模型推理从部署的角度看 bn 和 in 算子
Posted 极智视界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了模型推理从部署的角度看 bn 和 in 算子相关的知识,希望对你有一定的参考价值。
欢迎关注我的公众号 [极智视界],获取我的更多笔记分享
O_o >_< o_O O_o ~_~ o_O
本文介绍一下从部署角度来看 bn 和 in 的实现与对比。
做深度学习的同学应该都接触过残差网络 (Resnet) 这个经典且实用的网络,一般有 resnet18、resnet34、resnet50、resnet101、resnet152,其主要区别是 ResidualBlock 的多少。resnet 创新的提出了残差块结构,里面的恒等映射既不会引入额外的计算参数又有利于信息的传导,它最开始证明了网络能够向更深的方向发展,能够解决网络退化问题。resnet 的残差块结构如下:
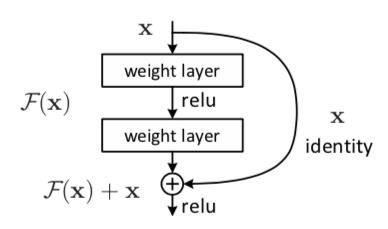
对于检测、识别任务来说,resnet 是一个非常不错的 backbone,能够十分有效的帮你提取到特征,后面再接 neck、head 就能组成完整的网络。介绍 resnet 是因为这里要说的 bn、in 的实现是嵌在 resnet 里的,接下来回到主题,来说一下 bn 和 in。
1、谈谈 bn
bn 全称是 batch normalization,是通过标准化让数据分布在线性区间,加大了梯度,让模型更大胆的进行梯度下降,可以解决因网络深度加深而导致梯度弥散问题,并且由于破坏了原来的数据分布,可以一定程度上解决过拟合问题。
batch normalization 的原理是这样的,如下图,bn 是整个 batch 每一张图的同一个通道一起做 normalization 操作,通俗点就是把每个通道 C 的 NHW 单独拿出来做归一化处理。

整个 bn 算子的计算过程数学表达如下:

前面提到的 resnet 里面有许多的 conv + bn + activation 的结构,这个结构对于做算法加速的人来说应该十分敏感了,一看到就想把它们揉在一块做算子融合。以最经典的 conv + bn 融合为例,数学原理上是这样的:
conv 层:

bn 层:

进行融合,把 conv 代入 bn:

融合后成了一个大卷积,相当于:
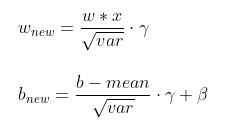
到这里其实比较关键了,有想过为什么要做算子融合吗,直观上考虑,算子融合能减少算子数量、减少算子间通信与中间存储,从而达到算法加速的目的。这当然没问题,不过对于 conv + bn 的融合来说,最实质的提升在于:由于 bn 的 mean 和 var 是离线计算好的,所以 conv + bn 融合后的大卷积里的 w_new 和 b_new 完全可以提前计算好,这相当于什么呢,就是原先我需要做一次卷积 (矩阵乘,tensorcore / cube 等矩阵运算单元) 和 一次 bn (点乘,vector 矢量计算单元),融合后我就把 矢量计算单元的运算 咔擦掉了,同时将两次计算降为1次,你想想是不是性能提升会非常多。
2、谈谈 in
in 全称是 instance normalization,适用于图像风格迁移,因为图像生成的结果主要依赖于单个图像,所以像 bn 那样对整个 batch 归一化并不适合,在风格迁移中使用 in 来做归一化不仅能够加速模型收敛,还可以保持每个图像实例之间的独立性。
instance normalization 的原理是这样的,如下图,in 是单张图片的单个通道单独做 normalization 操作,通俗点就是把每个 HW 单独拿出来做归一化处理,不受 通道 和 batchsize 的影响。

整个 in 算子的计算过程数学表达如下:
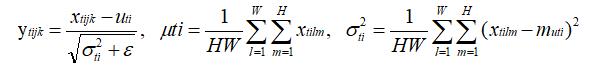
其中,
- t:表示图片的 index;
- i:表示 feature map 的 index;
既然 in 主要用于风格迁移领域,那么跟我们的检测 / 识别或其他领域有毛线关系呢?让我们来看一下下面的网络结构和一组数据你就清楚了。如下是 IBN 结构 和 前面提到的 resnet 中残差结构的对比图,可以看到 IBN-a 的做法是将 feature map 对半切,一半走 in,一半走 bn,形成 bn 和 in 并联结构;而 IBN-b 是在残差后 relu 激活前加入一个 in,形成 bn 和 in 串联结构。

来看一组实验数据:
对于分类问题来说,如下,IBN-a 和 IBN-b 相比 resnet50 具有更好的效果。

对于分割来说,训练集和测试集来自同一个数据的时候,IBN-a 模型的 mIoU 是能够比原模型 resnet50 高 4 个点。而训练集和测试集不同的时候,IBN-b 模型更占优势,说明 IBN-b 能够在跨域的问题上表现更好。

关于 IBN,做一些小结:
(1)IBN-a 适用于 当前域 和 目标域 一致的问题,比如说需提升 resnet50 的分类能力时,可以用 IBN-a;
(2)IBN-b 适合使用在 当前域 和 目标域 不一致的问题,比如说在行人重识别中,经常涉及跨域场景,这也是为何 IBN-Net 在行人重识别领域用的非常多的原因;
以上,现在有一些应用网络针对不同的应用场景,开始使用带 IBN 结构的 backbone,来提高 backbone 在特定场景的特征提取能力,所以我们对 in 算子的部署也需要有所研究。
3、谈谈部署中的 bn 和 in
从部署的角度来看 bn 和 in,其实前面 bn 那一块对 bn 的部署已经进行了一些介绍了,包括 conv + bn 的融合,以及为什么融合能加速。这里再谈谈 in 相对于 bn 在部署的时候有啥区别。
in 最开始用于图像风格迁移,对于风格生成来说,单图独立性和动态性就比较重要,这导致 in 的 均值 mean 和 方差 var 往往是在推理时在线计算的,其实在 pytorch 的 nn.InstanceNorm2d() 算子中有参数可以在训练时把 均值 和 方差 进行离线保存。这个时候我们先来看一下,对于部署来说 bn 需要四个权重,分别是 mean、var、scale 和 bias,相应的 in 也是需要这四个权重,当然两者计算过程不一样。回到前面说的,如果训练时我把 in 的 mean 和 var 进行离线保存,然后我像 bn 一样做一波融合操作,有了离线的四个权重我就可以提前算好融合后大卷积的 new_scale 和 new_bias,然后进 tensorcore 或 cube 矩阵运算单元 计算一下,岂不是完美,加速妥妥的,这样看 in 和 bn 在部署上也没啥区别…
问题来了,我们实验验证,在我们的场景中,in 采用 均值 和 方差 离线存储模式得到的模型精度相比 推理在线计算降了老多…这样的话,我们就必须在线计算 in 的 均值 和 方差了,这样即使你能做算子融合,融合后的 new_scale 和 new_bias 里的 mean 和 var 也是需要动态计算的,这个时候其实是将原来 conv + in 需要四次计算 (conv 1次 + mean 1次 + var 1次 + in 1 次) 减少到了三次计算 (mean 1次 + var 1次 + conv 1 次),是会有性能提升,但是相比于 conv + bn 融合后的 一次计算来说还差很多。
我之前有用 tvm 的 te 模块实现过 bn 和 in 算子,我把我写的计算部分拿出来给大家看一看。
bn_compute 部分如下,可以看到关键部分其实只有一个 out = te.compute…

in_compute 部分如下,我这里是把 mean 和 var 的计算过程拆开来写的,其实也可以把 in_compute… 里面的注释打开,这样相当于把 mean 、 var 和 in 的计算写到了一起,但是不管怎么样,整体的 in 计算过程都是有三个 te.compute… 的。

以上给出了 tvm compute 部分,其实 op schedule 也是一样,in 相比 bn 会多出对 mean 和 var 计算调度的过程。
小结一下,从部署的角度来看 bn 和 in 算子,如果 in 算子的 mean 和 var 是训练时离线存储的,那么 in 和 bn 在部署和推理效率上和 bn 是差不多的;如果 in 算子的 mean 和 var 是推理时在线计算的,那么 in 会比 bn 效率低,这样的 in 其实对于部署不是很友好。
好了,收工~ 欢迎讨论~
扫描下方二维码即可关注我的微信公众号【极智视界】,获取更多AI经验分享,让我们用极致+极客的心态来迎接AI !

以上是关于模型推理从部署的角度看 bn 和 in 算子的主要内容,如果未能解决你的问题,请参考以下文章