CNN卷土重来!超越Transformer!FAIR重新设计纯卷积架构:ConvNeXt Posted 2022-01-27 CVer
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CNN卷土重来!超越Transformer!FAIR重新设计纯卷积架构:ConvNeXt相关的知识,希望对你有一定的参考价值。
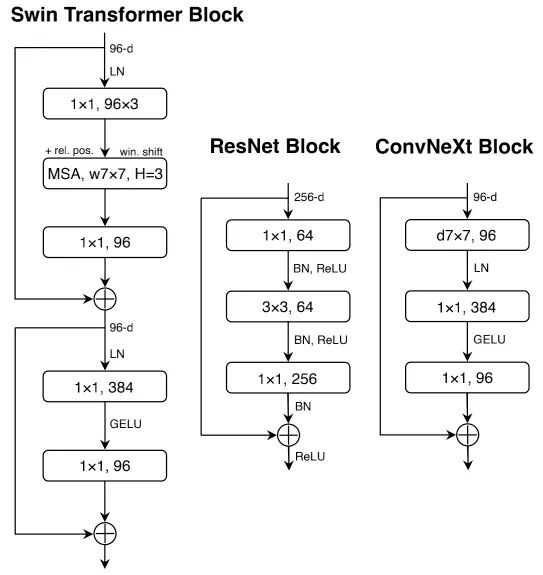
NLP与视觉架构的一个差异体现在激活函数的实用 。ConvNet大多采用ReLU,而ViT大多采用GELU。我们发现:ConvNet中的ReLU可以替换为GELU,同时性能不变(80.6%)。
Fewer Activation Functions. Transformer与ResNet模块的一个小区别:Transformer模块使用了更少的激活函数 。类似的,我们对ConvNeXt模块进行下图所示的改进,模型性能从80.6%提升到了81.3% (此时,它具有与Swin-T相当的性能)。
Fewer Normalization Layers Transformer通常具有更少的Normalization层,因此我们移除两个BN层仅保留 卷积之前的一个BN 。模型的性能提升到了81.4%,超越了Swin-T。
Substituting BN with LN 尽管BN是ConvNet的重要成分,具有加速收敛降低过拟合的作用;但BN对模型性能也存在有害影响。Transformer中的LN对不同的应用场景均具有比较好的性能。直接在原始ResNet中将BN替换为LN会导致性能下降,而组合了上述技术后再将BN替换为LN则能带来性能的提升:81.5% 。
Separate Downsamling Layers 在ResNet中,每个阶段先采用stride=2的模型的性能提升到了82.0%,大幅超越了Swin-T的81.3%。
Closing remarks . 到此为止,我们完成了ConvNet的进化之路,得到了超越SwinTransformer的纯ConvNet架构ConvNeXt。需要注意的是,上述设计并没有新颖之处,均得到了研究,但并未进行汇总集成。ConvNeXt具有与SwinTransformer相当的参数量、吞吐量、内存占用,更高的性能,且不需要依赖特定的模块(比如移位窗口注意力、相对位置偏置) 。
基于前述ConvNeXt架构,我们构建了ConvNeXt-T/S/B/L以对标Swin-T/S/B/L。此外,我们还构建了一个更大的ConvNeXt-XL以进一步测试ConvNeXt的缩放性。不同变种模型的区别在于通道数、模块数,详细信息如下:
ConvNeXt-XL: C=
参考技术A
©作者 | 小欣
以上是关于CNN卷土重来!超越Transformer!FAIR重新设计纯卷积架构:ConvNeXt的主要内容,如果未能解决你的问题,请参考以下文章
CNN和Transformer相结合的模型
Transformer模仿大脑,在预测大脑成像上超越42个模型,还能够模拟感官与大脑之间的传输...
视觉Transformer中的输入可视化方法
当可变形注意力机制引入Vision Transformer
三大特征提取器(RNN/CNN/Transformer)
Swin Transformer对CNN的降维打击