华为Ascend昇腾CANN详细教程
Posted 花花少年
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了华为Ascend昇腾CANN详细教程相关的知识,希望对你有一定的参考价值。
一、参考资料
基于昇腾CANN的推理应用开发——图片分类应用(C&C++)
二、重要说明
-
CANN软件提供进程级环境变量设置脚本,供用户在进程中引用,以自动完成环境变量设置。
# 例如 /home/ma-user/Ascend/ascend-toolkit/set_env.sh -
物理机场景下,一个Device上最多只能支持64个用户进程,Host最多只能支持Device个数64个进程;虚拟机场景下,一个Device上最多只能支持32个用户进程,Host最多只能支持Device个数32个进程。不支持使用fork函数创建多个进程,且在进程中调用AscendCL接口的场景,否则进程运行时会报错或者卡死 。
三、相关介绍
3.1 Davinci
达芬奇架构,华为自研的新型芯片架构。
3.2 FE
Fusion Engine融合引擎,负责对接GE和TBE算子,具备算子信息库的加载与管理、融合规则管理等能力。提供图优化,图编译实现接口; 实现算子接入管理;实现算子融合优化。
3.3 GE
Graph Engine,MindSpore计算图执行引擎,主要负责根据前端的计算图完成硬件相关的优化(算子融合、内存复用等等)、device侧任务启动。提供了Graph/Operator IR作为安全易用的构图接口集合,用户可以调用这些接口构建网络模型,设置模型所包含的图、图内的算子、以及模型和算子的属性。
3.4 TBE
Tensor Boost Engine,华为自研的NPU算子开发工具,在TVM( Tensor Virtual Machine )框架基础上扩展,提供了一套Python API来实施开发活动,进行自定义算子开发。
环境变量
# TBE operator implementation tool path
export TBE_IMPL_PATH=/home/ma-user/Ascend/ascend-toolkit/latest/opp/op_impl/built-in/ai_core/tbe
# TBE operator compilation tool path
export PATH=/home/ma-user/Ascend/ascend-toolkit/latest/fwkacllib/ccec_compiler/bin/:$PATH
# Python library that TBE implementation depends on
export PYTHONPATH=$TBE_IMPL_PATH:$PYTHONPATH
3.5 OPP
环境变量
# OPP path
export ASCEND_OPP_PATH=/home/ma-user/Ascend/ascend-toolkit/latest/opp
四、相关介绍
4.1 数据排布格式(format)
关键概念
极智AI | 谈谈为什么卷积加速更喜欢 NHWC Layout
Format为数据的物理排布格式,定义了解读数据的维度,比如1D,2D,3D,4D,5D等。
NCHW和NHWC
在深度学习框架中,多维数据通过多维数组存储,比如卷积神经网络的特征图(Feature Map)通常用四维数组保存,即4D,4D格式解释如下:
- N:Batch数量,例如图像的数目。
- H:Height,特征图高度,即垂直高度方向的像素个数。
- W:Width,特征图宽度,即水平宽度方向的像素个数。
- C:Channels,特征图通道,例如彩色RGB图像的Channels为3。
由于数据只能线性存储,因此这四个维度有对应的顺序。不同深度学习框架会按照不同的顺序存储特征图数据,比如:
- Caffe,排列顺序为[Batch, Channels, Height, Width],即NCHW。
- TensorFlow,排列顺序为[Batch, Height, Width, Channels],即NHWC。

如上图所示,以一张格式为RGB的图片为例,NCHW中,C排列在外层,每个通道内,像素紧挨在一起,实际存储的是“RRRRRRGGGGGGBBBBBB”,即同一通道的所有像素值顺序存储在一起;而NHWC中C排列在最内层,每个通道内,像素间隔挨在一起,实际存储的则是“RGBRGBRGBRGBRGBRGB”,即多个通道的同一位置的像素值顺序存储在一起。
NC1HWC0
昇腾AI处理器中,为了提高通用矩阵乘法(GEMM)运算数据块的访问效率,所有张量数据统一采用NC1HWC0的 五维数据格式,如下图所示:
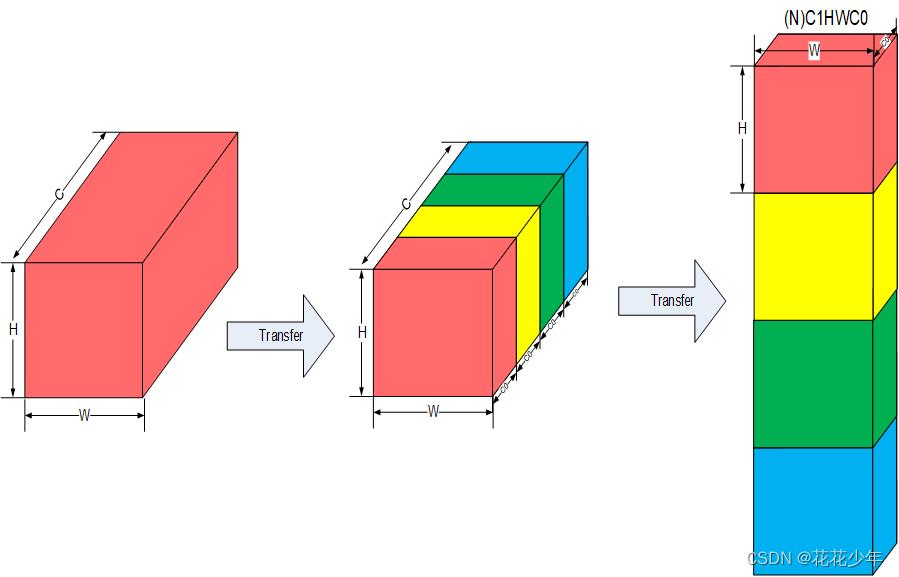
其中C0与微架构强相关,等于AI Core中矩阵计算单元的大小,对于FP16类型为16,对于INT8类型则为32,这部分数据需要连续存储;C1是将C维度按照C0进行拆分后的数目,即C1=C/C0。如果结果不整除,最后一份数据需要补零以对齐C0。
NHWC -> NC1HWC0的转换过程
- 将NHWC数据在C维度进行分割,变成C1份NHWC0。
- 将C1份NHWC0在内存中连续排列,由此变成NC1HWC0。
NHWC->NC1HWC0的转换场景示例
- 首层RGB图像通过AIPP转换为NC1HWC0格式。
- 中间层Feature Map每层输出为NC1HWC0格式,在搬运过程中需要重排。
4.2 Context/Stream/Even
昇腾CANN系列教程-AscendCL特性之运行资源管理(C++)
资源申请与释放
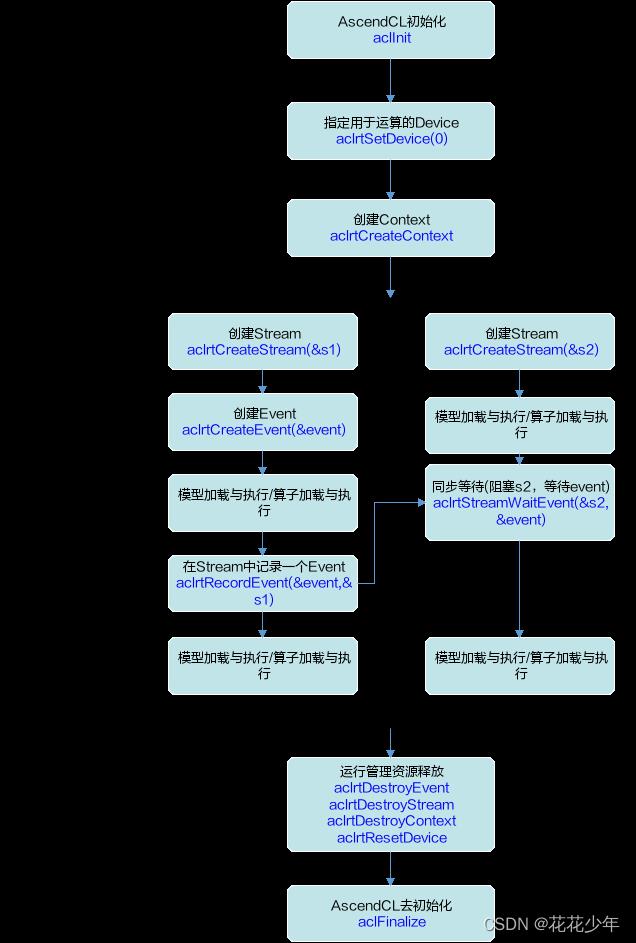
资源申请顺序:SetDevice->CreateContext->CreateStream->CreateEvent;
资源释放顺序:DestroyEvent->DestroyStream->DestroyContext->ResetDevice;
同步与异步
同步、异步是站在调用者和执行者的角度,在当前场景下,若在Host调用接口后不等待Device执行完成再返回,则表示Host的调度是异步的;若在Host调用接口后需等待Device执行完成再返回,则表示Host的调度是同步的。
Context
Context作为一个容器,管理了所有对象(包括Stream、Event、设备内存等)的生命周期。不同Context的Stream、不同Context的Event是完全隔离的,无法建立同步等待关系。多线程编程场景下,每切换一个线程,都要为该线程指定当前Context,否则无法获取任何其他运行资源。
Context分为两种
- 默认Context:调用aclrtSetDevice接口指定用于运算的Device时,系统会自动隐式创建一个默认Context,一个Device对应一个默认Context,默认Context不能通过aclrtDestroyContext接口来释放。
- (推荐)显式创建的Context:在进程或线程中调用aclrtCreateContext接口显式创建一个Context。
Context接口调用流程
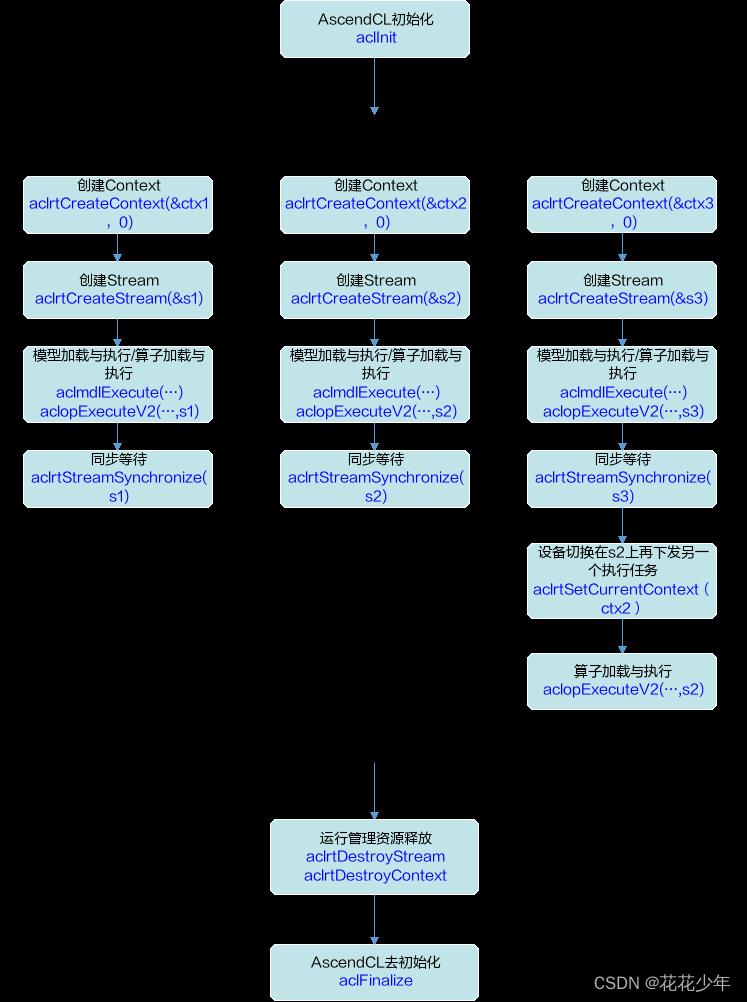
Stream(异步操作)
与 NVIDIA GPU的Stream类似,可参考资料:CUDA随笔之Stream的使用
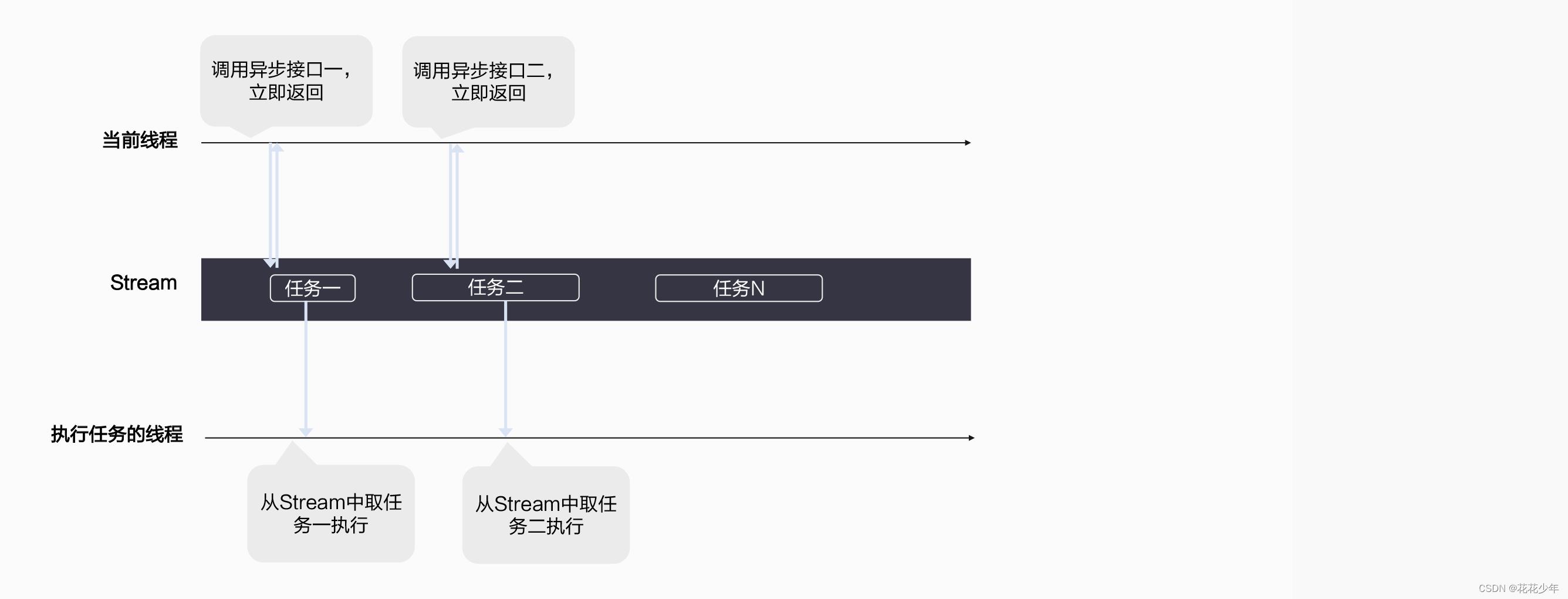
Stream用于维护一些异步操作的执行顺序,确保按照应用程序中的代码调用顺序在Device上执行。可以将Stream简单理解为一个异步任务的队列,主线程在调用异步接口时,指定了某个stream,本质上就是把异步任务送进了这个任务队列中。队列中任务的执行是保序的,即运行时环境会根据任务下发的顺序来依次执行,不会出现乱序执行的情况。在AscendCL的后台,运行时环境会自动从stream中依次取出一个个任务来执行。kernel执行和数据传输都显示或者隐式地运行在Stream中。
异步且基于stream的kernel执行和数据传输能够实现以下几种类型的并行:
- Host运算操作和device运算操作并行;
- Host运算操作和host到device的数据传输并行;
- Host到device的数据传输和device运算操作并行;
- Device内的运算并行;
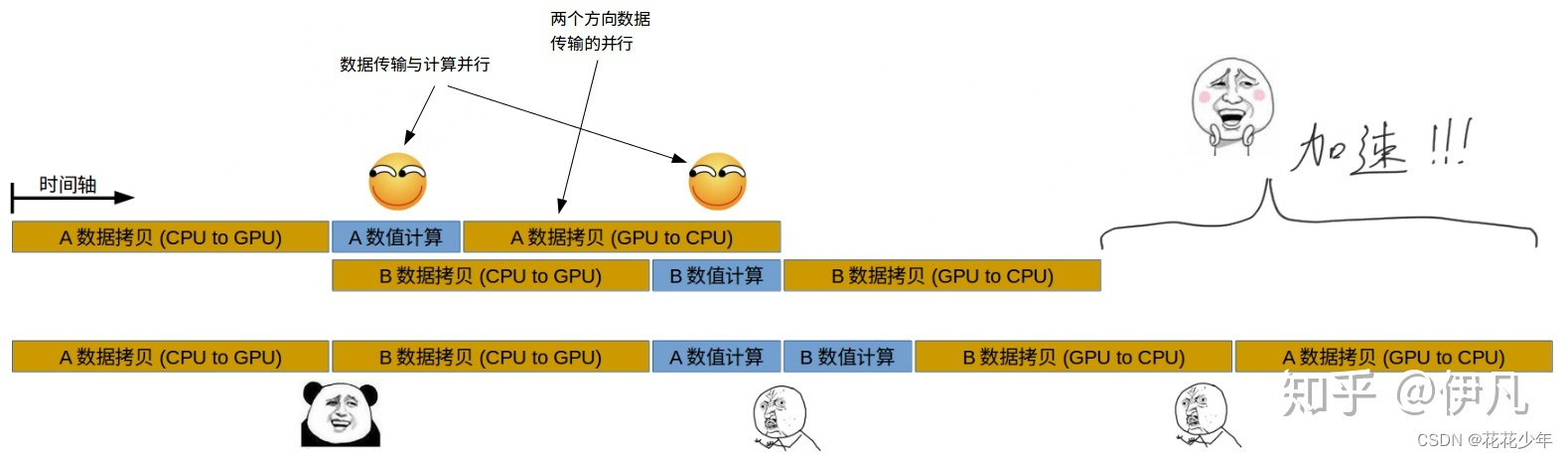
说明:基于Stream的kernel执行和数据传输,能够实现Host运算操作、Host与Device间的数据传输、Device内的运算并行。在许多情况下,花费在执行kernel上的时间要比传输数据多得多,所以很容易想到将Host与Devide之间的交互时间隐藏在其他kernel执行过程中,我们可以将数据传输和kernel执行放在不同的stream中来实现此功能。
Stream分两种:
- 默认Stream:调用aclrtSetDevice接口指定用于运算的Device时,系统会自动隐式创建一个默认Stream,一个Device对应一个默认Stream,默认Stream不能通过aclrtDestroyStream接口来释放。
- 显式创建的Stream:**推荐,**在进程或线程中调用aclrtCreateStream接口显式创建一个Stream。
Stream加速
Event(同步操作)
问题引入

上图中“Stream1->任务4”的执行依赖“Stream2->任务6”执行完毕,而如果还按照之前的方式,任务4执行前等待整个Stream2全部执行完毕,其实是多等了“任务7”、“任务8”的执行时间的。为了对Stream间任务依赖进行精细化管理,我们需要一个新的运行资源:Event。
Event通常用于在Stream之间执行事件同步操作,在两个Stream之间存在任务级别的依赖时尤其有用,如下图所示:
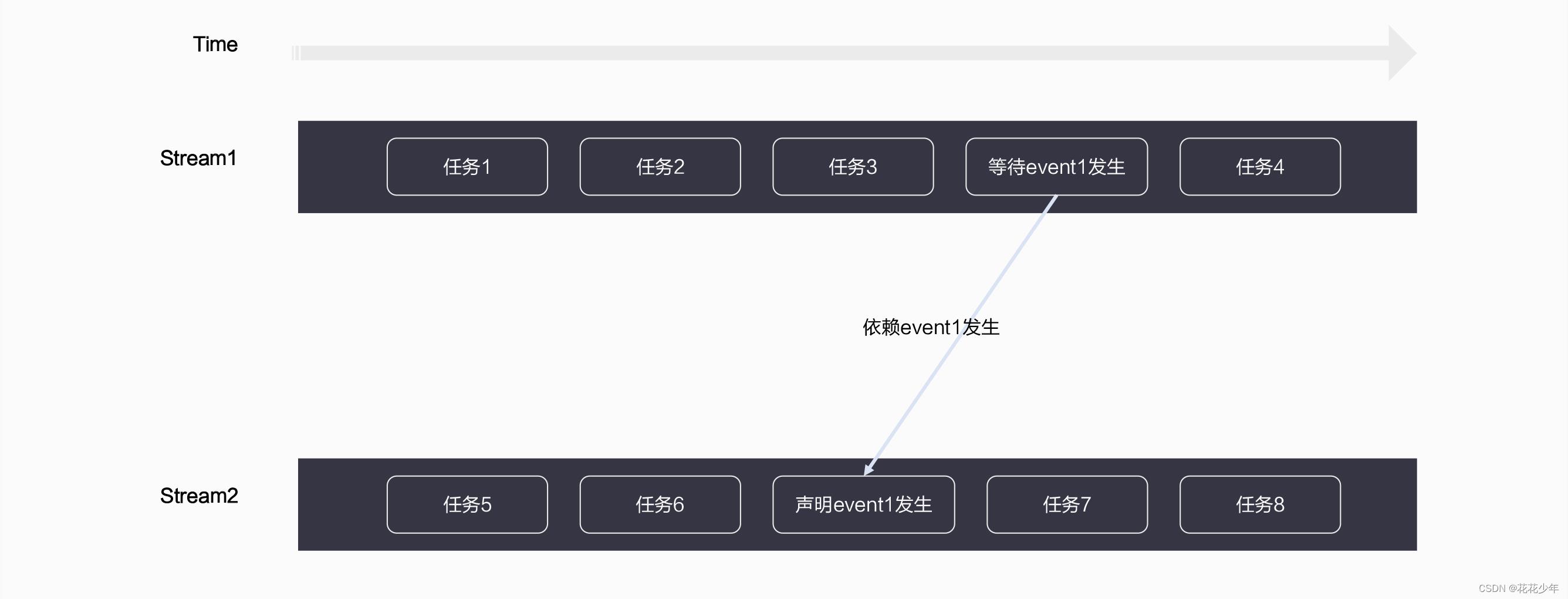
“Stream1->任务4”的确是依赖“Stream2->任务6”的完成,但这两个任务之间是无法直接产生依赖关系的,要使用Event机制来同步:
- Stream2->任务6:在执行完毕后,声明“event1”这一事件已发生;
- Stream1->任务4:在执行之前,等待“event1”这一事件的发生;
两个无法产生直接依赖关系的任务,通过Event实现了依赖机制。
// 在stream上声明event已经发生
aclError aclrtRecordEvent(aclrtEvent event, aclrtStream stream);
// 让stream等待event的发生
aclError aclrtStreamWaitEvent(aclrtStream stream, aclrtEvent event);
相关概念
支持调用AscendCL接口同步Stream之间的任务,包括同步Host与Device之间的任务、Device与Device间的任务。
Events标记了stream执行过程中的一个点,我们就可以检查正在执行的stream中的操作是否到达该点,我们可以把event当成一个操作插入到stream中的众多操作中,当执行到该操作时,所做工作就是设置CPU的一个flag来标记表示完成。
例如,若stream2的任务依赖stream1的任务,想保证stream1中的任务先完成,这时可创建一个Event,并将Event插入到stream1,在执行stream2的任务前,先同步等待Event完成。
Device、Context、Stream之间的关系
-
默认Context、默认Stream一般适用于简单应用,用户仅仅需要一个Device的计算场景下。多线程应用程序建议全部使用显式创建的Context和Stream。
-
线程中创建的多个Context,线程缺省使用最后一次创建的Context。
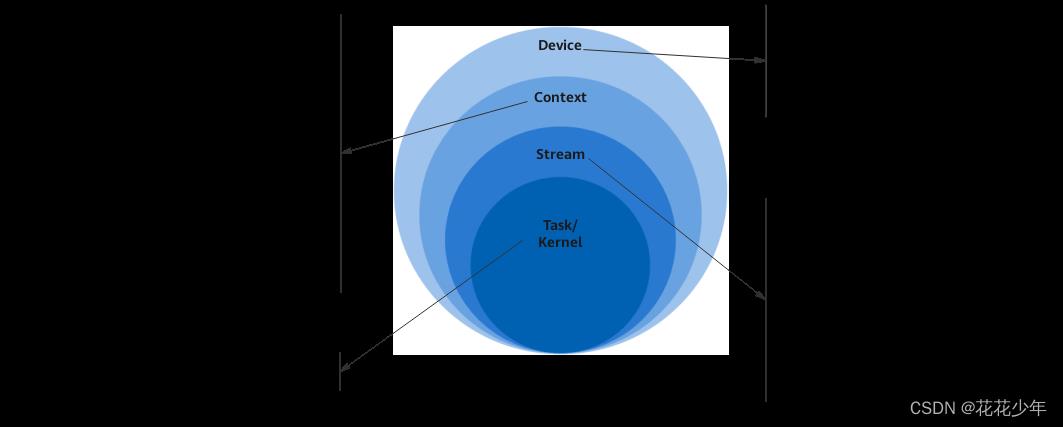
线程、Context、Stream之间的关系
-
一个用户线程一定会绑定一个Context,所有Device的资源使用或调度,都必须基于Context。
-
一个进程中可以创建多个Context,但一个线程同一时刻只能使用一个Contex,Context中已经关联了本线程要使用的Device。
-
一个线程中可以创建多个Stream,不同的Stream上计算任务是可以并行执行;多线程场景下,也可以每个线程分别创建一个Stream,且线程之间的Stream在Device上相互独立,每个Stream内部的任务是按照Stream下发的顺序执行。
-
多线程的调度依赖于运行应用的 操作系统调度 \\textcolorRed操作系统调度 操作系统调度,多Stream在Device侧的调度,由Device的 调度组件 \\textcolorRed调度组件 调度组件 进行调度。
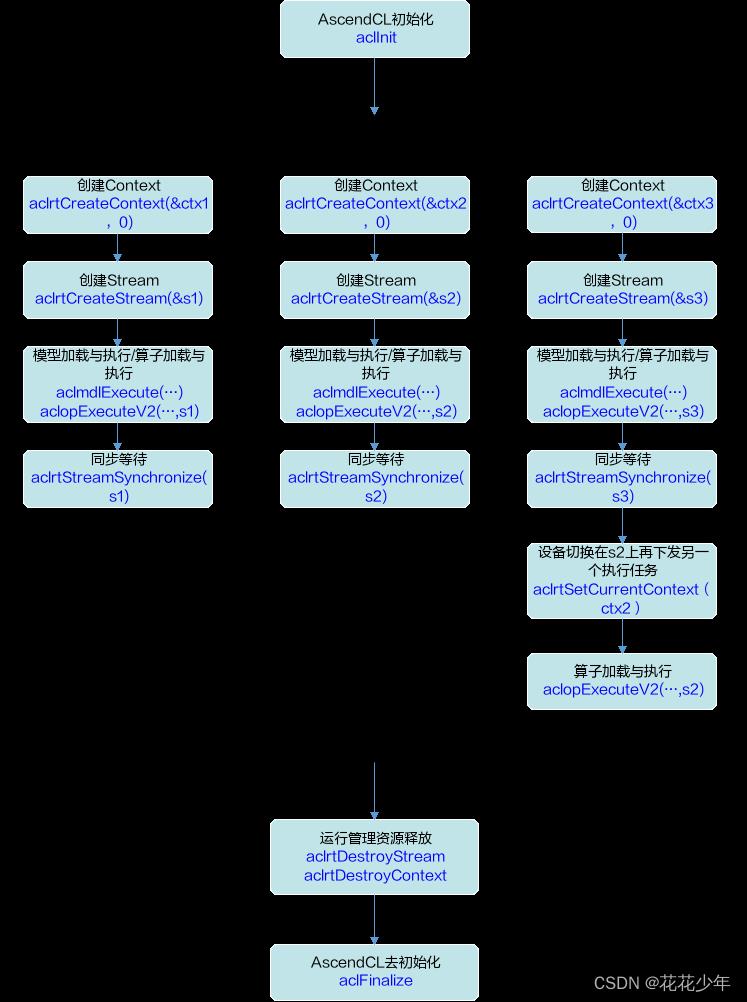
多线程、多stream的性能说明
- 线程调度依赖运行的操作系统,Stream上下发了任务后,Stream的调度由Device的调度单元调度,但如果一个进程内的多Stream上的任务在Device存在资源争抢的时候,性能可能会比单Stream低。
- 当前昇腾AI处理器有不同的执行部件,如AI Core、AI CPU、Vector Core等,对应使用不同执行部件的任务,建议多Stream的创建按照算子执行引擎划分。
- 单线程多Stream与多线程多Stream(一个进程中可以包含多个线程,每个线程中一个Stream)性能上哪个更优,具体取决于应用本身的逻辑实现,一般来说单线程多Stream性能略好,原因是应用层少了线程调度开销。
- 从同步场景,到Stream场景,再到Callback场景,我们见证了主线程一步一步被释放。在同步场景,所有场景都在主线程完成;在Stream场景,推理送到了Stream来做,而后处理还要主线程完成;而在Callback场景下,推理和后处理就都放到Stream中了。
4.3 内存管理
昇腾CANN系列教程-AscendCL特性之内存管理(C++)
如果进程运行在Host上,就申请Host内存,如果是运行在Device上,申请的就是Device内存。
Host-Device
aclrtMallocHost->aclrtMalloc->aclrtMemcpy(host-device)
模型输入与输出
模型输入
一个模型有且只有1个“输入DataSet”(数据集对象),里边包含所有的输入;而如果有多个输入的话,每个输入用一个“DataBuffer”来承载。
- 一个模型的所有输入抽象为一个“DataSet”对象;
- 每一个输入抽象为一个“DataBuffer”对象;

如上图所示,一个模型有2个输入,其中第一个输入是若干张图片,第二个输入是每张图片的元数据等信息,那么在编程中我们需要这样做:
- 用第一个输入,所有图片,创建一个DataBuffer对象;
- 用第二个输入,图片的信息,创建另一个DataBuffer对象;
- 创建一个DataSet对象;
- 把第1/2步中创建的2个DataBuffer对象放到DataSet对象中;
核心代码
// 创建DataBuffer
aclDataBuffer *aclCreateDataBuffer(void *data, size_t size);
// 创建DataSet
aclmdlDataset *aclmdlCreateDataset();
// 向DataSet中添加DataBuffer
aclError aclmdlAddDatasetBuffer(aclmdlDataset *dataset, aclDataBuffer *dataBuffer);
模型输出
模型输出数据结构,也是一个DataSet,1-N个DataBuffer,但是问题来了,我还没推理,没有数据呢,怎么会有DataBuffer? 其实在模型确定下来之后,基本上输出的个数和占用内存大小就已经完全确定了。比如一个有1000个类别的分类网络的输出,结果就是1000组数据,每组包含一个标签和一个置信度,共2000个数值。那么这个输出所占用的内存大小就很容易计算出来,并在推理之前先申请好内存。没错,AscendCL不支持推理过程中自动申请输出内存,一定要在调用推理接口之前先把输出内存、DataBuffer、DataSet准备好。
核心代码
// 创建一个“模型描述信息”对象,用于收集模型的描述信息,也就是模型的元数据
aclError aclmdlGetDesc(aclmdlDesc *modelDesc, uint32_t modelId);
// 获取模型描述信息
// 可以根据模型的modelId来获取模型描述信息,并将描述信息填充进modelDesc对象中
aclError aclmdlGetDesc(aclmdlDesc *modelDesc, uint32_t modelId);
4.4 npu-smi 命令
NPU信息
npu-smi info
4.5 设置环境变量
如果昇腾AI处理器配套软件包没有安装在默认路径,安装好MindSpore之后,需要导出Runtime相关环境变量,下述命令中LOCAL_ASCEND=/usr/local/Ascend的/usr/local/Ascend表示配套软件包的安装路径,需注意将其改为配套软件包的实际安装路径。
# 安装nnae包时配置
. /usr/local/Ascend/nnae/set_env.sh
# 安装tfplugin包时配置
. /usr/local/Ascend/tfplugin/set_env.sh
# 安装toolbox包时配置
. /usr/local/Ascend/toolbox/set_env.sh
# control log level. 0-DEBUG, 1-INFO, 2-WARNING, 3-ERROR, 4-CRITICAL, default level is WARNING.
export GLOG_v=2
# Conda environmental options
export LOCAL_ASCEND=/usr/local/Ascend # the root directory of run package
# lib libraries that the run package depends on
export LD_LIBRARY_PATH=$LOCAL_ASCEND/ascend-toolkit/latest/fwkacllib/lib64:$LOCAL_ASCEND/driver/lib64:$LOCAL_ASCEND/ascend-toolkit/latest/opp/op_impl/built-in/ai_core/tbe/op_tiling:$LD_LIBRARY_PATH
/usr/local/Ascend/driver/lib64/driver
# Environment variables that must be configured
## TBE operator implementation tool path
export TBE_IMPL_PATH=$LOCAL_ASCEND/ascend-toolkit/latest/opp/op_impl/built-in/ai_core/tbe
## OPP path
export ASCEND_OPP_PATH=$LOCAL_ASCEND/ascend-toolkit/latest/opp
## AICPU path
export ASCEND_AICPU_PATH=$ASCEND_OPP_PATH/..
## TBE operator compilation tool path
export PATH=$LOCAL_ASCEND/ascend-toolkit/latest/fwkacllib/ccec_compiler/bin/:$PATH
## Python library that TBE implementation depends on
export PYTHONPATH=$TBE_IMPL_PATH:$PYTHONPATH
4.6 CANN信息
# CANN版本信息
cat /usr/local/Ascend/version.info
输出:
version=21.0.3.1
# CANN安装路径
/usr/local/Ascend
4.7 ascend-toolkit信息
# ascend-toolkit版本信息
/usr/local/Ascend/ascend-toolkit/latest/arm64-linux/toolkit/version.info
输出:
Version=1.75.22.0.220
# ascend-toolkit安装信息
cat /usr/local/Ascend/ascend-toolkit/latest/arm64-linux/ascend_toolkit_install.info
输出:
version=20.1.rc1
arch=arm64
os=linux
path=/usr/local/Ascend/ascend-toolkit/latest/arm64-linux
4.8 ascend_nnae信息
cat /usr/local/Ascend/nnae/latest/ascend_nnae_install.info
输出:
package_name=Ascend-cann-nnae
version=5.0.3
innerversion=V100R001C79B220SPC1011
arch=aarch64
os=linux
path=/usr/local/Ascend/nnae/5.0.3
4.9 ascend_nnrt信息
# nnrt安装信息
cat /usr/local/Ascend/nnrt/latest/ascend_nnrt_install.info
输出:
version=20.0.RC1
arch=arm64
os=linux
gcc=gcc7.3.0
path=/usr/local/Ascend/nnrt/latest
fwkacllib信息
/usr/local/Ascend/nnae/5.0.3/fwkacllib/lib64
auto_tune-0.1.0-py3-none-any.whl libauto_tiling.so libge_executor.so libregister.a
hccl-0.1.0-py3-none-any.whl lib_caffe_parser.so libge_runner.so libregister.so
hccl_reduce_op_ascend710.o libcce_aicore.so libgraph.so libresource.so
hccl_reduce_op_ascend910.o libcce_aicpudev_online.so libhccl.so librs.so
libacl_cblas.so libcce.so libhcom_graph_adaptor.so libruntime.so
libacl_dvpp_mpi.so libcce_tools.so libindextransform.so libte_fusion.so
libacl_dvpp.so libcompress.so libmmpa.a libtiling.so
libacl_op_compiler.so libcompressweight.so libmmpa.so libtsdclient.so
libacl_retr.so libc_sec.so libmsprofiler.so libtvm_runtime.so
libacl_tdt_channel.so libdatatransfer.so libopskernel.so libtvm.so
libaicore_utils.so liberror_manager.a libopt_feature.so libtvm_topi.so
libaicpu_engine_common.so liberror_manager.so libparser_common.so plugin
libalog.so libfmk_onnx_parser.so libplatform.so schedule_search-0.1.0-py3-none-any.whl
libascendcl.a libfmk_parser.so libra_hdc.so stub
libascendcl.so libge_common.so libra_peer.so te-0.4.0-py3-none-any.whl
libascend_protobuf.so.3.13.0.0 libge_compiler.so libra.so topi-0.4.0-py3-none-any.whl
4.10 安装昇腾AI处理器配套软件包
昇腾软件包提供商用版和社区版两种下载途径:
- 商用版下载需要申请权限,下载链接与安装方式请参考Ascend Data Center Solution 22.0.RC1安装指引文档。
- 社区版下载不受限制,下载链接请前往CANN社区版,选择
5.1.RC1.alpha005版本,以及在固件与驱动链接中获取对应的固件和驱动安装包,安装包的选择与安装方式请参照上述的 商用版 安装指引文档。
表1-1 昇腾软件介绍
| 软件类型 | 软件介绍 |
|---|---|
| 固件 | 固件包含昇腾AI处理器自带的OS 、电源器件和功耗管理器件控制软件,分别用于后续加载到AI处理器的模型计算、芯片启动控制和功耗控制。 |
| 驱动 | 部署在昇腾服务器,功能类似英伟达驱动,管理查询昇腾AI处理器,同时为上层CANN软件提供芯片控制、资源分配等接口。 |
| CANN | 部署在昇腾服务器,功能类似英伟达CUDA,包含Runtime、算子库、图引擎、媒体数据处理等组件,通过AscendCL(Ascend Computing Language)对外提供Device管理、Context管理、Stream管理、内存管理、模型加载与执行、算子加载与执行、媒体数据处理等API,帮助开发者实现在昇腾CANN平台上进行深度学习推理计算、图像预处理、单算子加速计算。 |
重要说明:如果是首次安装请按照“驱动 > 固件”的顺序,分别安装驱动和固件包;覆盖安装请按照“固件 > 驱动”的顺序,分别安装固件和驱动包,**vision**表示软件版本号。
五、Ascend-toolkit 开发套件包
Ascend-toolkit 开发套件包。
Ascend-toolkit安装
(ms19) root@80f9a288c6ba:/data/YOYOFile/Downloads# ./Ascend-cann-toolkit_6.0.0.alpha003_linux-aarch64.run --install
Verifying archive integrity... 100% SHA256 checksums are OK. All good.
Uncompressing ASCEND_RUN_PACKAGE 100%
[Toolkit] [20221229-09:15:54] [INFO] LogFile:/var/log/ascend_seclog/ascend_toolkit_install.log
[Toolkit] [20221229-09:15:54] [INFO] install start
[Toolkit] [20221229-09:15:54] [INFO] The installation path is /usr/local/Ascend.
[Toolkit] [20221229-09:15:54] [WARNING] driver package maybe not installed
[Toolkit] [20221229-09:15:54] [WARNING] driver package maybe not installed
[Toolkit] [20221229-09:15:54] [INFO] install package CANN-runtime-6.0.0.alpha003-linux_aarch64.run start
[Toolkit] [20221229-09:16:03] [INFO] CANN-runtime-6.0.0.alpha003-linux_aarch64.run --devel --quiet --nox11 install success
[Toolkit] [20221229-09:16:03] [INFO] install package CANN-compiler-6.0.0.alpha003-linux_aarch64.run start
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv
[Toolkit] [20221229-09:16:54] [INFO] CANN-compiler-6.0.0.alpha003-linux_aarch64.run --devel --pylocal --quiet --nox11 install success
[Toolkit] [20221229-09:16:54] [INFO] install package CANN-opp-6.0.0.alpha003-linux_aarch64.run start
/root/selfgz5969520074/opp/script/opp_install.sh: 686: /root/selfgz5969520074/opp/script/opp_install.sh: __reverse_list: not found
/root/selfgz5969520074/opp/script/opp_install.sh: 686: /root/selfgz5969520074/opp/script/opp_install.sh: __reverse_list: not found
[Toolkit] [20221229-09:17:39] [INFO] CANN-opp-6.0.0.alpha003-linux_aarch64.run --devel --quiet --nox11 install success
[Toolkit] [20221229-09:17:39] [INFO] install package CANN-toolkit-6.0.0.alpha003-linux_aarch64.run start
[Toolkit] [20221229-09:18:29] [INFO] CANN-toolkit-6.0.0.alpha003-linux_aarch64.run --devel --pylocal --quiet --nox11 install success
[Toolkit] [20221229-09:18:29] [INFO] install package CANN-aoe-6.0.0.alpha003-linux_aarch64.run start
[Toolkit] [20221229-09:18:38] [INFO] CANN-aoe-6.0.0.alpha003-linux_aarch64.run --devel --quiet --nox11 install success
[Toolkit] [20221229-09:18:38] [INFO] install package Ascend-mindstudio-toolkit_6.0.0.alpha003_linux-aarch64.run start
[Toolkit] [20221229-09:18:51] [INFO] Ascend-mindstudio-toolkit_6.0.0.alpha003_linux-aarch64.run --devel --quiet --nox11 install success
[Toolkit] [20221229-09:18:51] [INFO] install package Ascend-test-ops_6.0.0.alpha003_linux.run start
[Toolkit] [20221229-09:18:51] [INFO] Ascend-test-ops_6.0.0.alpha003_linux.run --devel --quiet --nox11 install success
[Toolkit] [20221229-09:18:51] [INFO] install package Ascend-pyACL_6.0.0.alpha003_linux-aarch64.run start
[Toolkit] [20221229-09:18:52] [INFO] Ascend-pyACL_6.0.0.alpha003_linux-aarch64.run --devel --quiet --nox11 install success
[Toolkit] [20221229-09:18:52] [INFO] Please make sure that:
PATH includes :
/usr/local/Ascend/ascend-toolkit/latest/bin:
/usr/local/Ascend/ascend-toolkit/latest/compiler/ccec_compiler/bin:
LD_LIBRARY_PATH includes :
/usr/local/Ascend/ascend-toolkit/latest/lib64:
/usr/local/Ascend/ascend-toolkit/latest/lib64/plugin/opskernel:
/usr/local/Ascend/ascend-toolkit/latest/lib64/plugin/nnengine:
PYTHONPATH includes :
/usr/local/Ascend/ascend-toolkit/latest/python/site-packages:
/usr/local/Ascend/ascend-toolkit/latest/opp/built-in/op_impl/ai_core/tbe:
ASCEND_AICPU_PATH includes :
/usr/local/Ascend/ascend-toolkit/latest:
ASCEND_OPP_PATH includes :
/usr/local/Ascend/ascend-toolkit/latest/opp:
TOOLCHAIN_HOME includes :
/usr/local/Ascend/ascend-toolkit/latest/toolkit:
ASCEND_HOME_PATH includes :
/usr/local/Ascend/ascend-toolkit/latest:
[Toolkit] [20221229-09:18:52] [INFO] If your service is started using the shell script, you can call the /usr/local/Ascend/ascend-toolkit/set_env.sh script to configure environment variables. Note that this script can not be executed mannually.
[Toolkit] [20221229-09:18:52] [INFO] Ascend-cann-toolkit_6.0.0.alpha003_linux-aarch64 install success. The installation path is /usr/local/Ascend.
1. 环境变量
# 以安装用户在开发环境任意目录下执行以下命令,打开.bashrc文件。
vi ~/.bashrc
# 在文件最后一行后面添加如下内容。CPU_ARCH环境变量请根据运行环境cpu架构填写,如export CPU_ARCH=aarch64
export CPU_ARCH=[aarch64/x86_64]
# THIRDPART_PATH需要按照运行环境安装路径设置,如运行环境为arm,指定安装路径为Ascend-arm,则需要设置为export THIRDPART_PATH=$HOME/Ascend-arm/thirdpart/$CPU_ARCH
export THIRDPART_PATH=$HOME/Ascend/thirdpart/$CPU_ARCH #代码编译时链接第三方库
# CANN软件安装后文件存储路径,最后一级目录请根据运行环境设置,运行环境为arm,这里填arm64-linux;运行环境为x86,则这里填x86_64-linux,以下以arm环境为例
export INSTALL_DIR=$HOME/Ascend/ascend-toolkit/latest/arm64-linux
# 执行命令保存文件并退出。
:wq!
# 执行命令使其立即生效。
source ~/.bashrc
# 创建第三方依赖文件夹
mkdir -p $THIRDPART_PATH
# 拷贝公共文件到第三方依赖文件夹
cd $HOME
git clone https://gitee.com/ascend/samples.git
cp -r $HOME/samples/common $THIRDPART_PATH
2. 常用指令
# AscendCL头文件路径
/home/ma-user/Ascend/ascend-toolkit/latest/include/acl
# AscendCL库文件路径
/home/ma-user/Ascend/ascend-toolkit/latest/lib64
# 查看device设备
ls /dev/davinci*
# 驱动安装路径
/usr/local/Ascend/driver/
# 查看 Ascend-cann-toolkit 版本
cd /home/ma-user/Ascend/ascend-toolkit/latest/arm64-linux
cat ascend_toolkit_install.info
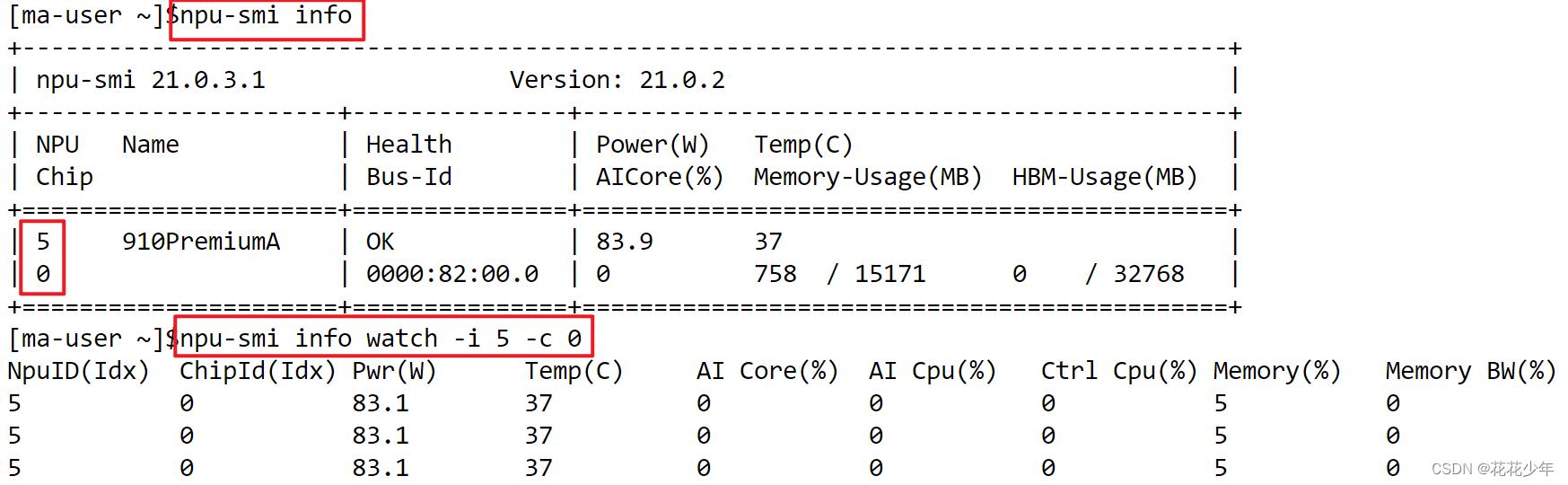
查看NPU资源
# 查看npu资源
npu-smi info
watch -n 1 npu-smi info
npu-smi info watch -i 0 -c 0
查看 Ascend-cann-toolkit 版本
cd /home/ma-user/Ascend/ascend-toolkit/latest/arm64-linux
cat ascend_toolkit_install.info
[ma-user@notebook-87136e07-6a9a-4138-beec-742972f7b62f arm64-linux]$ cat ascend_toolkit_install.info
package_name=Ascend-cann-toolkit
version=5.0.3
innerversion=V100R001C79B220SPC1011
arch=aarch64
os=linux
path=/home/ma-user/Ascend/ascend-toolkit/5.0.3/arm64-linux
3. 设置环境变量
设置 INC_PATH、LIB_PATH路径
| 说明 | 路径 | 变量1 | 变量2 | 变量3 |
|---|---|---|---|---|
| Ascend安装路径 | $HOME/Ascend/ascend-toolkit/latest | INSTALL_DIR | DDK_PATH | INC_PATH |
| Ascend库文件路径 | $INSTALL_DIR/acllib/lib64/stub | NPU_HOST_LIB | LIB_PATH |
设置INC_PATH、LIB_PATH路径有三种方式:
-
临时性设置
$INSTALL_DIR表示CANN软件安装目录,例如,$HOME/Ascend/ascend-toolkit/latest/arch-os,arch表示操作系统架构(需根据运行环境的架构选择),os表示操作系统(需根据运行环境的操作系统选择)。旧版本(默认)
export INSTALL_DIR=$HOME/Ascend/ascend-toolkit/latest export DDK_PATH=$INSTALL_DIR export NPU_HOST_LIB=$INSTALL_DIR/acllib/lib64/stub新版本(未来)
export INSTALL_DIR=$HOME/Ascend/ascend-toolkit/latest export DDK_PATH=$INSTALL_DIR export NPU_HOST_LIB=$INSTALL_DIR/arch-os/devlib -
永久性设置
vi ~/.bashrc # 末尾添加环境变量 export DDK_PATH=$INSTALL_DIR export NPU_HOST_LIB=$INSTALL_DIR/acllib/lib64/stub # 更新环境变量 source ~/.bashrc -
在CMakeLists.txt文件中修改路径
DDK_PATH也即INC_PATH,表示AscendCL头文件路径;NPU_HOST_LIB也即LIB_PATH,表示AscendCL库文件路径。
CMakeLists.txt文件中会指定 INC_PATH和LIB_PATH,根据真实路径修改。CMakeLists.txt
# CMake lowest version requirement cmake_minimum_required(VERSION 3.5.1) # project information project(AME) # Compile options add_compile_options(-std=c++11) add_definitions(-DENABLE_DVPP_INTERFACE) # Specify target generation path set(CMAKE_RUNTIME_OUTPUT_DIRECTORY "../../../out") set(CMAKE_CXX_FLAGS_DEBUG "-fPIC -O0 -g -Wall") set(CMAKE_CXX_FLAGS_RELEASE "-fPIC -O2 -Wall") # 设置环境变量,DDK_PATH即为INC_PATH set(INC_PATH $ENVDDK_PATH) if (NOT DEFINED ENVDDK_PATH) # set(INC_PATH "/usr/local/Ascend") set(INC_PATH "/home/ma-user/Ascend/ascend-toolkit/latest/arm64-linux") message(STATUS "set default INC_PATH: $INC_PATH") else () message(STATUS "env INC_PATH: $INC_PATH") endif() # 设置环境变量,NPU_HOST_LIB即为LIB_PATH set(LIB_PATH $ENVNPU_HOST_LIB) if (NOT DEFINED ENVNPU_HOST_LIB) # set(LIB_PATH "/usr/local/Ascend/acllib/lib64/stub/") set(LIB_PATH "/home/ma-user/Ascend/ascend-toolkit/latest/arm64-linux/acllib/lib64/stub/") message(STATUS "set default LIB_PATH: $LIB_PATH") else () message(STATUS "env LIB_PATH: $LIB_PATH") endif() # Header path include_directories( $INC_PATH/acllib/include/ ../inc/ ) # add host lib path link_directories( $LIB_PATH ) add_executable(main utils.cpp # dvpp_process.cpp model_process.cpp # singleOp_process.cpp sample_process.cpp main.cpp) target_link_libraries(main ascendcl acl_cblas acl_dvpp stdc++) install(TARGETS main DESTINATION $CMAKE_RUNTIME_OUTPUT_DIRECTORY)
示例:
set(INC_PATH "/usr/local/Ascend")
set(LIB_PATH "/usr/local/Ascend/acllib/lib64/stub/")
修改为
set(INC_PATH "/home/ma-user/Ascend/ascend-toolkit/latest/arm64-linux")
set(LIB_PATH "/home/ma-user/Ascend/ascend-toolkit/latest/arm64-linux/acllib/lib64/stub/")
配置 ascend-toolkit 环境变量
如果不设置环境变量,很多工具无法使用,例如:ATC模型转换工具。
# 设置环境变量
cd /home/ma-user/Ascend/ascend-toolkit
source set_env.sh
set_env.sh
export LD_LIBRARY_PATH=/home/ma-user/Ascend/ascend-toolkit/latest/lib64:/home/ma-user/Ascend/ascend-toolkit/latest/compiler/lib64/plugin/opskernel:/home/ma-user/Ascend/ascend-toolkit/latest/compiler/lib64/plugin/nnengine:$LD_LIBRARY_PATH
export PYTHONPATH=/home/ma-user/Ascend/ascend-toolkit/latest/python/site-packages:/home/ma-user/Ascend/ascend-toolkit/latest/opp/op_impl/built-in/ai_core/tbe:$PYTHONPATH
export PATH=/home/ma-user/Ascend/ascend-toolkit/latest/bin:/home/ma-user/Ascend/ascend-toolkit/latest/compiler/ccec_compiler/bin:$PATH
export ASCEND_AICPU_PATH=/home/ma-user/Ascend/ascend-toolkit/latest
export ASCEND_OPP_PATH=/home/ma-user/Ascend/ascend-toolkit/latest/opp
export TOOLCHAIN_HOME=/home/ma-user/Ascend/ascend-toolkit/latest/toolkit
export ASCEND_AUTOML_PATH=/home/ma-user/Ascend/ascend-toolkit/latest/tools
配置 atc 环境变量
# 设置环境变量
cd /home/ma-user/Ascend/ascend-toolkit
source set_env.sh
配置 tfplugin 环境变量
/home/ma-user/Ascend/tfplugin/set_env.sh
set_env.sh
export PYTHONPATH=/home/ma-user/Ascend/tfplugin/latest开发实践丨昇腾CANN的推理应用开发体验
摘要:这是关于一次 Ascend 在线实验的记录,主要内容是通过网络模型加载、推理、结果输出的部署全流程展示,从而快速熟悉并掌握 ACL(Ascend Computing Language)基本开发流程。
本文分享自华为云社区《基于昇腾CANN的推理应用开发快速体验(Python)》,作者: Tianyi_Li 。
前情提要
这是关于一次 Ascend 在线实验的记录,主要内容是通过网络模型加载、推理、结果输出的部署全流程展示,从而快速熟悉并掌握 ACL(Ascend Computing Language)基本开发流程。
注意,为了保证学习和体验效果,用户应该具有以下知识储备:
1.熟练的Python语言编程能力
2.深度学习基础知识,理解神经网络模型输入输出数据结构
1. 目录

2. 最终目标
1.了解ACL的基本概念,清楚ACL具备哪些能力,能为我们做什么
2.了解ACL定义的编程模型,理解各类运行资源的概念及其相互关系
3.能够区分Host和Device的概念,并学会管理这两者各自的内存
4.加载一个离线模型进行推理,并为推理准备输入输出数据结构
3. 基础知识
3.1 ATC介绍
ATC(Ascend Tensor Compiler)是华为昇腾软件栈提供的一个编译工具,它的主要功能是将基于开源框架的网络模型(如 Caffe、TensorFlow 等)以及单算子 Json 文件,转换成昇腾AI处理器支持的离线模型 Offline-Model 文件(简称OM文件)。在编译过程中,可以实现算子调度的优化、权值数据重排、内存使用优化等,并且可以脱离设备完成模型的预处理。更详细的ATC介绍,可参看官方文档 。
需要说明的是,理论上对于华为自研 AI 计算框架 MindSpore 的支持会更加友好。
3.2 ACL介绍
对已训练好的权重文件,比如 Caffe框架下的 caffemodel, TensorFlow框架下得到的 checkpoint 或者 pb 文件,再经过 ATC 工具转换后得到的离线模型文件,ACL(Ascend Computing Language,昇腾计算语言)提供了一套用于在昇腾系列处理器上进行加速计算的API。基于这套API,您能够管理和使用昇腾软硬件计算资源,并进行机器学习相关计算。更详细的ACL介绍,可参看官方文档 。
最新版本支持 onnx 模型和 MindSpore 模型转换为离线模型文件,甚至可以直接通过MindSpore进行部署和推理。
当前 ACL 提供了 C/C++ 和 Python 编程接口,能够很方便的帮助开发者达成包括但不限于如下这些目标:
1.加载深度学习模型进行推理
2.加载单算子进行计算
3.图像、视频数据的预处理
4. 准备工作
最终结果是使用 Resnet50 对 3 张图片进行分类推理。为了达成这个结果,首先我们准备了如下两个素材:
- 三张待推理分类的图片数据,如:

- 使用ATC工具,将 tensorflow 的 googlenet.pb 模型转换成昇腾支持的om(offine-model) 文件。
推理后我们将打印每张图片置信度排前5位的标签及其置信度。
5. 开始
5.1 初始化
在开始调用ACL的任何接口之前,首先要做ACL的初始化。初始化的代码很简单,只有一行:
acl.init(config_path)
这个接口调用会帮您准备好ACL的运行时环境。其中调用时传入的参数是一个配置文件在磁盘上的路径,这里暂时不必关注。
有初始化就有去初始化,在确定完成了ACL的所有调用之后,或者进程退出之前,要做去初始化操作,接口调用也十分简单:
acl.finalize()
导入Python包:
import argparse
import numpy as np
import struct
import acl
import os
from PIL import Image
接口介绍:

函数示例:
def init():
ret = acl.init()
check_ret("acl.init", ret)
5.2 申请计算资源
想要使用昇腾处理器提供的加速计算能力,需要对运行管理资源申请,包括Device、Context、Stream。且需要按顺序申请,主要涉及以下三个接口:
acl.rt.set_device(device_id)
这个接口指定计算设备,告诉运行时环境我们想要用哪个设备,或者更具体一点,哪个芯片。但是要注意,芯片和我们在这里传入的编号之间并没有物理上的一一对应关系。
acl.rt.create_context(device_id)
Context作为一个容器,管理了所有对象(包括Stream、Event、设备内存等)的生命周期。不同Context的Stream、不同Context的Event是完全隔离的,无法建立同步等待关系。个人理解为,如果计算资源足够的话,可以创建多个Context,分别运行不同的应用,来提高硬件利用率,而不用担心应用之间的互相干扰,类似于Docker。
acl.rt.create_stream()
Stream用于维护一些异步操作的执行顺序,确保按照应用程序中的代码调用顺序在Device上执行。基于Stream的kernel执行和数据传输能够实现Host运算操作、Host与Device间的数据传输、Device内的运算并行。
接口介绍:


函数示例:
import sys
import os
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
home_path = !echo $HOME
sys.path.append(os.path.join(home_path[0] , "jupyter-notebook/"))
print(System init success.)
# atlas_utils是本团队基于pyACL封装好的一套工具库,如果您也想引用的话,请首先将
# https://gitee.com/ascend/samples/tree/master/python/common/atlas_utils
# 这个路径下的代码引入您的工程中
from atlas_utils.acl_resource import AclResource
from constants import *
# 创建一个AclResource类的实例
acl_resource = AclResource()
#AscendCL资源初始化(封装版本)
acl_resource.init()
# 上方“init”方法具体实现(仅供参考)
# 请阅读“init(self)”方法,观察初始化和运行时资源申请的详细操作步骤
def init(self):
"""
Init resource
"""
print("init resource stage:")
ret = acl.init()
utils.check_ret("acl.init", ret)
#指定用于运算的Device
ret = acl.rt.set_device(self.device_id)
utils.check_ret("acl.rt.set_device", ret)
print("Set device n success.")
#显式创建一个Context
self.context, ret = acl.rt.create_context(self.device_id)
utils.check_ret("acl.rt.create_context", ret)
#创建一个Stream
self.stream, ret = acl.rt.create_stream()
utils.check_ret("acl.rt.create_stream", ret)
#获取当前昇腾AI软件栈的运行模式
#0:ACL_DEVICE,表示运行在Device的Control CPU上或开发者版上
#1:ACL_HOST,表示运行在Host CPU上
self.run_mode, ret = acl.rt.get_run_mode()
utils.check_ret("acl.rt.get_run_mode", ret)
print("Init resource success")
需要说明的是这里使用了 atlas_utils ,这是昇腾团队基于 pyACL 封装好的一套工具库,可以更加便捷的使用,但可能存在更新不及时的问题,也不易于优化提升,以及个人学习理解,建议能不用,则不用。
5.3 加载模型
既然要调用模型进行推理,首先当然是要把模型加载进来。ACL 提供了多种模型加载和内存管理方式,这里我们只选取其中相对简单的一种,即从磁盘上加载离线模型,并且加载后的模型内存由ACL自动管理:
model_path = "./model/resnet50.om"; # 模型文件在磁盘上的路径
model_id, ret = acl.mdl.load_from_file(model_path) # 加载模型
其中,model_id 是系统完成模型加载后生成的模型ID对应的指针对象,加载后生成的model_id,全局唯一。
记得这个“model_id”,后边我们使用模型进行推理,以及卸载模型的时候还要用到。
有加载自然就有卸载,模型卸载的接口比较简单:
acl.mdl.unload(model_id)
至此,您脑海中应该有这样一个概念,即使用了任何的资源,加载了任何的素材,都要记得用完后销毁和卸载。这点对于使用 C/C++编程的同学应该很好理解。
接口介绍:
函数示例:
def load_model(model_path):
model_path = "./model/googlenet_yuv.om"
model_id, ret = acl.mdl.load_from_file(model_path)
check_ret("acl.mdl.load_from_file", ret)
return model_id
5.4 获取模型信息
模型描述需要特殊的数据类型,使用以下函数来创建并获取该数据类型。
acl.mdl.create_desc()
acl.mdl.get_desc(model_desc, model_id)
获取到模型类型后,还需要根据该类型来获取模型的输入输出个数,调用函数如下:
acl.mdl.get_num_inputs(model_desc)
acl.mdl.get_num_outputs(model_desc)
接口介绍:
函数示例:
def get_model_data(model_id):
global model_desc
model_desc = acl.mdl.create_desc()
ret = acl.mdl.get_desc(model_desc, model_id)
check_ret("acl.mdl.get_desc", ret)
input_size = acl.mdl.get_num_inputs(model_desc)
output_size = acl.mdl.get_num_outputs(model_desc)
return input_size, output_size
5.5 申请device内存
要使用 NPU 进行加速计算,首先要申请能够被 NPU 直接访问到的专用内存。在讲解内存申请之前,首先我们要区分如下两个概念:
Host:Host指与Device相连接的X86服务器、ARM服务器,会利用Device提供的NN(Neural-Network )计算能力,完成业务。
Device:Device指安装了芯片的硬件设备,利用PCIe接口与Host侧连接,为Host提供NN计算能力。
简而言之,我们的数据需要先从Host侧进行加载,即读进Host侧内存,随后将其拷贝到Device侧内存,才能进行计算。计算后的结果还要传回Host侧才能进行使用。
申请Device侧内存:
dev_ptr, ret = acl.rt.malloc(size, policy) # 申请device侧内存
其中,dev_ptr是device侧内存指针,size是device侧内存大小。
这里我们分配了跟Host侧同样大小的内存,准备用于在Device侧存放推理数据。本接口最后一个参数policy是内存分配规则。
ACL_MEM_MALLOC_HUGE_FIRST ----- 优先申请大页内存,如果大页内存不够,则使用普通页的内存。
ACL_MEM_MALLOC_HUGE_ONLY ----- 仅申请大页,如果大页内存不够,则返回错误。
ACL_MEM_MALLOC_NORMAL_ONLY ----- 仅申请普通页。
使用完别忘了释放申请过的内存:acl.rt.malloc-> acl.rt.free,切记!!!
接口介绍:

函数示例:
def gen_data_buffer(size, des):
global model_desc
func = buffer_method[des]
for i in range(size):
temp_buffer_size = acl.mdl.get_output_size_by_index(model_desc, i)
temp_buffer, ret = acl.rt.malloc(temp_buffer_size,
const.ACL_MEM_MALLOC_NORMAL_ONLY)
check_ret("acl.rt.malloc", ret)
if des == "in":
input_data.append("buffer": temp_buffer,
"size": temp_buffer_size)
elif des == "out":
output_data.append("buffer": temp_buffer,
"size": temp_buffer_size)
def malloc_device(input_num, output_num):
gen_data_buffer(input_num, des="in")
gen_data_buffer(output_num, des="out")
5.6 图片处理(DVPP)
数字视觉预处理模块(DVPP)作为昇腾AI软件栈中的编解码和图像转换模块,为神经网络发挥着预处理辅助功能。当来自系统内存和网络的视频或图像数据进入昇腾AI处理器的计算资源中运算之前,由于Davinci架构对输入数据有固定的格式要求,如果数据未满足架构规定的输入格式、分辨率等要求,就需要调用数字视觉处理模块进行格式的转换,才可以进行后续的神经网络计算步骤。
DVPP相关接口介绍:
读取、初始化图片:
AclImage(image_file)
图片预处理:
yuv_image=jpegd(image)
将输入图片缩放为输出尺寸:
resized_image = _dvpp.resize(yuv_image, MODEL_WIDTH, MODEL_HEIGHT)
函数示例:
def image_process_dvpp():
global run_mode
global images_list
stream, ret = acl.rt.create_stream()
check_ret("acl.rt.create_stream", ret)
run_mode, ret = acl.rt.get_run_mode()
check_ret("acl.rt.get_run_mode", ret)
_dvpp = Dvpp(stream, run_mode)
_dvpp.init_resource()
IMG_EXT = [.jpg, .JPG, .png, .PNG, .bmp, .BMP, .jpeg, .JPEG]
images_list = [os.path.join("./data", img)
for img in os.listdir("./data")
if os.path.splitext(img)[1] in IMG_EXT]
img_list = []
for image_file in images_list:
image = AclImage(image_file)
image_input = image.copy_to_dvpp()
yuv_image = _dvpp.jpegd(image_input)
resized_image = dvpp.resize(yuv_image,
MODEL_WIDTH, MODEL_HEIGHT)
img_list.append(resized_image)
print("dvpp_process image: success".format(image_file))
return img_list
5.7 数据传输
5.7.1 host传输数据至device
把数据从Host侧拷贝至Device侧:
acl.rt.memcpy(dst, dest_max, src, count, direction)
参数的顺序是:目的内存地址,目的内存最大大小,源内存地址,拷贝长度,拷贝方向。
direction拷贝方向当前支持四种:
ACL_MEMCPY_HOST_TO_HOST ----- host->host
ACL_MEMCPY_HOST_TO_DEVICE ----- host->device
ACL_MEMCPY_DEVICE_TO_HOST ----- device->host
ACL_MEMCPY_DEVICE_TO_DEVICE ----- device->device
该步骤已在DVPP接口内自动完成。
接口介绍:
函数示例:
def _data_interaction_in(dataset):
global input_data
temp_data_buffer = input_data
for i in range(len(temp_data_buffer)):
item = temp_data_buffer[i]
ptr = acl.util.numpy_to_ptr(dataset)
ret = acl.rt.memcpy(item["buffer"],
item["size"],
ptr,
item["size"],
ACL_MEMCPY_HOST_TO_DEVICE)
check_ret("acl.rt.memcpy", ret)
5.7.2 准备推理所需数据结构
模型推理所需的输入输出数据,是通过一种特定的数据结构来组织的,这种数据结构叫“dataSet”,即所有的输入,组成了1个dateset,所有的输出组成了一个dataset。而对于很多模型来讲,输入其实不止一个,那么所有的输入集合叫“dataSet”,其中的每一个输入叫什么呢?
答案是“dataBuffer”。即一个模型的多个输入,每个输入是一个“dataBuffer”,所有的dataBuffer构成了一个“dataSet”。
下面我们从构建dataBuffer开始。
dataBuffer的创建很简单,还记得前边我们申请了Device侧的内存,并且把数据传过去了吗?现在要用到了。我们当时的device侧内存地址:data,这段内存的长度:size。使用上边两个对象来创建一个dataBuffer:
acl.create_data_buffer(data, size)
现在,这个“buffer”就是我们的第一个输入了。
接口介绍:
函数示例:
def create_buffer(dataset, type="in"):
global input_data, output_data
if type == "in":
temp_dataset = input_data
else:
temp_dataset = output_data
for i in range(len(temp_dataset)):
item = temp_dataset[i]
data = acl.create_data_buffer(item["buffer"], item["size"])
if data is None:
ret = acl.destroy_data_buffer(dataset)
check_ret("acl.destroy_data_buffer", ret)
_, ret = acl.mdl.add_dataset_buffer(dataset, data)
if ret != ACL_ERROR_NONE:
ret = acl.destroy_data_buffer(dataset)
check_ret("acl.destroy_data_buffer", ret)
针对本实验所用到的 resnet50 模型,我们只需要一个输入即可,那现在有了dataBuffer,要如何构建dataSet呢?
很简单:
acl.mdl.create_dataset()
dataset有了,下面就是向这个dataset中放置DataBuffer了:
acl.mdl.add_dataset_buffer(dataset, data)
这样,我们在dataset中添加了一个databuffer,输入准备好了。
创建输出数据结构同理,当您拿到一个模型,您应该是清楚这个模型的输出数据结构的,根据其输出个数、每个输出占用内存的大小来申请相应的device内存、dataBuffer以及dataSet即可。
现在假设我们已经创建好了输出的dataset,其变量名称叫做:
outputDataSet
至此,我们准备好了推理所需的所有素材。
当然,将来用完之后别忘了销毁:
acl.create_data_buffer-> acl.destory_data_buffer; acl.mdl.create_dataset-> acl.mdl.destroy_dataset
接口介绍:
函数实例:
def _gen_dataset(type="in"):
global load_input_dataset, load_output_dataset
dataset = acl.mdl.create_dataset()
if type == "in":
load_input_dataset = dataset
else:
load_output_dataset = dataset
create_buffer(dataset, type)
5.8 推理
所有素材准备好之后,模型推理已经是顺理成章的事情了,还记得我们的几个关键素材吗?
model_id
load_input_dataset
load_output_dataset
最终的推理,其实只需要一行代码:
ret = acl.mdl.execute(model_id, input, output)
这是个同步接口,线程会阻塞在这里直到推理结束。推理结束后就可以提取load_output_dataset中的数据进行使用了。
接口介绍:
函数示例:
def inference(model_id, _input, _output):
global load_input_dataset, load_output_dataset
ret = acl.mdl.execute(model_id,
load_input_dataset,
load_output_dataset)
check_ret("acl.mdl.execute", ret)
5.9 后处理
5.9.1释放资源
资源有申请就要有释放,调用以下接口释放之前申请的dataset和databuffer:
ret = acl.mdl.destroy_dataset(dataset)
ret = acl.destory_data_buffer(data_buffer)
接口介绍:
函数示例:
def _destroy_data_set_buffer():
global load_input_dataset, load_output_dataset
for dataset in [load_input_dataset, load_output_dataset]:
if not dataset:
continue
num = acl.mdl.get_dataset_num_buffers(dataset)
for i in range(num):
data_buf = acl.mdl.get_dataset_buffer(dataset, i)
if data_buf:
ret = acl.destroy_data_buffer(data_buf)
check_ret("acl.destroy_data_buffer", ret)
ret = acl.mdl.destroy_dataset(dataset)
check_ret("acl.mdl.destroy_dataset", ret)
5.9.2 申请host内存
建立outputDataset的时候,您应该使用了device侧的内存,将这部分内存拷贝回host侧,即可直接使用了。
申请Host侧内存:
host_ptr是host侧内存指针,随后即可使用host_ptr指向的内存来暂存推理输入数据。把数据从device侧拷贝至host侧:
ret = acl.rt.memcpy(dst, dest_max, src, count, direction)
参数的顺序是:目的内存地址,目的内存最大大小,源内存地址,拷贝长度,拷贝方向。(支持host->host, host->device, device->host, device->device四种,与申请device内存相同)
使用完别忘了释放申请过的内存:
acl.rt.malloc_host-> acl.rt.free_host
接口介绍:

函数示例:
def _data_interaction_out(dataset):
global output_data
temp_data_buffer = output_data
if len(dataset) == 0:
for item in output_data:
temp, ret = acl.rt.malloc_host(item["size"])
if ret != 0:
raise Exception("cant malloc_host ret=".format(ret))
dataset.append("size": item["size"], "buffer": temp)
for i in range(len(temp_data_buffer)):
item = temp_data_buffer[i]
ptr = dataset[i]["buffer"]
ret = acl.rt.memcpy(ptr,
item["size"],
item["buffer"],
item["size"],
ACL_MEMCPY_DEVICE_TO_HOST)
check_ret("acl.rt.memcpy", ret)
5.9.3 获取推理结果并打印
将推理后的结果数据转换为numpy类型,然后按照图片分类置信度前五的顺序打印出来。
结果示例如下:

接口介绍:

函数示例:
def print_result(result):
global images_list, INDEX
dataset = []
for i in range(len(result)):
temp = result[i]
size = temp["size"]
ptr = temp["buffer"]
data = acl.util.ptr_to_numpy(ptr, (size,), 1)
dataset.append(data)
st = struct.unpack("1000f", bytearray(dataset[0]))
vals = np.array(st).flatten()
top_k = vals.argsort()[-1:-6:-1]
print()
print("======== image: =============".format(images_list[INDEX]))
print("======== top5 inference results: =============")
INDEX+=1
for n in top_k:
object_class = get_image_net_class(n)
print("label:%d confidence: %f, class: %s" % (n, vals[n], object_class))
6. 完整样例演示
ACL完整程序示例:
import argparse
import numpy as np
import struct
import acl
import os
from PIL import Image
import sys
home_path = get_ipython().getoutput(echo $HOME)
sys.path.append(os.path.join(home_path[0] , "jupyter-notebook/"))
print(System init success.)
from src.acl_dvpp import Dvpp
import src.constants as const
from src.acl_image import AclImage
from src.image_net_classes import get_image_net_class
WORK_DIR = os.getcwd()
ACL_MEM_MALLOC_HUGE_FIRST = 0
ACL_MEMCPY_HOST_TO_DEVICE = 1
ACL_MEMCPY_DEVICE_TO_HOST = 2
ACL_ERROR_NONE = 0
MODEL_WIDTH = 224
MODEL_HEIGHT = 224
IMG_EXT = [.jpg, .JPG, .png, .PNG, .bmp, .BMP, .jpeg, .JPEG]
ret = acl.init()
# GLOBAL
load_input_dataset = None
load_output_dataset = None
input_data = []
output_data = []
_output_info = []
images_list = []
model_desc = 0
run_mode = 0
INDEX = 0
if WORK_DIR.find("src") == -1:
MODEL_PATH = WORK_DIR + "/src/model/googlenet_yuv.om"
DATA_PATH = WORK_DIR + "/src/data"
else:
MODEL_PATH = WORK_DIR + "/model/googlenet_yuv.om"
DATA_PATH = WORK_DIR + "/data"
buffer_method =
"in": acl.mdl.get_input_size_by_index,
"out": acl.mdl.get_output_size_by_index
def check_ret(message, ret):
if ret != ACL_ERROR_NONE:
raise Exception(" failed ret="
.format(message, ret))
def init():
ret = acl.init()
check_ret("acl.init", ret)
print("init success")
def allocate_res(device_id):
ret = acl.rt.set_device(device_id)
check_ret("acl.rt.set_device", ret)
context, ret = acl.rt.create_context(device_id)
check_ret("acl.rt.create_context", ret)
print("allocate_res success")
return context
def load_model(model_path):
model_id, ret = acl.mdl.load_from_file(model_path)
check_ret("acl.mdl.load_from_file", ret)
print("load_model success")
return model_id
def get_model_data(model_id):
global model_desc
model_desc = acl.mdl.create_desc()
ret = acl.mdl.get_desc(model_desc, model_id)
check_ret("acl.mdl.get_desc", ret)
input_size = acl.mdl.get_num_inputs(model_desc)
output_size = acl.mdl.get_num_outputs(model_desc)
print("get_model_data success")
return input_size, output_size
def gen_data_buffer(num, des):
global model_desc
func = buffer_method[des]
for i in range(num):
#temp_buffer_size = (model_desc, i)
temp_buffer_size = acl.mdl.get_output_size_by_index(model_desc, i)
temp_buffer, ret = acl.rt.malloc(temp_buffer_size,
const.ACL_MEM_MALLOC_NORMAL_ONLY)
check_ret("acl.rt.malloc", ret)
if des == "in":
input_data.append("buffer": temp_buffer,
"size": temp_buffer_size)
elif des == "out":
output_data.append("buffer": temp_buffer,
"size": temp_buffer_size)
def malloc_device(input_num, output_num):
gen_data_buffer(input_num, des="in")
gen_data_buffer(output_num, des="out")
def image_process_dvpp(dvpp):
global run_mode
global images_list
# _dvpp.init_resource()
IMG_EXT = [.jpg, .JPG, .png, .PNG, .bmp, .BMP, .jpeg, .JPEG]
images_list = [os.path.join(DATA_PATH, img)
for img in os.listdir(DATA_PATH)
if os.path.splitext(img)[1] in IMG_EXT]
img_list = []
for image_file in images_list:
#读入图片
image = AclImage(image_file)
image_input = image.copy_to_dvpp()
#对图片预处理
yuv_image = dvpp.jpegd(image_input)
resized_image = dvpp.resize(yuv_image,
MODEL_WIDTH, MODEL_HEIGHT)
img_list.append(resized_image)
print("dvpp_process image: success".format(image_file))
return img_list
def _data_interaction_in(dataset):
global input_data
temp_data_buffer = input_data
for i in range(len(temp_data_buffer)):
item = temp_data_buffer[i]
ptr = acl.util.numpy_to_ptr(dataset)
ret = acl.rt.memcpy(item["buffer"],
item["size"],
ptr,
item["size"],
ACL_MEMCPY_HOST_TO_DEVICE)
check_ret("acl.rt.memcpy", ret)
print("data_interaction_in success")
def create_buffer(dataset, type="in"):
global input_data, output_data
if type == "in":
temp_dataset = input_data
else:
temp_dataset = output_data
for i in range(len(temp_dataset)):
item = temp_dataset[i]
data = acl.create_data_buffer(item["buffer"], item["size"])
if data is None:
ret = acl.destroy_data_buffer(dataset)
check_ret("acl.destroy_data_buffer", ret)
_, ret = acl.mdl.add_dataset_buffer(dataset, data)
if ret != ACL_ERROR_NONE:
ret = acl.destroy_data_buffer(dataset)
check_ret("acl.destroy_data_buffer", ret)
#print("create data_buffer success".format(type))
def _gen_dataset(type="in"):
global load_input_dataset, load_output_dataset
dataset = acl.mdl.create_dataset()
#print("create data_set success".format(type))
if type == "in":
load_input_dataset = dataset
else:
load_output_dataset = dataset
create_buffer(dataset, type)
def inference(model_id, _input, _output):
global load_input_dataset, load_output_dataset
ret = acl.mdl.execute(model_id,
load_input_dataset,
load_output_dataset)
check_ret("acl.mdl.execute", ret)
def _destroy_data_set_buffer():
global load_input_dataset, load_output_dataset
for dataset in [load_input_dataset, load_output_dataset]:
if not dataset:
continue
num = acl.mdl.get_dataset_num_buffers(dataset)
for i in range(num):
data_buf = acl.mdl.get_dataset_buffer(dataset, i)
if data_buf:
ret = acl.destroy_data_buffer(data_buf)
check_ret("acl.destroy_data_buffer", ret)
ret = acl.mdl.destroy_dataset(dataset)
check_ret("acl.mdl.destroy_dataset", ret)
def _data_interaction_out(dataset):
global output_data
temp_data_buffer = output_data
if len(dataset) == 0:
for item in output_data:
temp, ret = acl.rt.malloc_host(item["size"])
if ret != 0:
raise Exception("cant malloc_host ret=".format(ret))
dataset.append("size": item["size"], "buffer": temp)
for i in range(len(temp_data_buffer)):
item = temp_data_buffer[i]
ptr = dataset[i]["buffer"]
ret = acl.rt.memcpy(ptr,
item["size"],
item["buffer"],
item["size"],
ACL_MEMCPY_DEVICE_TO_HOST)
check_ret("acl.rt.memcpy", ret)
def print_result(result):
global images_list, INDEX
dataset = []
for i in range(len(result)):
temp = result[i]
size = temp["size"]
ptr = temp["buffer"]
data = acl.util.ptr_to_numpy(ptr, (size,), 1)
dataset.append(data)
st = struct.unpack("1000f", bytearray(dataset[0]))
vals = np.array(st).flatten()
top_k = vals.argsort()[-1:-6:-1]
print()
print("======== image: =============".format(images_list[INDEX]))
print("======== top5 inference results: =============")
INDEX+=1
for n in top_k:
object_class = get_image_net_class(n)
print("label:%d confidence: %f, class: %s" % (n, vals[n], object_class))
def release(model_id, context):
global input_data, output_data
ret = acl.mdl.unload(model_id)
check_ret("acl.mdl.unload", ret)
while input_data:
item = input_data.pop()
ret = acl.rt.free(item["buffer"])
check_ret("acl.rt.free", ret)
while output_data:
item = output_data.pop()
ret = acl.rt.free(item["buffer"])
check_ret("acl.rt.free", ret)
if context:
ret = acl.rt.destroy_context(context)
check_ret("acl.rt.destroy_context", ret)
context = None
ret = acl.rt.reset_device(0)
check_ret("acl.rt.reset_device", ret)
print(release source success)
def main():
global input_data
#init()
context = allocate_res(0)
model_id = load_model(MODEL_PATH)
input_num, output_num = get_model_data(model_id)
malloc_device(input_num, output_num)
dvpp = Dvpp()
img_list = image_process_dvpp(dvpp)
for image in img_list:
image_data = "buffer":image.data(), "size":image.size
input_data[0] = image_data
_gen_dataset("in")
_gen_dataset("out")
inference(model_id, load_input_dataset, load_output_dataset)
_destroy_data_set_buffer()
res = []
_data_interaction_out(res)
print_result(res)
release(model_id,context)
if __name__ == __main__:
main()
更多有关ACL的介绍,请详见官方参考文档 。
以上是关于华为Ascend昇腾CANN详细教程的主要内容,如果未能解决你的问题,请参考以下文章