2023 · CANN训练营第一季昇腾AI入门Pytorch
Posted 信
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2023 · CANN训练营第一季昇腾AI入门Pytorch相关的知识,希望对你有一定的参考价值。
昇腾AI全栈架构
华为AI全栈全场景解决方案为4层,分别为芯片层、芯片使能层、AI框架层和应用使能层。
芯片
基于统一、可扩展架构的系列化AI IP和芯片,为上层加速提供硬件基础。
芯片产品:昇腾310和昇腾910的独立芯片,Nano-Tiny-Lite的非独立芯片。
Ascend层,一切集成电路的核心,主要作用为运算作用;芯片要学习外部数据以实现对特定数据的感知能力,衡量芯片运算能力的单位为TOPS(每秒钟进行一万亿次,\\(10^12\\)次)
根据不同的需求可以覆盖端边云全场景,端包括手机、手表、摄像头、耳机等(20MPOS-20TPOS间),边包括车载处理器、边缘计算服务器(10TOPS-100TOPS),云包括数据中心(配备Ascend910系列芯片,提供200+TOPS算力.)
芯片使能(异构计算架构)
芯片使能层作用是实现解决方案对外能力开放,及基于计算图的业务流的控制和运行。芯片使能层的作用是调用芯片算力,进行任务调度处理、加减乘除运算和复杂的微积分运算等,通过异构计算架构(Computer Architecture for Neural Networks,CANN)提供的AscendCL语言完成对芯片的控制,让其按照给定指令工作。
CANN支持多种主流的AI框架,包括MindSpore、Tensorflow、Pytorch、Caffe等,并提供上千个高性能算子;CANN中包括了计算加速库、芯片算子库和高度自动化的算子开发工具。
CANN可以抽象为5层,分别是计算基础层、计算执行层、计算编译层、计算服务层、计算语言。
- 计算基础层:为上层提供基础服务,如共享虚拟内存(Shared Virtual Memory,SVM)、设备虚拟化(Virtual Machine,VM)、主机-设备通信(Host Device Communication,HDC)等
- 计算执行层:负责模型和算子的执行,提供如运行时( Runtime )库(执行内存分配、模型管理、数据收发等)、图执行器( Graph Executor )、数字视觉预处理( Digital Vision Pre - Processing , DVPP )、人工智能预处理( Artificial Intelligence Pre-Processing, AIPP )、华为集合通信库(Huawei Collective Communication Library , HCCL )等功能单元。
- 计算编译层:本层主要提供图编译器( Graph Compiler )和 TBE ( Tensor Boost Engine )算子开发支持。前者将用户输入中间表达( Intermediate Representation , IR )的计算图编译成 NPU 运行的模型。后者提供用户开发自定义算子所需的工具。
- 计算服务层:本层主要提供异腾计算库,如神经网络( Neural Network , NN )库、线性代数计算库( Basic Linear Algebra Subprograms . BLAS )等;昇腾计算调优引擎库,例如算子调优、子图调优、梯度调优、模型压缩以及 AI 框架适配器。
- 计算语言(昇腾算子库):接口是昇腾计算开放编程框架,是对低层昇腾计算服务接口的封装。它提供 Device (设备)管理、 Context (上下文)管理、 Stream (流)管理、内存管理、模型加载与执行、算子加载与执行、媒体数据处理、 Graph (图)管理等 API 库,供用户开发人工智能应用调用。
CANN平台---应用开发框架AscendCL:昇腾计算语言,是昇腾计算开放编程框架(是加速模型推理和应用的框架,和训练无关),是对底层昇腾计算服务接口的封装,提供运行时资源(如设备、内存等)管理、模型加载与执行、算子加载与执行、图片数据编解码/裁剪/缩放处理等API库,实现在CANN平台上进行深度学习推理计算、图像图像预处理、单算子加速计算等能力。【统一的API框架实现对所有资源的调用】
AscendCL(Ascend Computing Language)是一套用于在昇腾平台上开发深度神经网络推理应用的C语言API库,提供Device管理、Context管理、Stream管理、内存管理、模型加载与执行、算子加载与执行、媒体数据处理等API,能够实现在昇腾CANN平台上进行深度学习推理计算、图形图像预处理、单算子加速计算等能力。用户可以通过第三方框架调用AscendCL接口,以便使用昇腾AI处理器的计算能力;用户还可以使用AscendCL封装实现第三方lib库,以便提供昇腾AI处理器的运行管理、资源管理能力。
这个框架需要完成三个任务:应用程序的实现、模型开发(训练代码)、算子(计算图)实现,对应的三种核心能力为模型加载能力开放、算子能力开发和Runtime能力开放。
AscendCL的优势:
- 高度抽象:算子编译、加载、执行的API诡异,相比每个算子一个API,AscendCL大幅度减少API数目,降低计算复杂度。
- 向后兼容:确保软件升级后,基于旧版本编译程序依然可以在新版本上运行。
- 零感知芯片:AscendCL接口可以实现应用代码统一,多昇腾处理器无差异。
AscendCL的应用场景:
- 开发应用:用户可以直接调用提供的接口开发目标分类识别应用。
- 供第三方框架调用:用户可以通过第三方框架调用AscendCL接口,使用昇腾AI处理器的计算能力。
- 供第三方开发lib库:用户可以使用AscendCL封装实现第三方库lib库,方便AI处理器运行管理和资源管理。
框架层
构建模型的训练框架,可支持MindSpore、Tensorflow、Pytorch、Caffe等端边云协同的同意训练和推理框架。
应用使能层
一键开发平台Modelarts,基于Web端的应用平台,提供云上的开发环境,训练环境,AI应用的生成以及部署。【用于部署模型的软硬件,包括API/SDK/部署平台和模型库】
模型迁移方法和步骤
硬件简介
NPU为神经网络处理单元,和CPU/GPU明显区别在于计算单元的区别;在上图中可以看到NPU将计算单元分为矩阵计算单元、向量计算单元和标量计算单元。
- 矩阵计算单元Cube:负责矩阵运算,每次可以完成FP16类型的\\(16\\times16\\)大小的两个矩阵相乘,包括MATMUL/CONV2D/LINEAR等运算。
- 向量计算单元Vector:负责向量运算,支持FP16/FP32/INT8/INT32类型。
- 标量计算单元Scalar:负责标量运算和程序流程控制。
Ascend-Pytorch安装
参考以下链接安装:
https://www.hiascend.com/document/detail/zh/canncommercial/601/envdeployment/instg/instg_000002.html
https://www.hiascend.com/document/detail/zh/canncommercial/601/modeldevpt/ptmigr/ptmigr_0004.html
https://www.hiascend.com/document/detail/zh/canncommercial/601/envdeployment/instg/instg_000035.html
模型迁移方法
自动迁移、脚本转换工具迁移和手工迁移。
Demo链接:https://gitee.com/ascend/modelzoo
参考手册:https://www.hiascend.com/document/detail/zh/canncommercial/601/modeldevpt/ptmigr/ptmigr_0008.html
自动迁移
在训练脚本中加入以下代码
from torch_npu.contrib import transfer_to_npu
脚本工具转换迁移
# 进入脚本转换工具所在路径(即脚本工具的安装路径)
cd Ascend-cann-toolkit安装目录/ascend-toolkit/tools/ms_fmk_transplt/
# 执行脚本转换
./pytorch_ _gpu2npu.sh -i 原始脚本路径 -0 脚本转换结果输出路径 -V 原始脚本框架
# 查看结果
手工迁移
单卡迁移:
# 1、导入NPU相关库
import torch
import torch_npu
# 2、迁移适配GPU的模型脚本,指定NPU作为训练设备。指定训练设备由两种方式
# .to(device)
# 该方式可以指定需要的训练资源,使用比较灵活,定义好device后可通过xx.to(device)的方式将模型或数据集等加载到GPU或NPU上,如model.to(device)。
device = torch.device(\'cuda:\'.format(args.gpu)) # 迁移前
device = torch.device(\'npu:\'.format(args.gpu)) # 迁移后
#.cuda(迁移前)和.npu(迁移后)
# 该方式不会自动使用GPU或NPU,需要以xx.cuda()或xx.npu()的方式将模型数据# 集等加载到GPU或NPU上,如model.cuda()
torch.cuda.set_device(args.gpu) # 迁移前
torch_npu.npu.set_device(args.gpu) # 迁移后
# 3、替换CUDA接口:将训练脚本中的CUDA接口替换为NPU接口,例如CUDA接口、模型、损失函数、数据集等迁移到NPU上。
# CUDA接口替换为NPU接口
torch.cuda.is_available() # 迁移前
torch_npu.npu.is_available() # 迁移后
# 模型迁移
model.cuda(args.gpu) # 迁移前
model.npu(args.gpu) # 迁移后
# 数据集迁移
images = images.cuda(args.gpu, non_blocking=True) # 迁移前
target = target.cuda(args.gpu, non_blocking=True)
images = images.npu(args.gpu, non_blocking=True) # 迁移后
target = target.npu(args.gpu, non_blocking=True)
多卡迁移:
# 除单卡迁移包含的3个修改要点外,在分布式场景下,还需要切换通信方式,直接修改init_process_group的值。
# 修改前,GPU使用nccl方式:
dist.init_process_group(backend=\'nccl\',init_method = "tcp//:127.0.0.1:**", ...... ,rank = args.rank) # **为端口号,根据实际选择一个闲置端口填写
# 修改后,NPU使用hccl方式:
dist.init_process_group(backend=\'hccl\',init_method = "tcp//:127.0.0.1:**", ...... ,rank = args.rank) # **为端口号,根据实际选择一个闲置端口填写
应用开发
基本准备
-
登录华为云:www.huaweicloud.com 注册账号
-
在账号中心获取华为账号名称,在我的凭证获取项目ID,申请ECS服务器和创建云平台。
-
在MOBAXTERM上创建SESSION,填写ECS上购买的公网IP,用户名为root用户,密码为所设置的密码。
-
切换到HwHiAiUser用户,在家目录下面(cd /home/),然后使用su - HwHiAiUser切入
-
CANN包安装在用户下的Ascend目录下的ascend-tookit的目录下。
-
在码云上选择一个案例进行部署推理:https://gitee.com/ascend/samples/tree/master/cplusplus/level2_simple_inference/2_object_detection/YOLOV3_coco_detection_picture,根据readme一步步操作即可。
-
日志目录为CANN软件安装目录/ascend/log,日志关键信息如下:
认证测试
-
以下哪一项是昇腾提供的AI框架(Mindspore)
-
通过AscendCL接口,能够实现利用昇腾硬件计算资源、在昇腾CANN平台上进行深度学习推理计算、图形图像预处理、单算子加速计算等能力。
-
您需要按顺序依次申请如下资源:Device、Context、Stream,确保可以使用这些资源执行运算、管理任务。有运行管理资源的申请,自然也有对应的释放接口,所有数据处理都结束后,需要按顺序释放运行管理资源:Stream、Context、Device。您可以只调用aclrtSetDevice接口,因为这个接口同时创建1个默认的Context;而这个默认的Context还附赠了Stream。
-
下列不属于昇腾计算服务层的是(昇腾张量编译器)
-
使用AscendCL开发应用的基本流程,以下正确的是?AscendCL初始化-->运行管理资源申请-->模型加载-->模型执行-->模型卸载-->运行管理资源释放-->AscendCL去初始化
-
以下关于ATC工具说法正确的是:ATC工具可将开源框架的网络模型(如Caffe、TensorFlow等)转换成Davinci架构专用的模型;ATC工具可以将Ascend IR定义的单算子描述文件转换为昇腾AI处理器支持的离线模型;ATC工具在转换过程中会进行算子调度优化、权重数据重排、内存使用优化等具体操作。
-
模型转换工具的名称是ATC
-
昇腾AI处理能识别*.om格式的模型文件
-
关于达芬奇架构中的计算单元,以下说法正确的是【Cube计算单元负责矩阵运算,每次执行可以完成一个fp16的16×16与16×16的矩阵乘; Vector计算单元负责执行向量运算,覆盖各种基本的计算类型;Scalar计算单元负责各类型的标量数据运算和程序的流程控制】
-
PyTorch-Ascend(1.8)的安装步骤为:安装依赖 pyyaml和wheel -> 安装官方torch包 -> 编译生成PyTorch插件的二进制安装包 -> 安装插件torch_npu包
-
AscendCL能够进行(模型加载与执行,运行时资源管理, 算子加载与执行,图像/视频处理)
-
下列关于AscendCL的说法正确的是:用户可以调用AscendCL提供的接口进行图片分类、目标识别等应用的开发;用户可以通过第三方框架调用AscendCL,以便使用昇腾AI处理器的计算能力;用户可以使用AscendCL封装实现第三方lib库,以便提供昇腾AI处理器的运行管理、资源管理等能力;用户可以使用AscendCL进行图开发并部署到昇腾AI处理器运行。
-
关于昇腾AI处理器内的计算单元,以下说法正确的是(AI CPU,负责执行不适合跑在AI Core上的算子,例如非矩阵类的复杂逻辑处理;AI Core,昇腾AI处理器内的AI计算加速单元;DVPP,昇腾AI处理器内置的图像处理单元;AIPP,可在AI Core上完成数据预处理)
-
AscendCL接口支持的编程语言有(C&C++;Python)
-
以下哪些昇腾硬件可以用于推理?Atlas 200 AI加速模块,Atlas 500智能小站,Atlas 800 训练服务器,Atlas 300V 视频解析卡
-
PyTorch框架在线对接昇腾AI处理器的适配方案有哪些特性和优点? 最大程度的继承PyTorch框架动态图的特性;最大限度的继承原生PyTorch上的使用方法,用户迁移过程中在代码开发和代码重用时做到最小的改动;最大限度的继承PyTorch原生的体系结构;扩展性好。在打通流程的通路之上,对于新增的网络模型或结构,只需涉及相关计算类算子的开发与实现。
-
以下关于apex的功能和描述正确的是:[功能]opt_level: O1 [描述]精度模式,Conv, Matmul等使用float16计算,其他如Softmax、BN使用float32;[功能]opt_level: O2 [描述]性能模式,除了BN使用float32外,其他绝大部分使用float16;[功能]静态Loss Scale [描述]静态设置参数确保混合精度训练收敛;[功能]动态Loss Scale [描述]动态计算Loss Scale值并判断是否溢出。
-
日志中包括以下哪些关键信息:日志级别、触发生成日志的文件及对应的行号、产生日志的模块的名称、各模块具体的日志内容
-
关于AscendCL初始化,以下说法不正确的是?一个应用程序进程内可以调用多次aclInit接口进行AscendCL初始化 【正确的内容包括:AscendCL初始化时,可以通过json配置文件配置Dump信息、Profiling采集信息等;如果默认配置已满足需求,无需修改,可向aclInit接口中传入NULL,或者可将配置文件配置为空json串(即配置文件中只有);
使用AscendCL接口开发应用时,必须先调用aclInit接口,否则可能会导致后续系统内部资源初始化出错,进而导致其它业务异常】
极智AI | 三谈昇腾CANN量化
欢迎关注我的公众号 [极智视界],获取我的更多笔记分享
大家好,我是极智视界,本文介绍一下 三谈昇腾CANN量化。
在之前我已经从原理和命令行的量化执行方面介绍了昇腾CANN的量化,有兴趣的同学可以去查看,附上:
- 《谈谈昇腾CANN量化》 ==> 昇腾CANN量化原理;
- 《再谈昇腾CANN量化》 ==> 昇腾CANN命令行量化执行;
这里我们来谈谈CANN量化的Python API,当然这跟命令行的量化执行一样,功能上也是进行量化操作。
先来一个resnet101的python量化的完整代码,然后再慢慢解释:
import os
import argparse
import cv2
import numpy as np
import onnxruntime as ort
import amct_onnx as amct
PATH = os.path.realpath('./')
IMG_DIR = os.path.join(PATH, 'data/images')
LABLE_FILE = os.path.join(IMG_DIR, 'image_label.txt')
PARSER = argparse.ArgumentParser(description='amct_onnx resnet-101 quantization sample.')
PARSER.add_argument('--nuq', dest='nuq', action='store_true', help='whether use nuq')
ARGS = PARSER.parse_args()
if ARGS.nuq:
OUTPUTS = os.path.join(PATH, 'outputs/nuq')
else:
OUTPUTS = os.path.join(PATH, 'outputs/calibration')
TMP = os.path.join(OUTPUTS, 'tmp')
def get_labels_from_txt(label_file):
"""Read all images' name and label from label_file"""
images = []
labels = []
with open(label_file, 'r') as file:
lines = file.readlines()
for line in lines:
images.append(line.split(' ')[0])
labels.append(int(line.split(' ')[1]))
return images, labels
def prepare_image_input(
images, height=256, width=256, crop_size=224, mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]):
"""Read image files to blobs [batch_size, 3, 224, 224]"""
input_tensor = np.zeros((len(images), 3, crop_size, crop_size), np.float32)
imgs = np.zeros((len(images), 3, height, width), np.float32)
for index, im_file in enumerate(images):
im_data = cv2.imread(im_file)
im_data = cv2.resize(im_data, (256, 256), interpolation=cv2.INTER_CUBIC)
cv2.cvtColor(im_data, cv2.COLOR_BGR2RGB)
imgs[index, :, :, :] = im_data.transpose(2, 0, 1).astype(np.float32)
h_off = int((height - crop_size) / 2)
w_off = int((width - crop_size) / 2)
input_tensor = imgs[:, :, h_off: (h_off + crop_size), w_off: (w_off + crop_size)]
# trans uint8 image data to float
input_tensor /= 255
# do channel-wise reduce mean value
for channel in range(input_tensor.shape[1]):
input_tensor[:, channel, :, :] -= mean[channel]
# do channel-wise divide std
for channel in range(input_tensor.shape[1]):
input_tensor[:, channel, :, :] /= std[channel]
return input_tensor
def img_postprocess(probs, labels):
"""Do image post-process"""
# calculate top1 and top5 accuracy
top1_get = 0
top5_get = 0
prob_size = probs.shape[1]
for index, label in enumerate(labels):
top5_record = (probs[index, :].argsort())[prob_size - 5: prob_size]
if label == top5_record[-1]:
top1_get += 1
top5_get += 1
elif label in top5_record:
top5_get += 1
return float(top1_get) / len(labels), float(top5_get) / len(labels)
def onnx_forward(onnx_model, batch_size=1, iterations=160):
"""forward"""
ort_session = ort.InferenceSession(onnx_model, amct.AMCT_SO)
images, labels = get_labels_from_txt(LABLE_FILE)
images = [os.path.join(IMG_DIR, image) for image in images]
top1_total = 0
top5_total = 0
for i in range(iterations):
input_batch = prepare_image_input(images[i * batch_size: (i + 1) * batch_size])
output = ort_session.run(None, 'input': input_batch)
top1, top5 = img_postprocess(output[0], labels[i * batch_size: (i + 1) * batch_size])
top1_total += top1
top5_total += top5
print('****************iteration:*****************'.format(i))
print('top1_acc:'.format(top1))
print('top5_acc:'.format(top5))
print('******top1:'.format(top1_total / iterations))
print('******top5:'.format(top5_total / iterations))
return top1_total / iterations, top5_total / iterations
def main():
"""main"""
model_file = './model/resnet-101.onnx'
print('[INFO] Do original model test:')
ori_top1, ori_top5 = onnx_forward(model_file, 32, 5)
config_json_file = os.path.join(TMP, 'config.json')
skip_layers = []
batch_num = 1
if ARGS.nuq:
amct.create_quant_config(
config_file=config_json_file, model_file=model_file, skip_layers=skip_layers, batch_num=batch_num,
activation_offset=True, config_defination='./src/nuq_conf/nuq_quant.cfg')
else:
amct.create_quant_config(
config_file=config_json_file, model_file=model_file, skip_layers=skip_layers, batch_num=batch_num,
activation_offset=True, config_defination=None)
# Phase1: do conv+bn fusion, weights calibration and generate
# calibration model
scale_offset_record_file = os.path.join(TMP, 'record.txt')
modified_model = os.path.join(TMP, 'modified_model.onnx')
amct.quantize_model(
config_file=config_json_file, model_file=model_file, modified_onnx_file=modified_model,
record_file=scale_offset_record_file)
onnx_forward(modified_model, 32, batch_num)
# Phase3: save final model, one for onnx do fake quant test, one
# deploy model for ATC
result_path = os.path.join(OUTPUTS, 'resnet-101')
amct.save_model(modified_model, scale_offset_record_file, result_path)
# Phase4: run fake_quant model test
print('[INFO] Do quantized model test:')
quant_top1, quant_top5 = onnx_forward('%s_%s' % (result_path, 'fake_quant_model.onnx'), 32, 5)
print('[INFO] ResNet101 before quantize top1::>10 top5::>10'.format(ori_top1, ori_top5))
print('[INFO] ResNet101 after quantize top1::>10 top5::>10'.format(quant_top1, quant_top5))
if __name__ == '__main__':
main()关于量化数据集的制作同样可以参考《再谈昇腾CANN量化》里的方法。
以上完整的量化过程,有三个主要的python接口,分别是:create_quant_config、quantize_model、save_model,来分别介绍一下。
create_quant_config的作用是根据graph的结构找到所有可量化的层,自动生成量化配置文件,并将可量化层的量化配置因子写入文件,函数接口如下:
create_quant_config(config_file, model_file, skip_layers=None, batch_unm=1, activation_offset=True, config_defination=None, updated_model=None)其中:

这个函数会输出一个json格式的量化配置文件,一个简单的调用方法如下:
import amct_onnx
model_file = "resnet101.onnx"
# 生成量化配置文件
amct_onnx.create_quant_config(config_file="config.json",
model_file=model_file,
skip_layers=None,
batch_num=1,
activation_offset=True)接着咱们来看quantize_model,顾铭思议,这个接口就是在做量化。将输入的待量化的graph结构按照create_quant_config生成的量化配置文件进行量化处理,在传入的graph结构中插入量化算子如quant/dequant,然后生成量化因子记录文件record_file,返回修改后的onnx量化校准模型。函数的接口如下:
quantize_model(config_file, model_file, modified_onnx_file, record_file)其中:

这个函数会返回modified_onnx_file待量化模型 和 record_file量化因子记录文件,以用于下一步生成量化模型。一个简单的调用示例如下:
import amct_onnx
model_file = "resnet101.onnx"
scale_offset_record_file = os.path.join(TMP, 'scale_offset_record.txt')
modified_model = os.path.join(TVM, 'modified_model.onnx')
config_file = "config.json"
# 量化
amct_onnx.quantize_model(config_file,
model_file,
modified_model,
scale_offset_record_file)最后来看save_model,这个函数的功能是根据量化因子文件record_file和修改后的量化模型modified_model,插入AscendQuant和AscendDequant等量化相关算子,生成可以在onnx runtime环境进行精度仿真的face_quant模型 以及 可以在昇腾上推理的deploy模型。函数接口如下:
save_model(modified_onnx_file, record_file, save_path)其中:
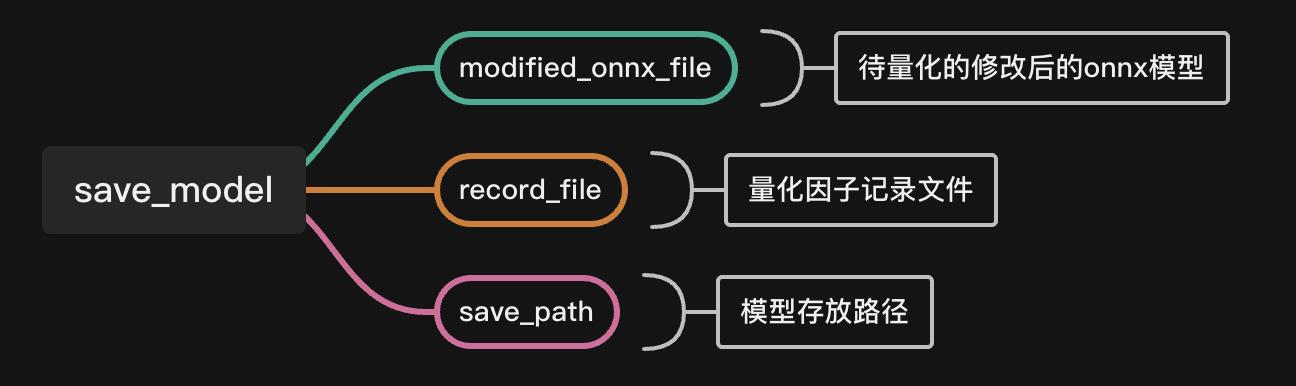
生成的精度仿真模型和推理模型在结构上有什么区别呢,来看:
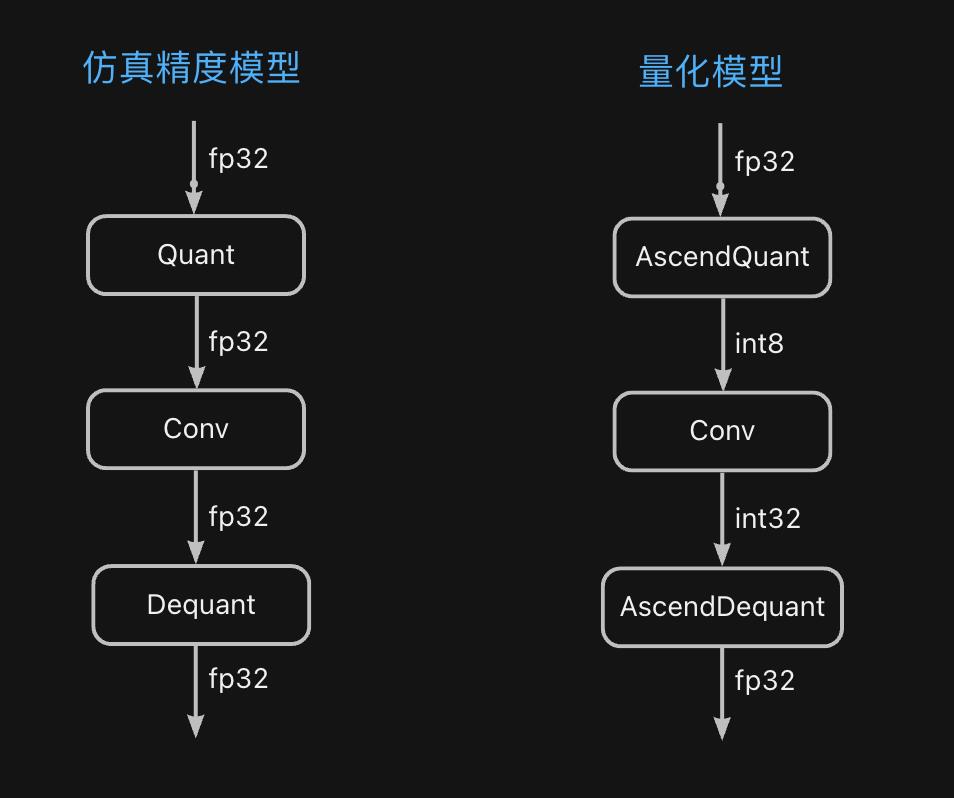
一个简单的调用示例如下:
import amct_onnx
# 保存量化模型
amct_onnx.save_model(modified_onnx_file="modified_model.onnx",
record_file="scale_offset_record_file.txt",
save_path="res")这样整个CANN量化的Python API实现方式就介绍完了。
好了,以上分享三谈昇腾CANN量化,希望我的分享能对你的学习有一点帮助。
【极智视界】

搜索关注我的微信公众号「极智视界」,获取我的更多经验分享,让我们用极致+极客的心态来迎接AI !
以上是关于2023 · CANN训练营第一季昇腾AI入门Pytorch的主要内容,如果未能解决你的问题,请参考以下文章