文本分类采用同义词的改进TF-IDF权重的文本分类
Posted 征途黯然.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文本分类采用同义词的改进TF-IDF权重的文本分类相关的知识,希望对你有一定的参考价值。
·摘要:
尝试使用相似词之间的关联性,来改变TF-IDF权重,依次改进普通TF-IDF文本分类算法的精确度,失败。
·参考文献:
[1]但唐朋,许天成,张姝涵.基于改进TF-IDF特征的中文文本分类系统[J].计算机与数字工程,2020,48(03):556-560.
[2]任姚鹏,陈立潮,张英俊,袁英.结合语义的特征权重计算方法研究[J].计算机工程与设计,2010,31(10):2381-2383+2387.DOI:10.16208/j.issn1000-7024.2010.10.022.
[3]田久乐,赵蔚.基于同义词词林的词语相似度计算方法[J].吉林大学学报(信息科学版),2010,28(06):602-608.
[1] 基于改进TF-IDF特征的中文文本分类系统
论文提出了一种改进计算TF-IDF权重的算法,提出了一个a因子乘上原TF-IDF公式,a因子是根据特征词之间的相似度关系得到的,而词语相似度是基于“知网”计算的。详细情况可以参考上一篇博客:【文本分类】基于改进TF-IDF特征的中文文本分类系统
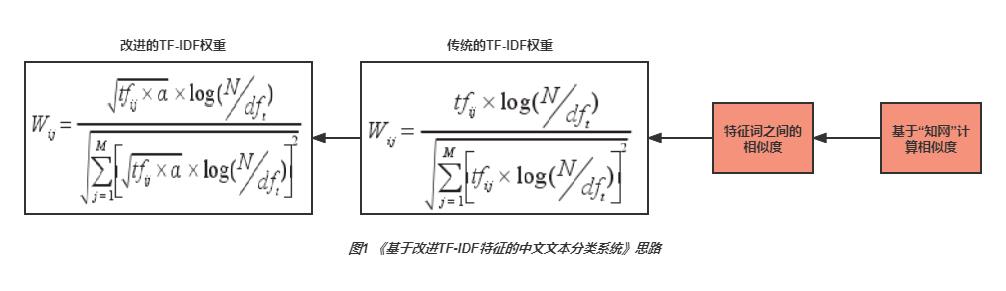
[注一]:基于“知网”来实现词语相似度之间的计算,需要Linux平台,暂时不好实现;
[注二]:本篇论文的实验结果显示,改进方法只比传统TF-IDF好一点点。我通过代码复现,发现只要在传统的TF-IDF公式上给TF(即词频)开方,在特征词在万以内,精确度就会比传统好1.4%左右。所以这篇论文的实验结果并不能表明是a因子提升了精确度,有99%的可能是因为加了平方根。
[2] 结合语义的特征权重计算方法研究
论文提出一种改进TF-IDF权重的方法,应用于文本聚类,对于文本分类具有参考价值。
论文主要改进IDF(逆文档频率),把计算IDF公式中的DF(文档频率)计算方式加以改进。传统DF就是在所有文本中特征词t出现过的文本数量,改进DF是在所有文本中特征词t与它的相似词出现过的文本数量的平均数。
特征词之间的相似关系,基于“知网”来实现。
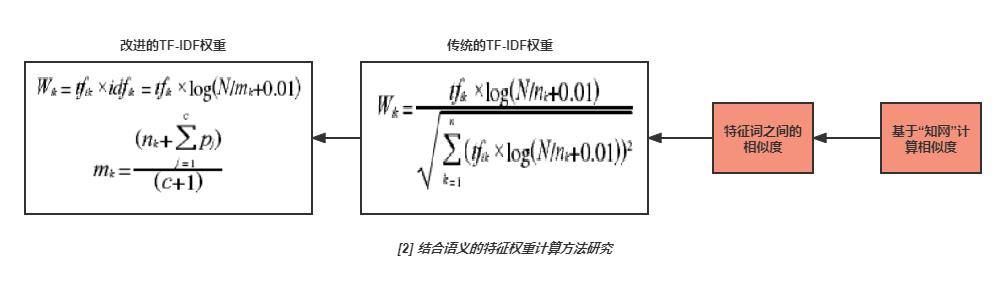
[注一]:基于“知网”来实现词语相似度之间的计算,需要Linux平台,暂时不好实现;
[注二]:将此改进权重应用于文本分类,采用同义词词林来做词语相似度计算,效果不明显。
[3] 基于同义词词林的词语相似度计算方法
《同义词词林》是梅家驹等人于1983年编纂而成,哈工大完成了一部具有汉语大词表的哈工大信息检索研究室《同义词词林扩展版》,《同义词词林扩展版》收录词语近7万条。
《同义词词林扩展版》不仅包括近义词,还包括同类词、关联词。
对于一类相似词语,具有一个指定的编码,编码表如下:
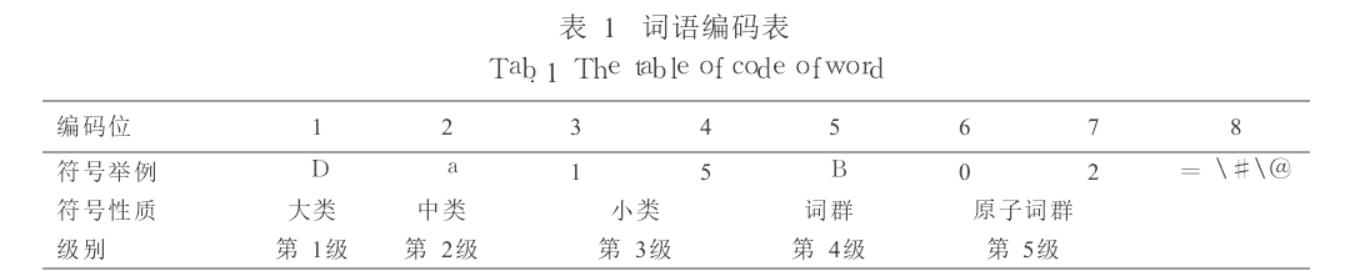
对于输入的两个词a、b,使用一定的算法,对a、b两个词的编码进行相似度计算,计算结果在[0,1]。计算结果越大表示越相似。
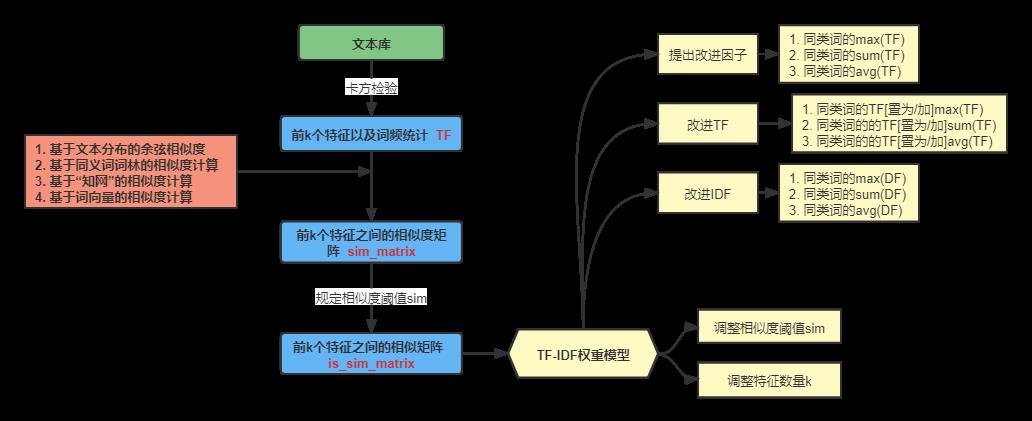
实验思路
以上是关于文本分类采用同义词的改进TF-IDF权重的文本分类的主要内容,如果未能解决你的问题,请参考以下文章