2,一个人体姿态识别的项目实现
Posted 奋斗的Brandon
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2,一个人体姿态识别的项目实现相关的知识,希望对你有一定的参考价值。
文档说明:
参考链接:
http://codec.wang/#/opencv/start/02-basic-element-image
1,认识
简单地放几张图片感受一下,opencv识别的人体
本项目基于pycharm python3.6 和anaconda4.0做的,仅供参考


2,start,直接干货
先来看一下这三个函数:
加载图片,显示图片,保存图片
OpenCV函数:
cv2.imread(参数1,参数2), 如img = cv2.imread('IU.jpg',0)
加载成功显示图片,没有找到图片返回none,
参数1,照片名字如: xx.jpg
参数2:读入方式,省略即采用默认值
cv2.IMREAD_COLOR:彩色图,默认值(1)
cv2.IMREAD_GRAYSCALE:灰度图(0)
cv2.IMREAD_UNCHANGED:包含透明通道的彩色图(-1)
cv2.imshow(参数1,参数2),如:cv2.imshow('IU',img)
cv2.imwrite(),如cv2.imwrite('IU.jpg', img)
例子1
显示一个图片的灰度图,挑选一张图片保存到这个工程下面即可
# -*- coding: utf-8 -*-
import cv2
img = cv2.imread('IU.jpg',0)#加载成功显示图片,没有找到图片返回none,第二个参数0看最后几行介绍
cv2.namedWindow('IU', cv2.WINDOW_NORMAL)#建立一个IU的窗口,参数2默认是cv2.WINDOW_AUTOSIZE,表示窗口大小自适应图片,也可以设置为cv2.WINDOW_NORMAL,表示窗口大小可调整。图片比较大的时候,可以考虑用后者。
cv2.imshow('IU',img)
cv2.waitKey(0) #让窗口显示停留 参数是等待时间(毫秒ms)。时间一到,会继续执行接下来的程序,传入0的话表示一直等待
例子2
学习打开摄像头捕获照片、播放本地视频、录制视频等
打开摄像头并捕获照片
播放本地视频,录制视频
OpenCV函数:cv2.VideoCapture(), cv2.VideoWriter()
打开摄像头,并灰度化显示,键盘上按q退出
# 打开摄像头并灰度化显示
import cv2
capture = cv2.VideoCapture(0)
while(True):
# 获取一帧
ret, frame = capture.read()
# 将这帧转换为灰度图
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
cv2.imshow('frame', gray)
# 获取捕获的分辨率
# propId可以直接写数字,也可以用OpenCV的符号表示
width, height = capture.get(3), capture.get(4)
print(width, height)
# 以原分辨率的一倍来捕获
# capture.set(cv2.CAP_PROP_FRAME_WIDTH, width * 2)
# capture.set(cv2.CAP_PROP_FRAME_HEIGHT, height * 2)
if cv2.waitKey(1) == ord('q'):
break
灰度播放一段视频:
# 播放本地视频
capture = cv2.VideoCapture('demo_video.mp4')
while(capture.isOpened()):
ret, frame = capture.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
cv2.imshow('frame', gray)
if cv2.waitKey(30) == ord('q'):
break
录制视频:
capture = cv2.VideoCapture(0)
# 定义编码方式并创建VideoWriter对象
fourcc = cv2.VideoWriter_fourcc(*'MJPG')#FourCC是用来指定视频编码方式的四字节码。如MJPG编码可以这样写
outfile = cv2.VideoWriter('output.avi', fourcc, 25., (640, 480))#输出的文件名,如'output.avi'
编码方式FourCC,帧率FP,要保存的分辨率大小
while(capture.isOpened()):
ret, frame = capture.read()
if ret:
outfile.write(frame) # 写入文件
cv2.imshow('frame', frame)
if cv2.waitKey(1) == ord('q'):
break
else:
break
例子3
ROI
ROI:Region of Interest,感兴趣区域。什么意思呢?比如我们要检测眼睛,因为眼睛肯定在脸上,所以我们感兴趣的只有脸这部分,其他都不care,所以可以单独把脸截取出来,这样就可以大大节省计算量,提高运行速度。
获取图像的ROI区域,如获取下图图片左眼的区域

先找到眼睛区域的值:运行下面代码然后移动鼠标获取像素点的x,y的值并记录下来
我记录的x,y的值为:53,122 ————106,169
import cv2
img = cv2.imread('pic.jpg',1)
cv2.imshow('face', img)
cv2.waitKey(0)
然后切记img【先是y,后是x】,行对应y,列对应x,所以其实是img[y, x],需要注意噢(●ˇ∀ˇ●)。容易混淆的话,可以只记行和列,行在前,列在后。
import cv2
img = cv2.imread('pic.jpg',1)
p = img[ 120:170, 50:100]
cv2.imshow('face', p)
cv2.waitKey(0)

下一个例子
import cv2
img = cv2.imread('IU.jpg',1)
p = img[ 594:835, 270:595]
cv2.imshow('face', p)
# cv2.namedWindow('IU', cv2.WINDOW_NORMAL)
# cv2.imshow('IU',img) #先运行注释掉的代码,用鼠标缺点脸部区域的坐标
cv2.waitKey(0)

通过行列的坐标来获取某像素点的值,对于彩色图,结果是B,G,R三个值的列表,对于灰度图或单通道图,只有一个值:
px = img[100, 90]
print(px) # [103 98 197]
# 只获取蓝色blue通道的值
px_blue = img[100, 90, 0]
print(px_blue) # 103
例子4
提取下面这张图的蓝色部分
HSV是一个常用于颜色识别的模型,相比BGR更易区分颜色,转换模式用COLOR_BGR2HSV表示。
cv2.cvtColor()函数用来进行颜色空间转换,常用BGR↔Gray,BGR↔HSV。
HSV颜色模型常用于颜色识别。要想知道某种颜色在HSV下的值,可以将它的BGR值用cvtColor()转换得到。

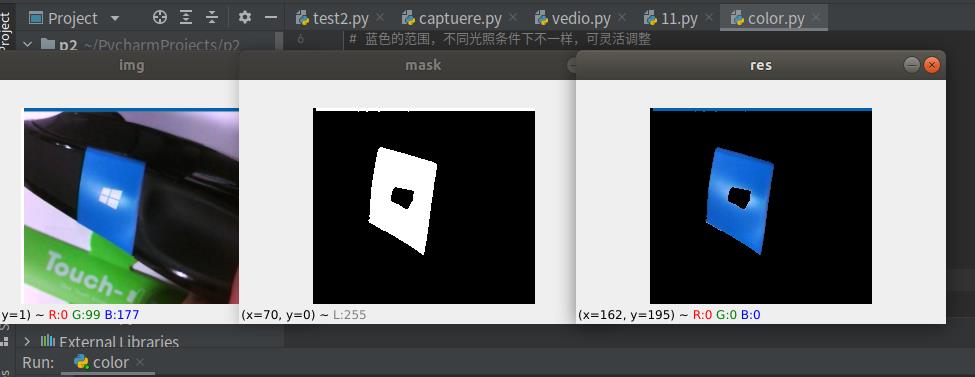
import cv2
import numpy as np
img = cv2.imread('color_blue.png',1) #图片导入
# 蓝色的范围,不同光照条件下不一样,可灵活调整
lower_blue = np.array([100, 110, 110])
upper_blue = np.array([130, 255, 255])
hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV) #BGR转HSV
mask = cv2.inRange(hsv, lower_blue, upper_blue) #inRange():介于lower/upper之间的为白色,其余黑色
res = cv2.bitwise_and(img, img, mask=mask)#只保留原图中的蓝色部分
cv2.imshow('img', img)
cv2.imshow('mask', mask)
cv2.imshow('res', res)
cv2.waitKey(0)
那蓝色的HSV值的上下限lower和upper范围是怎么得到的呢?其实很简单,我们先把标准蓝色的BGR值用cvtColor()转换下:
blue = np.uint8([[[255, 0, 0]]])
hsv_blue = cv2.cvtColor(blue, cv2.COLOR_BGR2HSV)
print(hsv_blue) # [[[120 255 255]]]
结果是[120, 255, 255],所以,我们把蓝色的范围调整成了上面代码那样。
例子5
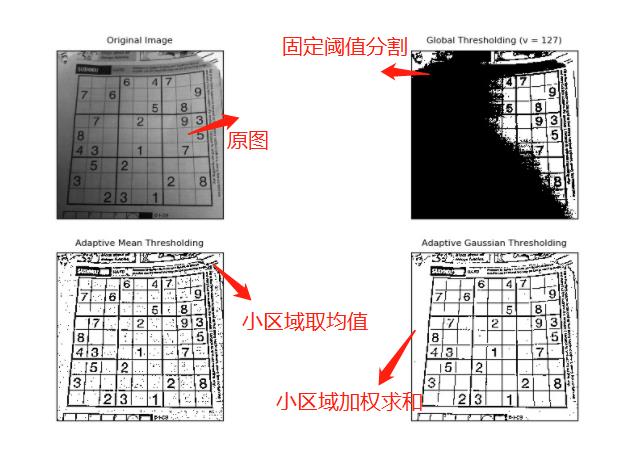
使用固定阈值、自适应阈值和Otsu阈值法"二值化"图像
固定阈值
分割很直接,一句话说就是像素点值大于阈值变成一类值,小于阈值变成另一类值。

自适应阈值
看得出来固定阈值是在整幅图片上应用一个阈值进行分割,它并不适用于明暗分布不均的图片。 cv2.adaptiveThreshold()自适应阈值会每次取图片的一小部分计算阈值,这样图片不同区域的阈值就不尽相同。
OpenCV函数:
cv2.threshold()#如:进行固定阈值分割,ret, th1 = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY)
cv2.adaptiveThreshold()#进行自适应阈值分割,它有6个参数,如th2 = cv2.adaptiveThreshold(
img, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 11, 4)
**cv2.threshold()**用来进行固定阈值分割。固定阈值不适用于光线不均匀的图片
所以用 cv2.adaptiveThreshold()进行自适应阈值分割。
二值化跟阈值分割并不等同。针对不同的图片,可以采用不同的阈值方法。
**cv2.threshold()**用来实现阈值分割,ret是return value缩写,代表当前的阈值,暂时不用理会。函数有4个参数:
参数1:要处理的原图,一般是灰度图
参数2:设定的阈值
参数3:对于THRESH_BINARY、THRESH_BINARY_INV阈值方法所选用的最大阈值,一般为255
参数4:阈值的方式,主要有5种
cv2.adaptiveThreshold()
参数1:要处理的原图
参数2:最大阈值,一般为255
参数3:小区域阈值的计算方式
ADAPTIVE_THRESH_MEAN_C:小区域内取均值
ADAPTIVE_THRESH_GAUSSIAN_C:小区域内加权求和,权重是个高斯核
参数4:阈值方法,只能使用THRESH_BINARY、THRESH_BINARY_INV,具体见前面所讲的阈值方法
参数5:小区域的面积,如11就是11*11的小块
参数6:最终阈值等于小区域计算出的阈值再减去此值
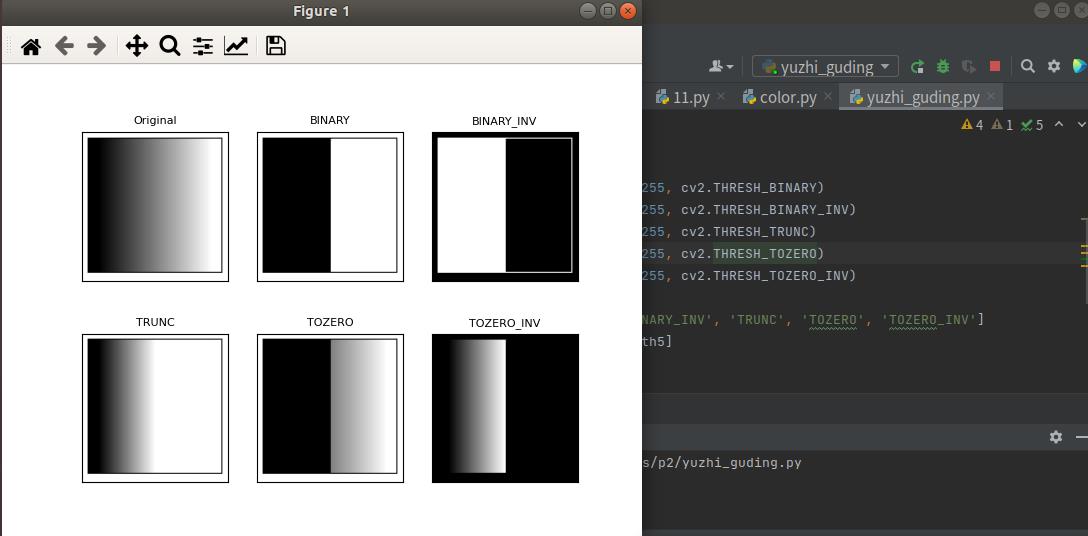
# 应用5种不同的阈值方法
ret, th1 = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY)//二分
ret, th2 = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY_INV)//倒置二分
ret, th3 = cv2.threshold(img, 127, 255, cv2.THRESH_TRUNC)//切割
ret, th4 = cv2.threshold(img, 127, 255, cv2.THRESH_TOZERO)//切割二分
ret, th5 = cv2.threshold(img, 127, 255, cv2.THRESH_TOZERO_INV)//倒置切割二分
分别为:'BINARY', 'BINARY_INV', 'TRUNC', 'TOZERO', 'TOZERO_INV'''
这五种阈值方式分别为:


——————————————————————————————
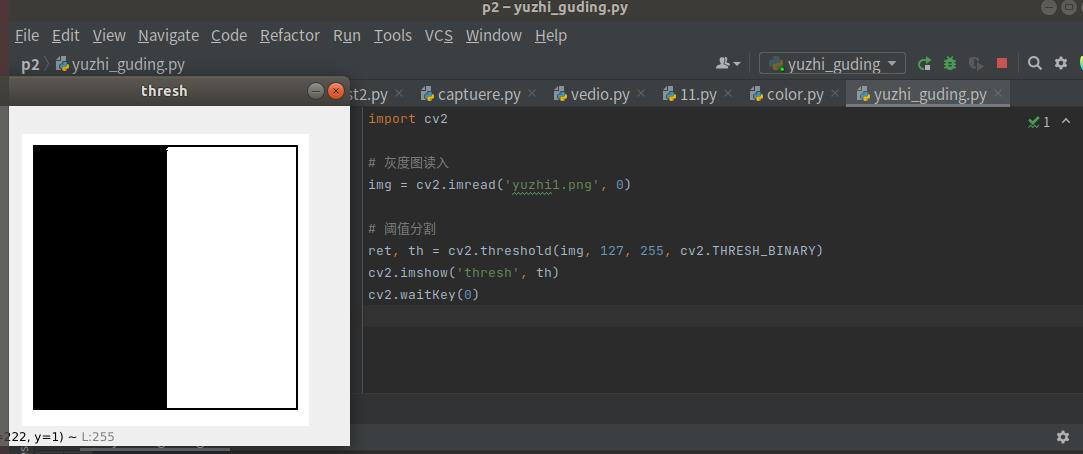
使用如下图片进行固定阈值分割:
import cv2
# 灰度图读入
img = cv2.imread('yuzhi1.png', 0)
# 阈值分割
ret, th = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY)#可更改127的值看看,参数2的值越小,黑色区域越少
cv2.imshow('thresh', th)
cv2.waitKey(0)

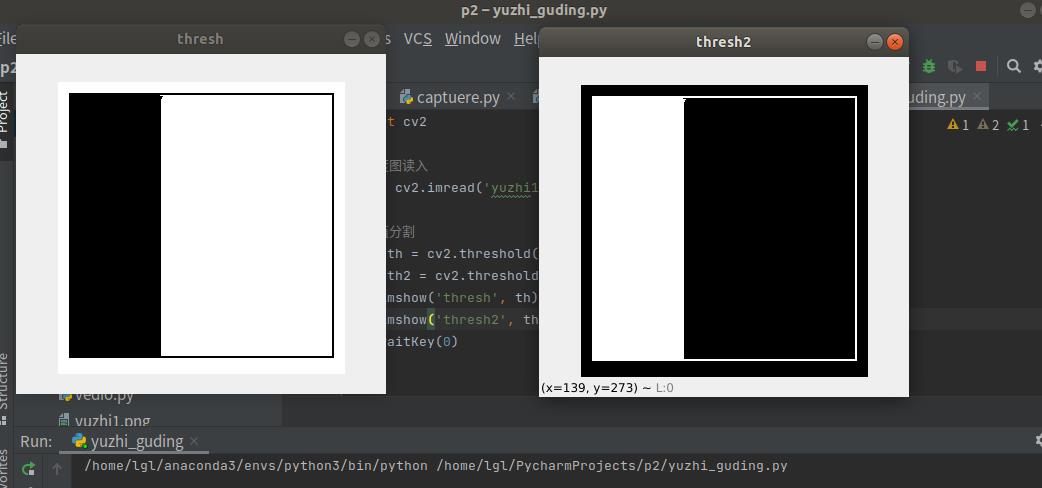
import cv2
# 灰度图读入
img = cv2.imread('yuzhi1.png', 0)
# 阈值分割
ret, th = cv2.threshold(img, 80, 255, cv2.THRESH_BINARY)
ret, th2 = cv2.threshold(img, 80, 255, cv2.THRESH_BINARY_INV)#倒置二分
cv2.imshow('thresh', th)
cv2.imshow('thresh2', th2)
cv2.waitKey(0)
先把代码复制进去,然后根据错误提示,点击波浪线安装matplotlib包即可。
import cv2
import matplotlib.pyplot as plt
# 灰度图读入
img = cv2.imread('yuzhi1.png', 0)
# 应用5种不同的阈值方法
ret, th1 = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY)
ret, th2 = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY_INV)
ret, th3 = cv2.threshold(img, 127, 255, cv2.THRESH_TRUNC)
ret, th4 = cv2.threshold(img, 127, 255, cv2.THRESH_TOZERO)
ret, th5 = cv2.threshold(img, 127, 255, cv2.THRESH_TOZERO_INV)
titles = ['Original', 'BINARY', 'BINARY_INV', 'TRUNC', 'TOZERO', 'TOZERO_INV']
images = [img, th1, th2, th3, th4, th5]
# 使用Matplotlib显示
for i in range(6):
plt.subplot(2, 3, i + 1)
plt.imshow(images[i], 'gray')
plt.title(titles[i], fontsize=8)
plt.xticks([]), plt.yticks([]) # 隐藏坐标轴
plt.show()
————————————————————————————————
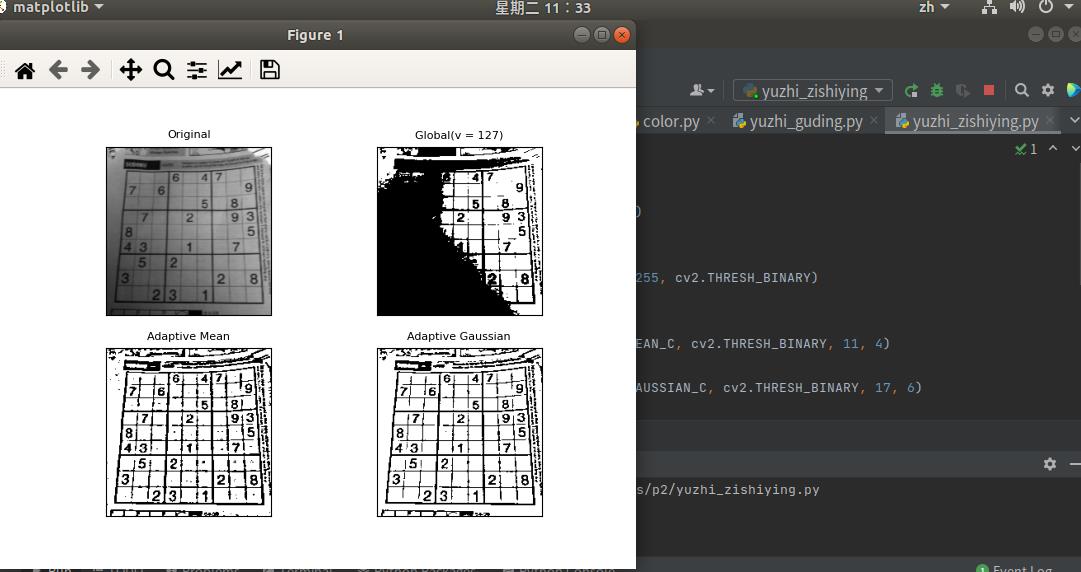
用自适应阈值来处理一个数独图片
————————————————————————————————
import cv2
import matplotlib.pyplot as plt
# 自适应阈值对比固定阈值
img = cv2.imread('zishiying.png', 0)
# 固定阈值
ret, th1 = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY)
# 自适应阈值
th2 = cv2.adaptiveThreshold(
img, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 11, 4)
th3 = cv2.adaptiveThreshold(
img, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 17, 6)
titles = ['Original', 'Global(v = 127)', 'Adaptive Mean', 'Adaptive Gaussian']
images = [img, th1, th2, th3]
for i in range(4):
plt.subplot(2, 2, i + 1), plt.imshow(images[i], 'gray')
plt.title(titles[i], fontsize=8)
plt.xticks([]), plt.yticks([])
plt.show()

以上是关于2,一个人体姿态识别的项目实现的主要内容,如果未能解决你的问题,请参考以下文章
二维已经 OUT 了?3DPose 实现三维人体姿态识别真香 | 代码干货