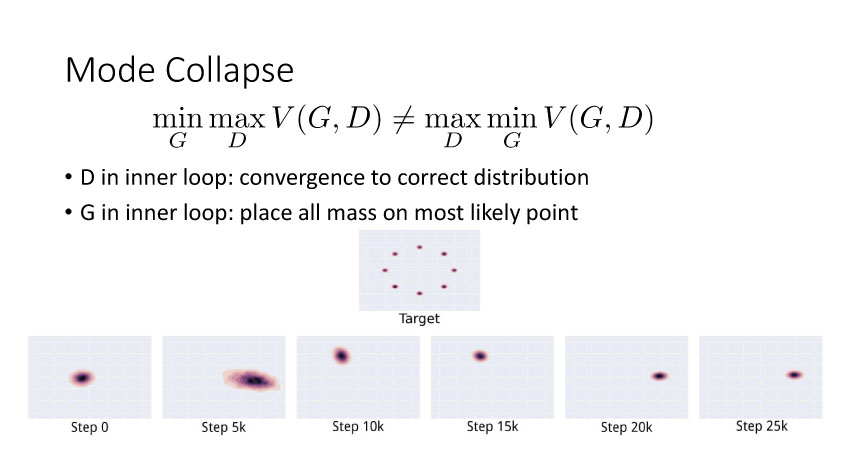
2.改善GAN的学习能力
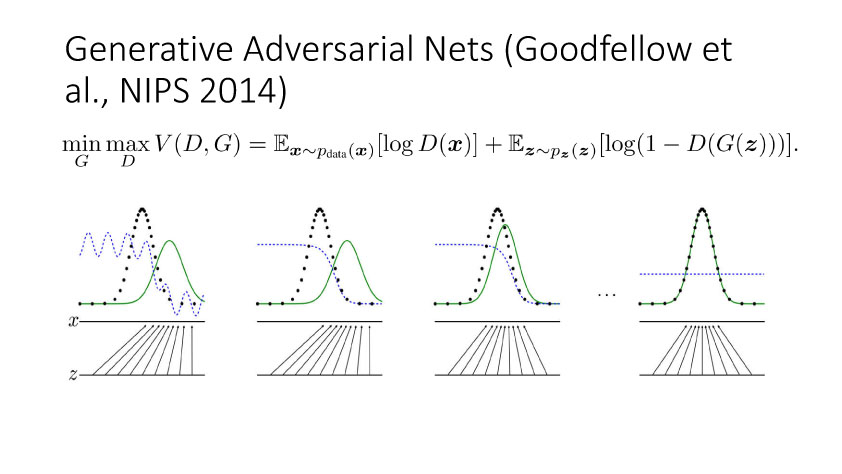
Gooodfellow等在2014年提出了生成对抗网络(GANs),它包含一个生成网络和一个判别网络。生成网络不断更新使得网络生成的图像更加逼真,而判别网络的目的是尽量正确的判断数据来源于真实数据还是生成网络生成的数据。
GAN的目的是利用生成网络按照真实数据的分布来生成逼真数据,对于GAN的学习,它是一个最大-最小优化问题。我们先从最大化均方分布(Maximum Mean Discrepancy,MMD)来开始讨论优化改进GAN的学习能力,Borgwardt在06年提出MMD,就是如果假设有两个分布,如果这两个分布相同,那么这两个分布的均值一定相同。但是如果这两个分布的数学期望相同,并不表示两个分布相同。倘若我们将所有分布限制在希尔伯特空间,且小于等于1,此时如果其数学期望相同,那么可以证明这两个分布是相同的。
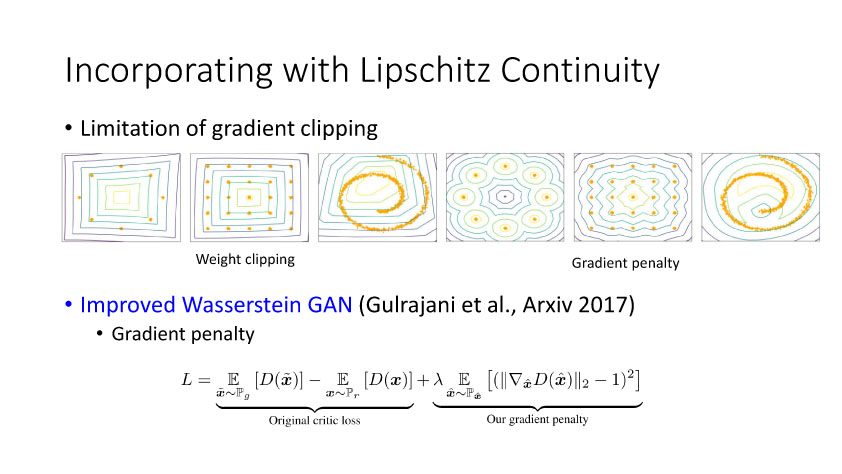
后面15年Li等人提出GenerativeMoment Matching Networks (GMMN)来利用核方法优化求解问题。Salimans等在2016年提出改进的GAN,将问题限制在Lipschitz连续性上,从而解决梯度消失的问题。Arjovsky等人提出Wasserstein GAN,利用Wasserstein距离来度量。另外一个优化方向可以从流行学习角度出发,从而考虑两个分布之间的局部关系。
3.图像转换
Image Translation可以分为有监督和无监督两种方式。首先就是有监督,最开始的时候是MSE和Perceptual loss,后来有了GAN,更多的工作开始基于GAN来实现。ConditionalGAN的视觉效果较好,但仍然有一点局限性,我们还可以基于内部和外部的约束去优化模型结构。有监督的ImageTranslation主要是图像复原,图像超分辨率,街景分割,边缘检测等。
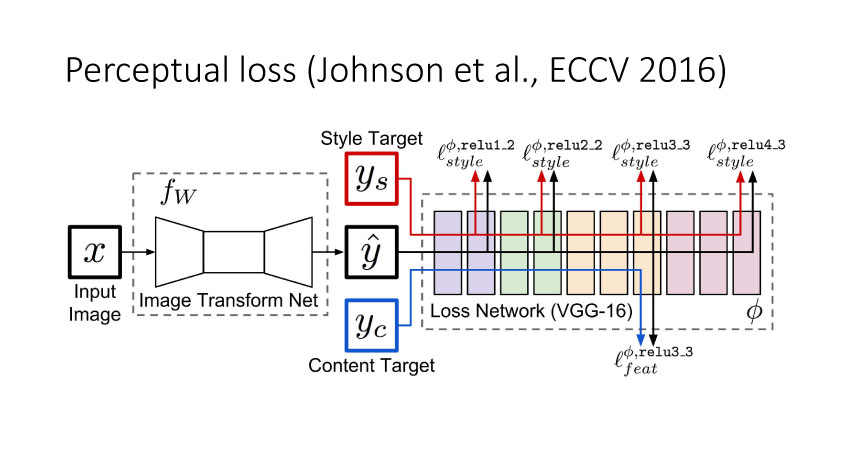
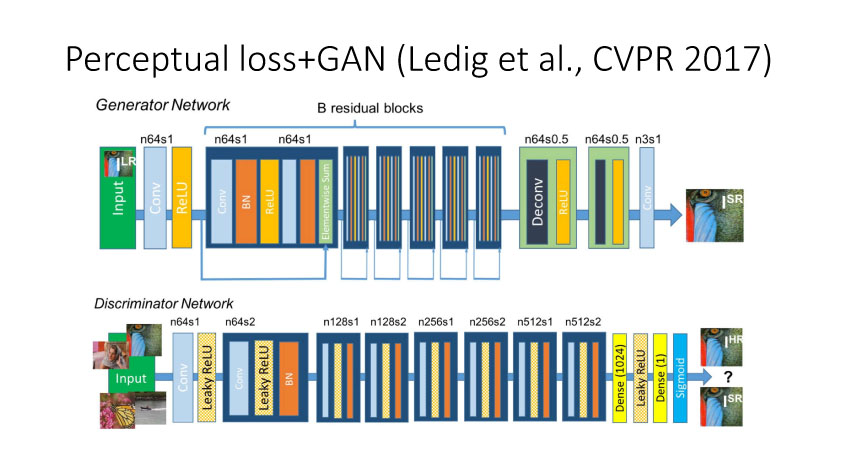
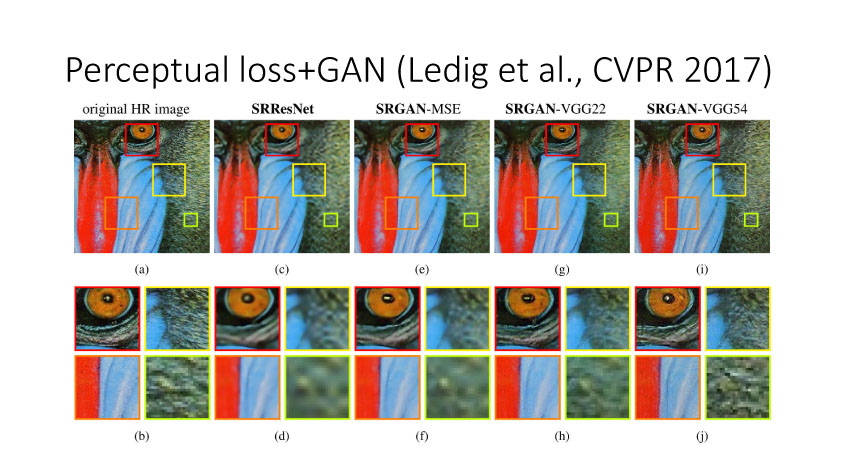
前面提到的基于MSE 定义的loss来实现Image Translation具有一定局限性,它会过于平滑图像,同时还会损失边缘和纹理细节信息。利用深度网络,比如VGG来实现基于perceptualloss的图像转换也会损失边缘和纹理细节信息,还会引入一些人工仿真场景信息。Ledig等人在今年CVPR上发表了文章将Perceptual loss和GAN结合,从而使得转换更为逼真。如果按照前面的这些方法来实现,我们需要设计用什么网络来实现计算Perceptual loss。那么如何避免去显示定义网络来实现Perceptualloss?Conditional GAN就可以实现,它定义正对(输入和真实图像)和反对(输入和仿真图像),然后学习网络来实现正确判断正反对。这样就可以将perceptual隐式嵌入到网络中,这种conditional GAN方法是当时实现效果最好的。
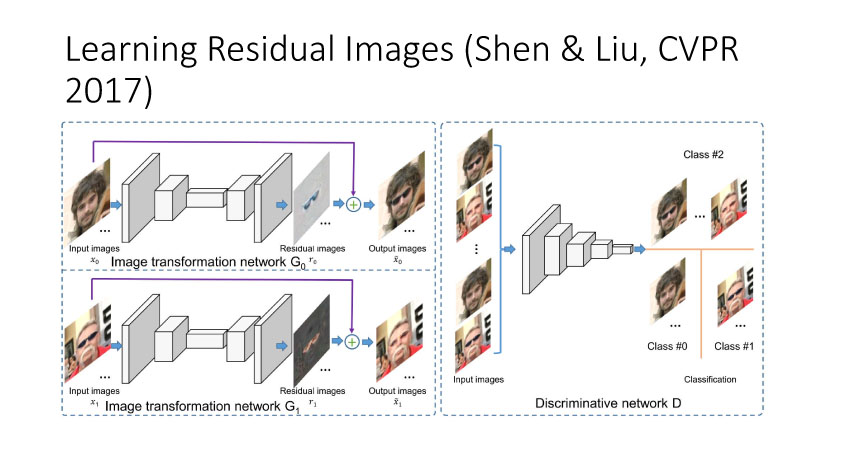
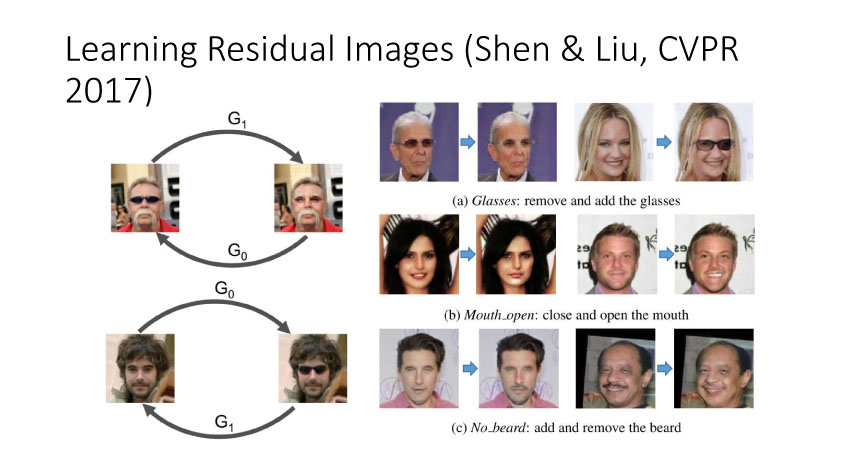
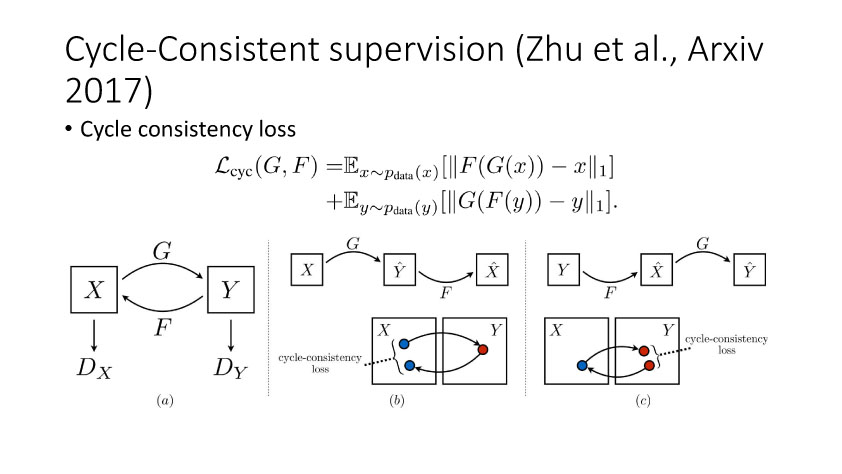
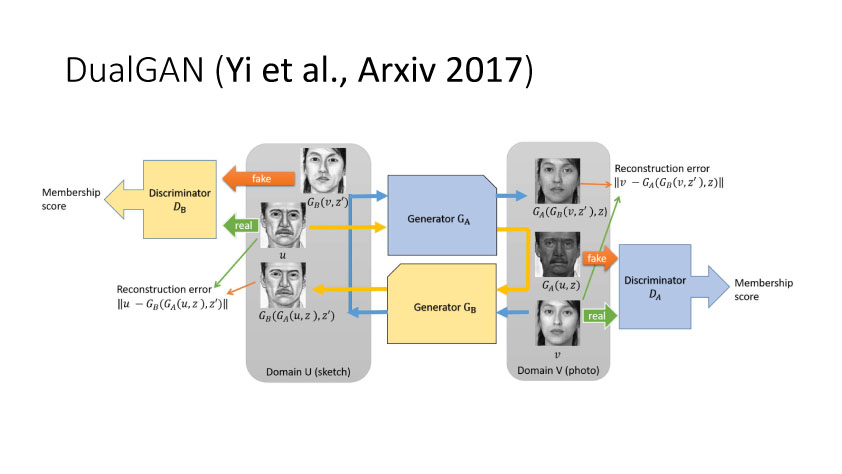
另一种就是无监督图像转换,比如马到斑马的转换,四季场景变化等。还有一个例子就是人脸标签转换,比如性别、是否戴眼镜等。一个典型工作是今年CVPR上的Learning Residual Images(Shen &Liu),他们提出利用一个残差网络来学一个脸部标签(戴眼镜),同时利用另外一个残差网络来去掉眼镜,训练过程中这两个网络一起学习,使得它可以从戴眼镜到不戴眼镜,同时也可以实现从不戴眼镜到戴眼镜,这就相当于一个环,可以实现遍历,最终实现一个可以完成Faceattribute transfer的模型。后面还有相似的工作比如DualGAN (Yi et al., Arxiv 2017)和Cycle-Consistentsupervision (Zhu et al., Arxiv2017)等。
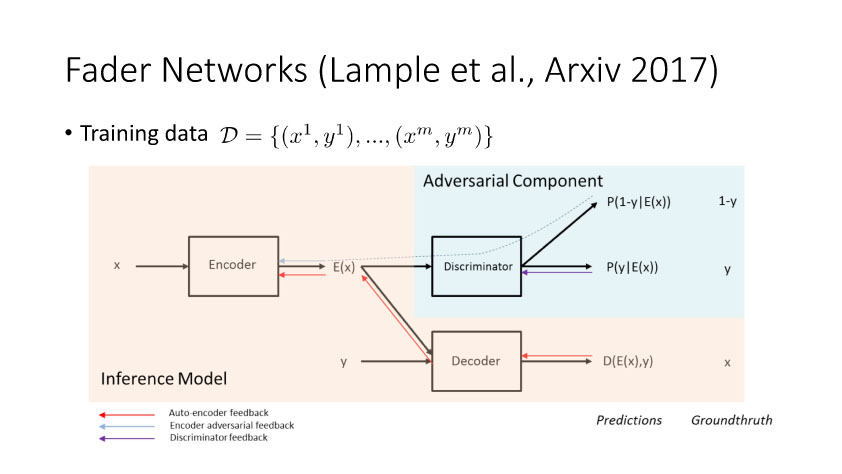
还有Facebook的一个工作,这个比较明确,就是说这里面有一个encoder,最后这个output需要设置什么样就是什么样。同时如果想调整这个Y得到目标的话,需要满足这个E(x)和Y是独立。这样的网络有一个很大好处就是它学一个网络,可以任意改变人脸的一个attribute即可,比如性别、年龄、眼镜等。这种网络结构是一个比较简洁比较漂亮的模型。
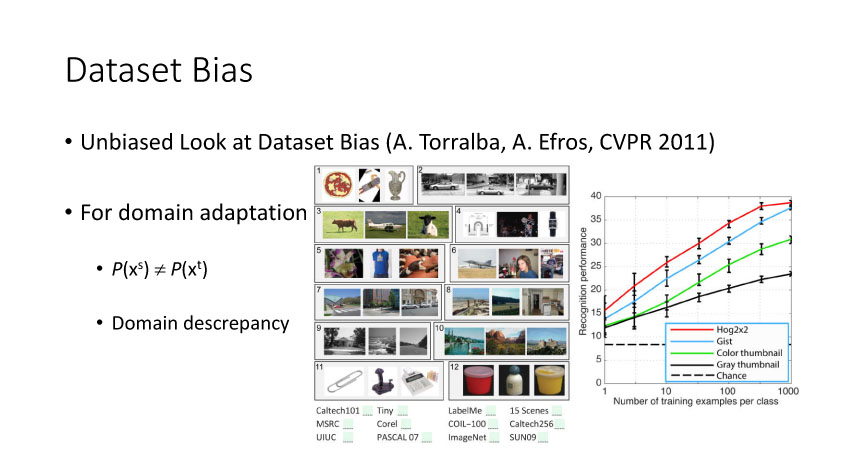
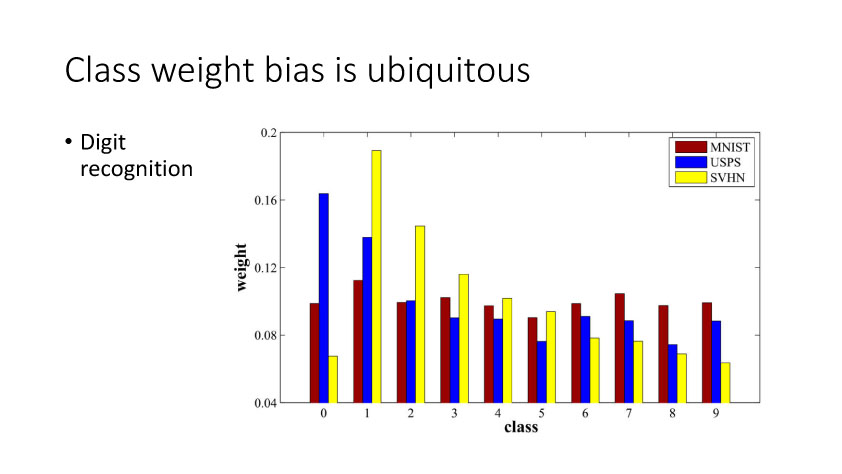
4.深度领域适应
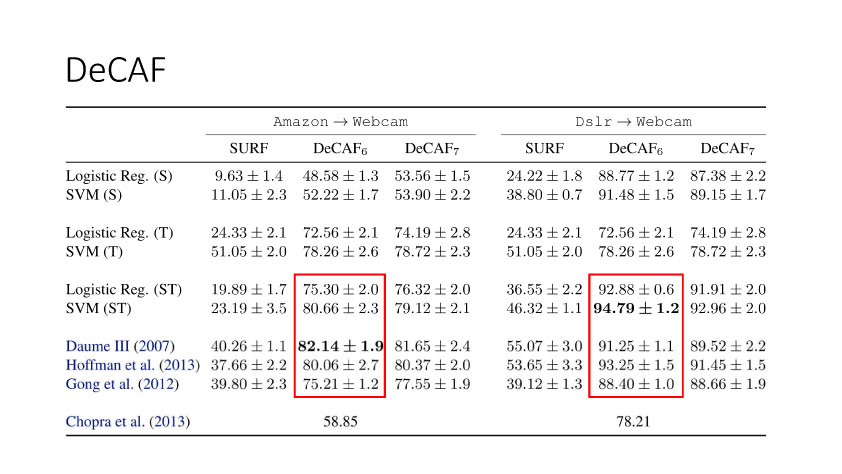
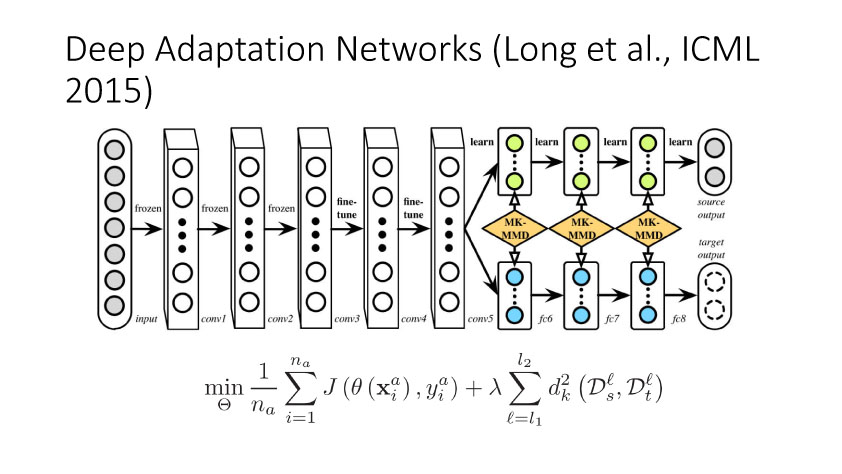
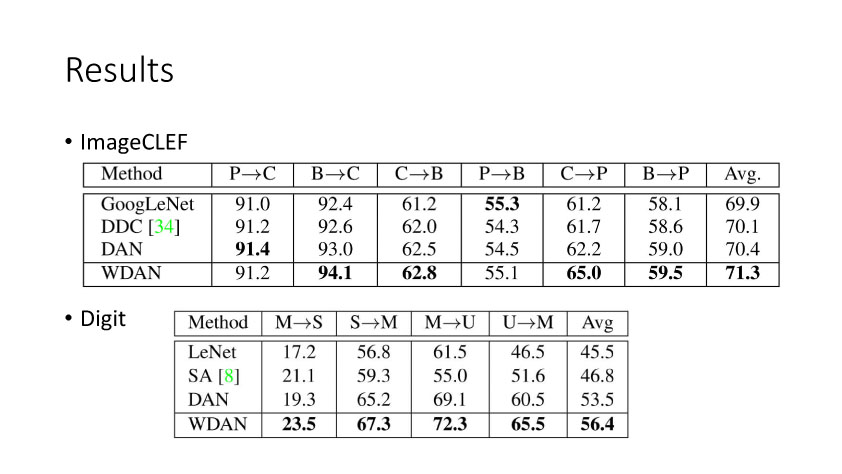
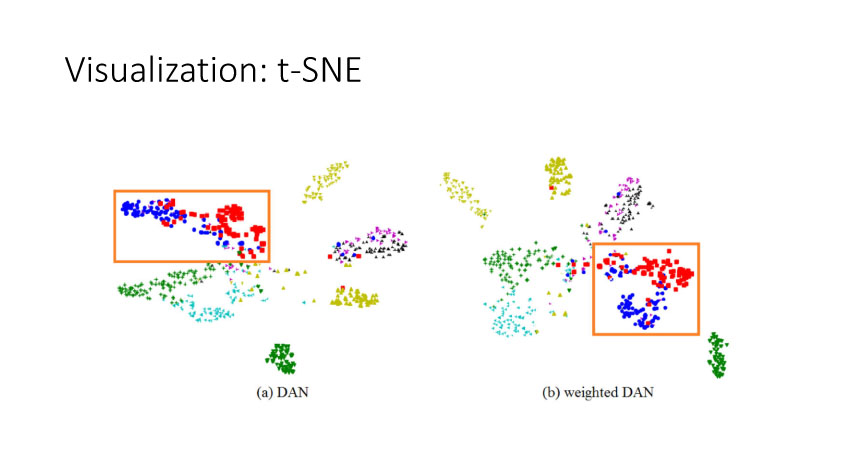
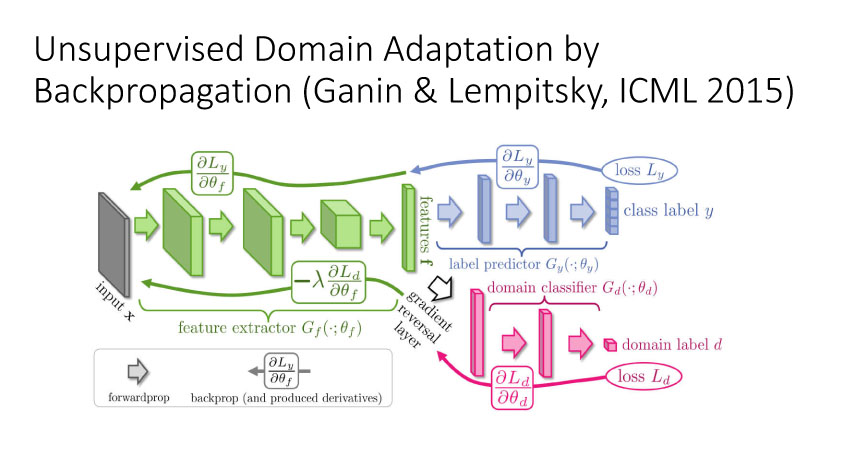
下面讲讲Deep Domain Adaptation。在GAN出来之前,该领域已经做了十来年了。传统Domain Adaptation目标主要是指在领域A学得的模型,用于领域B。为了实现这个目标,我们设定了任务。第一个任务就是有监督的这个类型,在这种情况下就是说A里头也有label,B领域里面也有。还有一种就是半监督,即A里面有label,而B领域里面没有或者只有少量label。最后一个就是无监督的领域适应,领域A和B都没有任何标签信息。无监督是最难也是最有意义的。后来随着deep learning的巨大成功,被逐步引入domain adaptation, Donahue等人在ICML2014提出一些有监督是深度特征可以减小不同domain之间的bias。后来(Yosinski et al., NIPS 2014)提出深度特征不能解决domainadaptation问题,从双向的角度出发,domain adaptation是需要的。最开始利用Maximum Mean Discrepancy (MMD) 来实现,主要用线性核,后来将CNN引入实现非线性映射。后来(Grettonet al., NIPS 2012)提出用多核方法实现domain adaptation,从对抗思想来理解,先固定核函数参数,更新特征提取模型的参数来最小化MMD,然后固定特征提取模型参数,更新核函数参数来最大化MMD。
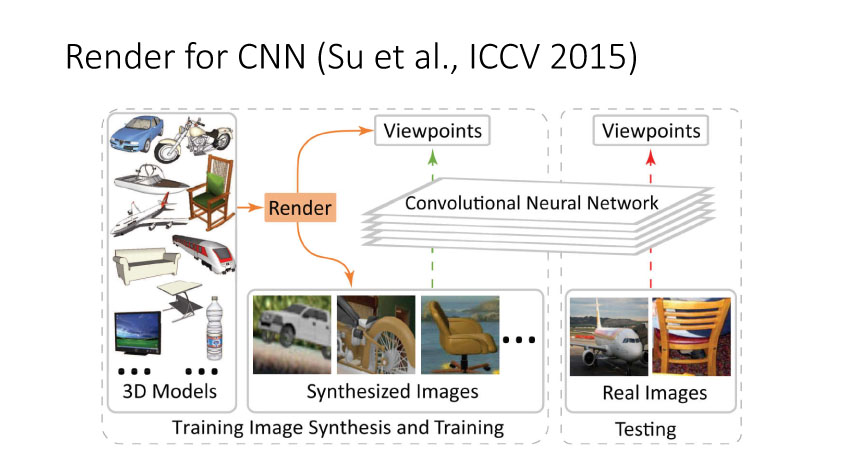
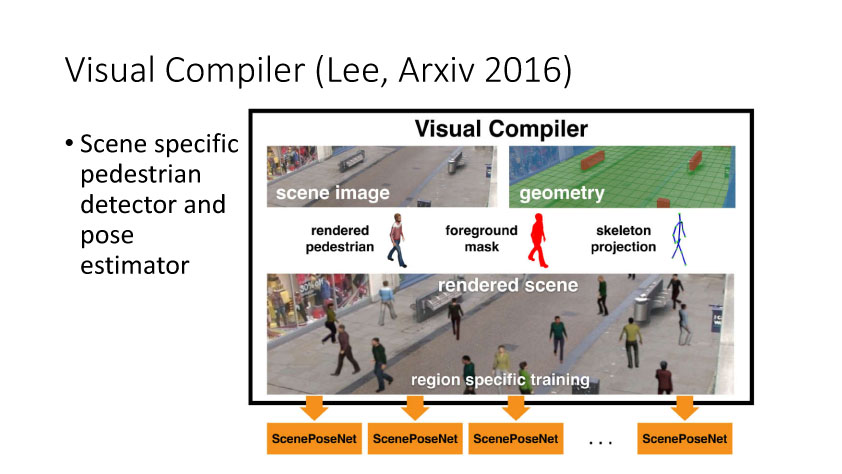
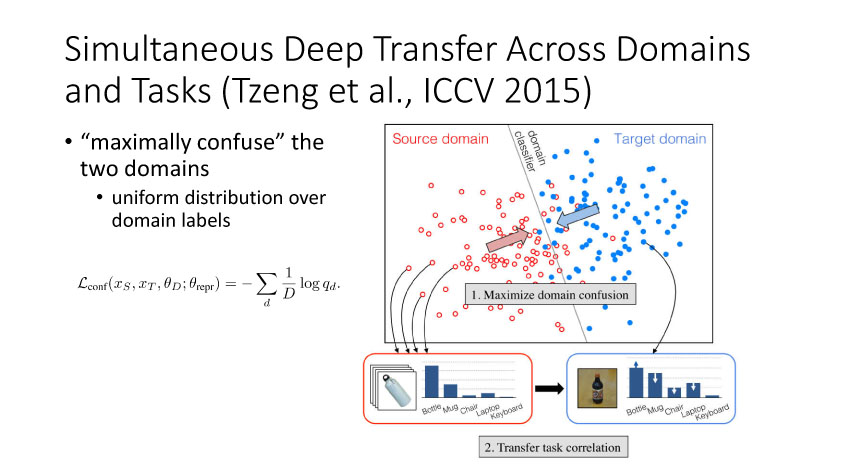
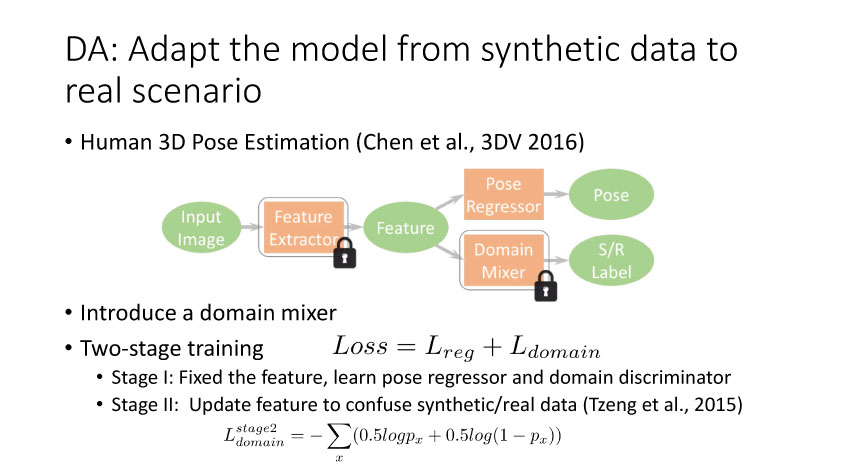
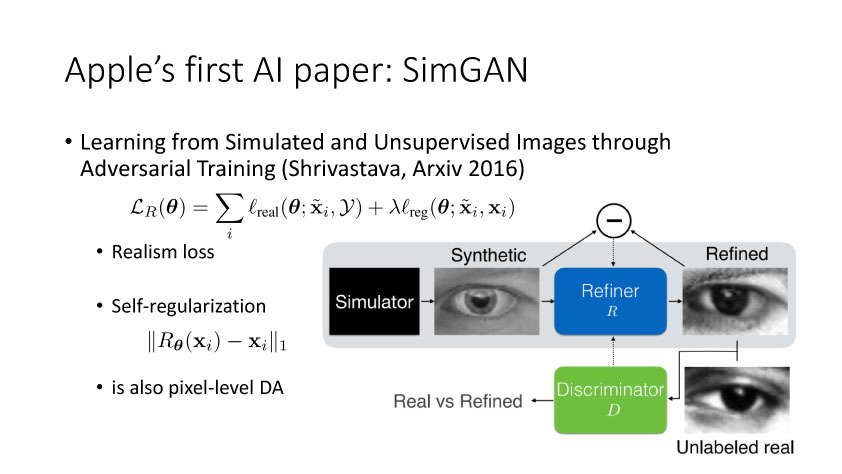
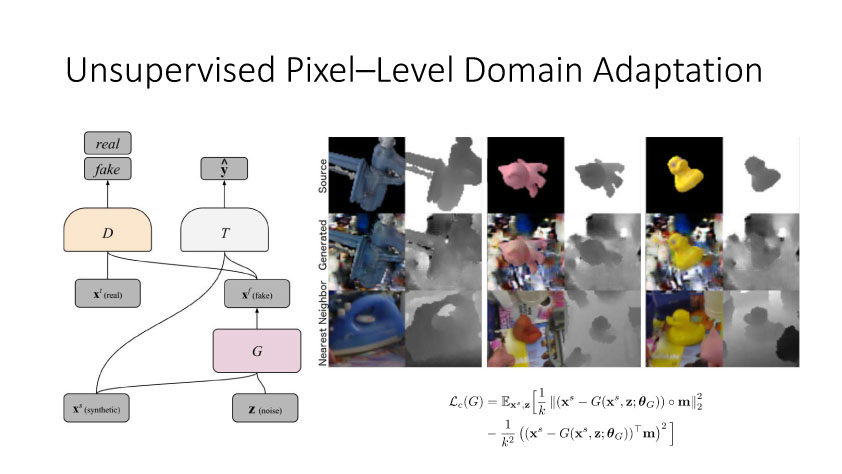
通过2014年的讨论,大家开始从无监督方向考虑,并结合GAN来做研究。时间是无监督DA就是利用合成数据学得模型再利用到真实环境中去,Render for CNN (Su et al., ICCV 2015)就是这样一个工作,如下图所示,他们提出在虚拟仿真图像训练模型,用于实际中估计物体姿态。上述从特征方面来实现domain adaptation,还有一个方面是从图像像素级方面来考虑实现,比较典型的一个工作就是Apple的第一篇AI论文,发表于几年的CVPR上。他们提出SimGAN,这里的输入为仿真图像,利用对抗网络学习来得到一个Refiner网络,从而使得生成图像既有仿真图像的标签数据,又有真实图像的纹理外观信息。














































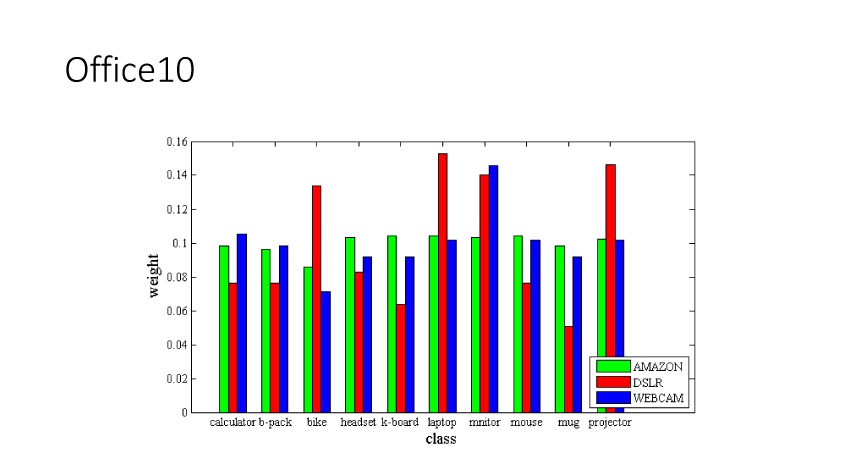
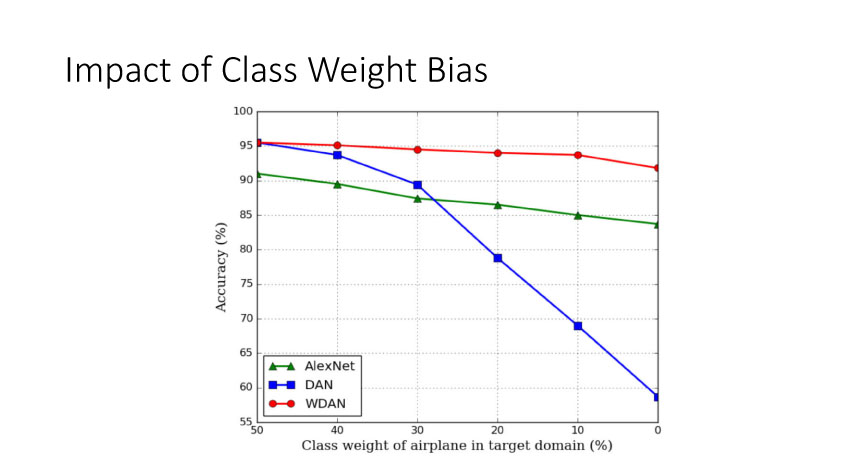


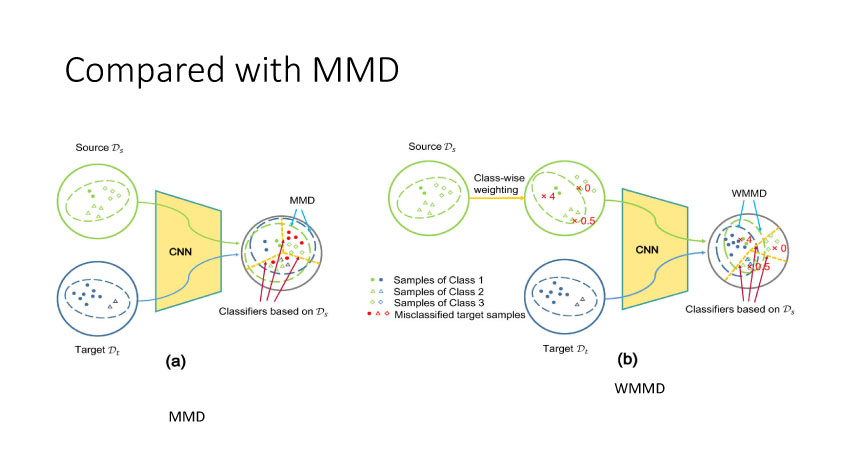

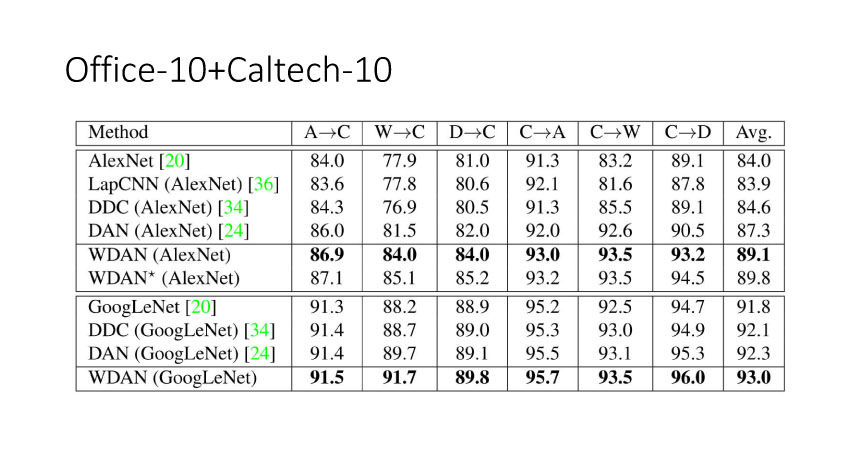








以上是关于[ZZ] 多领域视觉数据的转换关联与自适应学习的主要内容,如果未能解决你的问题,请参考以下文章