canal 源码解析系列-sink模块解析
Posted 犀牛饲养员
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了canal 源码解析系列-sink模块解析相关的知识,希望对你有一定的参考价值。
canal 源码解析系列-sink模块解析
引言
parser模块用来订阅binlog事件,然后通过sink投递到store。Sink阶段所做的事情,就是根据一定的规则,对binlog数据进行一定的过滤。另外还会做一些数据分发的工作。它的核心接口是CanalEventSink,它的核心方法sink用来提交数据的。
正文
CanalEventSink接口有两个核心实现类,分别是EntryEventSink和GroupEventSink,后者主要是用在多库的场景,比如分库分表。类图结构如下:
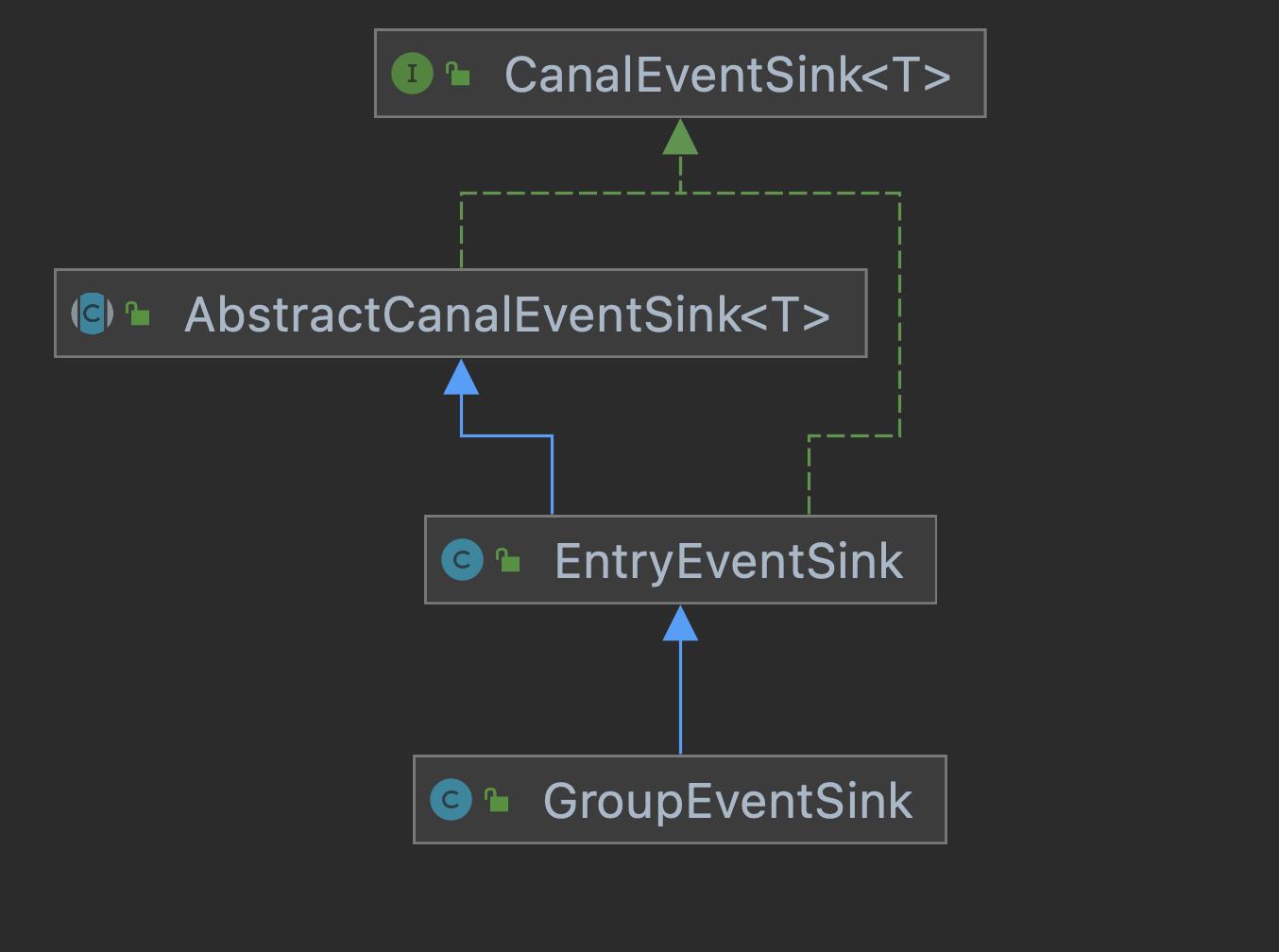
这俩个实现实现类创建的的地方在com.alibaba.otter.canal.instance.manager.CanalInstanceWithManager#initEventSink方法。
protected void initEventSink() {
logger.info("init eventSink begin...");
int groupSize = getGroupSize();
if (groupSize <= 1) {
eventSink = new EntryEventSink();
} else {
eventSink = new GroupEventSink(groupSize);
}
...
在上一篇文章我们讲的是parser模块,parse模块解析完成后,会把数据(CanalEntry.Entry)放到一个环形队列TransactionBuffer中,方法是:
com.alibaba.otter.canal.parse.inbound.EventTransactionBuffer#add(com.alibaba.otter.canal.protocol.CanalEntry.Entry)
public void add(CanalEntry.Entry entry) throws InterruptedException {
switch (entry.getEntryType()) {
case TRANSACTIONBEGIN:
flush();// 刷新上一次的数据
put(entry);
break;
case TRANSACTIONEND:
put(entry);
flush();
break;
case ROWDATA:
put(entry);
// 针对非DML的数据,直接输出,不进行buffer控制
EventType eventType = entry.getHeader().getEventType();
if (eventType != null && !isDml(eventType)) {
flush();
}
break;
case HEARTBEAT:
// master过来的heartbeat,说明binlog已经读完了,是idle状态
put(entry);
flush();
break;
default:
break;
}
}
这里根据事件的类型不同,进行不同的处理。比如如果是事物开始,先刷新上一次的数据到store,然后放入新的数据。
put和flush的代码我先贴出来,
private void put(CanalEntry.Entry data) throws InterruptedException {
// 首先检查是否有空位
if (checkFreeSlotAt(putSequence.get() + 1)) {
long current = putSequence.get();
long next = current + 1;
// 先写数据,再更新对应的cursor,并发度高的情况,putSequence会被get请求可见,拿出了ringbuffer中的老的Entry值
entries[getIndex(next)] = data;
putSequence.set(next);
} else {
flush();// buffer区满了,刷新一下
put(data);// 继续加一下新数据
}
}
private void flush() throws InterruptedException {
long start = this.flushSequence.get() + 1;
long end = this.putSequence.get();
if (start <= end) {
List<CanalEntry.Entry> transaction = new ArrayList<>();
for (long next = start; next <= end; next++) {
transaction.add(this.entries[getIndex(next)]);
}
flushCallback.flush(transaction);//刷新(sink)
flushSequence.set(end);// flush成功后,更新flush位置
}
}
首先看到put的时候会更新一个指针,putSequence,而flush也有个指针:flushSequence。于是我们看到在flush方法中,start就是flush的指针,end就是put的指针,flush的动作就是把当前flush到put中间的数据,全部刷新到下一个阶段。传递到下一个阶段的代码在flushCallback.flush方法中,这个方法的逻辑是:
//consumeTheEventAndProfilingIfNecessary的消费逻辑是调用sink落数据
boolean successed = consumeTheEventAndProfilingIfNecessary(transaction);
if (!running) {
return;
}
if (!successed) {
throw new CanalParseException("consume failed!");
}
//sink完更新binlog位置
LogPosition position = buildLastTransactionPosition(transaction);
if (position != null) { // 可能position为空
logPositionManager.persistLogPosition(AbstractEventParser.this.destination, position);
}
consumeTheEventAndProfilingIfNecessary调用CanalEventSink接口的sink方法,
protected boolean consumeTheEventAndProfilingIfNecessary(List<CanalEntry.Entry> entrys) throws CanalSinkException,
InterruptedException {
...
boolean result = eventSink.sink(entrys, (runningInfo == null) ? null : runningInfo.getAddress(), destination);
...
return result;
}
接着看这个sink方法,
public boolean sink(List<CanalEntry.Entry> entrys, InetSocketAddress remoteAddress, String destination)
throws CanalSinkException,
InterruptedException {
return sinkData(entrys, remoteAddress);
}
private boolean sinkData(List<CanalEntry.Entry> entrys, InetSocketAddress remoteAddress)
throws InterruptedException {
boolean hasRowData = false;
boolean hasHeartBeat = false;
List<Event> events = new ArrayList<>();
for (CanalEntry.Entry entry : entrys) {
if (!doFilter(entry)) {//数据过滤,过滤表名、字段等
continue;
}
if (filterTransactionEntry
&& (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND)) {
long currentTimestamp = entry.getHeader().getExecuteTime();
// 基于一定的策略控制,放过空的事务头和尾,便于及时更新数据库位点,表明工作正常
if (lastTransactionCount.incrementAndGet() <= emptyTransctionThresold
&& Math.abs(currentTimestamp - lastTransactionTimestamp) <= emptyTransactionInterval) {
continue;
} else {
// fixed issue https://github.com/alibaba/canal/issues/2616
// 主要原因在于空事务只发送了begin,没有同步发送commit信息,这里修改为只对commit事件做计数更新,确保begin/commit成对出现
if (entry.getEntryType() == EntryType.TRANSACTIONEND) {
lastTransactionCount.set(0L);
lastTransactionTimestamp = currentTimestamp;
}
}
}
hasRowData |= (entry.getEntryType() == EntryType.ROWDATA);
hasHeartBeat |= (entry.getEntryType() == EntryType.HEARTBEAT);
Event event = new Event(new LogIdentity(remoteAddress, -1L), entry, raw);
events.add(event);
}
if (hasRowData || hasHeartBeat) {
// 存在row记录 或者 存在heartbeat记录,直接跳给后续处理
return doSink(events);
} else {
// 需要过滤的数据
if (filterEmtryTransactionEntry && !CollectionUtils.isEmpty(events)) {
long currentTimestamp = events.get(0).getExecuteTime();
// 基于一定的策略控制,放过空的事务头和尾,便于及时更新数据库位点,表明工作正常
if (Math.abs(currentTimestamp - lastEmptyTransactionTimestamp) > emptyTransactionInterval
|| lastEmptyTransactionCount.incrementAndGet() > emptyTransctionThresold) {
lastEmptyTransactionCount.set(0L);
lastEmptyTransactionTimestamp = currentTimestamp;
return doSink(events);
}
}
// 直接返回true,忽略空的事务头和尾
return true;
}
}
注释写得比较清楚了。这里在补充一些点。
首先过滤数据那里,只有EntryType.ROWDATA类型才会过滤。过滤的原理使用的是canal的filter 模块,filter模块主要用于过滤 binlog 过来的表和字段数据。使用 canal 的时候,可以在服务端或客户端进行配置。filter基于aviater来做匹配,有几个实现类:
- AviaterELFilter EL表达式匹配
- AviaterRegexFilter 正则匹配
- AviaterSimpleFilter 简单匹配
这里不深入展开了这部分,有兴趣的可以去看。
接下来的部分看起来比较似乎比较难理解。filterTransactionEntry用来控制是否过滤事务头(TRANSACTIONBEGIN)和事物尾(TRANSACTIONEND),不过滤的话相当于在客户端收到的消息里会看到这两个entry。事务头和尾主要是用来区分事务边界,本身数据没啥意义。filterTransactionEntry的默认值是false,也就是大部分情况下是不过滤的,可以不用关注这个。
sinkData方法里的核心调用是doSink方法发送到下游(EventStore),我们接着看它的逻辑,
protected boolean doSink(List<Event> events) {
//HeartBeatEntryEventHandler
for (CanalEventDownStreamHandler<List<Event>> handler : getHandlers()) {
events = handler.before(events);//doSink 前置操作,过滤掉heartbeat数据
}
long blockingStart = 0L;
int fullTimes = 0;
do {
if (eventStore.tryPut(events)) {//送到下一步骤store
if (fullTimes > 0) {
eventsSinkBlockingTime.addAndGet(System.nanoTime() - blockingStart);
}
for (CanalEventDownStreamHandler<List<Event>> handler : getHandlers()) {
events = handler.after(events);//after是个空方法
}
return true;
} else {
//重试
if (fullTimes == 0) {
blockingStart = System.nanoTime();
}
applyWait(++fullTimes);//防止无限等待
if (fullTimes % 100 == 0) {
long nextStart = System.nanoTime();
eventsSinkBlockingTime.addAndGet(nextStart - blockingStart);
blockingStart = nextStart;
}
}
for (CanalEventDownStreamHandler<List<Event>> handler : getHandlers()) {
events = handler.retry(events);//retry是空方法
}
} while (running && !Thread.interrupted());
return false;
}
这个逻辑还比较简单。CanalEventDownStreamHandler其实只有HeartBeatEntryEventHandler一个实现,在before方法中把heartbeat事件从events去掉。然后就到调用tryPut()方法,送到下一步骤store中。
接下来看看GroupEventSink。
当一个业务的数据规模达到一定的量级后,必然会涉及到水平拆分和垂直拆分的问题,针对这些拆分的数据需要处理时,就需要链接多个store进行处理,消费的位点就会变成多份,而且数据消费的进度无法得到尽可能有序的保证。
所以,在一定业务场景下,需要将拆分后的增量数据进行归并处理,比如按照时间戳/全局id进行排序归并,归并完后统一由客户端输出到ES,hbase等存储设备。
先来看看它的doSink方法,
protected boolean doSink(List<Event> events) {
int size = events.size();
for (int i = 0; i < events.size(); i++) {
Event event = events.get(i);
try {
barrier.await(event);// 进行timeline的归并调度处理
if (filterTransactionEntry) {
super.doSink(Arrays.asList(event));
} else if (i == size - 1) {
// 针对事务数据,只有到最后一条数据都通过后,才进行sink操作,保证原子性
// 同时批量sink,也要保证在最后一条数据释放状态之前写出数据,否则就有并发问题
return super.doSink(events);
}
} catch (InterruptedException e) {
return false;
} finally {
barrier.clear(event);
}
}
return false;
}
实现归并的核心就是那个barrier,它的定义如下:
private GroupBarrier barrier; // 归并排序需要预先知道组的大小,用于判断是否组内所有的sink都已经开始正常取数据
它有两个实现类:TimelineBarrier和TimelineTransactionBarrier,那如何选择使用那个呢?逻辑是这样的:
public void start() {
super.start();
if (filterTransactionEntry) {
barrier = new TimelineBarrier(groupSize);
} else {
barrier = new TimelineTransactionBarrier(groupSize);// 支持事务保留
}
}
结合上面doSink的方法,基本流程已经清楚了。当filterTransactionEntry为true时,使用TimelineBarrier进行调度,否则使用TimelineTransactionBarrier。后者是批量调用支持事务。(利用事务头和事务尾)
继续来看看TimelineBarrier的await方法,看看调度的原理是啥?
/**
* 判断自己的timestamp是否可以通过
*
* @throws InterruptedException
*/
public void await(Event event) throws InterruptedException {
long timestamp = getTimestamp(event);//提取时间发生的时间
try {
lock.lockInterruptibly();
single(timestamp);//当前时间入优先级队列,并且通知下一个minTimestamp数据出队列
//如果当前时间timestamp大于threshold,说明还有更小的时间待处理
while (isPermit(event, timestamp) == false) {
condition.await();
}
} finally {
lock.unlock();
}
}
然后看看single方法,
/**
* 通知下一个minTimestamp数据出队列
*
* @throws InterruptedException
*/
private void single(long timestamp) throws InterruptedException {
lastTimestamps.add(timestamp);
if (timestamp < state()) {//当前事件时间,居然小于之前已经处理的某个较小的事件
// 针对mysql事务中会出现时间跳跃
// 例子:
// 2012-08-08 16:24:26 事务头
// 2012-08-08 16:24:24 变更记录
// 2012-08-08 16:24:25 变更记录
// 2012-08-08 16:24:26 事务尾
// 针对这种case,一旦发现timestamp有回退的情况,直接更新threshold,强制阻塞其他的操作,等待最小数据优先处理完成
threshold = timestamp; // 更新为最小值
}
if (lastTimestamps.size() >= groupSize) {// 判断队列是否需要触发
// 触发下一个出队列的数据
Long minTimestamp = this.lastTimestamps.peek();//出队列,时间最小值
if (minTimestamp != null) {
threshold = minTimestamp;
notify(minTimestamp);
}
} else {
threshold = Long.MIN_VALUE;// 如果不满足队列长度,需要阻塞等待
}
}
结合注释,调度的原理其实非常清晰了。说白了就是让时间戳最小的事件先执行(下发到store),所谓的时间戳最小并不是指事件先到的就先处理,而是根据事件本身发生的时间来排序。排序使用的是优先级队列PriorityBlockingQueue。
TimelineTransactionBarrier限于篇幅,就不多说了。代码比较简单可以自行阅读。
基于上面的分析,我们可以用一幅图归纳下EventSink的设计思想:
说明:
- 数据过滤:支持通配符的过滤模式,表名,字段内容等
- 数据路由/分发:解决1:n (1个parser对应多个store的模式)
- 数据归并:解决n:1 (多个parser对应1个store)
- 数据加工:在进入store之前进行额外的处理,比如join
参考:
- https://www.bookstack.cn/read/canal-v1.1.4/34357b71c7c1f182.md#%E6%9E%B6%E6%9E%84
- https://zhuanlan.zhihu.com/p/345736518
- https://github.com/alibaba/canal/issues/132
以上是关于canal 源码解析系列-sink模块解析的主要内容,如果未能解决你的问题,请参考以下文章