canal 源码解析系列-EventParser模块解析1
Posted 犀牛饲养员
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了canal 源码解析系列-EventParser模块解析1相关的知识,希望对你有一定的参考价值。
引言
上一篇文章,我们讲了canalInstance模块:
canal 源码解析系列-CanalInstance模块解析
instance 模块包含几个子模块:
- eventParser: 数据源接入,模拟 slave 协议和 master 进行交互,协议解析
- eventSink: Parser 和 Store 链接器,进行数据过滤,加工,分发的工作
- eventStore: 数据存储
- metaManager: 增量订阅 & 消费信息管理器
本篇文章就来详细看看这个EventParser模块。
正文
先看一副图:
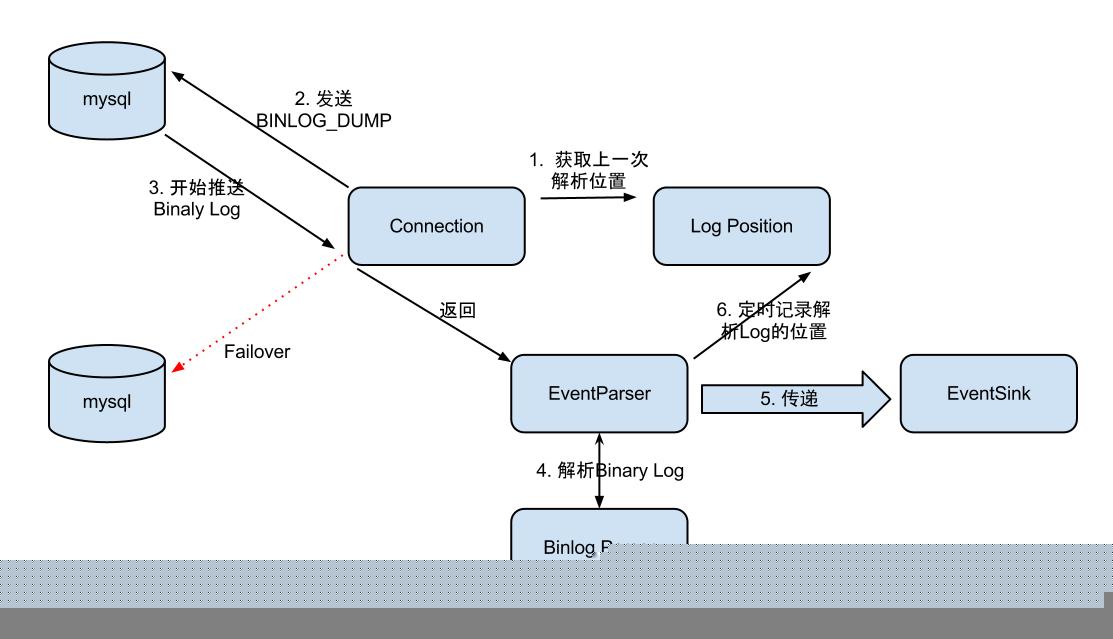
parser过程大致可分为几步:
- Connection获取上一次解析成功的位置 (如果第一次启动,则获取初始指定的位置或者是当前数据库的binlog位点)
- Connection建立链接,请求mysql发送binlog(发送BINLOG_DUMP指令)
- EventParser从mysql上拉取binlog数据进行解析并传递给EventSink
我们通过源码具体看看这几个步骤。
先看几个关键类的关系:
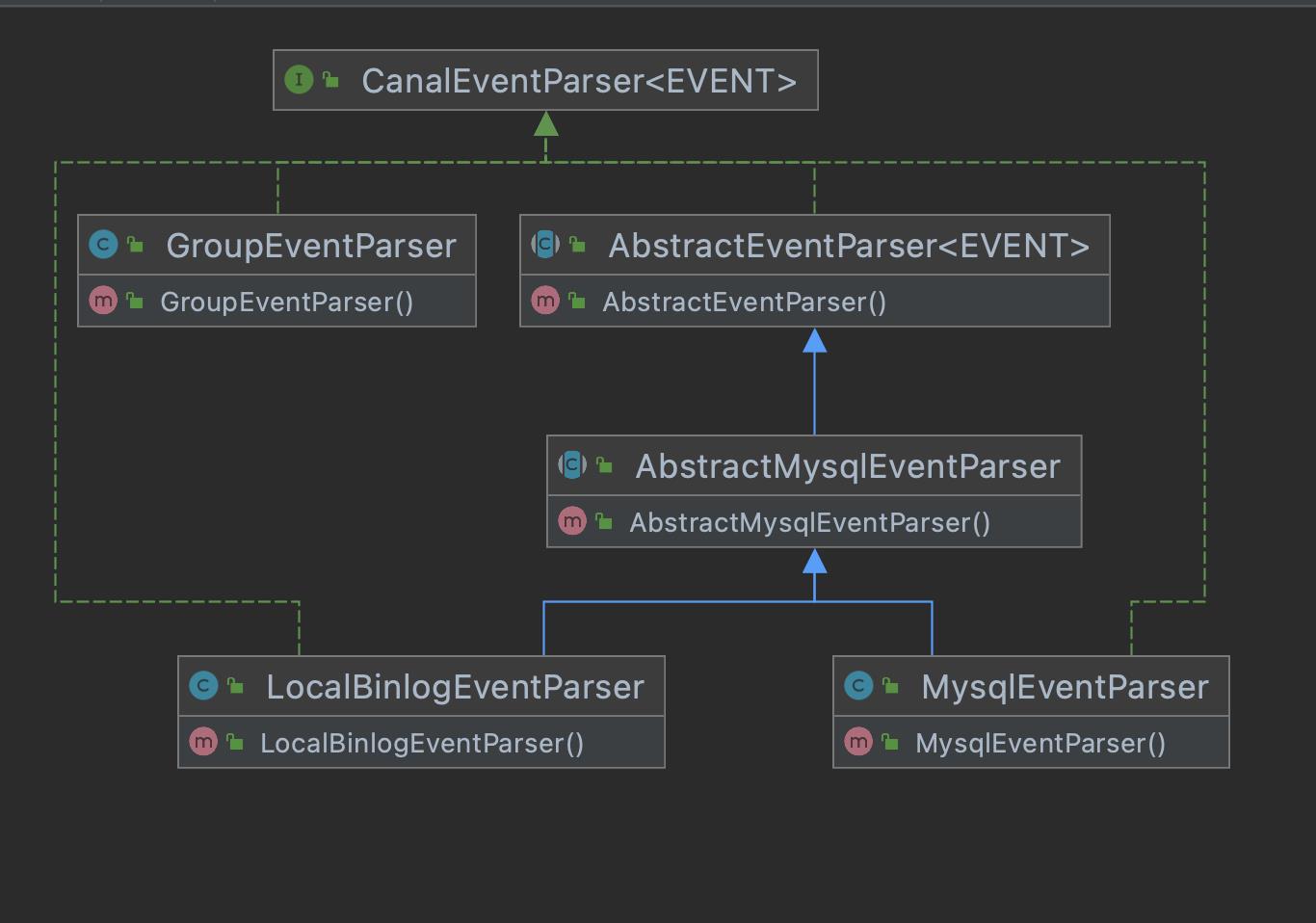
先说说不是那么重要的LocalBinlogEventParser,它主要用于本地binlog文件的复制的场景。例如将mysql的binlog文件拷贝到canal的机器上进行解析。很明显这是一个离线的场景,听起来似乎很少用到,实际也确实如此。
LocalBinlogEventParser 使用 LocalBinLogConnection进行连接,我们来看看后者的connect方法,
com.alibaba.otter.canal.parse.inbound.mysql.LocalBinLogConnection#connect方法
public void connect() throws IOException {
if (this.binlogs == null) {
//基于本地文件路径建立连接(directory)
this.binlogs = new BinLogFileQueue(this.directory);
}
this.running = true;
}
该方法基于本地文件建立binlog队列。LocalBinlogEventParser不是重点,就说到这里把。
GroupEventParser相当于是多个CanalEventParser的组合,实际上主要是多个MysqlEventParser实例的组合。MysqlEventParser伪装成单个mysql实例的slave解析binglog日志,而GroupEventParser伪装成多个mysql实例的slave解析binglog日志。
/**
* 组合多个EventParser进行合并处理,group只是做为一个delegate处理
*
* @author jianghang 2012-10-16 上午11:23:14
* @version 1.0.0
*/
public class GroupEventParser extends AbstractCanalLifeCycle implements CanalEventParser {
private List<CanalEventParser> eventParsers = new ArrayList<>();
public void start() {
super.start();
// 统一启动
for (CanalEventParser eventParser : eventParsers) {
if (!eventParser.isStart()) {
eventParser.start();
}
}
}
...
可以看到,GroupEventParser内部维护了多个CanalEventParser,组合多个EventParser进行合并处理而已。
通过GroupEventParser,可以同时处理多个数据库,比如常见的分库分表的场景。EventParser的初始化在前面我们讲CanalInstance部分,我们看下关键的部分:
protected void initEventParser() {
...
if (!CollectionUtils.isEmpty(groupDbAddresses)) {
//可能有多个数据库地址
int size = groupDbAddresses.get(0).size();// 取第一个分组的数量,主备分组的数量必须一致
List<CanalEventParser> eventParsers = new ArrayList<>();
for (int i = 0; i < size; i++) {
...
// 初始化其中的一个分组parser
eventParsers.add(doInitEventParser(lastType, dbAddress));
}
if (eventParsers.size() > 1) { // 如果存在分组,构造分组的parser
GroupEventParser groupEventParser = new GroupEventParser();
groupEventParser.setEventParsers(eventParsers);
this.eventParser = groupEventParser;
} else {
this.eventParser = eventParsers.get(0);
}
} else {
// 创建一个空数据库地址的parser,可能使用了tddl指定地址,启动的时候才会从tddl获取地址
this.eventParser = doInitEventParser(type, new ArrayList<>());
}
}
可以看到如果是多个数据库地址,就返回GroupEventParser。
所以核心逻辑都在MysqlEventParser了。MysqlEventParser有很多核心的逻辑等待我们去探索,比如如何抓取binlog,如何解析binlog,如何实现主备切换等。
先看看主备切换的逻辑,
public void doSwitch(AuthenticationInfo newRunningInfo) {
// 1. 需要停止当前正在复制的过程
// 2. 找到新的position点
// 3. 重新建立链接,开始复制数据
// 切换ip
String alarmMessage = null;
if (this.runningInfo.equals(newRunningInfo)) {
alarmMessage = "same runingInfo switch again : " + runningInfo.getAddress().toString();
logger.warn(alarmMessage);
return;
}
if (newRunningInfo == null) {
alarmMessage = "no standby config, just do nothing, will continue try:"
+ runningInfo.getAddress().toString();
logger.warn(alarmMessage);
sendAlarm(destination, alarmMessage);
return;
} else {
stop();
alarmMessage = "try to ha switch, old:" + runningInfo.getAddress().toString() + ", new:"
+ newRunningInfo.getAddress().toString();
logger.warn(alarmMessage);
sendAlarm(destination, alarmMessage);
runningInfo = newRunningInfo;
//更换了链接需要重新启动
start();
}
}
doSwitch方法什么时候调用呢?这个其实上一篇文章我们讲到CanalHAController有提到过。总结来讲过程是这样的:
MysqlEventParser持有一个名为MysqlDetectingTimeTask内部类,这是一个TimerTask的实例,定时去连接数据库做心跳检测。如果检测成功,就调用HeartBeatHAController的onSuccess方法如果失败,就HeartBeatHAController的onFail方法,如果失败超过一定次数,onFail方法中调用doSwitch方法进行主备切换。
MysqlEventParser很多功能是继承自AbstractEventParser,我们来看看后者的一些核心功能。
先来看构造函数:
public AbstractEventParser(){
// 初始化一下
/**
* 缓冲buffer,缓冲event队列,提供按事务刷新数据的机制。
* EventTransactionBuffer入参是一个callback
*/
transactionBuffer = new EventTransactionBuffer(transaction -> {
//consumeTheEventAndProfilingIfNecessary的消费逻辑是调用sink落数据
//sink后面再详细说
boolean successed = consumeTheEventAndProfilingIfNecessary(transaction);
if (!running) {
return;
}
if (!successed) {
throw new CanalParseException("consume failed!");
}
//sink完更新binlog位置
LogPosition position = buildLastTransactionPosition(transaction);
if (position != null) { // 可能position为空
logPositionManager.persistLogPosition(AbstractEventParser.this.destination, position);
}
});
}
注释都写得很清楚了,需要注意的是,构造函数这里并不会真正调用consumeTheEventAndProfilingIfNecessary,这里只是给函数赋值而已。真正调用的地方是com.alibaba.otter.canal.parse.inbound.EventTransactionBuffer#flush方法。flush方法的调用方等下会讲到。
start也是个重要的方法,MysqlEventParser的start调用的是其父类也就是AbstractEventParser的start方法,很多核心模块就是再这个start方法里被初始化或者启动的。这个方法比较长,我尽量把注释写得详细一些。
public void start() {
super.start();
//方便日志追踪destination
MDC.put("destination", destination);
// 配置transaction buffer
// 初始化缓冲队列
transactionBuffer.setBufferSize(transactionSize);// 设置buffer大小
//这里会给CanalEntry.Entry[]分配空间
transactionBuffer.start();
// 构造bin log parser
//BinLogParser是MysqlEventParser的模块,是具体负责解析binlog的接口
binlogParser = buildParser();// 初始化一下BinLogParser
binlogParser.start();
// 启动工作线程
parseThread = new Thread(new Runnable() {
public void run() {
MDC.put("destination", String.valueOf(destination));
ErosaConnection erosaConnection = null;
boolean isMariaDB = false;
while (running) {
try {
// 开始执行replication
// 1. 构造Erosa连接
erosaConnection = buildErosaConnection();
// 2. 启动一个心跳线程
startHeartBeat(erosaConnection);
// 3. 执行dump前的准备工作
preDump(erosaConnection);
erosaConnection.connect();// 链接
//mysql主从同步中的serverid
long queryServerId = erosaConnection.queryServerId();
if (queryServerId != 0) {
serverId = queryServerId;
}
if (erosaConnection instanceof MysqlConnection) {
isMariaDB = ((MysqlConnection)erosaConnection).isMariaDB();
}
// 4. 获取最后的位置信息
long start = System.currentTimeMillis();
logger.warn("---> begin to find start position, it will be long time for reset or first position");
//这一行就是获取binlog的解析位置
EntryPosition position = findStartPosition(erosaConnection);
final EntryPosition startPosition = position;
if (startPosition == null) {
throw new PositionNotFoundException("can't find start position for " + destination);
}
if (!processTableMeta(startPosition)) {
throw new CanalParseException("can't find init table meta for " + destination
+ " with position : " + startPosition);
}
long end = System.currentTimeMillis();
logger.warn("---> find start position successfully, {}", startPosition.toString() + " cost : "
+ (end - start)
+ "ms , the next step is binlog dump");
// 重新链接,因为在找position过程中可能有状态,需要断开后重建
erosaConnection.reconnect();
// 定义回调函数,当解析成功后,sink()方法会暂存到缓冲区transactionBuffer中。
// 真正执行sink的逻辑,这里只是定义SinkFunction,并不执行
final SinkFunction sinkHandler = new SinkFunction<EVENT>() {
private LogPosition lastPosition;
public boolean sink(EVENT event) {
try {
//把binlog的事件解析成CanalEntry.Entry结构
CanalEntry.Entry entry = parseAndProfilingIfNecessary(event, false);
if (!running) {
return false;
}
if (entry != null) {
exception = null; // 有正常数据流过,清空exception
//添加到缓冲区,这里会调用我们前面提到的flush
transactionBuffer.add(entry);
// 记录一下对应的positions
this.lastPosition = buildLastPosition(entry);
// 记录一下最后一次有数据的时间
lastEntryTime = System.currentTimeMillis();
}
return running;
} catch (TableIdNotFoundException e) {
throw e;
} catch (Throwable e) {
if (e.getCause() instanceof TableIdNotFoundException) {
throw (TableIdNotFoundException) e.getCause();
}
// 记录一下,出错的位点信息
processSinkError(e,
this.lastPosition,
startPosition.getJournalName(),
startPosition.getPosition());
throw new CanalParseException(e); // 继续抛出异常,让上层统一感知
}
}
};
// 4. 开始dump数据
// parallel默认是true,当然,是可以配置的。"canal.instance.parser.parallel"
if (parallel) {
// build stage processor
multiStageCoprocessor = buildMultiStageCoprocessor();
if (isGTIDMode() && StringUtils.isNotEmpty(startPosition.getGtid())) {
// 判断所属instance是否启用GTID模式,是的话调用ErosaConnection中GTID对应方法dump数据
GTIDSet gtidSet = parseGtidSet(startPosition.getGtid(),isMariaDB);
((MysqlMultiStageCoprocessor) multiStageCoprocessor).setGtidSet(gtidSet);
multiStageCoprocessor.start();
erosaConnection.dump(gtidSet, multiStageCoprocessor);
} else {
multiStageCoprocessor.start();
if (StringUtils.isEmpty(startPosition.getJournalName())
&& startPosition.getTimestamp() != null) {
erosaConnection.dump(startPosition.getTimestamp(), multiStageCoprocessor);
} else {
erosaConnection.dump(startPosition.getJournalName(),
startPosition.getPosition(),
multiStageCoprocessor);
}
}
} else {
if (isGTIDMode() && StringUtils.isNotEmpty(startPosition.getGtid())) {
// 判断所属instance是否启用GTID模式,是的话调用ErosaConnection中GTID对应方法dump数据
erosaConnection.dump(parseGtidSet(startPosition.getGtid(), isMariaDB), sinkHandler);
} else {
if (StringUtils.isEmpty(startPosition.getJournalName())
&& startPosition.getTimestamp() != null) {
erosaConnection.dump(startPosition.getTimestamp(), sinkHandler);
} else {
erosaConnection.dump(startPosition.getJournalName(),
startPosition.getPosition(),
sinkHandler);
}
}
}
} catch (TableIdNotFoundException e) {
exception = e;
// 特殊处理TableIdNotFound异常,出现这样的异常,一种可能就是起始的position是一个事务当中,导致tablemap
// Event时间没解析过
needTransactionPosition.compareAndSet(false, true);
logger.error(String.format("dump address %s has an error, retrying. caused by ",
runningInfo.getAddress().toString()), e);
} catch (Throwable e) {
processDumpError(e);
exception = e;
if (!running) {
if (!(e instanceof java.nio.channels.ClosedByInterruptException || e.getCause() instanceof java.nio.channels.ClosedByInterruptException)) {
throw new CanalParseException(String.format("dump address %s has an error, retrying. ",
runningInfo.getAddress().toString()), e);
}
} else {
logger.error(String.format("dump address %s has an error, retrying. caused by ",
runningInfo.getAddress().toString()), e);
sendAlarm(destination, ExceptionUtils.getFullStackTrace(e));
}
if (parserExceptionHandler != null) {
parserExceptionHandler.handle(e);
}
} finally {
// 重新置为中断状态
Thread.interrupted();
// 关闭一下链接
afterDump(erosaConnection);
try {
if (erosaConnection != null) {
erosaConnection.disconnect();
}
} catch (IOException e1) {
if (!running) {
throw new CanalParseException(String.format("disconnect address %s has an error, retrying. ",
runningInfo.getAddress().toString()),
e1);
} else {
logger.error("disconnect address {} has an error, retrying., caused by ",
runningInfo.getAddress().toString(),
e1);
}
}
}
// 出异常了,退出sink消费,释放一下状态
eventSink.interrupt();
transactionBuffer.reset();// 重置一下缓冲队列,重新记录数据
binlogParser.reset();// 重新置位
if (multiStageCoprocessor != null && multiStageCoprocessor.isStart()) {
// 处理 RejectedExecutionException
try {
multiStageCoprocessor.stop();
} catch (Throwable t) {
logger.debug("multi processor rejected:", t);
}
}
if (running) {
// sleep一段时间再进行重试
try {
Thread.sleep(10000 + RandomUtils.nextInt(10000));
} catch (InterruptedException e) {
}
}
}
MDC.remove("destination");
}
});
parseThread.setUncaughtExceptionHandler(handler);
parseThread.setName(String.format("destination = %s , address = %s , EventParser",
destination,
runningInfo == null ? null : runningInfo.getAddress()));
parseThread.start();
}
EventParser模块要说的东西太多了,其它的放在下篇讲吧。
以上是关于canal 源码解析系列-EventParser模块解析1的主要内容,如果未能解决你的问题,请参考以下文章