《流畅的python》学习笔记及书评
Posted 李英俊小朋友
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《流畅的python》学习笔记及书评相关的知识,希望对你有一定的参考价值。
《流畅的python》学习笔记
文章目录
写在前面

-
读后感 优点:
-
翻译满昏!绝对满昏!💯,你看下面黄色部分,这翻译绝了,感觉我才是文化沙漠,什么“亲者快,仇者痛”,我这辈子没见过这么高级的用法。

-
我被作者举的例子惊到了(见2.4),真的很有水平,翻译和作者本身都很厉害
比如下面这一句
t = (1, 2, [30, 40]) t[2] += [50, 60]这两行代码的执行结果:
- 抛出异常:
因为 tuple 不支持对它的元素赋值,所以会抛出 TypeError 异常。 t[2]的值发生了修改:t = (1, 2, [30, 40, 50, 60])
- 抛出异常:
-
在讲排序的时候,讲到
sorted和list.sort背后使用的排序算法是Timsort,这个算法的作者是Tim Peters- 这个算法的相关代码在Google对Sun的侵权案中,当作了呈堂证供。
- 这个算法的作者也是
import this,python之禅的作者。 - 我靠,太离谱了,世界线收束,鸡皮疙瘩都起来了。
-
每一章的小结真的写的太好了,方便回顾这一章讲了啥,也方便自己查漏补缺。
-
延伸阅读也是惊艳啊,作者很明显博览群书,基础扎实。
-
作者吹了一波《Python Cookbook(第三版)》和《Python Cookbook(第二版)》,我准备去学习学习!
-
作者每章的小结写的很不错,每次因为知识点需要复查书籍的时候,可以先看对应章节的 本章小结 ,再查。
-
-
读后感 缺点:
-
读到11章和12章的时候,就开始有点吃力了,不知道是不是我的知识储备不够。一些抽象的知识点作者和翻译都有点力不从心(作为读者的角度),就是好像作者想把这个点用比喻的方式说清楚,但是又很难把他心中的理解表达出来,甚至很多地方都是直接进行教条化的描述,对于翻译来说,就更困难了。
【对不起,我面向对象学的太差了呜呜呜】
比如 P540 中:优先使用对象组合,而不是类继承,还有,组合和委托可以代替混入,把行为提供给不同的类,但是不能取代接口继承去定义类型层次结构。
对于 组合、委托、混入、继承等名词的解释不够到位,这几个名词,我就对继承还可以有深入的理解,其他的三个名词出现的时候,一脸懵逼
-
从16章协程开始,我就开始绝望了起来,有点整不明白,咬牙硬吃到18章asyncio的一些知识点的时候,就是懵懵懂懂的,在 yield 和 yield from 中学傻了。在18.5章的时候,不知道为什么突然出现了个semaphore,十分突兀,就开始不知所云了起来。
-
-
传送门:
1. Python数据模型
-
collections.nametuple:用来构建只有少数属性但是没有方法的对象,比如数据库条目。 -
__getitem__:方法可以实现切片效果def __getitem__(self, position): return self._cards[position]
1.1 特殊方法
-
如何使用特殊方法
-
首先,特殊方法的存在是为了被python解析器调用的,而不是被我们调用的
-
其次,
my_object.__len__()这种写法应该修正为len(my_object),在执行len(my_object)的时候,如果my_object是一个自定义类的对象,那么python会自己去调用其中的,由我们自己实现的__len__方法 -
如果是python内置的类型,如列表list、字符串str、字节序列bytearray等,Cpython会抄近道,
__len__实际上会直接返回PyVarObject里的ob_size属性。其中PyVarObject表示内存中长度可变的内置对象的C语言结构体。直接读取这个值比调用一个方法要快很多。
-
很多时候,特殊方法的调用是隐式的,比如
for i in x这个语句,背后其实调用的是iter(x),而这个函数的背后则是x.__iter__()方法。(前提是这个方法在x中被实现了) -
不要想当然的随意添加特殊方法,说不定以后python会用到这个名字。
-
-
repr:能把一个对象用字符串的形式表达出来以便辨认,「字符串表示形式」。__repr__所返回的字符串应该准确、无歧义,并且尽可能表达出如何用代码创建出这个被打印的对象。__repr__和__str__的区别在于,后者是在str()函数被使用,或者是在用print函数打印一个对象的时候才能被调用的,并且它返回的字符串对终端用户更友好。如果你只想实现这两个特殊方法中的一个,
__repr__是更好的选择,因为如果一个对象没有__str__函数,而 Python 又需要调用它的时候,解释器会用__repr__作为替代。 -
bool(x)的背后是调用x.__bool__()的结果;如果不存在__bool__方法,那么bool(x)会尝试调用x.__len__()。若返回 0,则 bool 会返回 False;否则返回True。 -
跟运算符无关的特殊方法
- 字符串/字节序列表示形式:
__repr__、__str__、__format__、__bytes__ - 数值转换:
__abs__、__bool__、__complex__、__int__、__float__、__hash__、__index__ - 集合模拟:
__len__、__getitem__、__setitem__、__delitem__、__contains__ - 迭代枚举:
__iter__、__reversed__、__next__ - 可调用模拟:
__call__ - 上下文管理器:
__enter__、__exit__ - 实例创建和销毁:
__new__、__init__、__del__ - 属性管理:
__getattr__、__getattribute__、__setattr__、__delattr__、__dir__ - 属性描述符:
__get__、__set__、__delete__ - 跟类相关的服务:
__prepare__、__instancecheck__、__subclasscheck__
- 字符串/字节序列表示形式:
-
跟运算符相关的特殊方pos法
- 一元运算符:
__neg__(-)、__pos__(+)、__abs__(abs()) - 众多比较运算符:
__lt__(<)、__le__(<=)、__eq__(==)、__ne__(!=)、__gt__(>)、__ge__(>=) - 算数运算符:
__add__(+)、__sub__(-)、__mul__(*)、__truediv__(/)、__floordiv__(//)、__mod__(%)、__divmod__(divmod())、__pow__(**或pow())、__round__(round()) - 反向算数运算符:
__radd__、__rsub__、__rmul__、__rtruediv__、__rfloordiv__、__rmod__、__rdivmod__ - 增量赋值算数运算符:
__iadd__、__isub__、__imul__、__itruediv__、__ifloordiv__、__imod__、__ipow__ - 位运算符:
__invert__(~)、__lshift__(<<)、__rshift__(>>)、__and__(&)、__or__(|)、__xor__(^) - 反向位运算符:
__rlshift__、__rrshift__、__rand__、__rxor__、__ror__ - 增量赋值位运算符:
__ilshift__、__irshift__、__iand__、__ixor__、__ior__
- 一元运算符:
-
为什么len不是一个普通方法:「实用胜于纯粹」,如果 x 是一个内置类型的实例,那么
len(x)的速度会非常快。背后的原因是 CPython 会直接从一个 C 结构体里读取对象的长度,完全不会调用任何方法。获取一个集合中元素的数量是一个很常见的操作,在
str、list、memoryview等类型上,这个操作必须高效。
换句话说,len 之所以不是一个普通方法,是为了让 Python 自带的数据结构可以走后门,abs 也是同理。但是多亏了它是特殊方法,我们也可以把 len 用于自定义数据类型
2. 序列构成的数组
2.1 内置序列类型
-
容器序列:list、tuple、collections.deque。可以存放不同类型的数据。
-
扁平序列:str、bytes、bytearray、memoryview、array.array。只能容纳一种类型。
-
容器序列存放的是它们所包含的任意类型的对象的引用,而扁平序列里存放的是值而不是引用。换句话说,扁平序列其实是一段连续的内存空间。由此可见扁平序列其实更加紧凑,但是它里面只能存放诸如字符、字节和数值这种基础类型。
-
可变序列:list、bytearray、array.array、collections.deque、memoryview
-
不可变序列:tuple、str、bytes
-
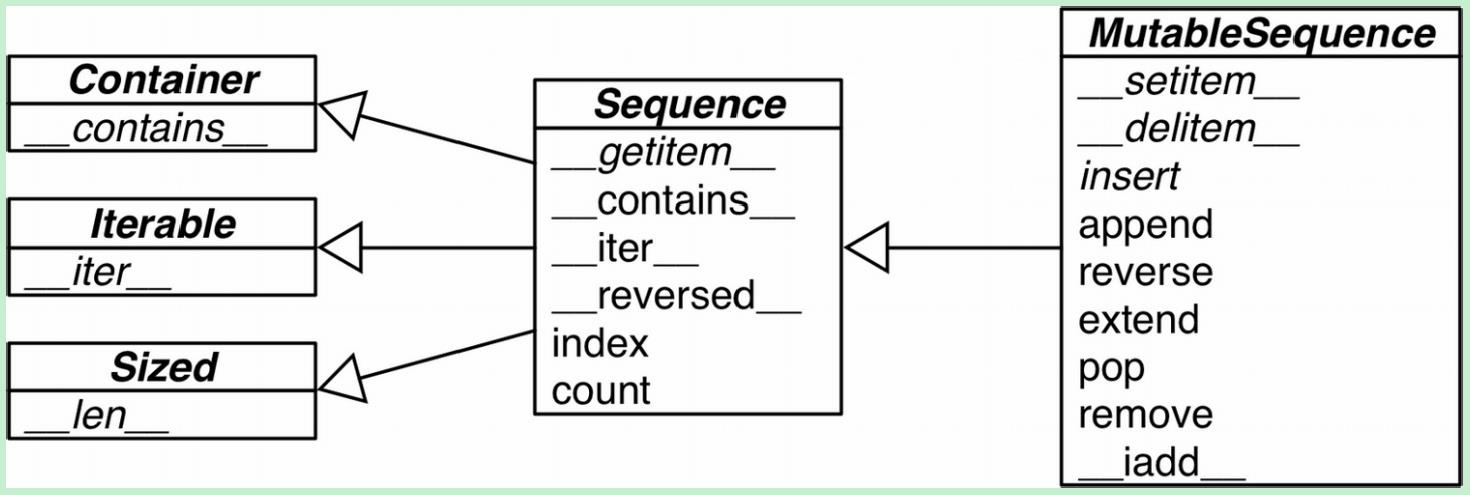
可变序列(MutableSequence)和不可变序列(Sequence)的差异
2.2 列表推导和生成器表达式
-
Python 会忽略代码里 []、{} 和 () 中的换行,因此如果你的代码里有多行的列表、列表推导、生成器表达式、字典这一类的,可以省略不太好看的续行符 \\。
-
列表推导不会再有变量泄漏的问题
x = 'ABC' dummy = [ord(x) for x in x] print(x, dummy) # ABC [65, 66, 67] -
生成器表达式的语法跟列表推导差不多,只不过把方括号换成圆括号而已。
2.3 元组不仅仅是不可变的列表
-
除了用作不可变的列表,它还可以用于没有字段名的记录。
-
元组其实是对数据的记录:元组中的每个元素都存放了记录中一个字段的数据,外加这个字段的位置。正是这个位置信息给数据赋予了意义。
-
在元组拆包中使用
*也可以帮助我们把注意力集中在元组的部分元素上。用*来处理剩下的元素a, b, *rest = range(5) print(a, b, rest) # 0 1 [2, 3, 4] -
在平行赋值中,
*前缀只能用在一个变量名前面,但是这个变量可以出现在赋值表达式的任意位置a, *body, c, d = range(5) print(a, body, c, d) # 0 [1, 2] 3 4 -
collections.namedtuple:创建一个具名元组需要两个参数,一个是类名,另一个是类的各个字段的名字。后者可以是由数个字符串组成的可迭代对象,或者是由空格分隔开的字段名组成的字符串。_fields:一个包含这个类所有字段名称的元组。_make():通过接受一个可迭代对象来生成这个类的一个实例,它的作用等价于类(*参数元组)是一样的。_asdict():把具名元组以collections.OrderedDict的形式返回,我们可以利用它来把元组里的信息友好地呈现出来。
-
列表、元组、数组、双向队列的方法和属性
方法和属性 列表 元组 数组 双向队列 描述 s.__add__(s2)√ √ √ × s+s2,拼接s.__iadd__(s2)√ × √ √ s+=s2,就地拼接s.append(e)√ × √ √ 在尾部添加一个新元素 s.appendleft(e)× × × √ 添加一个元素到最左侧(到第一个元素之前) s.byteswap× × √ × 翻转数组内每个元素的字节序列,转换字节序列 s.clear()√ × × √ 删除所有元素 s.__contains__(e)√ √ √ × s是否包含e s.copy()√ × × × 列表的浅复制 s.__copy__()× × √ √ 对 copy.copy(浅复制)的支持s.count(e)√ √ √ √ e在s中出现的次数 s.__deepcopy__()× × √ × 对 copy.deepcopy(深复制)的支持s.__delitem__(p)√ × √ √ 把位于p的元素删除 s.extend(it)√ × √ √ 把可迭代对象it追加给s s.extendleft(i)× × × √ 将可迭代对象i中的元素添加到头部 s.frombytes(b)× × √ × 将压缩成机器值得字节序列读出来添加到尾部 s.fromfile(f,n)× × √ × 将二进制文件f内含有机器值读出来添加到尾部,最多添加n项 s.fromlist(l)× × √ × 将列表里的元素添加到尾部,如果其中任何一个元素导致了 TypeError异常,那么所有的添加都会取消s.__getitem__()√ √ √ √ s[p],获取位置p的元素s.__getnewargs__()× √ × × 在pickle中支持更加优化的序列化 s.index(e)√ √ √ × 在s中找到元素e第一次出现的位置 s.insert(p,e)√ × √ × 在位置p之前插入元素e s.itemsize× × √ × 数组中每个元素的长度是几个字节 s.__iter__()√ √ √ √ 获取s的迭代器 s.__len__()√ √ √ √ len(s),元素的数量s.__mul__()√ √ √ × s*n,n个s的重复拼接s.__imul__()√ × √ × s*=n,就地重复拼接s.__rmul__()√ √ √ × n*s,反向拼接*s.pop([p])√ × √ √ 删除最后或者是(可选的)位于p的元素,并返回它的值(注意,在双向队列中不接受参数) s.popleft()× × × √ 移除第一个元素并返回它的值 s.remove(e)√ × √ √ 删除s中第一次出现的e s.reverse()√ × √ √ 就地把s的元素倒序排列 s.__reversed__√ × × √ 返回s的倒序迭代器 s.rotate(n)× × × √ 把n个元素从队列的一段移到另一端 s.__setitem__(p,e)√ × √ √ s[p]=e,把元素e放在位置p,替代已经在那个位置的元素s.sort([key],[reverse])√ × × × 就地对s中的元素进行排序,可选的参数有键(key)和是否倒序(reverse) s.tobytes()× × √ × 把所有元素的机器值用bytes对象的形式返回 s.tofile(f)× × √ × 把所有元素以机器值的形式写入一个文件 s.tolist()× × √ × 把数组转换成列表,列表里的元素类型是数字对象 s.typecode× × √ × 返回只有一个字符的字符串,代表数组元素在C语言中的类型
2.4 切片
-
为什么切片和区间会忽略最后一个元素:
在切片和区间操作里不包含区间范围的最后一个元素是 Python 的风格,这个习惯符合 Python、C 和其他语言里以 0 作为起始下标的传统。这样做带来的好处如下。
- 当只有最后一个位置信息时,我们也可以快速看出切片和区间里有几个元素:
range(3)和my_list[:3]都返回 3 个元素。 - 当起止位置信息都可见时,我们可以快速计算出切片和区间的长度,用后一个数减去第一个下标(stop - start)即可。
- 这样做也让我们可以利用任意一个下标来把序列分割成不重叠的两部分,只要写成
my_list[:x]和my_list[x:]就可以了。
- 当只有最后一个位置信息时,我们也可以快速看出切片和区间里有几个元素:
-
slice(a, b, c):对seq[start:stop:step]进行求值的时候,Python 会调用seq.__getitem__(slice(start, stop, step))。 -
slice(start, stop, step):使用方法a = slice(6, 40) item[a] -
多维切片:如果要得到
a[i, j]的值,Python 会调用a.__getitem__((i, j)) -
x[i, ...]:x[i, :, :, :]的缩写 -
给切片赋值:如果把切片放在赋值语句的左边,或把它作为
del操作的对象,我们就可以对序列进行 嫁接 、 切除 或 就地修改 操作。- 如果赋值的对象是一个切片,那么赋值语句的右侧必须是个可迭代对象。
- 即便只有单独一个值,也要把它转换成可迭代的序列。
2.5 增量赋值
-
+和*的陷阱:如果要生成二维序列:- 不能:
[['_']*3]*3 - 而要:
[['_']*3 for i in range(3)]
- 不能:
-
a += b- 如果a实现了
__iadd__方法,就相当于调用了a.extend(b) - 如果a没有实现
__iadd__的话,a += b就跟a = a + b一样了。首先计算a + b,得到一个新的对象,然后赋值给a。 - 也就是说,在这个表达式中,变量名会不会被关联到新的对象,完全取决于这个类型有没有实现
__iadd__方法。
- 如果a实现了
-
对不可变序列进行重复拼接操作的话,效率会很低,因为每次都有一个新对象,而解释器需要把原来对象中的元素先赋值到新的对象里,然后再追加新的元素。
str是一个例外,因为对字符串做+=实在是太普遍了,所以CPython对它做了优化,为str初始化内存的时候,程序会为它留出额外的可扩展空间,因此进行增量操作的时候,并不会涉及复制原有字符串到新位置这类操作。
2.6 排序
-
Python中的排序算法:Timesort 是稳定的,意思是就算两个元素比不出大小,在每次排序的结果里他们的相对位置是固定的。
-
list.sort:就地排序列表,也就是说不会把原列表复制一份,返回值为None -
sorted:会新建一个列表作为返回值 -
key参数能让你对一个混有数字字符和数值的列表进行排序。l = [28, 14, '28', 5, '9', '1', 0, 6, '23', 19] sorted(l, key=int) # [0, '1', 5, 6, '9', 14, 19, '23', 28, '28'] -
sorted和list.sort背后的排序算法是 Timsort,它是一种自适应算法,会根据原始数据的顺序特点交替使用插入排序和归并排序,以达到最佳效率。这样的算法被证明是很有效的,因为来自真实世界的数据通常是有一定的顺序特点的。 -
用
bisect来管理 已排序 的序列:二分法bisect函数其实是bisect_right函数的别名,后者还有个姊妹函数叫bisect_leftbisect_left返回的插入位置是原序列中跟被插入元素相等的元素的位置,也就是新元素会被放置于它相等的元素的前面bisect_right返回的则是跟它相等的元素之后的位置
-
利用
bisect进行评价分组def grade(score, breakpoints=[60, 70, 80, 90], grades='FDCBA'): i = bisect.bisect(breakpoints, score) return grades[i] [grade(score) for score in [33, 99, 77, 70, 89, 90, 100]] # ['F', 'A', 'C', 'C', 'B', 'A', 'A'] -
bisect.insort(seq, item)把变量item插入到序列seq中,并能保持seq的升序顺序。
2.7 数组、内存视图、NumPy和队列
- 如果我们需要一个只包含数字的列表,那么
array.array比list更高效。通过array.tofile和array.fromfile进行文件的保存和读取。 memoryview:是一个内置类,它能让用户在不复制内容的情况下操作同一个数组的不同切片。memoryview.cast的概念跟数组模块类似,能用不同的方式读写同一块内存数据,而且内容字节不会随意移动。memoryview.cast会把同一块内存里的内容打包成一个全新的memoryview对象给你。numpy:- 将一维数组转化为二维:
array.shape=(x, y) - 将数组转置:
array.T、array.transpose()
- 将一维数组转化为二维:
collections.deque类(双向队列)是一个线程安全、可以快速从两端添加或者删除元素的数据类型。dq = deque(range(10), maxlen=10),maxlen是一个可选参数,带别找个队列可以容纳的元素的数量。dq.rotate(n):队列的旋转操作接受一个参数n,当n>0时,队列的最右边的n个元素会被移动到队列的左边。当n<0时,最左边的n个元素会被移动到右边。append和popleft都是原子操作,也就说是 deque 可以在多线程程序中安全地当作先进先出的栈使用,而使用者不需要担心资源锁的问题。- 其他队列的实现:
queue提供了Queue、LifoQueue、PriorityQueue。在满员的时候,这些类不会扔掉旧的元素来腾出位置。相反,如果队列满了,它就会被锁住,直到另外的线程移除了某个元素而腾出了位置。这一特性让这些类很适合用来控制活跃线程的数量。multiprocessing实现了自己的Queue,跟queue.Queue相似,是涉及给进程间通信用的。multiprocessing.JoinableQueue可以让任务管理变得更方便。asyncio里面有Queue、LifoQueue、PriorityQueue、JoinableQueue,这些类受到queue和multiprocessing模块的影响,但是为异步编程里的任务管理提供了专门的便利。heapq没有队列类,而是提供了heappush和heappop方法,让用户可以把可变序列当作堆队列或者优先队列来使用。
- 列表倾向于存放有通用特性的元素;元组则恰恰相反,经常用来存放不同类型的元素。
3. 字典和集合
3.1 泛映射类型和字典推导
-
collections.abc模块中有Mapping和MutableMapping这两个抽象基类,它们的作用是为 dict 和其他类似的类型定义形式接口
-
可散列的数据类型(hashable)
如果一个对象是可散列的,那么在这个对象的生命周期中,它的散列值是不变的,而且这个对象需要实现
__hash__()方法。另外可散列对象还要有__eq__()方法,这样才能跟其他键做比较。如果两个可散列对象是相等的,那么它们的散列值一定是一样的。简单来说,如果一个对象是可散列的数据类型的话,那它应是不可变的。
-
list等可变对象是不可散列的,因为随着数据的改变他们的哈希值会变化导致进入错误的哈希表。
-
元组的话,只有当一个元组包含的所有元素都是可散列类型的情况下,它才是可散列的。
-
一般用户自定义的类型的对象都是可散列的,散列值就是它们的
id()函数的返回值,所以所有这些对象在比较的时候都是不相等的。如果一个对象实现了__eq__()方法,并且在方法中用到了这个对象的内部状态的话,那么只有当所有这些内部状态都是不可变的情况下,这个对象才是可散列的。 -
Python 里所有的不可变类型都是可散列的,这个说法其实是不准确的,比如虽然元组本身是不可变序列,它里面的元素可能是其他可变类型的引用。 -
字典推导:
{code: country.upper() for country, code in country_code.items() if code < 66}
3.2 常见的映射方法
dict、collections.defaultdict和collections.OrderedDict的方法列表
| 方法 | dict | defaultdict | OrderedDIct | 描述 |
|---|---|---|---|---|
d.clear() | √ | √ | √ | 移除所有元素 |
d.__contains__(k) | √ | √ | √ | 检查k是否在d中 |
d.copy() | √ | √ | √ | 浅复制 |
d.__copy()__ | × | √ | × | 用于支持copy.copy |
d.default_factory | × | √ | × | 在__missing__函数中被调用的函数,用以给未找到的元素设置值 |
d.__delitem__(k) | √ | √ | √ | del d[k],移除键位k的元素 |
d.fromkeys(it, [initial]) | √ | √ | √ | 将迭代器it里的元素设置为映射里的键,如果initial参数,就把它作为这些键对应的值(默认是None) |
d.get(k, [default]) | √ | √ | √ | 返回键k对应的值,如果字典里没有键k,则返回None或者default |
d.__getitem__(k) | √ | √ | √ | 让字典d能用d[k]的形式返回键k对应的值 |
d.items() | √ | √ | √ | 返回d里所有的键值对 |
d.__iter__() | √ | √ | √ | 获取键的迭代器 |
d.keys() | √ | √ | √ | 获取所有的键 |
d.__len__() | √ | √ | √ | 可以用len(d)的形式得到字典里键值对的数量 |
d.__missing__(k) | × | √ | × | 当__getitem__找不到对应键的时候,这个方法会被调用 |
d.move_to_end(k, [last]) | × | × | √ | 把键位k的元素移动到最靠前或者最靠后的位置(last的默认值是True) |
d.pop(k, [default]) | √ | √ | √ | 返回键k所对应的值,然后移除这个键值对。如果没有这个键,返回None或者default |
d.popitem() | √ | √ | √ | 随机返回一个键值对并从字典里移除它 |
d.__reversed__() | × | × | √ | 返回倒序的键的迭代器 |
d.setdefault(k, [default]) | √ | √ | √ | 若字典里有键k,则把它对应的值设置位default,然后返回这个值;若无,则让d[k]=default,然后返回default |
d.__setitem__ | √ | √ | √ | 实现d[k]=v操作,把k对应的值设为v |
d.update(m, [**kwargs]) | √ | √ | √ | m可以是映射或者键值对迭代器,用来更新d里对应的条目 |
d.values | √ | √ | √ | 返回字典里的所有值 |
-
用setdefault处理找不到的键
-
使用
d.get(k, default)来代替d[k],可以防止报错 -
字典处理优化
-
好的方法
my_dict.setdefault(key, []).append(new_value) -
差的方法
if key not in my_dict: my_dict[key] = [] my_dict[key].append(new_value) -
二者的效果是一样的,只不过后者至少要进行两次键查询——如果键不存在的话,就是三次,用
setdefault只需要一次就可以完成整个操作。
-
-
3.3 映射的弹性键查询
-
场景:有时候为了方便起见,就算某个键在映射里不存在,我们也希望在通过这个键读取值的时候能得到一个默认值。
-
方法:
-
collections.defaultdict类- 把list构造方法作为
default_factory来创建一个defaultdict - 如果在创建
defaultdict的时候没有指定default_factory,查询不存在的键会触发KeyError defaultdict里的default_factory只会在__getitem__里被调用,在其他的方法里完全不会发挥作用。比如dd[k]会创建默认值并返回该默认值,dd.get(k)就会返回None- 所有这一切的背后是基于特殊方法
__missing__实现的,它会在defaultdict遇到找不到的键的时候调用default_factory,而实际上这个特性是所有映射类型都可以选择去支持的
"""创建一个从单词到其出现情况的映射""" import sys import re from collections import defaultdict WORD_RE = re.compile(r'\\w+') # index = {} index = defaultdict(list) with open(sys.argv[1], encoding='utf-8') as fp: for line_no, line in enumerate(fp, 1): for match in WORD_RE.finditer(line): word = match.group() column_no = match.start() + 1 location = (line_no, column_no) ''' 这其实是一种很不好的实现,这样写只是为了证明论点 occurrences = index.get(word, []) occurrences.append(location) index[word] = occurrences ''' ''' 下面是好的实现,用到了setdefault函数 index.setdefault(word, []).append(location) ''' ''' 通过collections.defaultdict实现,取得key没有的时候,新建这个key,并赋予默认值''' index[word].append(location) # 以字母顺序打印出结果 for word in sorted(index, key=str.upper): print(word, index[word]) - 把list构造方法作为
-
自定义一个
dict子类,然后在子类中实现__missing__方法-
像
k in my_dict.keys()这种操作在Python3中是很快的,而且即便映射类型对象很庞大也没关系。这是因为dict.keys()的返回值是一个视图。 -
视图就像一个集合,而且跟字典类似的是,在视图里查找一个元素的速度很快。
class StrKeyDict0(dict): def __missing__(self, key): if isinstance(key, str): raise KeyError(key) return self[str(key)] def get(self, key, default=None): try: return self[key] except KeyError: return default def __contains__(self, key): return key in self.keys() or str(key) in self.keys()
-
-
3.4 字典的变种
-
collections.OrderedDict:这个类型在添加键的时候会保持顺序,因此键的迭代次序总是一致的。OrderedDict的popitem方法默认删除并返回的是字典里的最后一个元素,但是如果像my_odict.popitem(last=False)这样调用它,那么它删除并返回第一个被添加进去的元素。 -
collections.ChainMap:该类型可以容纳数个不同的映射对象,然后在进行键查找操作的时候,这些对象会被当作一个整体被逐个查找,直到键被找到为止。这个功能在给有嵌套作用域的语言做解释器的时候很有用,可以用一个映射对象来代表一个作用域的上下文。 -
collections.Counter:这个映射类型会给键准备一个整数计数器。每次更新一个键的时候都会增加这个计数器。所以这个类型可以用来给可散列表对象计数,或者是当成多重集来用——多重集合就是集合里的元素可以出现不止一次。 -
my_dict.most_common(n):统计字典中出现次数最多的数据ct = Counter({'a': 10, 'b': 2, 'r': 2, 'c': 1, 'd': 1, 'z': 3}) ct.most_common(2) # [('a', 10), ('z', 3)] -
colllections.UserDict:这个类其实就是把标准dict用纯 Python 又实现了一遍。跟OrderedDict、ChainMap和Counter这些开箱即用的类型不同,UserDict是让用户继承写子类的。- 更倾向于从
UserDict而不是从dict继承的主要原因是,后者有时会在某些方法的实现上走一些捷径,导致我们不得不在它的子类中重写这些方法,但是 UserDict 就不会带来这些问题。
- 更倾向于从
-
不可变映射类型:
types.MappingProxyType。如果给这个类一个映射,它会返回一个只读的映射视图。虽然是个只读视图,但是它是动态的。这意味着如果对原以上是关于《流畅的python》学习笔记及书评的主要内容,如果未能解决你的问题,请参考以下文章
《TensorFlow实战Google深度学习框架(第二版)》学习笔记及书评
《TensorFlow实战Google深度学习框架(第二版)》学习笔记及书评