sqoop的简单使用
Posted 啊帅和和。
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了sqoop的简单使用相关的知识,希望对你有一定的参考价值。
sqoop是一种数据集成工具,主要负责异构数据源的互相导入,也就是
可以将关系型数据库的数据(比如MySQL的数据)导入HDFS中,或者从HDFS中导入到关系型数据库中
但是不能自己导入自己,也就是说,不能自己从MySQL导入到MySQL,不能从HDFS导入到HDFS
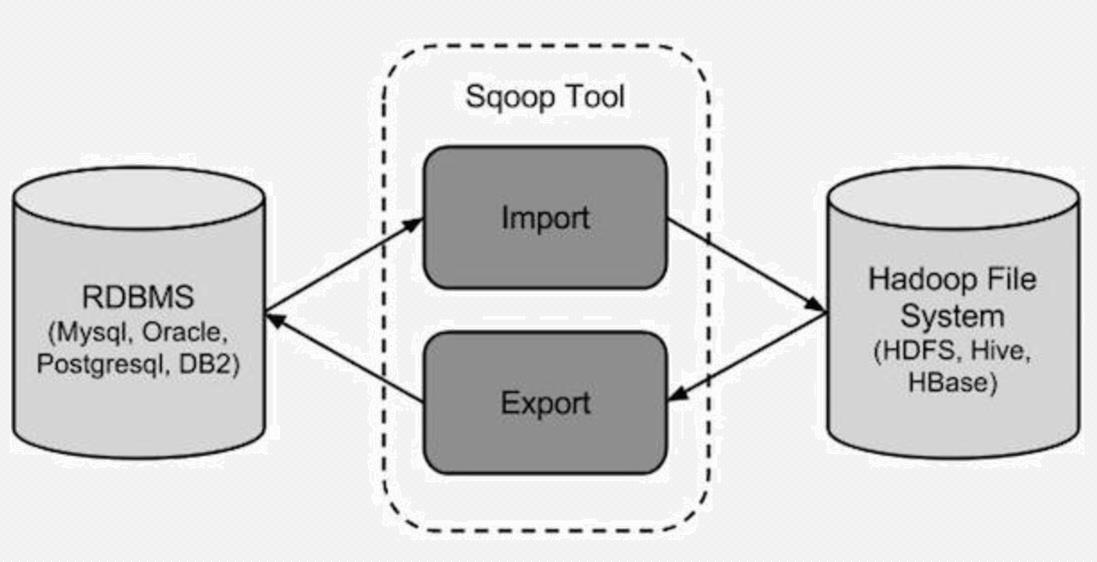
import
从传统关系型数据库导入到HDFS、HIVE、HBASE…
传统关系型数据到导入到HDFS
编写脚本:
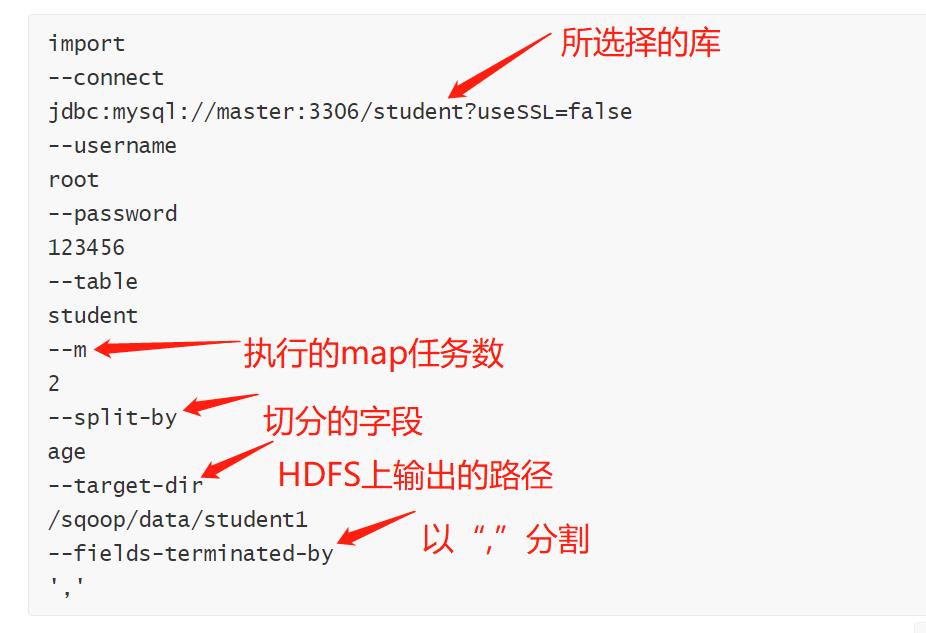
执行脚本:
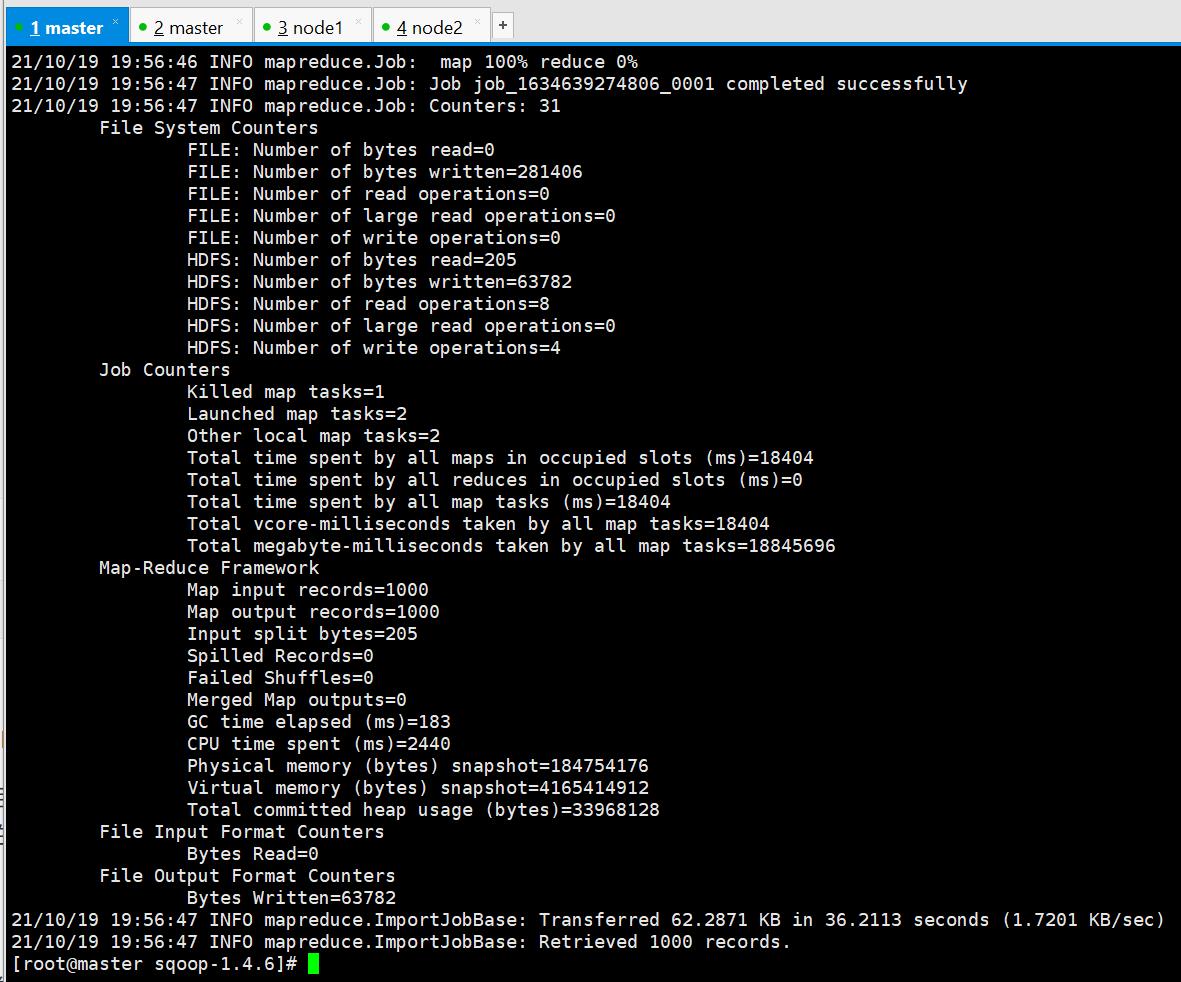
sqoop --options-file /opt/datas/sql/mysqltoHDFS.conf
执行成功
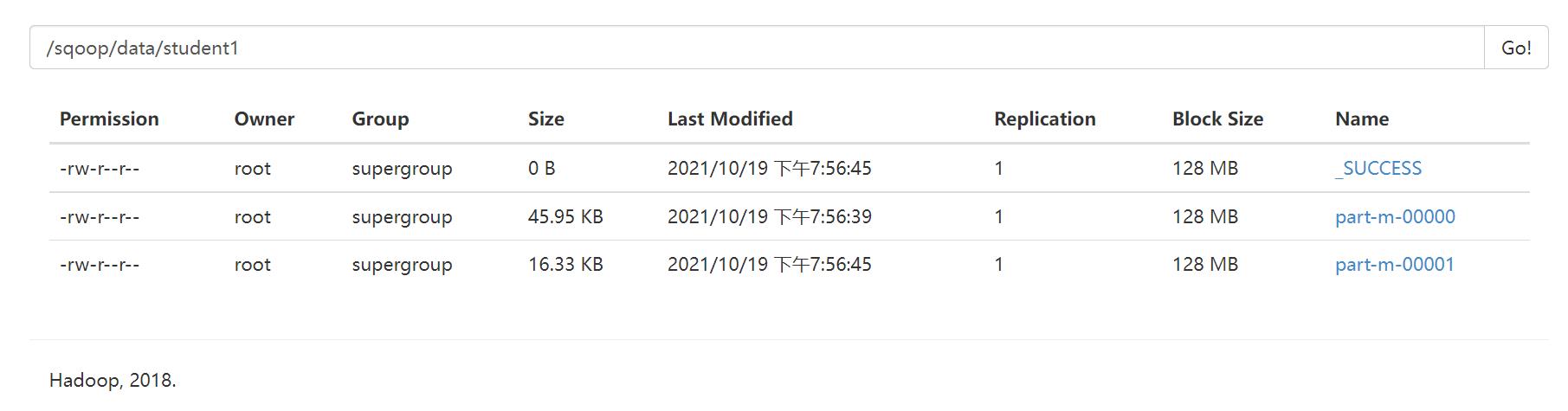
以age作为分割,并且设置了map的任务数为2之后,得到了两个文件(这里可以看到名字为part-m-00000和part-m-00001,其中的m指的是map)
注意事项
注意事项:
1、–m 表示指定生成多少个Map任务,不是越多越好,因为MySQL Server的承载能力有限
2、当指定的Map任务数>1,那么需要结合--split-by参数,指定分割键,以确定每个map任务到底读取哪一部分数据,最好指定数值型的列,最好指定主键(或者分布均匀的列=>避免每个map任务处理的数据量差别过大)
3、如果指定的分割键数据分布不均,可能导致数据倾斜问题
4、分割的键最好指定数值型的,而且字段的类型为int、bigint这样的数值型
5、编写脚本的时候,注意:例如:--username参数,参数值不能和参数名同一行
–username root // 错误的
// 应该分成两行
–username
root
6、实际上sqoop在读取mysql数据的时候,用的是JDBC的方式,所以当数据量大的时候,效率不是很高
7、sqoop底层通过MapReduce完成数据导入导出,只需要Map任务,不需要Reduce任务
8、每个Map任务会生成一个文件
传统关系型数据到导入到HIVE
编写脚本
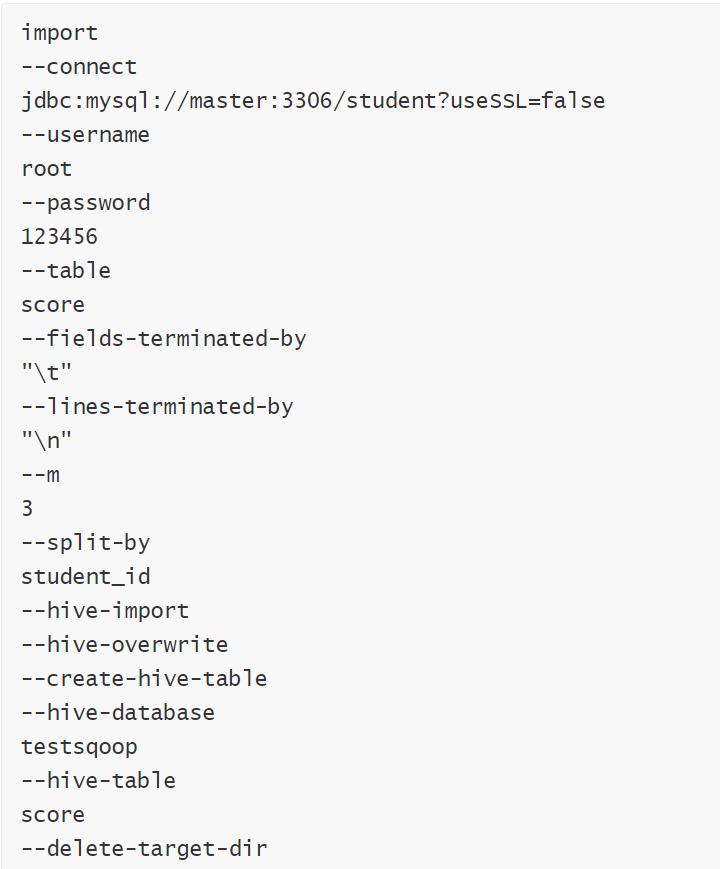
在hive中创建testsqoop库

将HADOOP_CLASSPATH加入到环境变量(/etc/profile)中
export HADOOP_CLASSPATH=$HADOOP_HOME/lib:$HIVE_HOME/lib/*
将hive-site.xml放入SQOOP_HOME/conf/
cp /opt/modules/hive-1.2.1/conf/hive-site.xml /opt/modules/sqoop-1.4.6/conf/
在创建脚本的执行路径下执行脚本
sqoop --options-file MySQLToHIVE.conf
执行成功
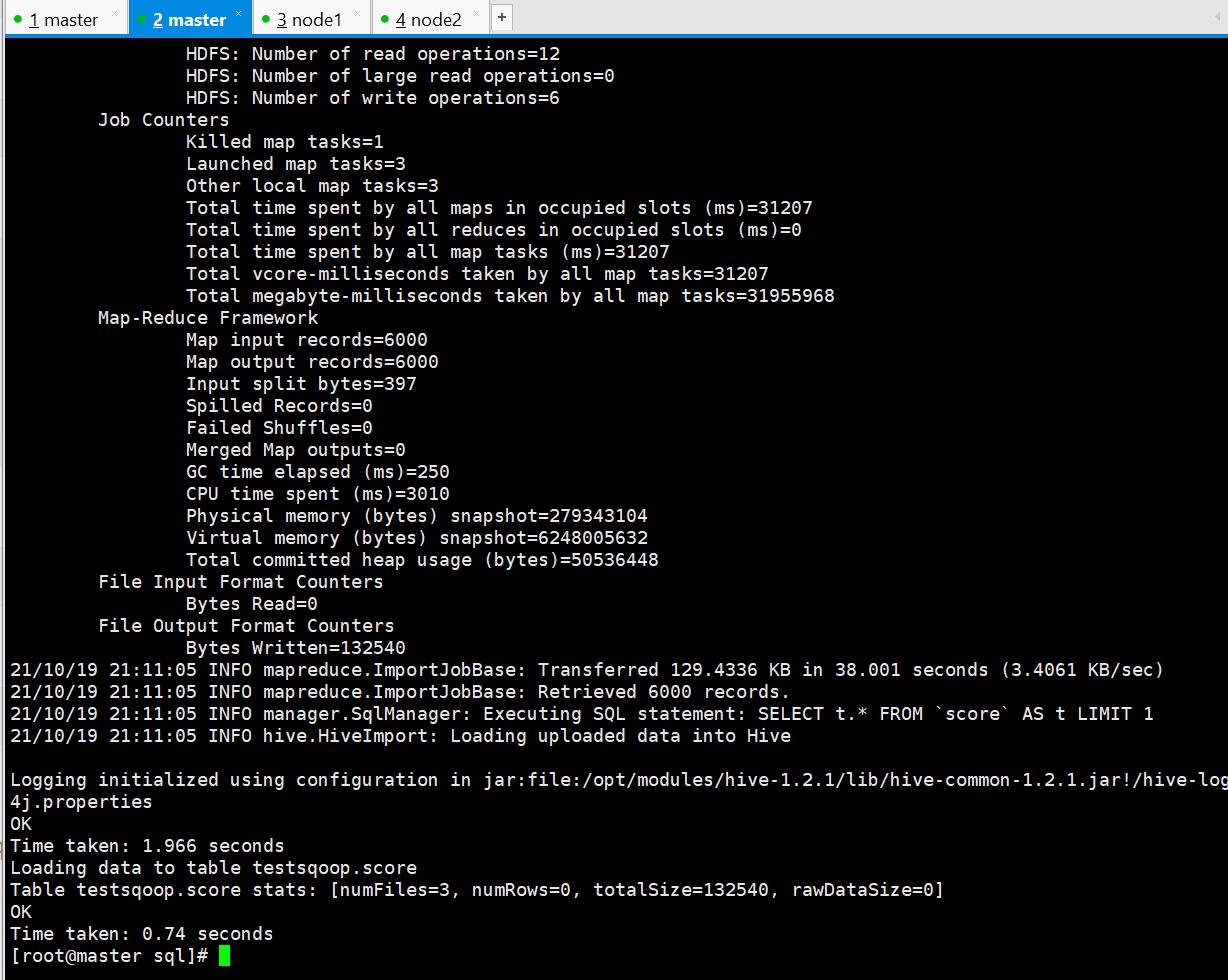
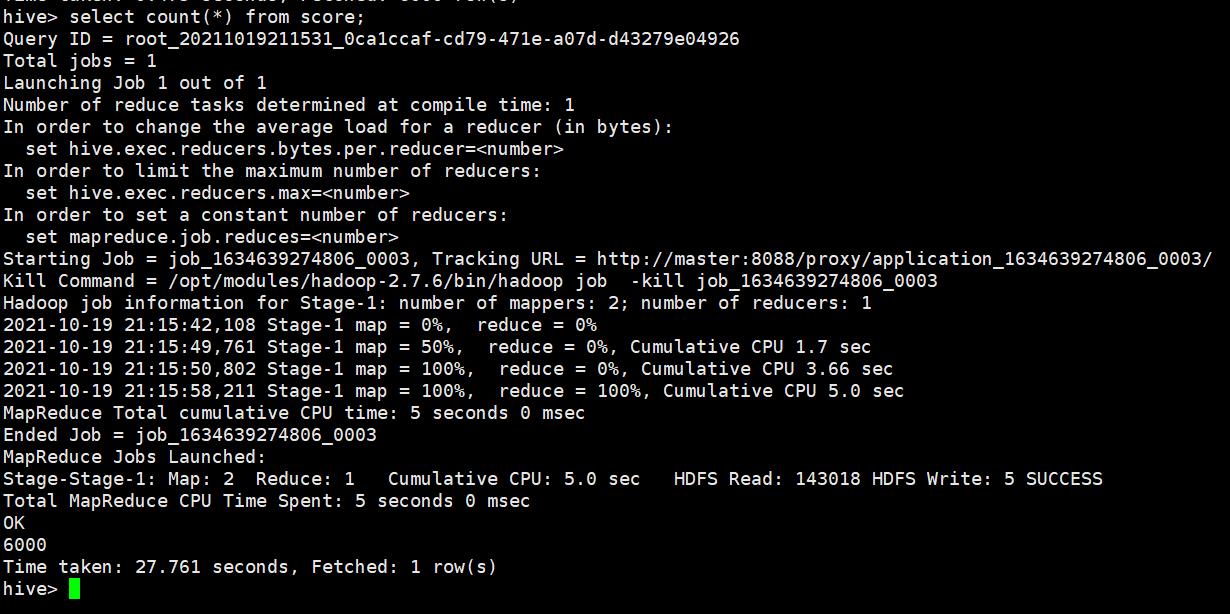
提升关系型数据库导入到HIVE的执行效率
-direct
加上这个参数,可以在导出MySQL数据的时候,使用MySQL提供的导出工具mysqldump,加快导出速度,提高效率
需要将master上的/usr/bin/mysqldump分发至 node1、node2的/usr/bin目录下
scp /usr/bin/mysqldump node1:/usr/bin/
scp /usr/bin/mysqldump node2:/usr/bin/
-e参数的使用
传统关系型数据到导入到HBASE
编写脚本
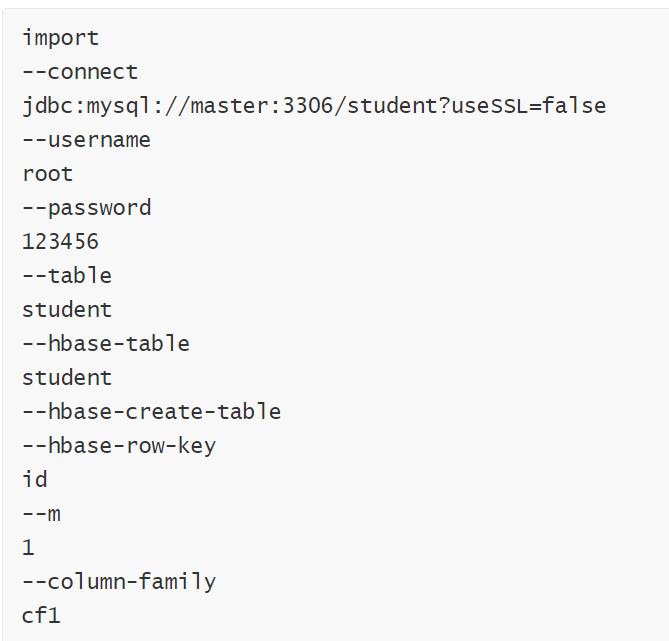
hbase中创建student表
create ‘student’,‘cf1’
执行脚本
sqoop --options-file MYSQLtoHBase.conf
执行成功
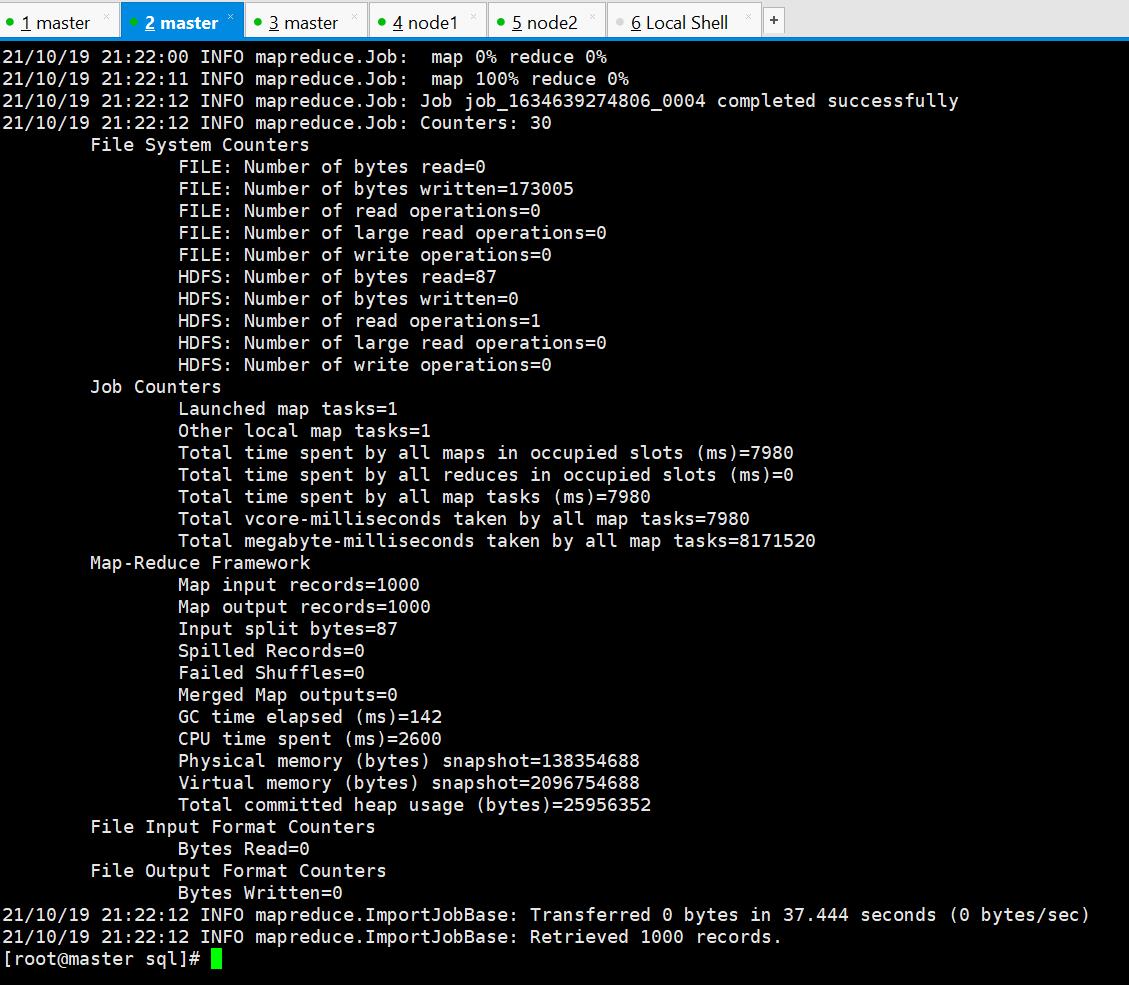
hbase中数据导入成功
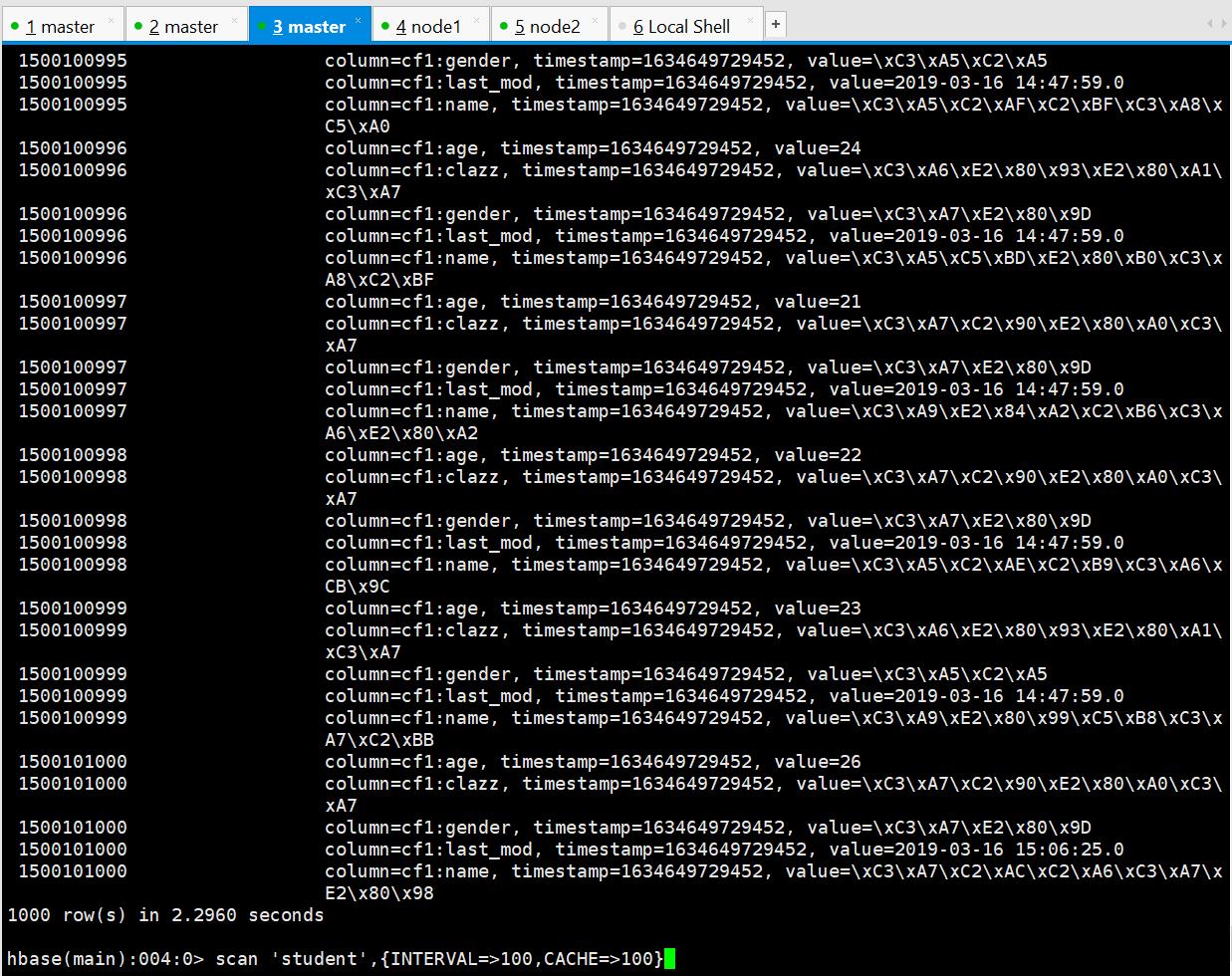
export
将HDFS中的数据导入到MYSQL
编写脚本
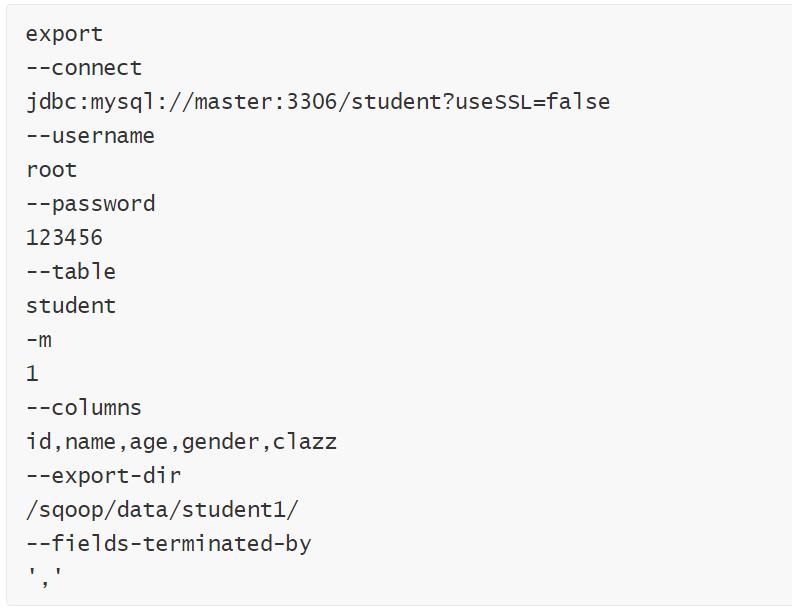
清空MySQL中student表中的数据
执行脚本
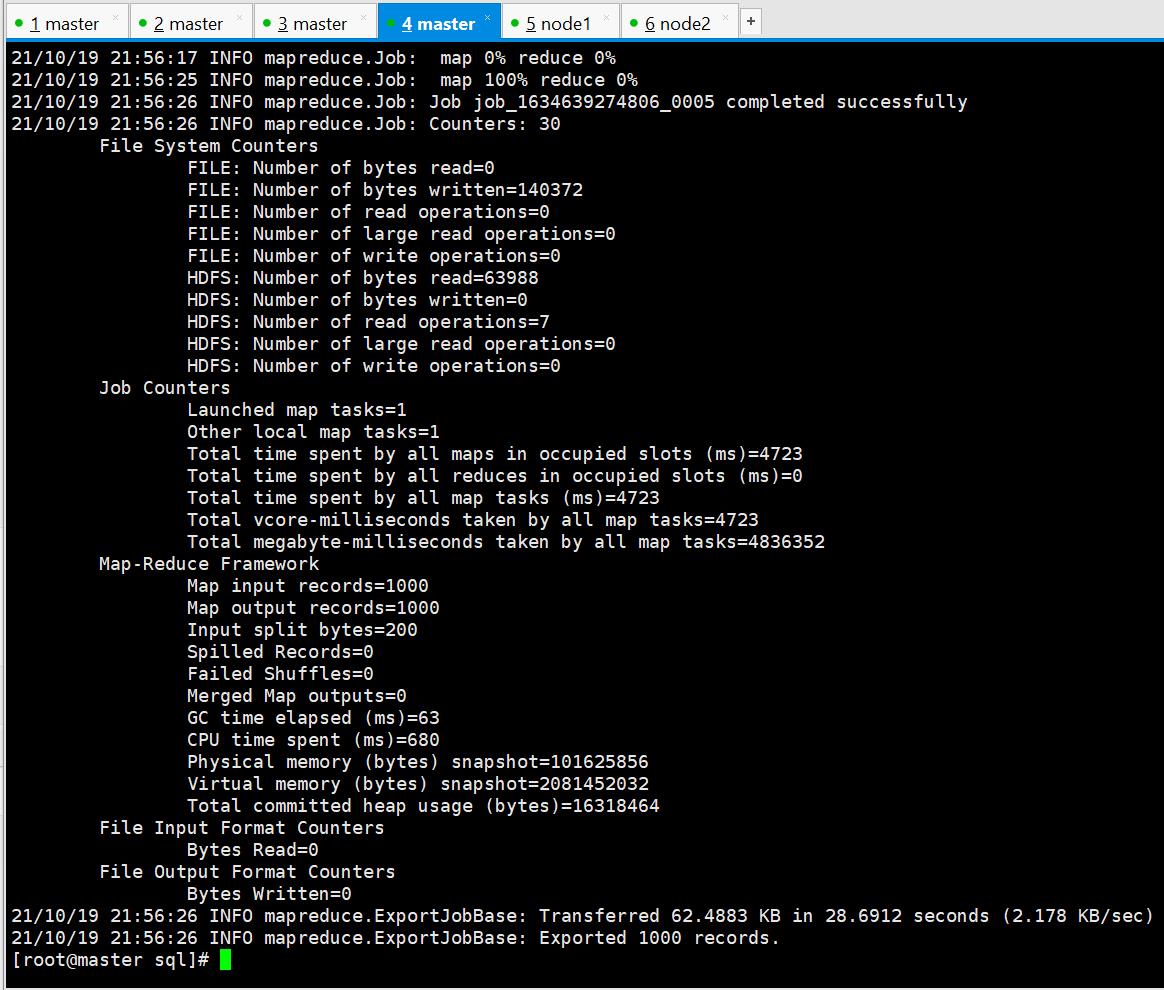
sqoop --options-file HDFSToMySQL.conf
执行成功
感谢阅读,我是啊帅和和,一位大数据专业大四学生,祝你快乐。
以上是关于sqoop的简单使用的主要内容,如果未能解决你的问题,请参考以下文章