sklearn库学习----逻辑回归(LogisticRegression)使用详解
Posted iostreamzl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了sklearn库学习----逻辑回归(LogisticRegression)使用详解相关的知识,希望对你有一定的参考价值。
为什么需要逻辑回归
逻辑回归是由线性回归演变而来的一个分类算法,所以说逻辑回归对数据的要求比较高。对于分类器来说,我们前面已经学习了几个强大的分类器(决策树, 随机森林等),这些分类器对数据的要求没有那么高,那我们为什么还需要逻辑回归呢?主要在于逻辑回归有以下几个优势:
- 对线性关系的拟合效果好到丧心病狂:特征与标签之间的线性关系极强的数据,比如金融领域中的信用卡欺诈,评分卡制作,电商中的营销预测等等相关的数据,都是逻辑回归的强项。虽然现在有了梯度提升树GDBT,比逻辑回归效果更好,也被许多数据咨询公司启用,但逻辑回归在金融领域,尤其是银行业中的统治地位依然不可动摇
- 计算快 : 在大型数据集上的表现优于其他的分类器
- 抗噪能力强
重要参数
- penalty:指定正则化的参数可选为"l1", “l2” 默认为“l2”.
注意:l1正则化会将部分参数压缩到0,而l2正则化不会让参数取到0只会无线接近 - C : 大于0的浮点数。C越小对损失函数的惩罚越重
- multi_class : 告知模型要处理的分类问题是二分类还是多分类。默认为“ovr”(二分类)
- “multinational” : 表示处理多分类问题,在solver="liblinear"师不可用
- “auto” : 表示让模型自动判断分类类型
- solver:指定求解方式
| solver参数 | liblinear | lbfgs | newton-cg | sag | saga |
|---|---|---|---|---|---|
| 使用原理 | 梯度下降法 | 拟牛顿法的一种利用 损失函数二阶导数矩阵 来迭代优化损失函数 | 牛顿法的一种利用 损失函数二阶导数矩阵 来迭代优化损失函数 | 随机梯度下降 | 随机梯度下降的优化 |
| 支持的惩罚项 | L1,L2 | L2 | L2 | L2 | L1,L2 |
| 支持的回归类型 | |||||
| multinormal | 否 | 是 | 是 | 是 | 是 |
| ovr | 是 | 是 | 是 | 是 | 是 |
| 在大型数据集上速度 这里的快慢仅是内部比较 与外部比较逻辑回归仍然是比较快速的 | 慢 | 慢 | 慢 | 快 | 快 |
penalty参数示例
通过在乳腺癌数据集上的使用,来比较L1,L2参数求得的系数。
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_breast_cancer # 乳腺癌数据集
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
# 获得特征标签数据
data = load_breast_cancer()
X = data['data']
y = data['target']
# 分割训练姐测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
lr_l1 = LogisticRegression(penalty="l1", C=0.5, solver="liblinear")
lr_l2 = LogisticRegression(penalty="l2", C=0.5, solver="liblinear")
# 训练模型
lr_l1.fit(X_train, y_train)
lr_l2.fit(X_train, y_train)
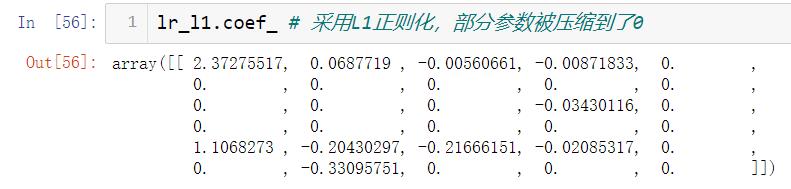
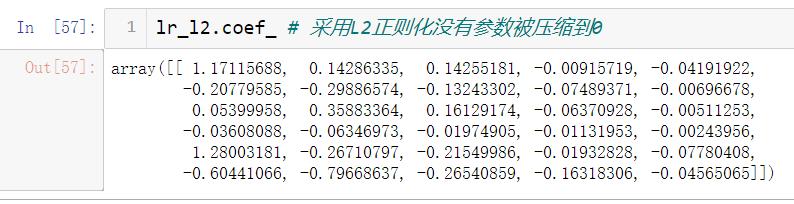
L1,L2的效果对比
# 训练集表现
l1_train_predict = []
l2_train_predict = []
# 测试集表现
l1_test_predict = []
l2_test_predict = []
for c in np.linspace(0.01, 2, 50) :
lr_l1 = LogisticRegression(penalty="l1", C=c, solver="liblinear", max_iter=1000)
lr_l2 = LogisticRegression(penalty='l2', C=c, solver='liblinear', max_iter=1000)
# 训练模型,记录L1正则化模型在训练集测试集上的表现
lr_l1.fit(X_train, y_train)
l1_train_predict.append(accuracy_score(lr_l1.predict(X_train), y_train))
l1_test_predict.append(accuracy_score(lr_l1.predict(X_test), y_test))
# 记录L2正则化模型的表现
lr_l2.fit(X_train, y_train)
l2_train_predict.append(accuracy_score(lr_l2.predict(X_train), y_train))
l2_test_predict.append(accuracy_score(lr_l2.predict(X_test), y_test))
data = [l1_train_predict, l2_train_predict, l1_test_predict, l2_test_predict]
label = ['l1_train', 'l2_train', 'l1_test', "l2_test"]
color = ['red', 'green', 'orange', 'blue']
plt.figure(figsize=(12, 6))
for i in range(4) :
plt.plot(np.linspace(0.01, 2, 50), data[i], label=label[i], color=color[i])
plt.legend(loc="best")
plt.show()
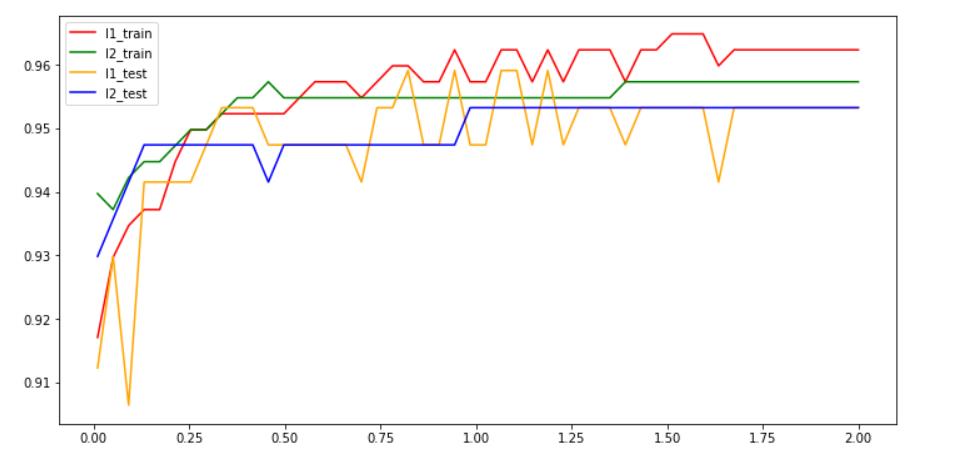
一般情况下使用l2.在l2表现不好的时候考虑换l1尝试。具体实际中看个人的需求来选择使用哪个参数。
处理多多分类问题
将multi_class参数设置为multinational,或者auto即可。注意在使用multinational参数时,solver不能为liblinear。否则会报错。
# 导入鸢尾花数据集
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score
iris = load_iris()
X = iris.data
y = iris.target
# 将multi_class设置为multinational,solver设置为liblinear出现保存
# lr = LogisticRegression(penalty='l2', solver='liblinear', max_iter=1000, multi_class="multinomial")
# 出错:ValueError: Solver liblinear does not support a multinomial backend.
lr = LogisticRegression(C=0.5, penalty='l2', solver='sag', multi_class="auto", max_iter=2000)
score = cross_val_score(lr, X, y, cv=10).mean()
score # 0.9666666666666666
总结
本篇文章只是讲了逻辑回顾的简单使用,以及其中的几个重要的参数。文中没有涉及到任何的数学原理。逻辑回顾的数学原理相当的复杂难懂,感兴趣的小伙伴可以自行百度查看。
以上是关于sklearn库学习----逻辑回归(LogisticRegression)使用详解的主要内容,如果未能解决你的问题,请参考以下文章