我,谷歌AI编舞师,能根据音乐来10种freestyle,想看霹雳还是爵士芭蕾?
Posted QbitAl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了我,谷歌AI编舞师,能根据音乐来10种freestyle,想看霹雳还是爵士芭蕾?相关的知识,希望对你有一定的参考价值。
丰色 发自 凹非寺
量子位 报道 | 公众号 QbitAI
Transformer又又接新活了——
这次谷歌用它搞了一个会根据音乐跳舞的AI。
话不多说,先让它给大家来几段freestyle(戴上耳机,沉浸式的):
嗯,动作还挺美观,各种风格也驾驭住了。
看着我都想跟着来一段。
你pick哪个 ?
?
而这个AI也凭借着对音乐和舞蹈之间的关联的深刻理解,打败了3个同类模型取得SOTA,登上了ICCV 2021。

另外,除了代码开源,研究团队还随之一起公开了一个含有10种类型的3D舞蹈动作数据集。
心动的,搞起来搞起来!
这个freestyle怎么来?
前面咱们不是说,这个AI用了Transformer吗?
但这里的Transformer不是普通的Transformer,它是一个基于完全注意力机制(Full-Attention)的跨模态Transformer,简称FACT。
为什么要搞这么复杂?
因为研究人员发现,光用单纯的Transformer并不能让AI理解音乐和舞蹈之间的相关性。

所以,这个FACT是怎么做的呢?
总的来说,FACT模型采用了独立的动作和音频transformer。
首先输入2秒钟的seed动作序列和一段音频,对其进行编码。
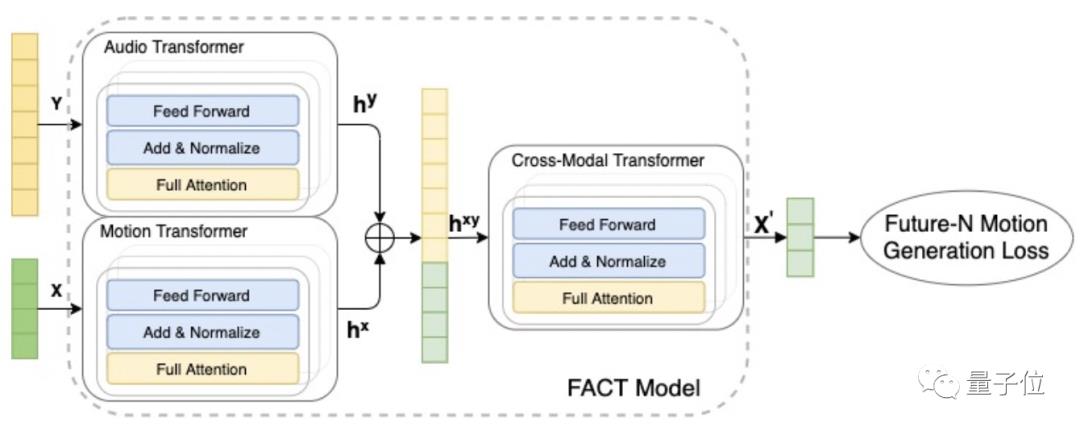
然后将embedding(从语义空间到向量空间的映射)连接起来,送入跨模态transformer学习两种形态的对应关系,并生成n个后续动作序列。
这些序列再被用来进行模型的自监督训练。
其中3个transformer一起学习,采用的是不用预处理和特征提取,直接把原始数据扔进去得到最终结果的端到端的学习方式。
另外就是在自回归框架中进行模型测试,将预期运动作为下一代阶段的输入。
最终,该模型可以逐帧地生成一段(long-range)舞蹈动作。
下图则展示了该模型通过同一段种子动作(嘻哈风格)、不同音乐生成了四种舞蹈作品(霹雳舞、爵士芭蕾、Krump和Middle Hip-hop)。
有没有懂行的点评一下?
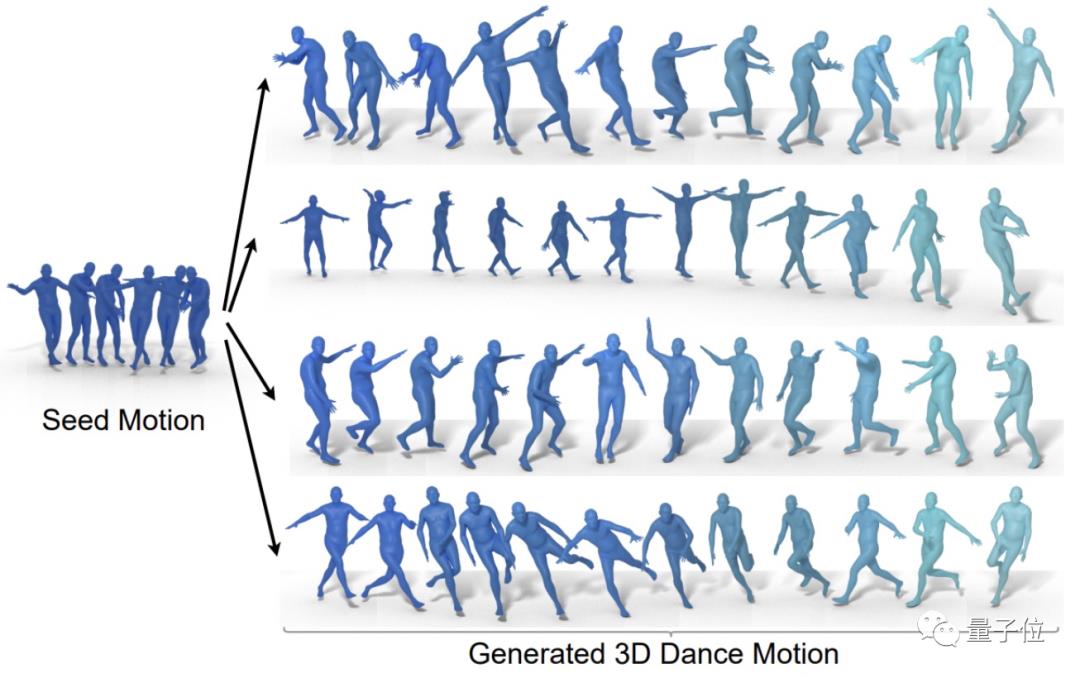
而为了让AI生成的舞蹈生动且和音乐风格保持一致,这个模型设计里面有3个关键点:
1、模型内部token可以访问所有输入,因此三个transformer都使用一个完全注意力mask。这使得它比传统的因果模型更具表现力。
2、不止预测下一个,该模型还预测N个后续动作。这有助于模型关注上下文,避免在几个生成步骤后出现动作不衔接和跑偏的情况。
3、此外,在训练过程的前期还用了一个12层深的跨模态transformer模块来融合两个embedding(音频和动作)。研究人员表示,这是训练模型倾听分辨输入音乐的关键。
下面就用数据来看看真实性能。
打败3个SOTA模型
研究人员根据三个指标来评估:
1、动作质量:用FID来计算样本(也就是他们自己发布的那个数据集,后面介绍)和生成结果在特征空间之间的距离。一共用了40个模型生成的舞蹈序列,每个序列1200帧(20秒)。
FID的几何和动力学特性分别表示为FIDg和FIDk。
2、动作多样性:通过测量40套生成动作在特征空间中的平均欧氏距离(Euclidean distance)得出。
分别用几何特征空间Distg和动力学特征空间k来检验模型生成各种舞蹈动作的能力。
3、动作与音乐的相关性:没有好的已有指标,他们自己提出了一个“节拍对齐分数”来评估输入音乐(音乐节拍)和输出3D动作(运动节拍)之间的关联。
下面是FACT和三种SOTA模型(Li等人的、Dancenet、Dance Revolution)的对比结果:
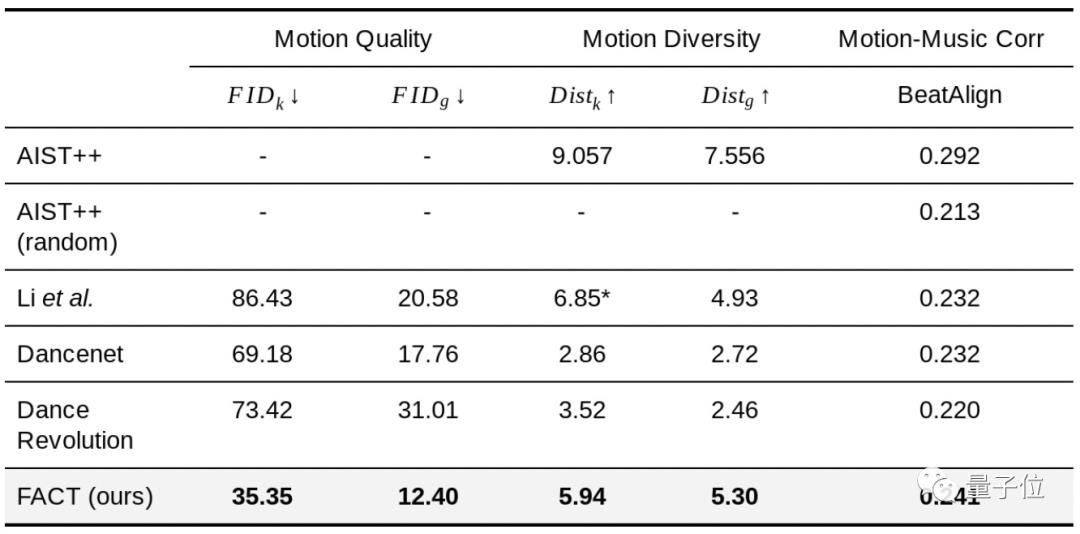
可以看到,FACT在三项指标上全部KO了以上三位。
*由于Li等人的模型生成的动作不连续,所以它的平均动力学特征距离异常高,可以忽略。
看了数据,咱们再看个更直观的:
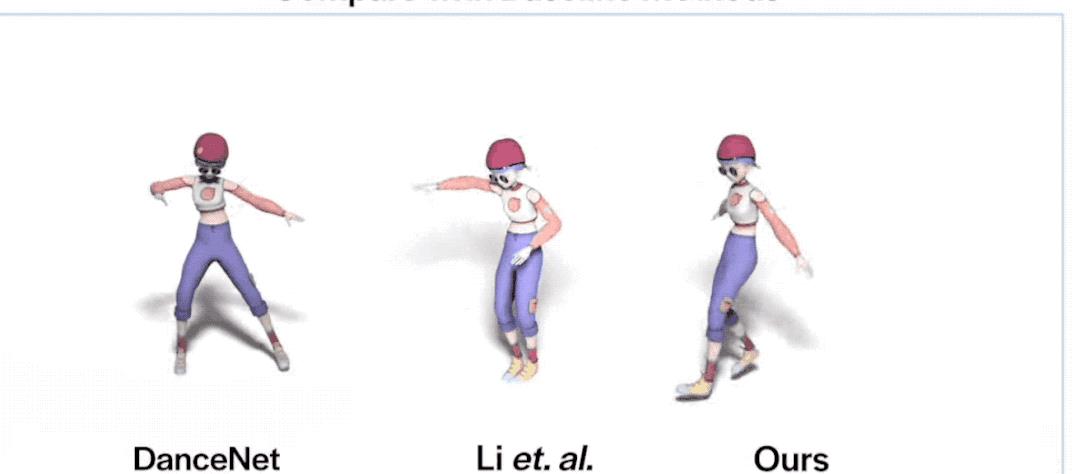
emmm,相比动作灵活的FACT,其他两位看起来都有点“不太聪明”的亚子……

舞蹈动作数据集AIST++
最后,再来简单介绍一下他们自己打造的这个3D舞蹈动作数据集AIST++。
看名字你也发现了,这是基于现有的舞蹈数据集AIST的“加强版”,主要是在原有基础上加上了3D信息。
最终的AIST++一共包含5.2小时、1408个序列的3D舞蹈动作,跨越十种舞蹈类型,包括老派和新派的的霹雳舞、Pop、 Lock、Waack,以及Middle Hip-Hop、LA-style Hip-Hop、House、Krump、街头爵士和爵士芭蕾,每种舞蹈类型又有85%的基本动作和15%的高级动作。
(怎么感觉全是街舞啊?)
每个动作都提供了9个相机视角,下面展示了其中三个。

它可以用来支持以下三种任务:多视角的人体关键点估计;人体动作预测/生成;人体动作和音乐之间的跨模态分析。
团队介绍
一作李瑞龙,UC伯克利一年级博士生,UC伯克利人工智能研究室成员,Facebook Reality Labs学生研究员。
研究方向是计算机视觉和计算机图形学的交叉领域,主要为通过2D图像信息生成和重建3D世界。
读博之前还在南加州大学视觉与图形实验室做了两年的研究助理。
本科毕业于清华大学物理学和数学专业、硕士毕业于计算机专业,曾在Google Research和字节AI Lab实习。

共同一作Yang Shan,就职于Google Research。

研究方向包括:应用机器学习、多模态感知、3D计算机视觉与物理仿真。
博士毕业于北卡罗来纳大学教堂山分校(UNC,美国8所公立常春藤大学之一)。
David A. Ross,在Google Research领导Visual Dynamics研究小组。
加拿大多伦多大学机器学习和计算机视觉专业博士毕业。

Angjoo Kanazawa,马里兰大学博士毕业,现在是UCB电气工程与计算机科学系的助理教授,在BAIR领导旗下的KAIR实验室,同时也是Google Research的研究员。

最最后,再来欣赏一遍AI编舞师的魅力吧:
论文:
https://arxiv.org/abs/2101.08779
GitHub:
https : //github.com/google-research/mint
数据集:
https://google.github.io/aistplusplus_dataset/
项目主页:
https://google.github.io/aichoreographer/
参考链接:
[1]https://www.marktechpost.com/2021/09/15/google-ai-introduces-full-attention-cross-modal-transformer-fact-model-and-a-new-3d-dance-dataset-aist/
[2]https://ai.googleblog.com/2021/09/music-conditioned-3d-dance-generation.html
以上是关于我,谷歌AI编舞师,能根据音乐来10种freestyle,想看霹雳还是爵士芭蕾?的主要内容,如果未能解决你的问题,请参考以下文章
谷歌推出全能扒谱AI:只要听一遍歌曲,钢琴小提琴的乐谱全有了
苹果开年第一购!买下仅24名员工的AI音乐公司,可根据环境动态生成音乐