基于改进CHI和PCA的文本特征选择
Posted 征途黯然.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于改进CHI和PCA的文本特征选择相关的知识,希望对你有一定的参考价值。
摘要:改进CHI算法后,结合PCA算法,应用于文本的特征选择,提高了精度。
参考文献:[1]文武,万玉辉,张许红,文志云.基于改进CHI和PCA的文本特征选择[J].计算机工程与科学,2021,43(09):1645-1652.
一、引言
文本特征空间的高维稀疏性严重影响了分类器的训练效率及分类精度,需要使用一些算法对高维的矩阵来降维、去噪。常用的特征选择算法有:文档频率DF、互信息MI、卡方检验CHI、信息增益IG、主成分分析PCA。
二、基础算法
2.1、CHI算法【卡方统计】
基本思想如下所示:
(1)由CHI计算公式计算特征词与类别的CHI值;
(2)根据所有特征与类别的CHI值大小排序;
(3)选取前T个特征词作为输出特征子集。
CHI算法的主要目的是筛选出和类别相关性强的特征,去除噪声特征,实现降维。
初始卡方统计公式:

以上公式中A、B、C、D的含义如下:
| ` | Ci类 | 非Ci类 |
|---|---|---|
| 含有特征tk的文本数 | A | B |
| 不含有特征tk的文本数 | C | D |
如果数据集有n类,那么一个特征对每个类别都会有一个CHI值,这里会涉及到卡方值的选取模型问题,有2种方式:
1、求n个卡方值的max
2、求n个卡方值的avg
通常使用第1种,max值更具有代表性,更能表达出一个特征对分类的话语权。
2.2、PCA算法【主成分分析】
基本思想如下所示:

主成分分析 PCA 在尽可能保留较多原始特征信息的基础上,根据方差最大化,将原始的高维特征重新组合在低维空间上表达出来,提取出贡献率大的综合特征,实现降维。
PCA是特征选择,还是特征杂糅在一起(综合)?求解。
2.3、CHI算法的改进ICHI
从CHI算法的缺点出发:
1、词频问题。CHI算法仅考虑特征词是否出现在文档中,没有考虑特征词的出现次数。原始CHI公式中,A、B、C、D计算的都是特征是否在文本中出现,而不是特征在文本中出现的几次,相当于求布尔值。
2、文档分布。对于具体类别内部,若某特征词仅在此类中的个别文档中出现,在其它文档中不出现,则该特征词所代表的类别信息就少很多。
3、类别频。若特征词只出现在极少类别中,它就会比在较多类别中都出现的特征更重要。
4、负相关特性。负相关特性会对特征的重要性产生负面的影响,从CHI的原始公式中可以看出,特征词与类别成正相关,即A×D-B×C>0,卡方值越大,特征越重要。若特征词与类别成负相关,即A×D-B×C <0,该特征词对此类别越不重要,卡方值应越小,但实际卡方值却变大,这就影响了分类效果。
理论上说,由于CHI的原始公式是求平方的,如果负相关,最终平方也是大于零的。但是卡方值算的就是数据的信息程度,越偏离,信息量越大。此处有待研究。
CHI算法的缺点的解决办法:
1、词频问题。引入基于类别文档归一化的特征频度因子。同时为了防止分布不均匀,主要措施是特征词在文本内归一化,再在类别内归一化。公式如下:

2、文档分布。提出了类别内部特征词的文档分布因子。算一下特征在内中分布。公式如下:
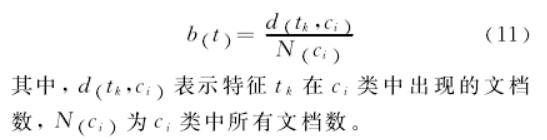
3、类别频。 提出了逆类别分布因子。类似于TF-IDF思想。公式如下:

4、负相关特性。解决办法是当A×D-B×C <0,卡方值直接为0。
总结:
最终改进后的ICHI算法公式为:
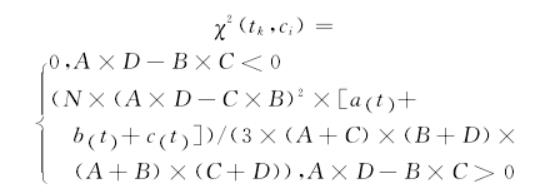
三、代码实验
3.1、实验思路
根据以下4种方法:
(1)普通CHI算法来选择特征
(2)改良ICHI算法来选择特征
(3)普通CHI算法来选择特征 + PCA
(4)改良ICHI算法来选择特征 + PCA
比较不同算法之间,文本分类的准确率。
3.2、数据集
数据来源于 https://github.com/cystanford/text_classification 。数据集共包含四个类别,分别为“女性”,“体育”,“文学”,“校园”,原始数据集已经划分了测试集和训练集,并给出了停用词文档。
3.3、实验结果
| 特征维度 | sklean的chi2卡方 | 手写普通卡方CHI | 手写改进卡方ICHI | 手写普通卡方+PCA | 手写改进卡方ICHI+PCA |
|---|---|---|---|---|---|
| 4000 | 0.86 | 0.875 | 0.875 | 0.87 | 0.88 |
| 6000 | 0.865 | 0.885 | 0.885 | 0.88 | 0.885 |
| 8000 | 0.88 | 0.855 | 0.875 | 0.855 | 0.88 |
| 10000 | 0.87 | 0.875 | 0.88 | 0.875 | 0.88 |
| 12000 | 0.865 | 0.865 | 0.875 | 0.875 | 0.865 |
| 14000 | 0.87 | 0.87 | 0.885 | 0.875 | 0.88 |
| 16000 | 0.88 | 0.87 | 0.895 | 0.885 | 0.89 |
| 18000 | 0.875 | 0.865 | 0.9 | 0.875 | 0.89 |
| 20000 | 0.87 | 0.865 | 0.875 | 0.885 | 0.87 |
| 22000 | 0.875 | 0.865 | 0.885 | 0.9 | 0.89 |
| 24000 | 0.87 | 0.875 | 0.885 | 0.89 | 0.88 |
【注】PCA算法降维到3000个特征。
实验结果分析:
1、对比chi2、CHI、ICHI方法,可以看到ICHI算法准确率效果确实最好;
2、对比CHI+PCA、ICHI+PCA,可以看到仍然是ICHI+PCA效果好。
获取本项目的源代码
如果需要本组件的源代码,请扫描关注我的公众号,回复“ICHIPCA”即可。

以上是关于基于改进CHI和PCA的文本特征选择的主要内容,如果未能解决你的问题,请参考以下文章