canal 源码解析系列-canal的HA机制解析
Posted 犀牛饲养员
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了canal 源码解析系列-canal的HA机制解析相关的知识,希望对你有一定的参考价值。
引言
首先什么是HA?HA指的是High Available,也就是高可用。通常我们一个服务要支持HA都要借助于第三方的分布式同步协调服务,最常用的是zookeeper(以下简称ZK)。canal实现高可用,主要是依赖了zookeeper的几个特性,watcher和EPHEMERAL节点。
正文
canal的整个HA机制,分为两部分。canal server和client都要有对应的实现。
首先在server端,为了减少对mysql dump的请求,不同server上的instance要求同一时间只能有一个处于running,其他的处于standby状态。也就是说,只会有一个canal server的instance处于active状态,但是当这个instance down掉后会重新选出一个canal server。
在client端,为了保证有序性,一个instance同一时间只能由一个canal client进行get/ack/rollback操作,否则客户端接收无法保证有序。
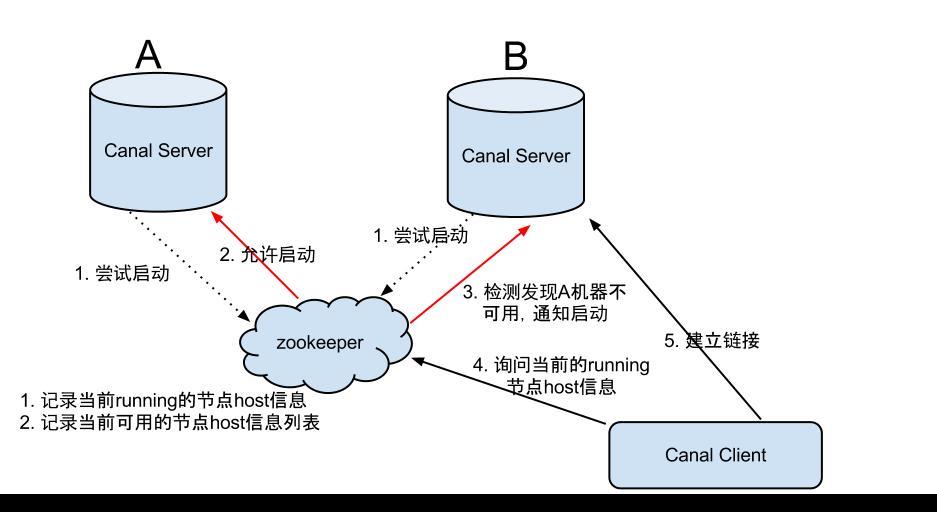
这里在解释下instance。instance 是 canal 数据同步的核心,在一个 canal 实例中只有启动instace才能进行数据的同步任务。一个 canal server 实例中可以创建多个 CanalInstance 实例。每一个 CanalInstance 可以看成是对应一个 MySQL 实例。
在开始分析canal的HA机制之前,有两个zk概念需要先铺垫下,分别是ZK的watcher和EPHEMERAL节点。他们是canal实现HA的基础。
先说说watcher。
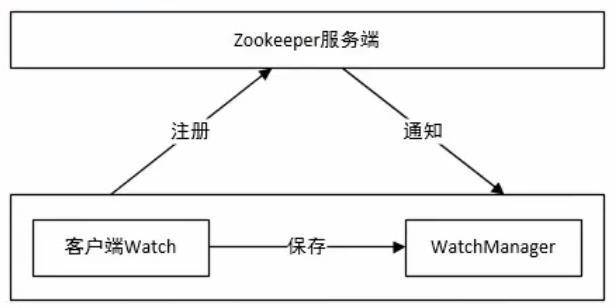
Zookeeper采用了Watcher机制实现数据的发布/订阅功能,当被订阅对象发生变化时会通知订阅者(ZK客户端)。Watcher实现由三个部分组成:
- ZK服务端
- ZK客户端
- 客户端的ZKWatchManager对象
客户端首先将Watcher注册到服务端,同时将Watcher对象保存到客户端的ZKWatchManager中。当ZK服务端监听的数据状态发生变化时,服务端主动通知客户端,客户端的ZKWatchManager会触发Watcher来回调处理逻辑。
EPHEMERAL节点也叫临时节点,是zk中的一种节点类型(还有永久节点)。这种节点和一次会话(session)绑定,会话断开节点会被删除。
canal server 启动时向 zookeeper 创建的节点就是临时节点,它与 session 生命周期绑定,当我手动执行关闭命令,客户端会话会失效,临时节点会自动清除;
一旦 zookeeper 发现 canal server 机器创建的节点消失后,就会通知其它的 canal server 再次进行向 zookeeper 尝试创建临时节点的操作,就会有新的 active 节点产生;
基础知识打好了,我们继续。
server端的HA机制
先来看看server端的HA实现机制。
首先在配置文件canal.properties中有如下配置:
canal.zkServers =
# flush data to zk
canal.zookeeper.flush.period = 1000
第一个是zk的地址,比如可以写127.0.0.1:2181,第二个配置是使用PeriodMixedMetaManager管理位点信息,这个信息会定时刷新到zk上。代码如下:
// 启动定时工作任务
executor.scheduleAtFixedRate(() -> {
List<ClientIdentity> tasks = new ArrayList<>(updateCursorTasks);
for (ClientIdentity clientIdentity : tasks) {
try {
updateCursorTasks.remove(clientIdentity);
// 定时将内存中的最新值刷到zookeeper中,多次变更只刷一次
zooKeeperMetaManager.updateCursor(clientIdentity, getCursor(clientIdentity));
} catch (Throwable e) {
// ignore
logger.error("period update" + clientIdentity.toString() + " curosr failed!", e);
}
}
}, period, period, TimeUnit.MILLISECONDS);
}
canal server 在tcp模式下的调用链路是这样的:
com.alibaba.otter.canal.deployer.CanalLauncher#main --> com.alibaba.otter.canal.deployer.CanalStarter#start --> com.alibaba.otter.canal.deployer.CanalController#start
先看下CanalController这个类的构造方法:
//读取配置文件
final String zkServers = getProperty(properties, CanalConstants.CANAL_ZKSERVERS);
if (StringUtils.isNotEmpty(zkServers)) {
zkclientx = ZkClientx.getZkClient(zkServers);
// 初始化系统目录
///otter/canal/destinations:用于存放instance信息
zkclientx.createPersistent(ZookeeperPathUtils.DESTINATION_ROOT_NODE, true);
///otter/canal/cluster,整个canal server的集群节点信息
zkclientx.createPersistent(ZookeeperPathUtils.CANAL_CLUSTER_ROOT_NODE, true);
}
...
这里创建的目录都是永久节点。
然后CanalController#start的代码会初始化canal在zookeeper上的节点系统目录,
public void start() throws Throwable {
logger.info("## start the canal server[{}({}):{}]", ip, registerIp, port);
// 创建整个canal的工作节点
//会在/otter/canal/cluster节点下创建"ip:port"临时节点,如/otter/canal/cluster/127.0.0.1:8080
//这里是根据ip+端口获取节点在zk的完整路径
final String path = ZookeeperPathUtils.getCanalClusterNode(registerIp + ":" + port);
initCid(path);
if (zkclientx != null) {
this.zkclientx.subscribeStateChanges(new IZkStateListener() {
public void handleStateChanged(KeeperState state) throws Exception {
}
//会话过期后重新建立新会话时再次创建"ip:port"临时节点。
public void handleNewSession() throws Exception {
initCid(path);
}
@Override
public void handleSessionEstablishmentError(Throwable error) throws Exception {
logger.error("failed to connect to zookeeper", error);
}
});
}
// 优先启动embeded服务
embededCanalServer.start();
// 尝试启动一下非lazy状态的通道
for (Map.Entry<String, InstanceConfig> entry : instanceConfigs.entrySet()) {
final String destination = entry.getKey();
InstanceConfig config = entry.getValue();
// 创建destination的工作节点
if (!embededCanalServer.isStart(destination)) {
// HA机制启动
//ServerRunningMonitor 是针对server的running节点控制类,用于管理instance
ServerRunningMonitor runningMonitor = ServerRunningMonitors.getRunningMonitor(destination);
if (!config.getLazy() && !runningMonitor.isStart()) {
runningMonitor.start();
}
}
....
}
}
干了这么几件事情:
- 会在/otter/canal/cluster节点下创建"ip:port"临时节点
- 注册IZkStateListener,监听zk的连接状态变化,当会话过期后重新建立新会话时再次创建"ip:port"临时节点。
- 启动canal server
- 启动ServerRunningMonitor
3.HA机制启动。对于每一个instance,都会在/otter/canal/destinations节点下记录自己的canal-server和canal-client信息。每个canal-server对每个instance的管理是交给ServerRunningMonitor类的。
ServerRunningMonitor 是针对server的running节点控制类,用于管理instance。首先来看看它的构造方法:
public ServerRunningMonitor(){
// 创建父节点
//用来监听该节点的数据增删改变化的listener
dataListener = new IZkDataListener() {
//数据发生变化回调
// "/otter/canal/destinations/{destination}/running" 临时节点
// //表示当前为该instance服务的canal server节点是谁,如果canal server与zk连接超时,会导致该临时节点被删除。
// canal server注册在该节点上的dataListener便会监听到这一变化,比如可以做主备切换之类的操作。
public void handleDataChange(String dataPath, Object data) throws Exception {
MDC.put("destination", destination);//方便日志跟踪
ServerRunningData runningData = JsonUtils.unmarshalFromByte((byte[]) data, ServerRunningData.class);
if (!isMine(runningData.getAddress())) {
mutex.set(false);
}
if (!runningData.isActive() && isMine(runningData.getAddress())) { // 说明出现了主动释放的操作,并且本机之前是active
//删除zk上该临时节点,关闭instance
releaseRunning();// 彻底释放mainstem
}
activeData = (ServerRunningData) runningData;
}
//数据删除回调
/**
* 当节点被删除时,如果上一次active的状态就是本机,调用initRunning即时触发一下抢占。
* 否则就是等待delayTime之后在抢占,避免因网络瞬端或者zk异常,导致出现频繁的切换操作。
*/
public void handleDataDeleted(String dataPath) throws Exception {
MDC.put("destination", destination);
mutex.set(false);
if (!release && activeData != null && isMine(activeData.getAddress())) {
// 如果上一次active的状态就是本机,则即时触发一下active抢占
initRunning();
} else {
// 否则就是等待delayTime,避免因网络瞬端或者zk异常,导致出现频繁的切换操作
delayExector.schedule(() -> initRunning(), delayTime, TimeUnit.SECONDS);
}
}
};
}
就是新建了一个IZkDataListener实例,并实现了它的回调方法。每个回调方法的功能注释都写得很清楚了。
再看看它的start方法:
public synchronized void start() {
super.start();
try {
processStart();
if (zkClient != null) {
// 如果需要尽可能释放instance资源,不需要监听running节点,不然即使stop了这台机器,另一台机器立马会start
String path = ZookeeperPathUtils.getDestinationServerRunning(destination);
//在/otter/canal/destinations/{destination}/running 节点下注册dataListener,用来监听该节点的数据增删改变化。
zkClient.subscribeDataChanges(path, dataListener);
initRunning();//初始化instance下的canal-server信息
} else {
processActiveEnter();// 没有zk,直接启动
}
} catch (Exception e) {
logger.error("start failed", e);
// 没有正常启动,重置一下状态,避免干扰下一次start
stop();
}
}
方法不长,调用了processStart方法:
public void processStart() {
try {
if (zkclientx != null) {
final String path = ZookeeperPathUtils.getDestinationClusterNode(destination,
registerIp + ":" + port);
initCid(path);
zkclientx.subscribeStateChanges(new IZkStateListener() {
public void handleStateChanged(KeeperState state) throws Exception {
}
public void handleNewSession() throws Exception {
initCid(path);
}
@Override
public void handleSessionEstablishmentError(Throwable error) throws Exception {
logger.error("failed to connect to zookeeper", error);
}
});
}
processStart方法,会在/otter/canal/destinations/{destination}/cluster 节点下注册IZkStateListener,用来监听zk的连接状态变化,同时创建"ip:port"临时节点。这个临时节点主要是用来给canal client提供该instance下可用canal serve节点列表。
接着在/otter/canal/destinations/{destination}/running节点下注册dataListener,用来监听该节点的数据增删改变化。
initRunning方法用来初始化instance下的canal server信息:
private void initRunning() {
if (!isStart()) {
return;
}
//服务端当前正在提供服务的running节点路径
String path = ZookeeperPathUtils.getDestinationServerRunning(destination);
// 序列化
byte[] bytes = JsonUtils.marshalToByte(serverData);
try {
//mutex是canal自己实现的一个同步类,基于AQS
mutex.set(false);
zkClient.create(path, bytes, CreateMode.EPHEMERAL);//创建临时节点
activeData = serverData;
processActiveEnter();// 触发一下事件
mutex.set(true);
release = false;
} catch (ZkNodeExistsException e) {
bytes = zkClient.readData(path, true);
if (bytes == null) {// 如果不存在节点,立即尝试一次
initRunning();
} else {
activeData = JsonUtils.unmarshalFromByte(bytes, ServerRunningData.class);
}
} catch (ZkNoNodeException e) {
zkClient.createPersistent(ZookeeperPathUtils.getDestinationPath(destination), true); // 尝试创建父节点
initRunning();
}
}
mutex设置false,代表访问的线程需要被阻塞挂起,等待mutex变为true被唤醒。所以这里能保证在高并发情况下服务端当前正在提供服务的running节点只有一个。
我们来梳理下目前看到的永久节点和临时节点
- /otter/canal/cluster 永久节点目录,集群的节点信息根目录,代表正在运行的canal server
- /otter/canal/cluster/ip:port 临时节点,存放具体的节点信息
- /otter/canal/destinations 存放多个instance信息
- /otter/canal/destinations/{destination}/cluster 代表当前instance下有多少可用的canal server
- /otter/canal/destinations/{destination}/running 临时节点下的数据代表当前instance的激活canal-server是谁,每个正常运行的canal-server都会在/otter/canal/destinations/{destination}/running 临时节点下注册dataListener,用于及时做HA切换。
client端的HA机制
前面说了,在client端,为了保证有序性,一个instance同一时间只能由一个canal client进行get/ack/rollback操作,否则客户端接收无法保证有序。
client端的HA实现更多的依赖是canal的使用方,官方给了一个例子可以参考,那就是ClusterCanalClientTest类。使用起来很简单,如下:
// 基于zookeeper动态获取canal server的地址,建立链接,其中一台server发生crash,可以支持failover
CanalConnector connector = CanalConnectors.newClusterConnector("127.0.0.1:2181", destination, "canal", "canal");
final ClusterCanalClientTest clientTest = new ClusterCanalClientTest(destination);
clientTest.setConnector(connector);
clientTest.start();
CanalConnector实现了failover的机制,支持失败重连,代码如下:
/**
* 创建带cluster模式的客户端链接,自动完成failover切换,服务器列表自动扫描
*/
public static CanalConnector newClusterConnector(String zkServers, String destination, String username,
String password) {
ClusterCanalConnector canalConnector = new ClusterCanalConnector(username,
password,
destination,
new ClusterNodeAccessStrategy(destination, ZkClientx.getZkClient(zkServers)));
canalConnector.setSoTimeout(60 * 1000);
canalConnector.setIdleTimeout(60 * 60 * 1000);
return canalConnector;
}
注意这个ClusterNodeAccessStrategy,CanalConnector就是通过ClusterNodeAccessStrategy来注册zk的listeners感知这些数据的变化。
if (accessStrategy instanceof ClusterNodeAccessStrategy) {
//初始化zkclient
currentConnector.setZkClientx(((ClusterNodeAccessStrategy) accessStrategy).getZkClient());
}
public void setZkClientx(ZkClientx zkClientx) {
this.zkClientx = zkClientx;
initClientRunningMonitor(this.clientIdentity);
}
上面的代码,设置当前connector的zkClient,并在zk上初始化客户端信息。ClientRunningMonitor是客户端的instance管理类,它的启动在com.alibaba.otter.canal.client.impl.SimpleCanalConnector#connect,如下:
public void connect() throws CanalClientException {
...
//这个runningMoitor是ClientRunningMonitor
if (runningMonitor != null) {
if (!runningMonitor.isStart()) {
runningMonitor.start();
}
} else {
...
}
继续来看看runningMonitor.start里都干了啥,
public void start() {
super.start();
// /otter/canal/destinations/{destination}/{clientid}/running
// 表示客户端目前正在工作的节点
String path = ZookeeperPathUtils.getDestinationClientRunning(this.destination, clientData.getClientId());
//监听数据变化,负责客户端的HA切换
zkClient.subscribeDataChanges(path, dataListener);
initRunning();
}
dataListener定义如下:
public ClientRunningMonitor(){
dataListener = new IZkDataListener() {
//数据变化时,保存当前的running data,其中包含客户端地址,clientid等
public void handleDataChange(String dataPath, Object data) throws Exception {
MDC.put("destination", destination);
ClientRunningData runningData = JsonUtils.unmarshalFromByte((byte[]) data, ClientRunningData.class);
if (!isMine(runningData.getAddress())) {
mutex.set(false);
}
if (!runningData.isActive() && isMine(runningData.getAddress())) { // 说明出现了主动释放的操作,并且本机之前是active
release = true;
releaseRunning();// 彻底释放mainstem
}
activeData = (ClientRunningData) runningData;
}
public void handleDataDeleted(String dataPath) throws Exception {
MDC.put("destination", destination);
mutex.set(false);
// 触发一下退出,可能是人为干预的释放操作或者网络闪断引起的session expired timeout
processActiveExit();
if (!release && activeData != null && isMine(activeData.getAddress())) {
// 如果上一次active的状态就是本机,则即时触发一下active抢占
initRunning();
} else {
// 否则就是等待delayTime,避免因网络瞬端或者zk异常,导致出现频繁的切换操作
delayExector.schedule(() -> initRunning(), delayTime, TimeUnit.SECONDS);
}
}
};
}
initRunning方法会在 /otter/canal/destinations/{destination}/{clientid}/running创建临时节点写入数据,写入信息为客户端的IP,port和clientId信息。创建临时节点成功才能与canal server建立连接。
这个临时节点的创建过程在ClientRunningMonitor.initRunning中,创建临时节点成功才能与canal server建立连接。临时节点写入信息为客户端的IP,port和clientId信息。
客户端的HA还有一个重要的逻辑,就是在HA模式下,客户端位点,filter等信息会放到zk上,方便canal server切换时的共用。我们前面的文章讲过,canal的meta信息管理器接口时CanalMetaManager,它有多个实现类,其中就有ZooKeeperMetaManager。这部分的代码如下:
public void subscribe(ClientIdentity clientIdentity) throws CanalMetaManagerException {
String path = ZookeeperPathUtils.getClientIdNodePath(clientIdentity.getDestination(),
clientIdentity.getClientId());
try {
zkClientx.createPersistent(path, true);
} catch (ZkNodeExistsException e) {
// ignore
}
///如果客户端存在filter,则创建/otter/canal/destinations/{destination}/{clientId}/filter持久节点,存放客户端的filter信息。
if (clientIdentity.hasFilter()) {
String filterPath = ZookeeperPathUtils.getFilterPath(clientIdentity.getDestination(),
clientIdentity.getClientId());
byte[] bytes = null;
try {
bytes = clientIdentity.getFilter().getBytes(ENCODE);
} catch (UnsupportedEncodingException e) {
throw new CanalMetaManagerException(e);
}
try {
zkClientx.createPersistent(filterPath, bytes);
} catch (ZkNodeExistsException e) {
// ignore
zkClientx.writeData(filterPath, bytes);
}
}
}
最后总结下client端的HA机制。
canal client与canal server建立连接前,会创建临时节点/otter/canal/destinations/{destination}/{clientId}/running,并在改节点下写入自己的IP,port,clientId信息,表示当前该instance下激活的client是自己。
同时每个canal client都会在节点上注册dataListener,监听节点数据变化负责客户端的HA切换。当前被激活的client会通过ClusterNodeAccessStrategy(nextNode)获得zk上canal server的信息并与之建立连接。
客户端发送SUBSCRIPTION 请求给canal server,客户端位点,filter等信息会被注册到zk上,方便canal server切换时的共用。
参考:
- https://www.bookstack.cn/read/canal-v1.1.4/34357b71c7c1f182.md#HA%E6%9C%BA%E5%88%B6%E8%AE%BE%E8%AE%A1
- https://cloud.tencent.com/developer/article/1648637
以上是关于canal 源码解析系列-canal的HA机制解析的主要内容,如果未能解决你的问题,请参考以下文章