文本分类混合CHI和MI的改进文本特征选择方法
Posted 征途黯然.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文本分类混合CHI和MI的改进文本特征选择方法相关的知识,希望对你有一定的参考价值。
摘要:改进CHI算法、改进MI算法,结合改进CHI+改进MI,应用于文本的特征选择,提高了精度。
参考文献:[1]王振,邱晓晖.混合CHI和MI的改进文本特征选择方法[J].计算机技术与发展,2018,28(04):87-90+94.
一、引言
通过特征选择方法,降低特征向量的维数,减少分类算法的运行时间,从而最终提高分类准确度。常用的特征选择算法有:文档频率DF、互信息MI、 卡方检验CHI、信息增益IG。
二、基础算法
2.1、CHI算法【卡方统计】
参考此篇博客的2.1小节:【文本分类】基于改进CHI和PCA的文本特征选择
2.2、MI算法【互信息】
互信息的概念出自信息论中,原本互信息用来衡量两个信号间的关联程度。在文本分类中,表现为特征与类别之间的关联程度。

2.3、CHI算法的改进
从CHI算法的缺点出发:传统 CHI 统计方法只考虑了特征词在所有文档集中出现的文档数量,而没有考虑特征词在某一篇文档中出现的次数,从而夸大了低频词的作用。所以引入词频因子:

2.4、MI算法的改进
从MI算法的缺点出发:没有考虑特征本身出现的频度,这会造成 MI 方法在评估特征时会倾向于选择一些低频特征。
通过引入β,添加词频信息,适当增加中高频特征所占比重,降低低频特征的互信息值,避免互信息方法选择过多的低频特征,从而降低低频词对互信息方法的负效用。
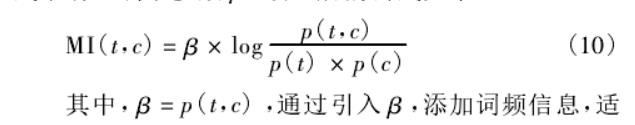
不同类别之间,特征的词频也代表了不同的类别区分能力。一个区分能力强的特征词,应该集中分布在某些特定的类别中,也就是不同类别中的特征词频的方差应该尽可能大,这样的特征含有更多的类别区分信息为此,引入不同类别间特征的词频的方差对 MI 方法进行优化。

总结:
最终改进后的CHMI算法公式为:
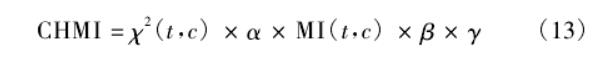
三、代码实验
3.1、实验思路
根据以下5种方法:
(1)普通CHI算法来选择特征
(2)改良ICHI算法来选择特征
(3)普通MI算法来选择特征
(4)改良MI算法来选择特征
(5)混合CHMI算法来选择特征
比较不同算法之间,文本分类的准确率。
3.2、数据集
数据来源于 https://github.com/cystanford/text_classification 。数据集共包含四个类别,分别为“女性”,“体育”,“文学”,“校园”,原始数据集已经划分了测试集和训练集,并给出了停用词文档。
3.3、实验结果
| 特征维度 | 手写普通卡方CHI | 手写改进卡方CHI | 手写普通MI | 手写改进MI | 混合CHI +MI |
|---|---|---|---|---|---|
| 200 | 0.79 | 0.775 | 0.58 | 0.77 | 0.765 |
| 400 | 0.79 | 0.795 | 0.58 | 0.815 | 0.825 |
| 600 | 0.81 | 0.815 | 0.58 | 0.82 | 0.84 |
| 800 | 0.825 | 0.825 | 0.58 | 0.83 | 0.835 |
| 1000 | 0.81 | 0.815 | 0.585 | 0.83 | 0.835 |
| 1200 | 0.825 | 0.83 | 0.585 | 0.85 | 0.845 |
| 1400 | 0.835 | 0.845 | 0.605 | 0.86 | 0.865 |
| 1600 | 0.875 | 0.85 | 0.585 | 0.87 | 0.88 |
| 1800 | 0.87 | 0.87 | 0.575 | 0.87 | 0.87 |
| 2000 | 0.87 | 0.875 | 0.575 | 0.875 | 0.885 |
| 4000 | 0.875 | 0.86 | 0.58 | 0.865 | 0.875 |
| 6000 | 0.875 | 0.88 | 0.56 | 0.875 | 0.88 |
| 8000 | 0.895 | 0.87 | 0.58 | 0.875 | 0.88 |
| 10000 | 0.905 | 0.875 | 0.57 | 0.88 | 0.88 |
| 12000 | 0.905 | 0.895 | 0.615 | 0.875 | 0.89 |
| 14000 | 0.91 | 0.91 | 0.6 | 0.885 | 0.895 |
| 16000 | 0.91 | 0.9 | 0.625 | 0.895 | 0.895 |
| 18000 | 0.89 | 0.89 | 0.65 | 0.89 | 0.885 |
| 20000 | 0.88 | 0.875 | 0.685 | 0.885 | 0.885 |
| 22000 | 0.88 | 0.88 | 0.72 | 0.885 | 0.88 |
| 24000 | 0.875 | 0.875 | 0.795 | 0.875 | 0.875 |
【注】表中标黄为同一维度下最高准确率。
实验结果分析:
1、从前2000维上分析,可以看到本文提出的混合CHMI算法准确率效果确实最好;
2、但当维度变高时,本文提出的CHMI算法效果并不好。
思考一:为什么会出现低维效果好,高维效果差的情况?能否有理论依据?
思考二:求MI的时候,会出现log(0)的情况,本文并没有提到解决方法。
获取本项目的源代码
如果需要本组件的源代码,请扫描关注我的公众号,回复“论文源码”即可。

以上是关于文本分类混合CHI和MI的改进文本特征选择方法的主要内容,如果未能解决你的问题,请参考以下文章