李飞飞团队创建深度学习“游乐场”:AI也在自我进化,细思极恐!
Posted 程序员的店小二
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了李飞飞团队创建深度学习“游乐场”:AI也在自我进化,细思极恐!相关的知识,希望对你有一定的参考价值。
【导读】近日,斯坦福李飞飞教授等人的研究「深度进化强化学习」登上nature子刊,首次证明了「鲍德温效应」。或许,机器人形态的设计也可以通过一波「进化」来搞定?
动物的智慧是在和环境互动的过程中与身体形态同步进化的。
例如,仓鼠通过「进化」出长了好多腿的仓鼠球来逃避猫的追捕(doge)。

好吧,言归正传,AI也相当聪明,但与动物不同的是,AI通常是在硅基的芯片上实现的,并没有实体。
那么,如果给AI一个「身体」,这对于智能的进化是否重要?如果是的话,又该如何利用来创造更聪明的人工智能?
在李飞飞的带领下,斯坦福大学的研究小组创建了一个计算机模拟的「游乐场」——DERL(深度进化强化学习),其中被称为「Unimals」(通用动物)的智能体在经历不断变异和自然选择。论文刊登在《自然通讯》杂志上。

研究结果显示,虚拟生物的身体形状影响了它们学习新任务的能力,在更具挑战性的环境中学习和进化的形态,或者在执行更复杂的任务时,比那些在更简单的环境中学习和进化的形态学习进化得更快、更好。
在这项研究中,具有最成功的形态的Unimal也比前几代更快地掌握了任务,尽管它们最初的基线智力水平与前代相同。也就是说,「具身化」是智能进化的关键。

「我们通常专注于AI是如何实现人类大脑中神经元的功能,」研究小组成员、斯坦福大学HAI的联合主任李飞飞表示,「然而将AI看作是具有物理实体的东西是一种完全不同的范式。」
研究报告的共同作者、人文与科学学院应用物理学副教授、HAI副主任Surya Ganguli说:「据我们所知,这是第一次相关的模拟实验,其结果表明可以通过改变形态来加快学习的速度。」
「Unimal」宇宙
团队设置了一个虚拟空间,并将简单的模拟生物放入其中。当然,这些生物只是一些通过「随机方式」进行移动的「几何图形」(Unimal)。
在学习阶段中,有平坦的地形,有更具挑战性的地形,包括块状山脊、阶梯和光滑的山丘。Unimal必须在多变的地形上将一个块状物移动到目标位置。
训练结束后,每个Unimal与其他三个在相同环境/任务组合中训练过的Unimal进行比赛。胜者将产生一个单一的后代,该后代在面对与父母相同的任务之前,经历了一次涉及肢体或关节变化的突变。
最终,在训练了4000种不同的形态后,团队结束了模拟。此时,幸存的Unimal平均经历了10代的进化,其形态令人惊讶地多样化,包括两足动物、三足动物以及有手臂和无手臂的四足动物。

而最初,「几乎图形」只有一个「脑袋」和发达的「四肢」,他们有许多奇形怪状的姿势,「有些人蹒跚前行,有些如蜥蜴般的行走姿势。其他人挥舞着十分逗趣的行为风格,让人联想到「八爪鱼」。

咦?看起来似乎与旧实验没区别,别急,进化才刚刚开始。
这些Unimal生长在不同的星球中,星球中充满了「起伏的山丘」和「低矮的障碍物」,他们在更加激烈的环境中展开竞争。看看是否如大家所说,「逆境是成功之母」。
每个环境中的前 10 名Unimal被安排在了新任务中,从「新障碍」到将球移动到目标位置、将盒子推上山或在两点之间巡逻。这些「角斗士」真正展示了他们的虚拟勇气。
最终,那些能在「复杂的地形中」行走的 Unimal 比在「平地上的表亲」更快地学习新任务,并且完成的更好。
换句话说,它们通过「生存」而「进化」,但并不是「边做边学」。而是在复杂的环境中同时进行「进化」和「学习」,比如有台阶、丘陵、山脊和移动的地形,以便在这些复杂环境中进行操作。

在平坦的地形上,「章鱼flop」可能会以相同的时间到达终点线,但「适应山丘和山脊的身体配置」往往是更快速、更稳定和能力最强的。他们多才多艺的身体能够更好的利用他们的经验教训 - 很快他们就将竞争对手抛在了脑后。
都交给「进化」去做吧
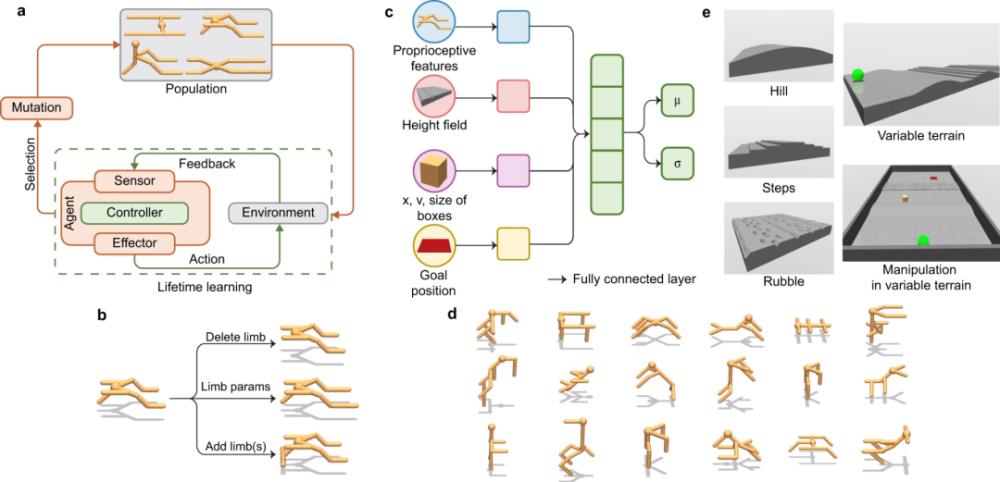
通用计算框架DERL利用两个相互作用的适应过程来制造具身的智能体
进化的外循环通过变异操作优化智能体的形态(b),内部强化学习循环优化了神经控制器的参数(c)。在可变地形的操纵中,智能体必须从初始位置(绿色球体)开始,将一个盒子移动到目标位置(红色方块)。
在每个环境完成三次进化运行后(每次有4000种形态),团队从每个环境中挑选出表现最好的10个Unimal,并从头开始训练它们完成8项全新的任务,如绕过障碍物、操纵一个球或将一个箱子推上斜坡。
最成功的Unimal在个体(通过较少的训练获得更好的表现)和跨代的学习方面也更快。团队发现,在早期祖先生命后期习得的行为能够在他们的后代生命早期表达出来。
此外,在10代之后,最成功的Unimal形态在学习同一任务的时间是其最早祖先的一半。
这也验证了美国心理学家James Mark Baldwin在19世纪末提出的假设:「学习具有适应性优势的事物的能力」可以通过达尔文的自然选择来传承。
人类不一定知道如何为奇怪的任务设计机器人的身体,例如爬过核反应堆提取废物,在地震后提供救灾,引导纳米机器人穿过人体,甚至做洗碗或叠衣服等家务。
或许,设计这些机器人的唯一出路就是交给「进化」去实现。
参考资料:
https://hai.stanford.edu/news/how-bodies-get-smarts-simulating-evolution-embodied-intelligence
https://techcrunch.com/2021/10/06/simulated-ai-creatures-demonstrate-how-mind-and-body-evolve-and-succeed-together/
来源:新智元
以上是关于李飞飞团队创建深度学习“游乐场”:AI也在自我进化,细思极恐!的主要内容,如果未能解决你的问题,请参考以下文章
李飞飞团队给机器人造了一个“模拟厨房”:洗切炒菜一条龙训练!人类还能VR监管 | 开源...