谷歌AI练习生写了首歌,网友听完心率都低了
Posted QbitAl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了谷歌AI练习生写了首歌,网友听完心率都低了相关的知识,希望对你有一定的参考价值。
杨净 衡宇 发自 凹非寺
量子位 | 公众号 QbitAI
一段话整出一首歌,甚至是男女唱(跳)rap的那种。
谷歌最新模型MusicLM一经推出就惊艳四座,不少网友惊呼:这是迄今听到最好的谱曲。

它可以根据文本生成任何类型的音乐,不管是根据时间、地点、年代等各种因素来调节,还是给故事情节、世界名画配乐、生成人声rap口哨,通通不在话下。
比如这幅《呐喊》(Scream)

在一段摘自百科的说明提示下,它生成了这样一段音乐。
(蒙克在一次幻觉经历中感受到并听到了整个自然界的尖叫声,它的灵感来源于此,描绘了一个惊慌失措的生物,既像尸体又让人联想到精子或胎儿,其轮廓与血红色天空的旋涡线条相呼应。)
ViT(Vision Transformer)作者在听过一段关键词含“平静舒缓”“长笛和吉他”的生成音乐后,表示自己真的平静下来。
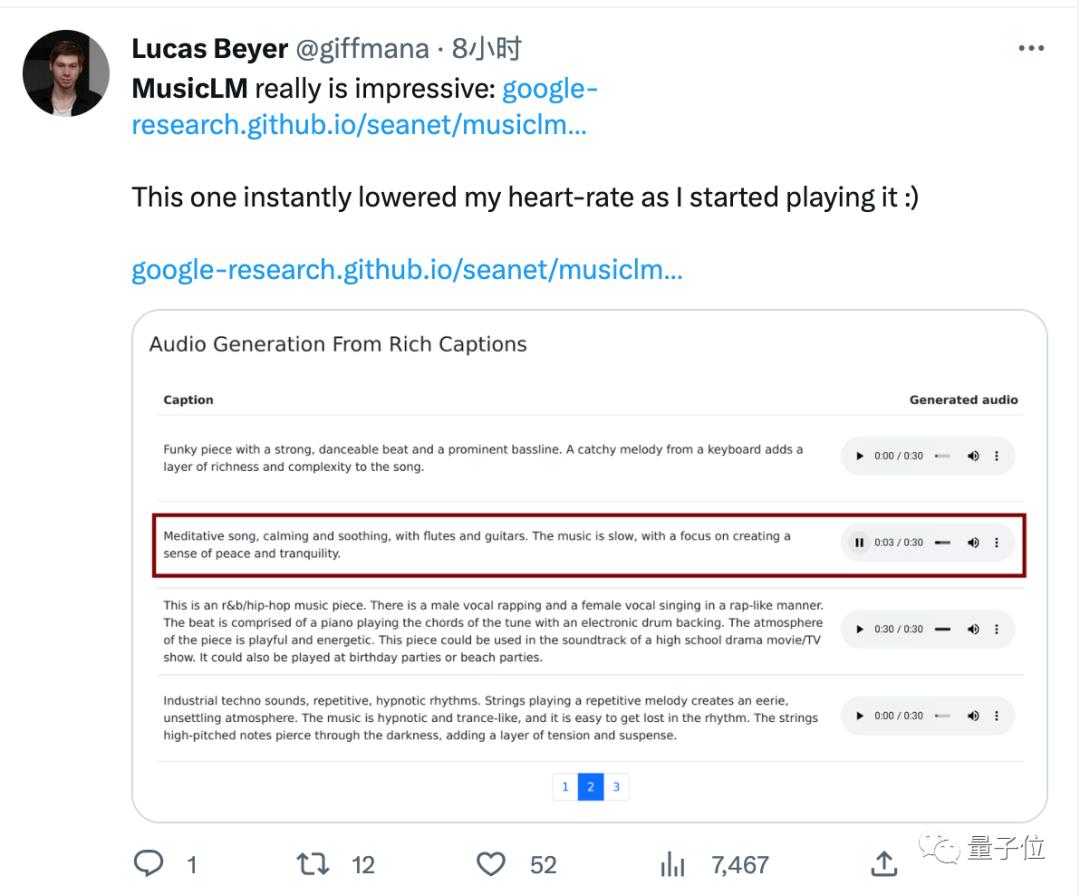
也不免有同行表示,这对我来说比ChatGPT更值得关注,谷歌几乎解决了音乐生成的问题。
毕竟MusicLM背靠280000小时音乐的训练数据库,事实上从现释出的Demo来看,MusicLM的能力还不止如此。
还可以5分钟即兴创作
可以看到,MusicLM最大的亮点莫过于就是根据丰富的文字描述来生成音乐,包括乐器、音乐风格、适用场景、节奏音调、是否包括人声(哼唱、口哨、合唱)等元素,以此来生成一段30秒的音乐。
即便说的只是那种说不清道不明的氛围,“迷失在太空”、“轻松而悠闲”;又或者是直接用在一些实用场景上,比如“街机游戏配乐”、给绘画配乐等。
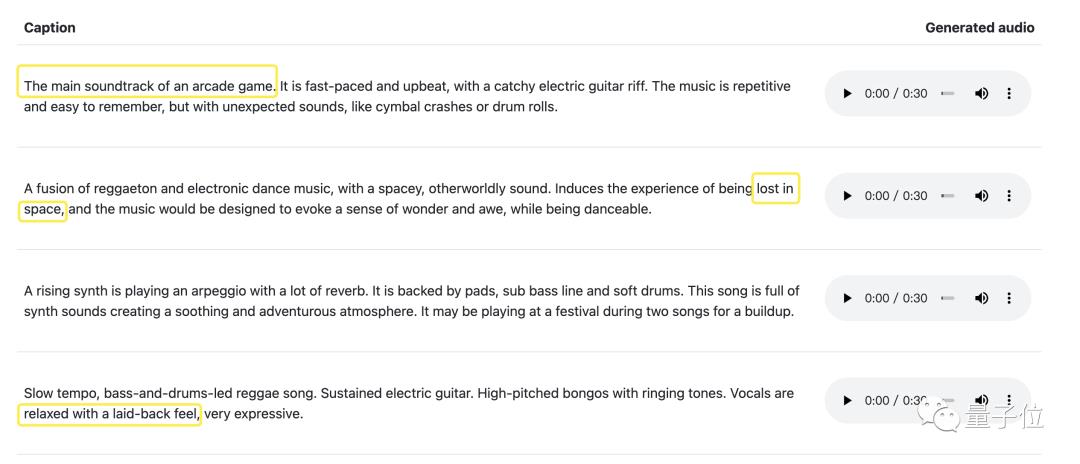
除此之外,MusicLM具备长段音乐创作、故事模式、调节旋律等方面的能力。
在长段音乐方面, 它能完成5分钟即兴创作,即便提示只有一个词。
比如仅在Swing(摇摆)的提示下,听着真就有种想马上下班去跳舞的冲动。(bushi)
而在故事模式中,不同的情标记甚至可以精确到秒的生成,哪怕情境之间完全没有任何联系……
游戏中播放的歌曲(0到15秒)——河边播放的冥想曲(15到20秒)——火(0:30-0:45)——烟花(0:45-0:60 )
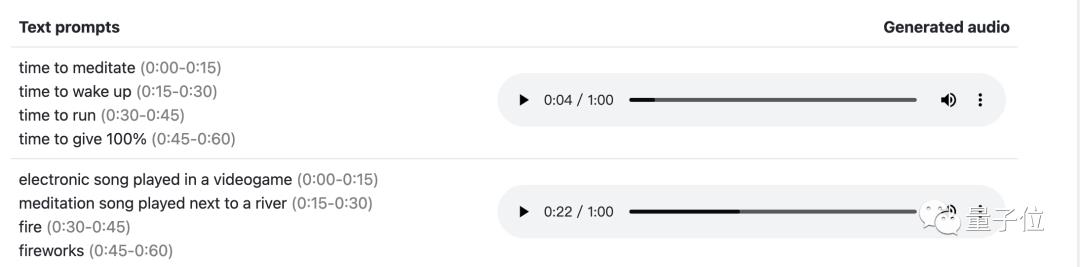
更让人惊艳到的是,它还有很强的实用性功能。
一方面,它可以将旋律的提示结合进文本提示当中去,这样一来可以更精细地来调整音乐。有点改甲方爸爸需求那味了。
另一方面,它还能根据具体的乐器、地点、流派、年代、甚至是音乐家演奏水平等文本来生成。

背后生成模型MusicLM
但有一说一,AI生成音乐模型不在少数,谷歌自己此前也推出有类似的模型AudioLM。
此番MusicLM究竟有何不同?

据研究团队介绍,贡献主要有三个方面:
生成模型MusicLM。
把方法扩展到其他条件信号,如根据文本提示合成的旋律,并生成5分钟的demo。
发布了首个专门为文本-音乐生成任务评估数据集MusicCaps。
首先,MusicLM正是基于谷歌三个月前提出AudioLM模型的拓展。
AudioLM不需要转录或标记,只需收听音频,AudioLM就能生成和提示风格相符的连贯音乐,包括钢琴音或人声对话等复杂声音。
而最新的MusicLM,就是利用了AudioLM的多阶段自回归建模作为生成条件,且以此为基础进行拓展,使其可以通过文本提示来生成和修改音乐。
它是一个分层的序列到序列(Sequence-to-Sequence)模型,可以通过文本描述,以24kHz的频率生成音乐,并在几分钟内保持这个频率。
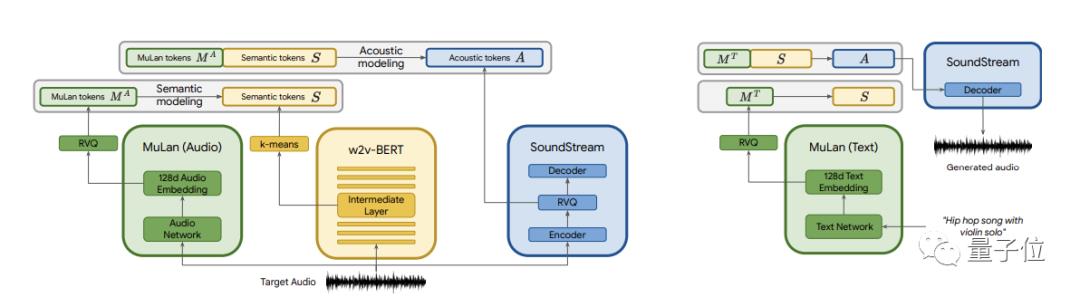
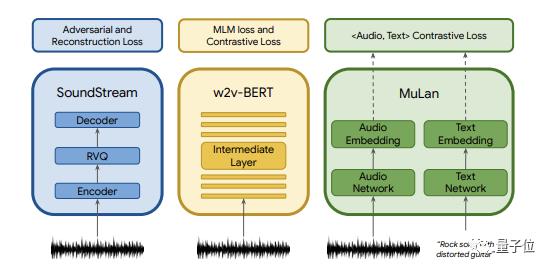
具体而言,研究团队使用了三个模型来用来预训练,包括自监督音频表征模型SoundStream,它可以以低比特率压缩一般音频,同时保持高重建质量。
还有语义标记模型w2vBERT,促进连贯生成;音频文本嵌入模型Mulan,它可以将音乐及其对应的文本描述投射到嵌入空间(以消除在训练时对文本的不同需求),并允许纯音频语料库上进行训练,以此来应对训练数据有限的难题。
训练过程中,他们从纯音频训练集中提取MuLan音频标记、语义标记和声学标记。
在语义建模阶段,他们用MuLan音频标记作为条件来预测语义标记。随后在声学建模阶段,又基于MuLan音频标记和语义标记来预测声学标记。
每个阶段都被建模为一个序列-序列任务,均使用单独解码器Transformer。
在推理过程中,他们使用从文本提示中计算出的MuLan文本标记作为调节信号,并使用SoundStream解码器将生成的音频标记转换成波形。
在280000个小时的训练后,MusicLM最终学会了保持24kHz的频率生成音乐,哪怕用来生成音乐的文本非常绕口。
类似“迷人的爵士歌曲与令人难忘的萨克斯独奏和独奏歌手”或“柏林90年代低音和强烈的电子乐”之类的。

研究团队还引入了一个高质量音乐数据集MusicCaps来解决任务缺乏评估数据的问题。
MusicCaps由专业人士共建,涵盖5500个音乐-文本对。研究团队公布了这个数据集,方便大伙进一步的研究。
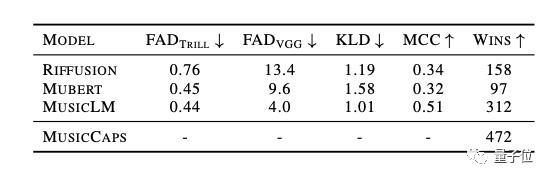
这么一套操作下来,通过定量指标和人工评估,MusicLM在音频质量和文本契合度等方面都优于此前的音乐生成AI。
不过,谷歌研究团队说了:目前没有对外发布MusicLM的计划。
原因很简单,除了训练过程中难免出现的样本质量失真,最最关键的还有2点。
一来,尽管MusicLM在技术上可以生成合唱和声等人声,但是仔细听来,生成音乐的歌词,有的还勉勉强强听得出是音乐,有的根本就是无人能听懂的外星方言。
再者,研究团队发现系统生成的音乐中,约有1%直接从训练集的歌曲中复制——这已经足以阻止对外发布MusicLM了。
此外,还有批评者质疑,在受版权保护的音乐素材上训练AI模型到底合不合理。

不过团队在论文中介绍了下一步动向,主要关注歌词生成、改善提示文本准确性以及提高生成质量。
复杂音乐结构的建模也将成为团队的重点关注方向之一。
音频生成AI
这个研究的背后团队,是谷歌研究院。
共同一作Timo I. Denk,是谷歌瑞士的软件工程师,每天的工作就是利用ML进行音乐理解。

在这里多说两句,MusicLM的论文中,研究团队提到,MusicLM在质量和提示依从性方面都优于以前的系统。
“以前的系统”包括哪些?
一个是Mubert,已在Github开源API,是一个text-to-music的AI,系列产品有根据既有标签生成音乐的Mubert Render、听歌软件Mubert Play等。
还有Riffusion,它建立在AI绘图的基础上,但将其应用于声音。
换句话说,Riffusion的工作原理是首先构建一个索引的频谱图集合,上面标记代表频谱图中捕获的音乐风格的关键字。
在频谱图主体上训练时,Riffusion就用Stable Diffusion的同一个方法——干预噪音,来获得与文本提示匹配的声波图像。
还有针对音乐制作人和音乐家的 AI 音频生成工具Dance Diffusion,OpenAI推出的可自动生成音乐的ML框架Jukebox……
要咱说,别成天盯着ChatGPT了,AIGC下一个风口万一是音乐生成呢?
参考链接:
[1]https://google-research.github.io/seanet/musiclm/examples/
[2]https://arxiv.org/pdf/2301.11325.pdf
[3]https://techcrunch.com/2023/01/27/google-created-an-ai-that-can-generate-music-from-text-descriptions-but-wont-release-it/
— 完 —
量子位红包封面限量发放
最后一次补货红包封面啦!两款任选,先到先得~
扫描下方二维码即可领取量子位人类编辑与Stable Diffusion共同创作的红包封面噢 


点这里👇关注我,记得标星哦~
以上是关于谷歌AI练习生写了首歌,网友听完心率都低了的主要内容,如果未能解决你的问题,请参考以下文章
谷歌研究员走火入魔认为AI已具备人格,被带薪休假,聊天记录让网友炸了