用ViT替代卷积网络做密集预测,英特尔实验室提出DPT架构,在线Demo可用
Posted Charmve
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用ViT替代卷积网络做密集预测,英特尔实验室提出DPT架构,在线Demo可用相关的知识,希望对你有一定的参考价值。
点击上方“迈微AI研习社”,选择“星标★”公众号
重磅干货,第一时间送达
选自丨机器之心
在这项研究中,研究者提出了 DPT 架构。这种 ViT 架构代替了卷积网络作为密集预测任务的主干网络,获得了更好的细粒度和更全局一致的预测。
图像语义分割的目标是将图像的每个像素所属类别进行标注。因为是预测图像中的每个像素,这个任务通常被称为密集预测。
当前,密集预测的架构几乎都是基于卷积网络的,且通常遵循一种模式:将网络分为一个编码器和一个解码器,编码器通常基于图像分类网络,也称为主干,它是在一个大型语料库 (如 ImageNet) 上进行预训练的;解码器聚合来自编码器的特征,并将其转换为最终的密集预测。以往的密集预测架构研究通常关注解码器及其聚合策略,但实际上主干架构的选择对整个模型来说非常关键,因为在编码器中丢失的信息不可能在解码器中恢复。
在英特尔的一项研究中,研究者提出了 DPT 架构(dense prediction transformer)。DPT 是一种用于密集预测的新架构,它仍然基于编码器 - 解码器的设计,但其中利用 transformer 作为编码器的基础计算构建块。
具体而言,研究者使用此前的视觉 transformer(ViT)作为主干架构,将由 ViT 提供的词袋表征重组为各种分辨率下的类图像特征表征,并使用卷积解码器逐步将这些特征表征组合到最终的密集预测中。
Transformer 主干网络以一个不变的和相对高的分辨率来处理表征,并在每个阶段都有一个全局接感受野。与全卷积网络相比,这些特性允许 DPT 提供更好的细粒度和更全局一致的预测。
实验表明,这种架构对于密集预测任务有很大的改进,特别是在有大量训练数据可用的情况下。对于单目深度估计,研究者观察到相比于当前 SOTA 全卷积网络,新架构取得了高达 28% 的提升。当应用于语义分割时,DPT 在 ADE20K 上实现了新的 SOTA(49.02% mIoU)。此外,研究者也展示了该架构在较小的数据集上的微调结果,比如在 NYUv2、 KITTI 和 Pascal Context 均实现了新的 SOTA。

论文地址:https://arxiv.org/abs/2103.13413
代码地址:https://github.com/intel-isl/dpt
值得一提的是,感兴趣的研究者现在可以到 Huggingface 平台体验 Demo:
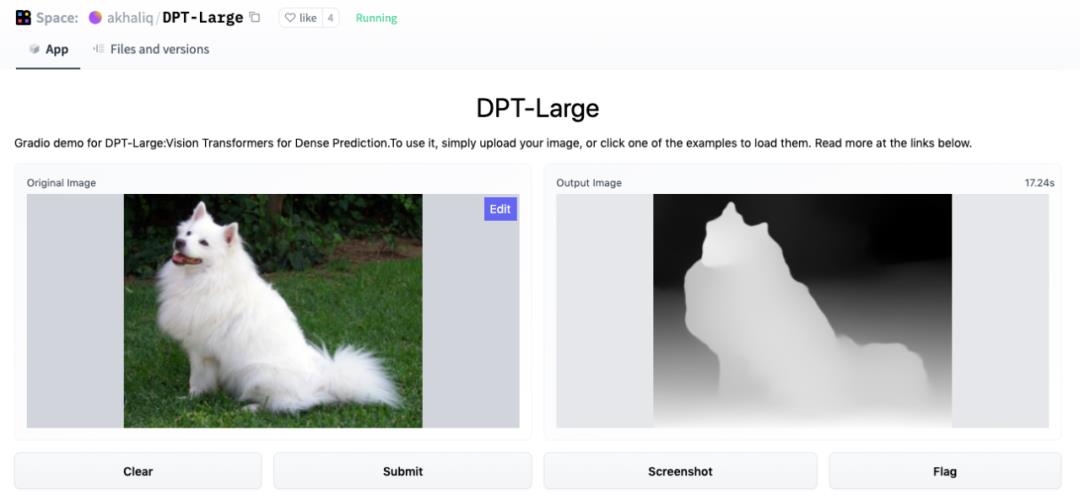
Demo 地址:https://huggingface.co/spaces/akhaliq/DPT-Large
架构
我们来具体看下这种密集 ViT 的新型架构,它沿用了已在密集预测方面取得成功的编码器 - 解码器结构。其中以视觉 transformer 作为主干,由编码器产生的表征能够被有效地转换为密集预测,完整架构如下图 1(左)所示。
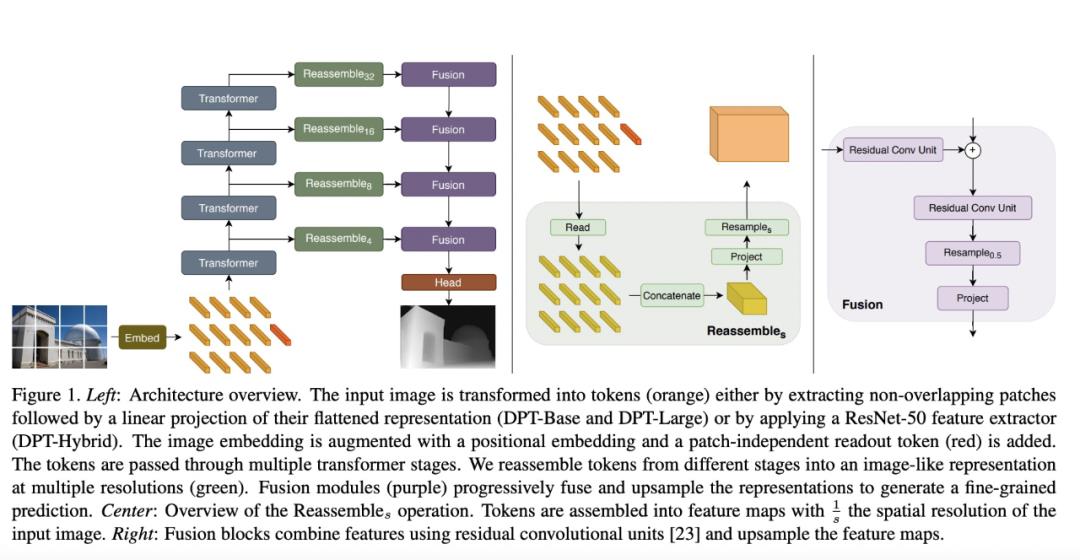
Transformer 编码器
在高层级上,视觉变换器 (ViT) 对图像的词袋(bag-of-words)表征进行操作。单独嵌入到特征空间中的图像 patch 或从图像中提取的深度特征,扮演「word」的角色。该研究的其余部分将嵌入「word」作为 token。Transformer 使用多头自注意力(MHSA)的序列块对 token 集进行转换,其中每个 token 相互关联以转换表征。
对于应用程序来说,最重要的是 transformer 在所有计算中都要保持 token 的数量。由于 token 与图像 patch 一一对应,这意味着 ViT 编码器在所有 transformer 阶段都能保持初始嵌入的空间分辨率。此外,MHSA 本质上是一种全局操作,因为每个 token 都可以参与并影响其他所有 token。因此,transformer 在初始嵌入后的每个阶段都能有一个全局感受野,这与卷积网络形成鲜明对比。
卷积解码器
该架构的解码器将 token 集组合成多种分辨率的类图像特征表征。这些特征表征被逐渐融合到最终的密集预测中。该研究提出了一个简单的三阶段重组(Reassemble)操作,以从 transformer 编码器任意层的输出 token 中恢复类图像表征:
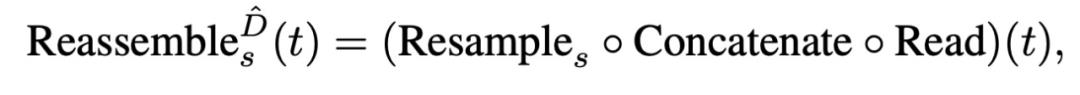
其中, s 代表恢复得到的表征相比于输入图像的输出尺寸比率,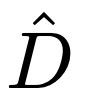 代表输出特征维度。
代表输出特征维度。
变换图像尺寸
与全卷积网络类似,DPT 可以变换图像的尺寸。只要图像尺寸能够被 p 整除,就可以应用嵌入过程产生不同数量的图像 token N_p。作为一种 set-to-set 架构,transformer 编码器可以轻松处理不同数量的 token。然而,位置嵌入依赖于图像的尺寸,因为它对输入图像中 patch 的位置进行编码。该研究遵循 Alexey Dosovitskiy 等人在论文《An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale》中提出的方法,并将位置嵌入线性插入到适当的尺寸。值得注意的是这可以对每个图像即时完成。在嵌入过程和 transformer 阶段之后,只要输入图像与卷积解码器的步幅(32 个像素)对齐,重组和融合模块都可以轻松处理不同数量的 token。
实验
在实验环节,研究者将 DPT 应用于两个密集的预测任务: 单目深度估计和语义分割。首先使用默认配置展示了主要部分的结果,并在最后展示了不同 DPT 配置的消融实验结果。
表 1 展示了 Zero-shot 跨数据集迁移学习的结果,这些数据集均未参与训练过程。
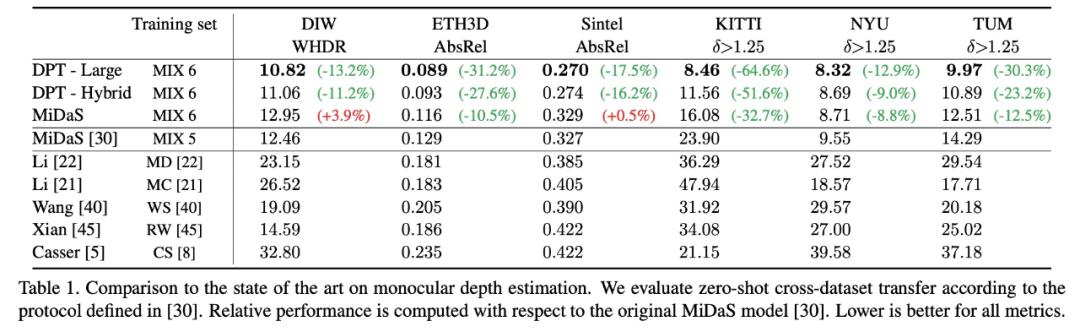
图 2 展示了几种方法的视觉效果对比。

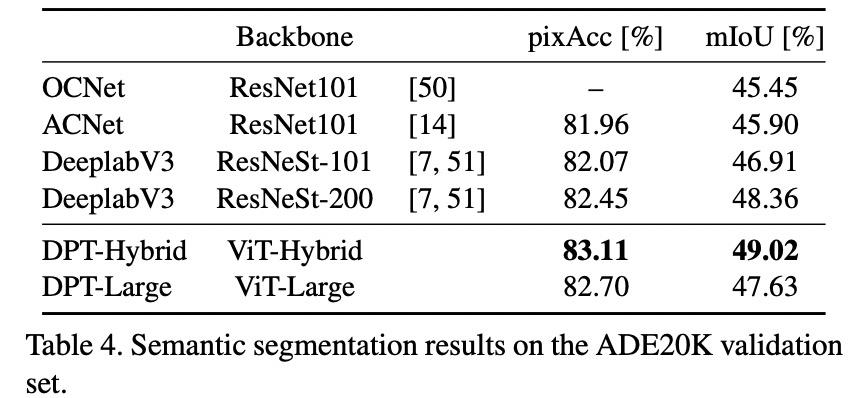
此外,研究者在 KITTI 和 NYUv2 数据集上微调了 DPT-Hybrid,以进一步比较 DPT 与现有工作的性能。如表 2 和表 3 所示,DPT 架构在所有指标上均持平或有所提高。这表明 DPT 也可以有效地应用于较小的数据集。
语义分割
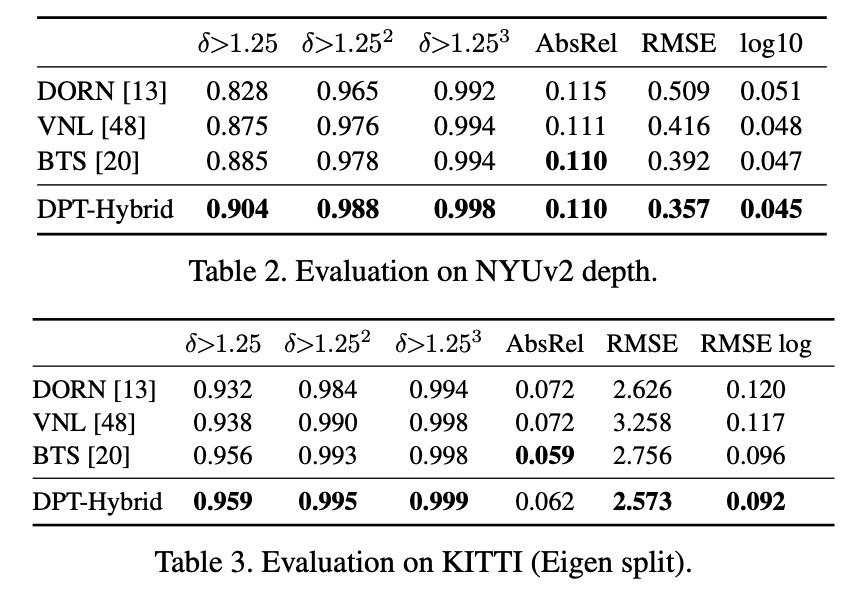
随后,研究者选择了语义分割作为第二项任务,因为它是离散标记任务的代表,也是密集预测架构的重要任务。研究者采用了与上述实验相同的主干网络和解码器结构,使用一个 output head,以半分辨率进行预测以及对 logits 进行上采样,使用双线性插值补全分辨率。编码器再次由 ImageNet 预训练的权重初始化,解码器则随机初始化。
研究者在 ADE20K 语义分割数据集上对 DPT 进行了 240 个 epoch 的训练。表 4 展示了验证集上的结果,DPT-Hybrid 的性能优于所有现有的全卷积架构。
该研究还在 Pascal Context 数据集上对 DPT-Hybrid 进行了 50 个 epoch 的微调,其他超参数保持不变。表 5 展示了验证集的结果:DPT 即使在较小的数据集上也能提供优秀的性能。

消融实验
由于 Transformer 主干网络保持一个稳定的特征分辨率,因此不清楚主干网络特征中有哪些值得利用的部分。研究者进行了消融实验来探究这一点。
表 6(顶部)中对几种可能的选择进行了评估。其中发现,从包含低层特征的图层和包含高层特征的深层图层中挖掘特征是有益的。研究者采用最佳的设置进行进一步的实验。
研究者用表 6(底部)中的 Hybrid 结构进行了类似的实验,其中 R0 和 R1 指的是使用 ResNet50 嵌入网络的第一和第二阶段下采样的特征。
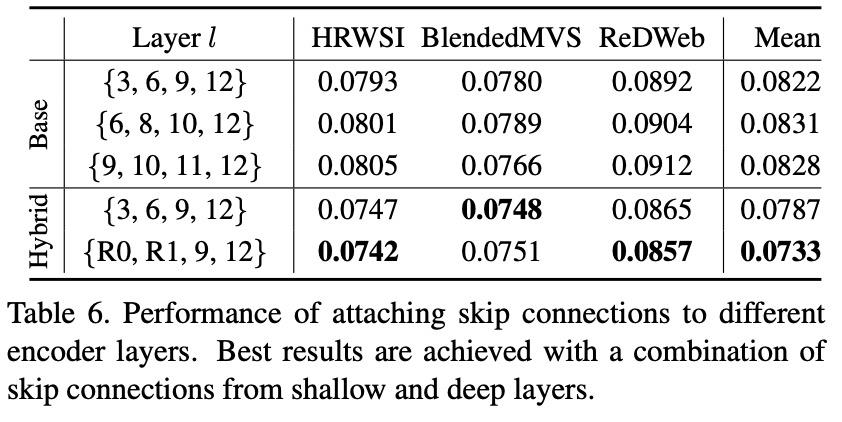
表 7 展示了重组块(Reassemble block)的第一阶段在处理 readout token 时的各种设置及其相应性能:

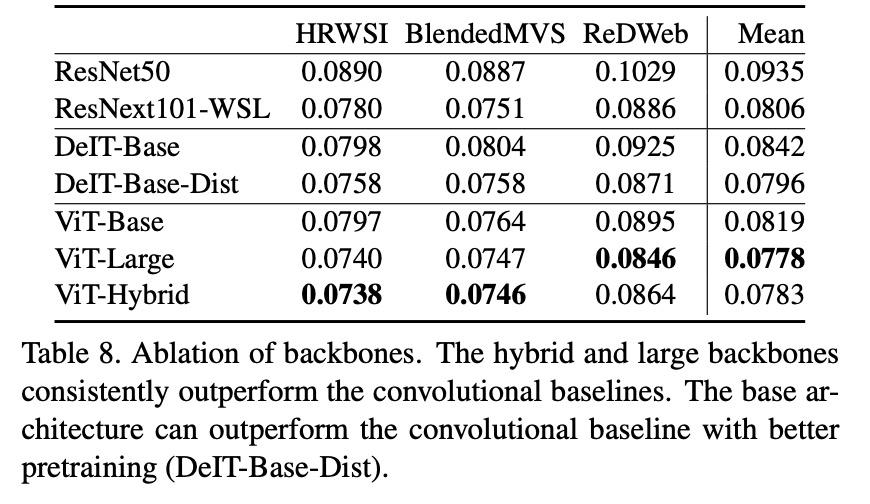
如表 8 所示,ViT-Large 的性能优于所有其它主干网络,但大小也几乎是 ViT-Base 和 ViT-Hybrid 的 3 倍。在参数量相近的情况下,ViT-Hybrid 的性能优于 ViT-Base,而且与大型主干网络的性能相当。
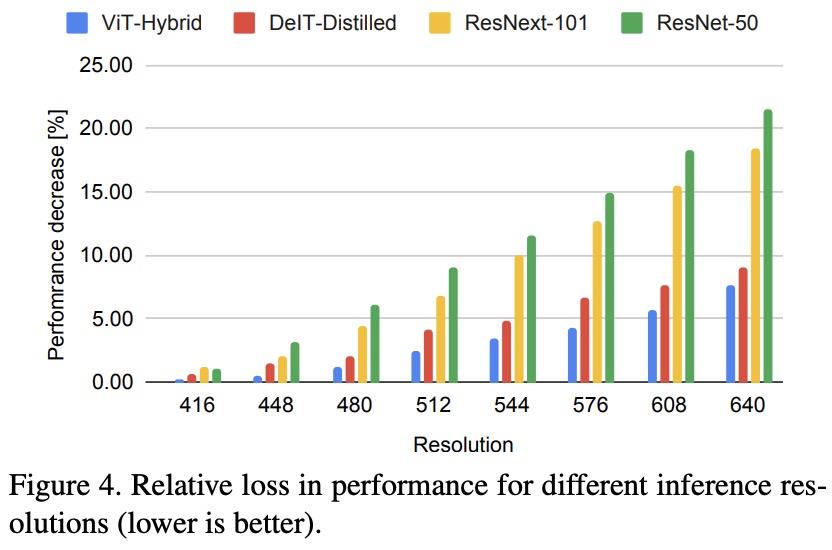
虽然完全卷积结构在其最深层有大的有效感受野,但接近输入的层却是局部的,感受野较小。如下图 4 所示,可以观察到,随着推理分辨率的提高,DPT 变体的性能确实会更缓慢地降低。
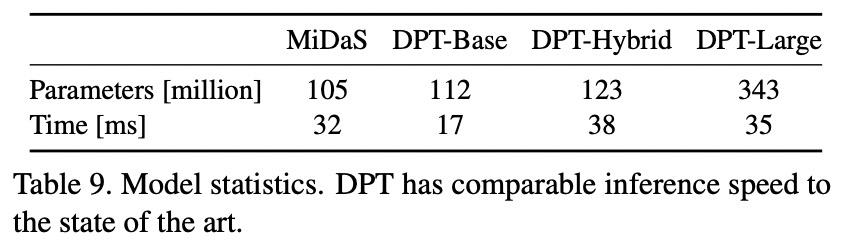
在推理速度方面,表 9 展示了不同网络结构的推理时间:
更多细节可参考论文原文,更多精彩内容请关注迈微AI研习社,每天晚上七点不见不散!
© THE END
投稿或寻求报道微信:MaiweiE_com
GitHub中文开源项目《计算机视觉实战演练:算法与应用》,“免费”“全面“”前沿”,以实战为主,编写详细的文档、可在线运行的notebook和源代码。
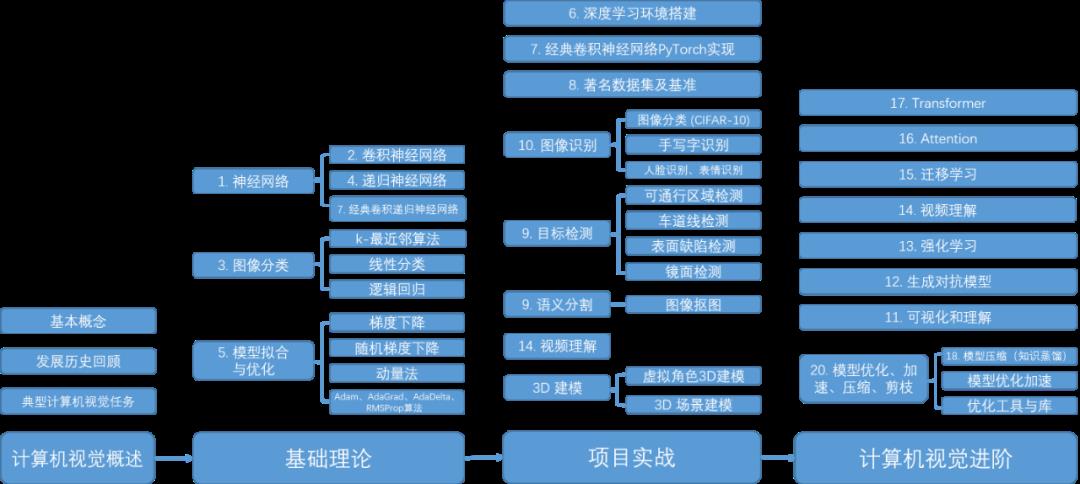
项目地址 https://github.com/Charmve/computer-vision-in-action
项目主页 https://charmve.github.io/L0CV-web/
推荐阅读
(更多“抠图”最新成果)
迈微AI研习社
微信号: MaiweiE_com
GitHub: @Charmve
CSDN、知乎: @Charmve
投稿: yidazhang1@gmail.com
主页: github.com/Charmve

如果觉得有用,就请点赞、转发吧!
以上是关于用ViT替代卷积网络做密集预测,英特尔实验室提出DPT架构,在线Demo可用的主要内容,如果未能解决你的问题,请参考以下文章
英特尔用ViT做密集预测效果超越卷积,性能提高28%,mIoU直达SOTA|在线可玩
第37篇EdgeViTs: 在移动设备上使用Vision Transformers 的轻量级 CNN