AlexNet-pytorch实现
Posted TOPthemaster
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AlexNet-pytorch实现相关的知识,希望对你有一定的参考价值。
AlexNet
1.网络架构
如图所示可见其结构为:

AlexNet网络共八层,五层卷积层和三层全连接层。这是一个非常经典的设计,为后续神经网络的发展提供了极大的贡献。
2.pytorch网络设计
网络设计部分做了一些小的修改,目的是为了适配minist的3x28x28的输入图片大小。
网络构造代码部分:
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(3, 96, 11, 1, 5), # in_channels, out_channels, kernel_size, stride, padding
nn.ReLU(),
nn.MaxPool2d(3, 1), # kernel_size, stride 26x26
# 减少卷积窗口,使用填充为2来使输入输出大小一致
nn.Conv2d(96, 256, 5, 1, 2),
nn.ReLU(),
nn.MaxPool2d(4, 2), # 12x12
# 下面接三个卷积层
nn.Conv2d(256, 384, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(384, 384, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(384, 256, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(4, 2) # 5x5
)
self.fc = nn.Sequential(
nn.Linear(256 * 5 * 5, 4096),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(4096, 10),
)
def forward(self, img):
img.shape[0]
# img.resize_(3,224,224)
feature = self.conv(img)
output = self.fc(feature.view(img.shape[0], -1))
return output
3.网络测试
一些基础设置与上一篇文章一致,还是贴一下代码。
网络测试部分我使用的是minist数据集,为了贴近真实(主要是方便我自己懂),在下载了数据集之后将其转为了图片数据集,更为直观。数据集分为train 和test两部分,在测试中需要做如下配置:
1.依赖资源引入
draw_tool是一个自己编写的绘制loss,acc的画图库,device使用了我电脑的1050ti显卡。
import torch
from matplotlib import pyplot as plt
import torch.optim as optim
from torch.autograd import Variable
import torch.nn.functional as F
from torch import nn
from torchsummary import summary
from torchvision import transforms
from torch.utils.data import Dataset, DataLoader
from PIL import Image
import draw_tool
root = "F:/pycharm/dataset/mnist/MNIST/"
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
draw = draw_tool.draw_tool()
2.数据集的读取和分类
#加载图片
def default_loader(path):
return Image.open(path).convert('RGB')
#构造标注和图片相关
class MyDataset(Dataset):
def __init__(self, txt, transform=None, target_transform=None, loader=default_loader):
fh = open(txt, 'r')
imgs = []
for line in fh:
line = line.strip('\\n')
line = line.rstrip()
words = line.split()
imgs.append((words[0], int(words[1])))
self.imgs = imgs
self.transform = transform
self.target_transform = target_transform
self.loader = loader
def __getitem__(self, index):
fn, label = self.imgs[index]
img = self.loader(fn)
if self.transform is not None:
img = self.transform(img)
return img, label
def __len__(self):
return len(self.imgs)
train_data = MyDataset(txt=root + 'rawtrain.txt', transform=transforms.ToTensor())
test_data = MyDataset(txt=root + 'rawtest.txt', transform=transforms.ToTensor())
train_loader = DataLoader(dataset=train_data, batch_size=31, shuffle=True)
test_loader = DataLoader(dataset=test_data, batch_size=31, shuffle=True)
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))
])
3.模型训练设置
model = AlexNet()
#使用softmax分类
criterion = torch.nn.CrossEntropyLoss()
#设置随机梯度下降 学习率和L2正则
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
#使用GPU训练
model = model.to(device)
4.训练
每训练一个epoch 做一次平均loss train acc test acc的计算绘制
def train(epoch):
running_loss = 0.0
num_correct = 0.0
total = 0
correct = 0
total = 0
test_acc = 0.0
# train
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
inputs = inputs.to(device)
target = target.to(device)
optimizer.zero_grad()
# forward + backward + update
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = torch.max(outputs.data, dim=1)
total += target.size(0)
num_correct += (predicted == target).sum().item()
# #test
# with torch.no_grad():
# for data in test_loader:
# images, labels = data
# images = images.to(device)
# labels = labels.to(device)
# outputs = model(images)
# _, predicted = torch.max(outputs.data, dim=1)
# total += labels.size(0)
#
# correct += (predicted == labels).sum().item()
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / len(train_loader)))
# print('Accuracy on test set: %d %%' % (100 * correct / total))
# test_acc=100 * correct / total
test_acc = test()
acc = (num_correct / len(train_loader.dataset) * 100)
print("num_correct=")
print(acc)
running_loss /= len(train_loader)
draw.new_data(running_loss, acc, test_acc, 2)
draw.draw()
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
test_acc = 100 * correct / total
print('Accuracy on test set: ', test_acc, '%')
return test_acc
5.结果统计
if __name__ == '__main__':
for epoch in range(20):
train(epoch)
torch.save(model.state_dict(), "minist_last.pth")
draw.show()
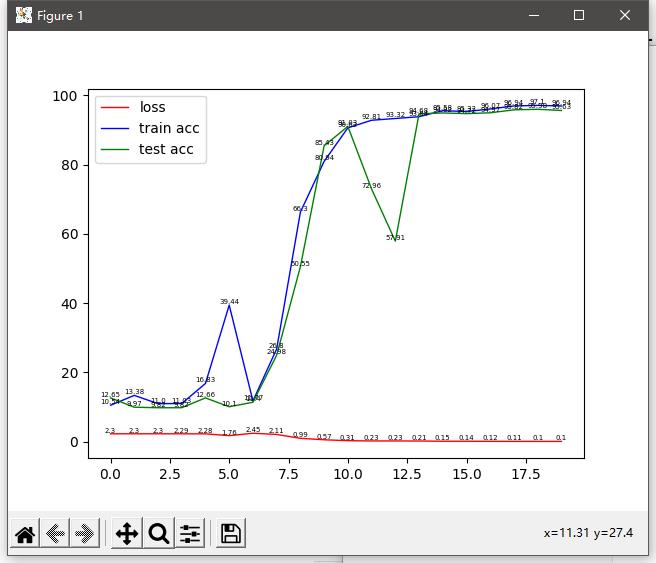
从图中效果可以看到随着训练次数的增加,loss在不断下降,train acc 和test acc 也在慢慢收敛,最终达到了train acc=97% test acc=96%的效果。但与之前上一文的训练有一样的问题所在,不知道为什么中途的test acc会突然下降,这里就不在往下继续训练了,网络变得更为复杂并不代表精度一定会上升,反而对于简单数据的预测来说,只会更差。
留下一个问题,就是为什么我的test acc 会突然下滑这么多,如果有朋友有自己的想法或者有大佬愿意回复我一下还请评论一下,谢谢。
以上是关于AlexNet-pytorch实现的主要内容,如果未能解决你的问题,请参考以下文章