模型推理聊一聊昇腾 CANN TBE 算子开发方式
Posted 极智视界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了模型推理聊一聊昇腾 CANN TBE 算子开发方式相关的知识,希望对你有一定的参考价值。
欢迎关注我的公众号 [极智视界],获取我的更多笔记分享
O_o >_< o_O O_o ~_~ o_O
本文主要聊一聊华为昇腾 CANN TBE 开发方式。
之前也写过几篇关于昇腾部署相关的文章,在做昇腾卡部署或有兴趣的同学可以查阅:
-
今天这里主要聊一下 TBE 开发方式,分以下几个部分进行介绍:数据布局、达芬奇架构、TBE开发方式。
文章目录
1、数据布局
昇腾 AI 处理器中,为了提高通用矩阵乘法(GEMM)运算数据块的访问效率,所有张量数据统一采用 NC1HWC0 的五维数据格式。其中 C0 与微架构强相关,等于 AI Core 中矩阵计算单元的大小,对于 FP16 类型为 16,对于 INT8 类型则为 32,这部分数据需要连续存储,而 C1 = C / C0。
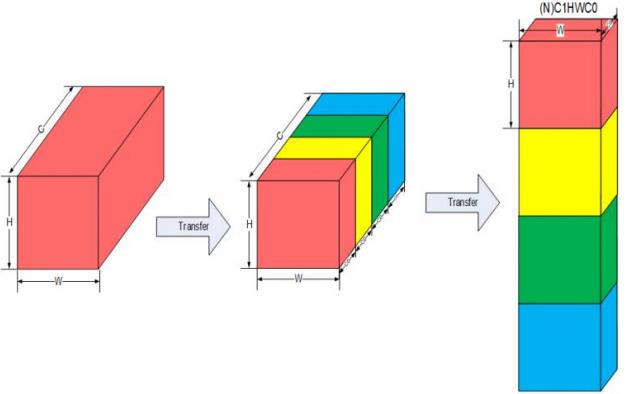
2、达芬奇架构
达芬奇架构本质上是为了适应某个特定领域中的常见应用和算法,通常称为特定域架构,昇腾 AI 处理器的计算核心主要由 AI Core 构成,负责执行向量和张量相关的计算密集型算子。它包括了三种基础计算资源:矩阵计算单元 (CubeUnit)、向量计算单元 (Vector Unit) 和 标量计算单元 (Scalar Unit)。在实际的计算过程中各司其职,形成了三条独立的执行流水线,在系统软件的统一调度下互相配合达到优化的计算效率,并且每一种计算单元都提供了不同精度和不同类型的计算方式。
2.1 计算单元
AI Core 中的执行单元主要包括:Cube、Vector 和 Scalar,完成 AI Core 中不同类型的数据计算。
关于这个模块可以查看这篇:《【系统架构】一文看懂昇腾达芬奇架构计算单元》,这里不多说了。
2.2 存储单元
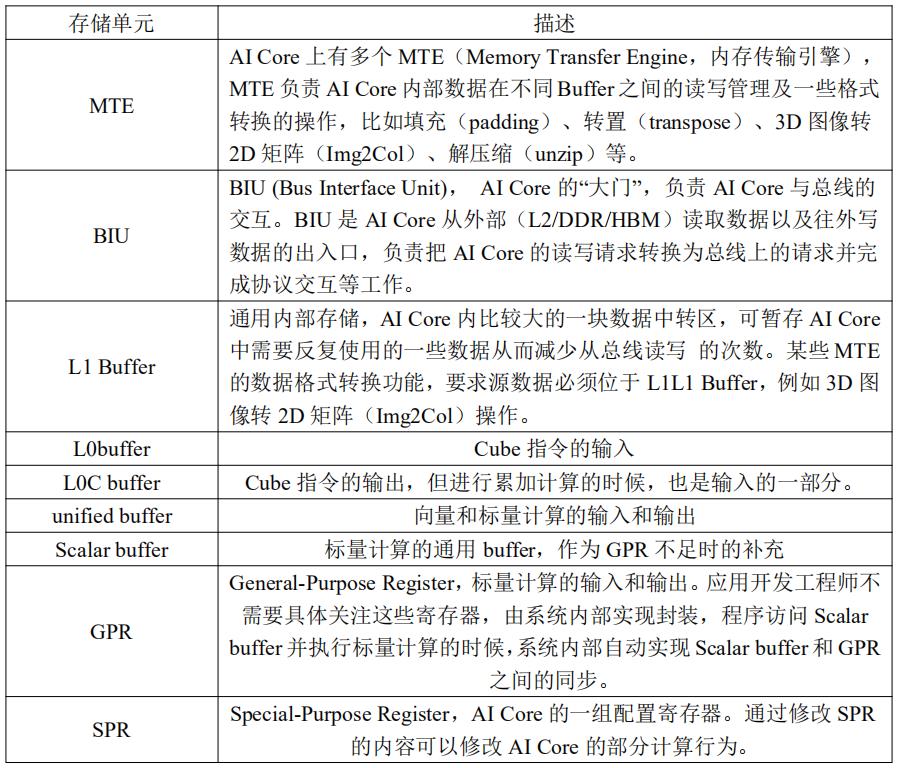
其中 buffer 主要是用来做向量计算或者标量计算的临时数据保存,后两种的寄存器主要是用来标量计算,AI core 的每种存储单元只能使用特定指令来访问。
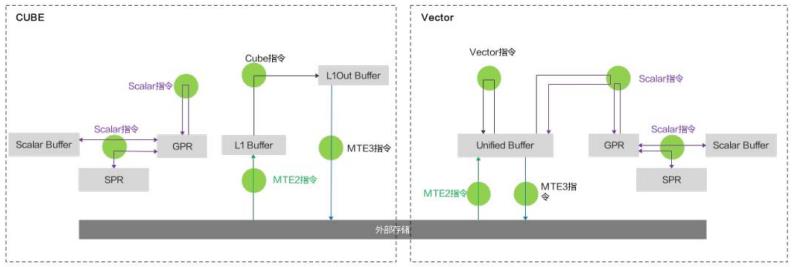
上图的存储单元是软件层面的概念,其中:
- Scalar Buffer 对应硬件存储单元 Scalar Buffer;
- Unified Buffer 对应硬件存储单元 Unified Buffer;
- L1 Buffer 对应硬件存储单元 L1 Buffer;
- L1Out Buffer 为 Cube 运算单元的输出数据的存储单元;
2.3 控制单元
控制单元主要有指令缓冲模块、标量处理指令队列、指令发射模块、矩阵运算队列、向量运算队列、储存转换队列等。
3、TBE 开发方式
3.1 TBE 逻辑架构图
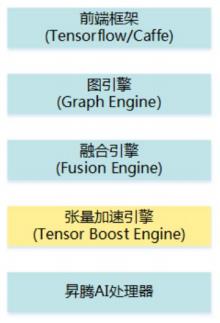
其中:
- 前端框架:包含第三方开源框架 tf、caffe;
- 图引擎(Graph Engine:GE):Graph Engine 是基于昇腾 AI 处理器软件栈对不同的机器学习框架提供统一的 IR 接口,对接上层网络模型框架,如 tf、caffe,GE 的主要功能包括图准备、图拆分、图优化、图编译、图加载、图执行和图管理等;
- 融合引擎(Fusion Engine:FE):FE 负责对接 GE 和 TBE 算子,具备算子信息库的加载与管理、融合规则管理、原图融合和子图优化的能力。GE 在子图优化阶段将子图传递给 FE,FE 根据算子信息库以及 FE 融合优化进行预编译,例如修改数据类型、插入转换算子等,该子图将再次传递给 GE 进行子图合并及子图优化;
- 张量加速引擎(TBE):TBE 通过 IR 定义为 GE 的图推导提供必要的算子信息,通过算子信息库和融合规则为 FE 提供子图优化信息和 TBE 算子调用信息,TBE 生成的算子实现对接昇腾 AI 处理器,最终生成网络在昇腾 AI 处理器上的执行任务。
3.2 TBE 功能框架图
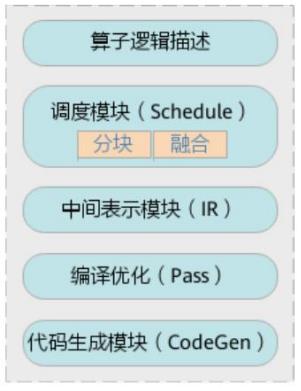
其中:
- DSL 模块:面向开发者,提供算子逻辑编写的接口(Compute 接口),使用接口来编写算子;
- Schedule 模块:用于描述指定 shape 下算子如何在昇腾 AI 处理器上进行切分,包括 Cube 类算子的切分、Vector 类算子的切分,使用提供的调度原语来描述;
- IR 模块:IR 图表示,包括 IR 变形、AST 树的维护等功能;
- 编译优化(Pass):对生成的 IR 进行编译优化,优化的方式有双缓冲(Double Buffer)、流水线(Pipeline)同步、内存分配管理、指令映射、分块适配矩阵计算单元等;
- 代码生成模块(CodeGen):CodeGen 生成类 C 代码的临时文件,这个临时代码文件可以通过编译器生成算子的实现文件,可被网络模型直接加载调用。
3.3 TBE 算子编译执行流程
一个完整的 TBE 算子包含四部分:算子原型定义、对应开源框架的算子适配插件、算子信息库定义和算子实现。
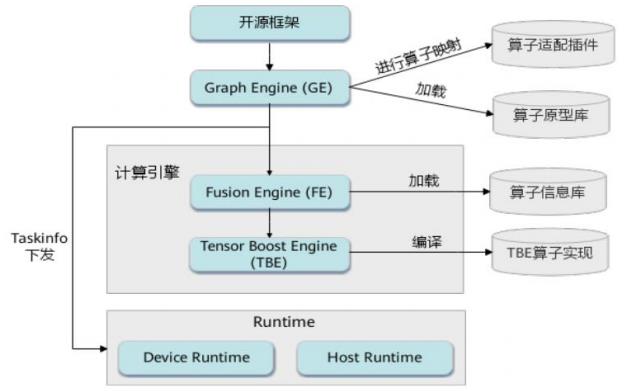
其中,
-
TBE 算子实现:算子实现的 python 文件,包含算子的计算实现及 Schedule 调度实现;
-
算子适配插件:基于第三方框架(tf / caffe)进行自定义算子开发的场景,在完成自定义算子的实现代码后,需要进行适配插件的开发,将基于第三方框架的算子映射成适合昇腾 AI 处理器的算子,将算子信息注册到 GE 中。基于第三方框架的网络运行时,首先会加载并调用算子适配插件信息,将第三方框架网络中的算子进行解析并映射成昇腾 AI 处理器中的算子;
-
算子原型库:算子原型定义规定了在昇腾 AI 处理器上可运行算子的约束,主要体现算子的数学含义,包含定义算子输入、输出、属性和取值范围,基本参数的校验和 shape 的推导。网络运行时,GE 会调用算子原型库的校验接口进行基本参数的校验,校验通过后,会根据原型库中的推导函数推导每个节点的输出 shape 与 dtype,进行输出 tensor 的静态内存的分配;
-
算子信息库:算子信息库主要体现算子在昇腾 AI 处理器上物理实现的限制,包括算子的输入输出 dtype、format 以及输入 shape 信息。网络运行时,FE 会根据算子信息库中的算子信息做基本校验,判断是否需要为算子插入合适的转换节点,并根据算子信息库中信息找到对应的算子实现文件进行编译,生成算子二进制文件进行执行。
主要流程如下:
(1) 将原始第三方网络模型(tf / caffe)下发给 GE;
(2) GE 调用算子插件,将 tf / caffe 网络模型中的算子映射为适配昇腾 AI 处理器的算子,从而将原始 tf / caffe 图解析为适配昇腾 AI 处理器的图;
(3) 调用算子原型库校验接口进行基本参数的校验,校验通过后,会根据原型库中的推导函数推导每个节点的输出 shape 与 dtype,进行输出 tensor 的静态内存的分配;
(4) GE 向 FE 发送图优化请求,并将图下发给 FE,FE 匹配融合规则进行图融合,并根据 fe.ini 中的配置进行算子选择,选择优先级最高的算子类型进行算子匹配(默认自定义算子优先级最高),最后将优化后的整图返回给 GE;
(5) GE 根据图中数据将图拆分为子图并下发给 FE,FE 首先在子图内部插入转换算子,然后按照当前子图流程进行 TBE 算子预编译,对 TBE 算子进行 UB 融合(算子可以在 UB 中根据 UB 融合规则自动与其他算子的计算进行组装),并根据算子信息库中算子信息找到算子实现将其编译成算子 kernel(算子的 .o 与.json),最后将优化后子图返回给 GE;
(6) GE 进行图编译,包含内存分配、流资源分配等,并向 FE 发送 tasking 请求,FE 返回算子的 taskinfo 信息给 GE,图编译完成之后生成适配昇腾 AI 处理器的离线模型文件(*.om);
3.4 TBE 算子开发方式
TBE 的算子开发方式主要有两种:DSL 和 TIK。DSL 借鉴了 TVM 中的 TOPI 机制,预先提供一些常用运算的调度,封装成一个个运算接口,开发时只需要生命计算的流程再使用调度机制,生成指定目标代码即可。而 TIK 一种基于 Python 语言的动态编程框架,程序员直接使用 TIK 提供的 API 完成计算过程及 Schedule 过程,需要手工控制数据搬运的参数和 Schedule,不过无需关注 Buffer 地址的分配及数据同步处理,由 TIK 工具进行管理。
3.4.1 DSL 开发示例
下面展示一个 add 的 DSL 实现例子:
from te import tvm
from te.platform.fusion_manager
import fusion_manager
import te.lang.cce as tbe
from te.utils import para_check
from te.utils import shape_util
from functools import reduce
SHAPE_SIZE_LIMIT = 2147483648
# 实现 Add 算子的计算逻辑
@fusion_manager.register("add")
def add_compute(input_x, input_y, output_z, kernel_name="add"):
shape_x = shape_util.shape_to_list(input_x.shape) # 将 shape 转换为 list
shape_y = shape_util.shape_to_list(input_y.shape) # 将 shape 转换为 list
shape_x, shape_y, shape_max = shape_util.broadcast_shapes(shape_x, shape_y,param_name_input1="input_x",param_name_input="input_y")
shape_size = reduce(lambda x, y: x * y, shape_max[:])
if shape_size > SHAPE_SIZE_LIMIT:
raise RuntimeError("the shape is too large to calculate")
input_x = tbe.broadcast(input_x, shape_max) # 将 input_x 的 shape 广播为 shape_max
input_y = tbe.broadcast(input_y, shape_max) # 将 input_y 的 shape 广播为 shape_max
res = tbe.vadd(input_x, input_y) # 执行 input_x + input_y
return res # 返回计算结果的 tensor
# 算子定义函数
def add(input_x, input_y, output_z, kernel_name="add"):
# 获取算子输入 tensor 的 shape 与 dtype
shape_x = input_x.get("shape")
shape_y = input_y.get("shape")
check_tuple = ("float16", "float32", "int32")
input_data_type = input_x.get("dtype").lower()
if input_data_type not in check_tuple:
raise RuntimeError("only support %s while dtype is %s" % (",".join(check_tuple), input_data_type))
# shape_max 取 shape_x 与 shape_y 的每个维度的最大值
shape_x, shape_y, shape_max = shape_util.broadcast_shapes(shape_x, shape_y,param_name_input1="input_x",param_name_input="input_y")
if shape_x[-1] == 1 and shape_y[-1] == 1 and shape_max[-1] == 1:
# 如果 shape 的长度等于 1,就直接赋值,如果 shape 的长度不等于 1,做切片,将最后一个维度舍弃(按照内存 排布,最后一个维度为 1 与没有最后一个维度的数据排布相同,例如 2*3=2*3*1,将最后一个为 1 的维度舍弃可提升 后续的调度效率)。
shape_x = shape_x if len(shape_x) == 1 else shape_x[:-1]
shape_y = shape_y if len(shape_y) == 1 else shape_y[:-1]
shape_max = shape_max if len(shape_max) == 1 else shape_max[:-1]
# 使用 TVM 的 placeholder 接口对第一个输入 tensor 进行占位,返回一个 tensor 对象
data_x = tvm.placeholder(shape_x, name="data_1", dtype=input_data_type)
# 使用 TVM 的 placeholder 接口对第二个输入 tensor 进行占位,返回一个 tensor 对象
data_y = tvm.placeholder(shape_y, name="data_2", dtype=input_data_type)
# 调用 compute 实现函数
res = add_compute(data_x, data_y, output_z, kernel_name)
# 自动调度
with tvm.target.cce():
schedule = tbe.auto_schedule(res)
# 编译配置
config = {"name": kernel_name, "tensor_list": (data_x, data_y, res)}
tbe.build(schedule, config)
3.4.2 TIK 开发示例
如下实现算子用于实现从 Global Memory 中的 A、B 两处分别读取 128 个 float16 类型的数值搬运到 unified buffer 中相加,并将结果从 unified buffer 写入 Global Memory 地址 C 中。
from te import tik
def simple_add():
tik_instance = tik.Tik()
# 指定 Tensor 对象的所在 buffer 空间。scope_gm 表示 Global Memory 中的数据;
# scope_ubuf 表示 unified buffer 中的数据
data_A = tik_instance_Tensor("float16", (128,), name="data_A", scope=tik.scope_gm)
data_B = tik_instance_Tensor("float16", (128,), name="data_B", scope=tik.scope_gm)
data_C = tik_instance_Tensor("float16", (128,), name="data_C", scope=tik.scope_gm)
data_A_ub = tik_instance_Tensor("float16", (128,), name="data_A_ub", scope=tik.scope_ubuf)
data_B_ub = tik_instance_Tensor("float16", (128,), name="data_B_ub", scope=tik.scope_ubuf)
data_C_ub = tik_instance_Tensor("float16", (128,), name="data_C_ub", scope=tik.scope_ubuf)
# 数据搬运 假设要搬运的数据为 128 个 float16 类型的数据,占 128*2Byte,而一个 unifield buffer 为 256kb,每次
# 搬运大小为 128*2/32Byte。
tik_instance.data_move(data_A_ub, data_A, 0, 1, 128 //16, 0, 0)
tik_instance.data_move(data_B_ub, data_B, 0, 1, 128 //16, 0, 0)
tik_instance.vec_add(128, data_C_ub[0], data_A_ub[0], data_B_ub[0], 1, 8, 8, 8)
tik_instance.data_move(data_C, data_C_ub, 0, 1, 128 //16, 0, 0)
tik_instance.BuildCCE(kernel_name="simple_add",inputs=[data_A,data_B],outputs=[data_C])
TIK 的基本操作单位包括简单四则运算、逻辑运算等,TIK 的 Vector 指令每个 cycle 能处理 256Byte 的数据,并提供 mask 功能调整计算的数据,同时在时间上支持 repeat 操作,完成一连串的数据计算。TIK 指令操作分布在空间和时间两个维度,其中空间上最多处理 256 Byte 数据(包括 128 个 float16 / unint16 / int16、64 个 float32 / unint32 / int32 或 256 个 int8 / uint8 的数据),时间上支持 repeat 操作。1 次 repeat 内部的数据,计算哪些数据,不计算哪些数据,由 mask 参数决定。针对 float16 数据,vetcor 引擎一次计算 128 个 elements,如 mask = 128,表示前 128 个 elements 参与计算。
这里聊了一下昇腾 TBE 开发方式,希望分享的东西对你有一点帮助,有问题欢迎沟通~
好了,收工~
【公众号传送】
扫描下方二维码即可关注我的微信公众号【极智视界】,获取更多AI经验分享,让我们用极致+极客的心态来迎接AI !

以上是关于模型推理聊一聊昇腾 CANN TBE 算子开发方式的主要内容,如果未能解决你的问题,请参考以下文章