英特尔用ViT做密集预测效果超越卷积,性能提高28%,mIoU直达SOTA|在线可玩
Posted QbitAl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了英特尔用ViT做密集预测效果超越卷积,性能提高28%,mIoU直达SOTA|在线可玩相关的知识,希望对你有一定的参考价值。
丰色 发自 凹非寺
量子位 报道 | 公众号 QbitAI
用全卷积网络做密集预测 (dense prediction),优点很多。
但现在,你可以试试Vision Transformer了——
英特尔最近用它搞了一个密集预测模型,结果是相比全卷积,该模型在单目深度估计应用任务上,性能提高了28%。

其中,它的结果更具细粒度和全局一致性。

在语义分割任务上,该模型更是在ADE20K数据集上以49.02%的mIoU创造了新的SOTA。
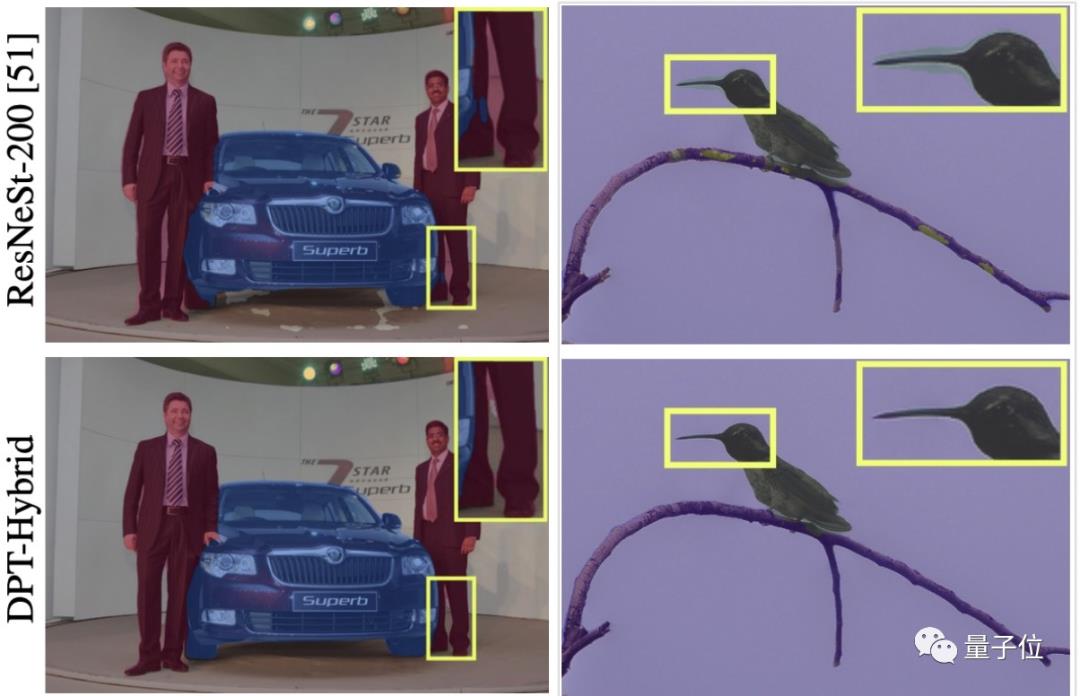
这次,Transformer又在CV界秀了一波操作。
沿用编码-解码结构
此模型名叫DPT,也就是dense prediction transformer的简称。
总的来说,DPT沿用了在卷积网络中常用的编码器-解码器结构,主要是在编码器的基础计算构建块用了transformer。
它通过利用ViT为主干,将ViT提供的词包(bag-of-words)重新组合成不同分辨率的图像特征表示,然后使用卷积解码器将该表示逐步组合到最终的密集预测结果。
模型架构图如下:
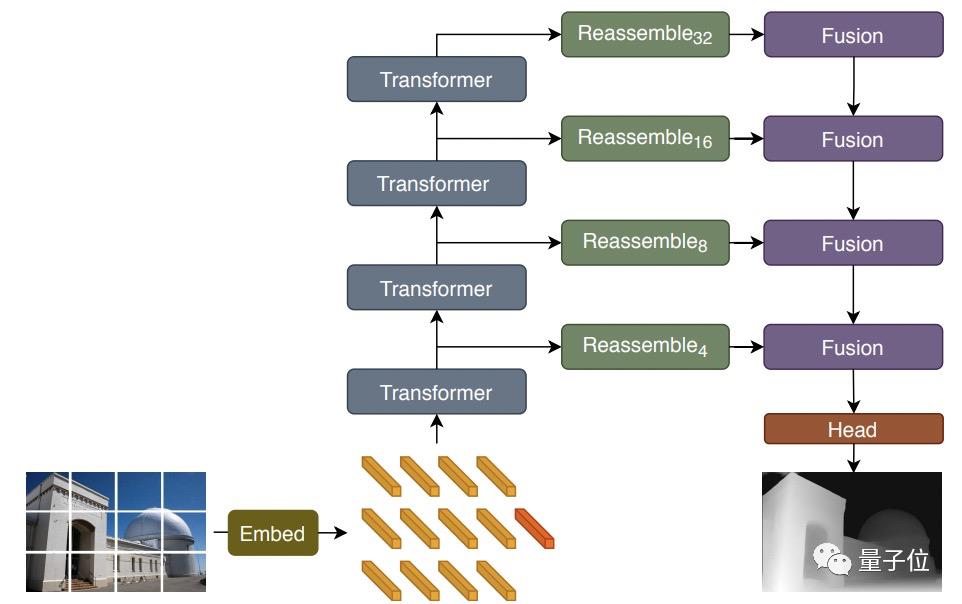
具体来说就是先将输入图片转换为tokens(上图橙色块部分),有两种方法:
(1)通过展开图像表征的线性投影提取非重叠的图像块(由此产生的模型为DPT-Base与DPT-Large);
(2)或者直接通过ResNet-50的特征提取器来搞定(由此产生的模型为DPT-Hybrid)。
然后在得到的token中添加位置embedding,以及与图像块独立的读出token(上图红色块部分)。
接着将这些token通过transformer进行处理。
再接着将每个阶段通过transformer得到的token重新组合成多种分辨率的图像表示(绿色部分)。注意,此时还只是类图像(image-like)。
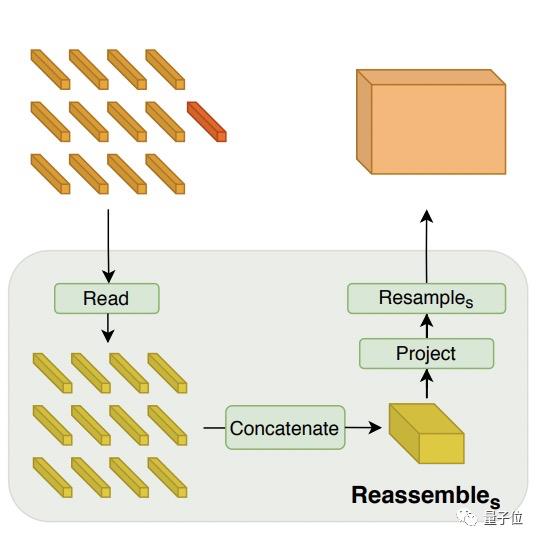
下图为重组过程,token被组装成具有输入图像空间分辨率1/s的特征图。
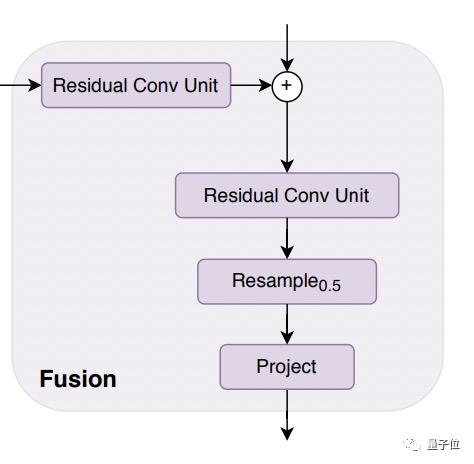
最后,通过融合模块(紫色)将这些图像表示逐步“拼接”并经过上采样,生成我们最终想要的密集预测结果。
ps.该模块使用残差卷积单元组合特征,对特征图进行上采样。
以上就是DPT的大致生成过程,与全卷积网络不同,ViT主干在初始图像embedding计算完成后放弃了下采样,并在全部处理阶段保持恒定维数的图像表示。
此外,它在每阶段都有一个全局感受野。
正是这两点不同对密集预测任务尤其有利,让DPT模型的结果更具细粒度和全局一致性。
用两种任务来检验效果
具体效果如何?
研究人员将DPT应用于两种密集预测任务。
由于transformer只有在大训练集上才能展现其全部潜能,因此单目深度估计评估是测试DPT能力的理想任务。
他们将DPT与该任务上的SOTA模型进行对比,采用的数据集包含约140万张图像,是迄今为止最大的单目深度估计训练集。
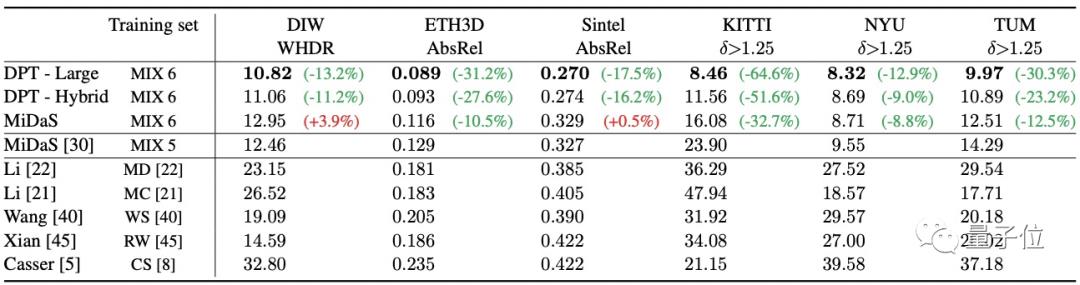
结果是,两种DPT变体的性能均显著优于最新模型(以上指标越低越好)。
其中,与SOTA架构MiDaS相比,DPT-Hybrid的平均相对改善率超过23%,DPT-Large的平均相对改善率则超过28%。
为了确保该成绩不仅是由于扩大了训练集,研究人员也在更大的数据集上重新训练了MiDaS,结果仍然是DPT胜出。
通过视觉比较图还可以看出,DPT可以更好地重建细节,可以在对卷积结构具有挑战的区域(比如较大的均匀区域)中提高全局一致性。

另外,通过微调,研究人员发现DPT也可以有效地应用于较小的数据集。
在具有竞争力的语义分割任务上:研究人员在ADE20K数据集上对DPT进行了240个epoch的训练。
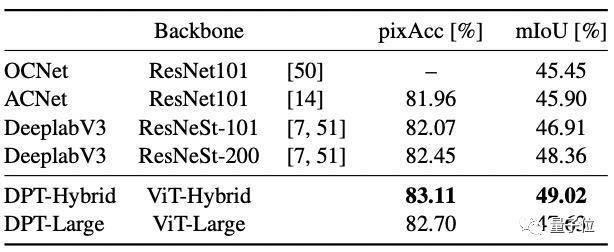
结果发现,DPT-Hybrid优于现有的所有全卷积结构,以49.02的mIoU达到了SOTA(其更清晰、更细粒度的边界效果如开头所展示)。
而DPT-Large的性能稍差,研究人员分析可能是因为与之前的实验相比,采用的数据集要小得多。
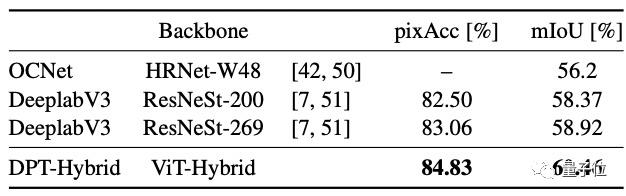
同时,他们在小数据集(Pascal)上对表现优异的DPT-Hybrid微调了50个epoch后发现,DPT的性能仍然强大。
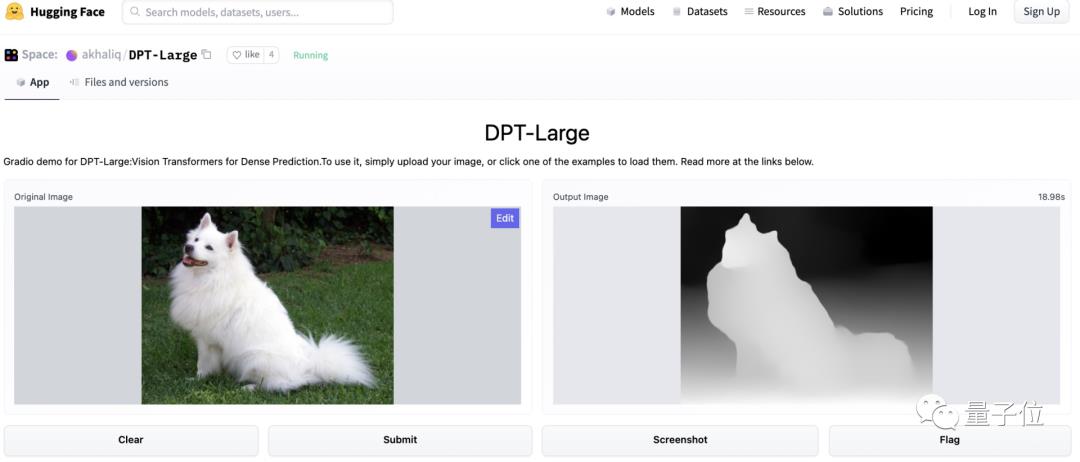
最后,“百闻不如一见”,如果你想体验DPT的真实效果,可以到Huggingface官网。
论文地址:
https://arxiv.org/abs/2103.13413
模型地址:
https://github.com/intel-isl/dpt
Hugging Face体验地址:
https://huggingface.co/spaces/akhaliq/DPT-Large
以上是关于英特尔用ViT做密集预测效果超越卷积,性能提高28%,mIoU直达SOTA|在线可玩的主要内容,如果未能解决你的问题,请参考以下文章
用ViT替代卷积网络做密集预测,英特尔实验室提出DPT架构,在线Demo可用
CNN卷土重来!超越Transformer!FAIR重新设计纯卷积架构:ConvNeXt