文本分类基于改进TF-IDF特征的中文文本分类系统
Posted 征途黯然.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文本分类基于改进TF-IDF特征的中文文本分类系统相关的知识,希望对你有一定的参考价值。
摘要:改进TFIDF,提出相似度因子,提高了文本分类准确率。
参考文献:[1]但唐朋,许天成,张姝涵.基于改进TF-IDF特征的中文文本分类系统[J].计算机与数字工程,2020,48(03):556-560.
😮 最近看了许多有关机器学习的文本分类改进,有一部分论文写的非常差劲,文不知所以,论文中的公式站不住脚,根本无法代码实现,一度使我怀疑是不是自己出了问题。现在已经往基于深度学习的文本分类上转了。
一、引言
采用 one-hot模型进行文本向量化操作,并利用TF-IDF策略进行向量维度的权重计算。其后对传统TF-IDF策略进行改进并联合基于SVM模型机器学习算法完成自动化文本分类系统的设计。
二、基础算法
2.1、TF-IDF算法【词频-逆文档频】
可以参考上一篇博客【文本分类】基于类信息的TF-IDF权重分析与改进。
2.2、改进算法
传统的TF-IDF算法忽略了相似词对文本分类的影响。[例如,经过训练得到特征词"自然语言处理"对标签"文本分类"有很大贡献度,那么"NLP"作为与"自然语言处理"在某种关系R下的相似词,也应该对标签"文本分类"有很大贡献度]。
论文提出了对于两个特征词x、y,计算它们的相似度的方法:

其中x、y的shape为(1,n),n为数据集中文本数量。x[i]的含义是特征词x在第i篇文档的频数。
得到每个特征之间的相似度关系之后,计算相似度因子:

其中,P表示特征词t在某一个文本d中的频数,Q表示在文本d中与特征词t相似的各个特征的频数和,U是文本d中所有特征的频数和。
最终,改进的TFIDF的公式为:

三、代码实验
3.1、实验思路
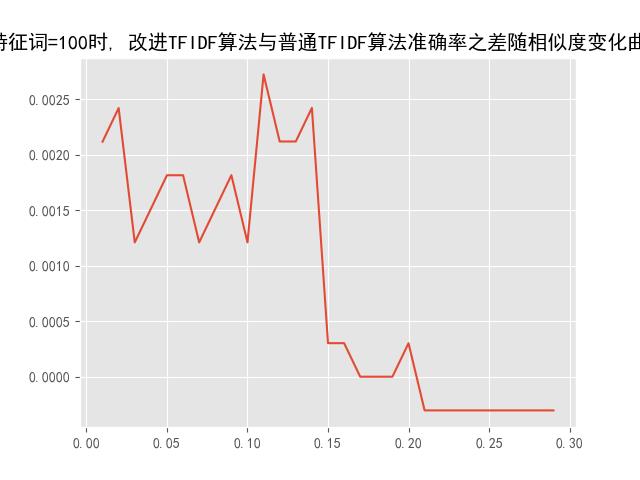
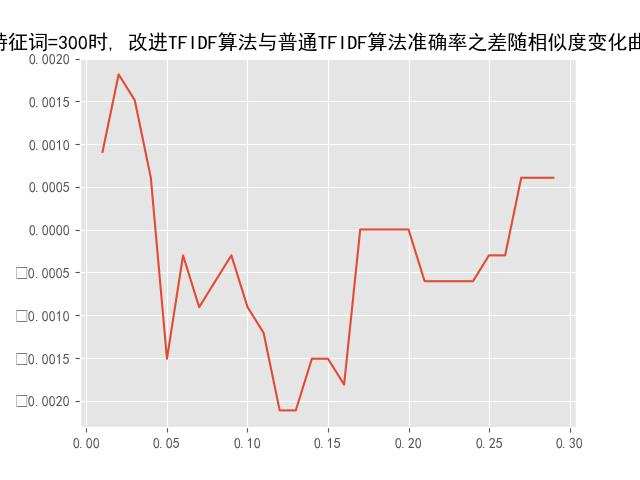
改进TFIDF算法中存在的参数为:【特征维数,相似度大小】
通过调整实验参数,来观察改进TFIDF算法与普通TFIDF算法文本分类准确率之差。
3.2、数据集
数据来源于 https://github.com/cystanford/text_classification 。数据集共包含四个类别,分别为“女性”,“体育”,“文学”,“校园”,原始数据集已经划分了测试集和训练集,并给出了停用词文档。
3.3、实验结果
5折交叉检验:


获取本项目的源代码
如果需要本项目的源代码,请扫描关注我的公众号,回复“论文源码”即可。

以上是关于文本分类基于改进TF-IDF特征的中文文本分类系统的主要内容,如果未能解决你的问题,请参考以下文章