AlexNet
Posted frighting_ing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AlexNet相关的知识,希望对你有一定的参考价值。
AlexNet
简介
AlexNet网络,是2012年ImageNet竞赛冠军获得者Hinton和他的学生Alex Krizhevsky设计的。在那年之后,更多的更深的神经网路被提出,比如优秀的vgg,GoogleLeNet。其官方提供的数据模型,准确率达到57.1%,top 1-5 达到80.2%. 这项对于传统的机器学习分类算法而言,已经相当的出色。
论文:《ImageNet Classification with Deep Convolutional Neural Networks》
AlexNet创新点:
- 成功应用ReLU激活函数(所有卷积层都使用ReLU作为非线性映射函数,使模型收敛速度更快)
- 成功使用Dropout机制(使用随机丢弃技术(dropout)选择性地忽略训练中的单个神经元,避免模型的过拟合)
- 使用了重叠最大池化(Max Pooling)(目前较少使用)
- 使用LRN对局部的特征进行归一化,结果作为ReLU激活函数的输入能有效降低错误率(局部响应归一化)(目前较少使用,以BN为主)
- 在多个GPU上进行模型的训练,不但可以提高模型的训练速度,还能提升数据的使用规模(目前训练使用较少)
- 使用了数据增强策略(Data Augmentation)缓和过拟合问题
- 平移和翻转
- 使用了PCA对RGB像素降维的方式
预测
对每张图像提取出5张(四个角落以及中间)以及水平镜像版本,总共10张,平均10个预测作为最终预测。
网络结构
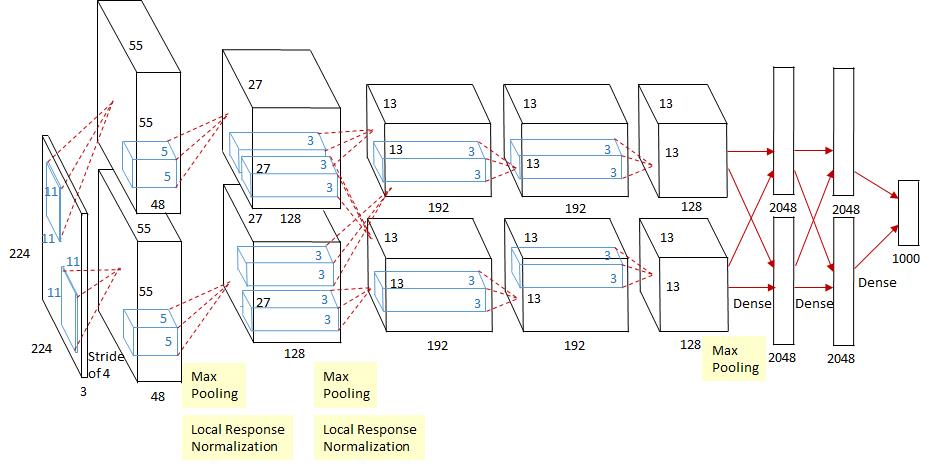
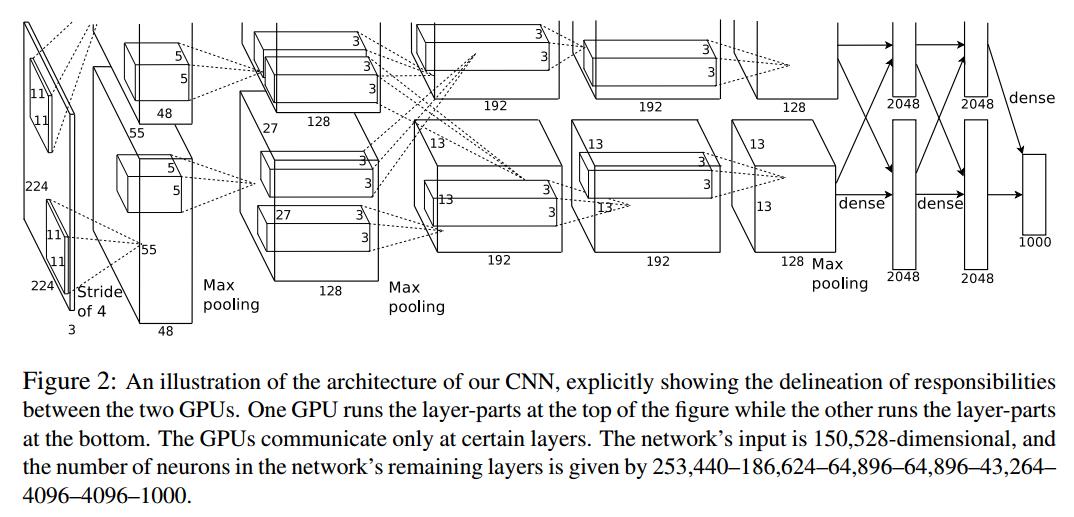
自己在验证的时候,发现了一些BUG,input_image图像的大小应该为227x227x3,图注的253440计算有误,应该为55*55*48*2 (253400 = 48*48*55*2),另外,网络中每层的结构也找了一张非常PL的图,附下:


第一层:卷积层1,输入为 224×224×3,经过验算,原文应该有误,正确图像尺寸为 227×227×3的图像,卷积核的数量为96,论文中两片GPU分别计算48个核; 卷积核的大小为 11×11×3; stride = 4, stride表示的是步长,pad = 0, 表示不扩充边缘;
卷积后的图形大小是怎样的呢?
wide = (227 + 2 * padding - kernel_size) / stride + 1 = 55
height = (227 + 2 * padding - kernel_size) / stride + 1 = 55
dimention = 96
然后进行 (Local Response Normalized), 后面跟着池化pool_size = (3, 3), stride = 2, pad = 0 最终获得第一层卷积的feature map
最终第一层卷积的输出为2727128*2
第二层:卷积层2, 输入为上一层卷积的feature map, 卷积的个数为256个,论文中的两个GPU分别有128个卷积核。卷积核的大小为:5×5×48 ; pad = 2, stride = 1; 然后做 LRN,最后 max_pooling, pool_size = (3, 3), stride = 2;
第三层:卷积3, 输入为第二层的输出,卷积核个数为384, kernel_size = (3×3×256 563×3×256), padding = 1, 第三层没有做LRN和Pool
第四层:卷积4, 输入为第三层的输出,卷积核个数为384, kernel_size = (3×3 3), padding = 1, 和第三层一样,没有LRN和Pool
第五层:卷积5, 输入为第四层的输出,卷积核个数为256, kernel_size = (3×3 3), padding = 1。然后直接进行max_pooling, pool_size = (3, 3), stride = 2;
第6,7,8层是全连接层,每一层的神经元的个数为4096,最终输出softmax为1000,因为上面介绍过,ImageNet这个比赛的分类个数为1000。全连接层中使用了RELU和Dropout。
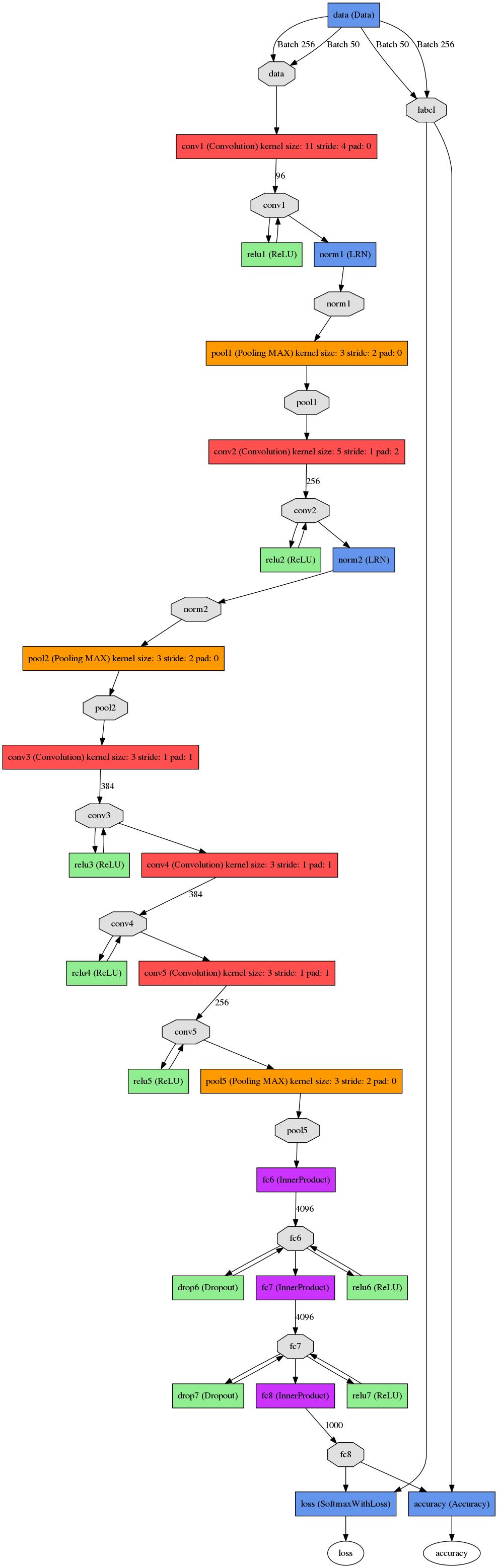
虽然AlexNet已经很少被使用,但该方法产生了巨大的影响
网络框架代码实现
注:模型训练使用的是单GPU。Image
import torch.nn as nn
from torchsummary import summary
class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
super(AlexNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=96, kernel_size=11, stride=4),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.LocalResponseNorm(size=5, alpha=1e-4, beta=0.75, k=1.)
)
self.layer2 = nn.Sequential(
nn.Conv2d(in_channels=96, out_channels=256, kernel_size=5, stride=1, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.LocalResponseNorm(size=5)
)
self.layer3 = nn.Sequential(
nn.Conv2d(in_channels=256, out_channels=384, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
)
self.layer4 = nn.Sequential(
nn.Conv2d(in_channels=384, out_channels=384, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True)
)
self.layer5 = nn.Sequential(
nn.Conv2d(in_channels=384, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2)
)
self.layer6 = nn.Sequential(
nn.Linear(in_features=9216, out_features=4096),
nn.ReLU(inplace=True),
nn.Dropout()
)
self.layer7 = nn.Sequential(
nn.Linear(in_features=4096, out_features=4096),
nn.ReLU(inplace=True),
nn.Dropout()
)
self.layer8 = nn.Linear(in_features=4096, out_features=num_classes)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.layer5(x)
x = x.view(x.size(0), -1)
x = self.layer6(x)
x = self.layer7(x)
x = self.layer8(x)
return x
model = AlexNet()
summary(model,(3,227,227))
运行完成后可查看网络整体模型框架等信息哦
完整代码:
https://link.zhihu.com/?target=https%3A//github.com/sloth2012/AlexNet
以上是关于AlexNet的主要内容,如果未能解决你的问题,请参考以下文章