模型推理教你 tensorrt 实现 mish 算子
Posted 极智视界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了模型推理教你 tensorrt 实现 mish 算子相关的知识,希望对你有一定的参考价值。
欢迎关注我的公众号 [极智视界],获取我的更多笔记分享
O_o >_< o_O O_o ~_~ o_O
本文介绍了使用 tensorrt 实现 mish 算子的方法。
相信做过目标检测的同学对 yolo 肯定比较熟悉了,yolov4是 2020 年初提出的,相继后来有了 yolov5 和其他一些变体,yolov4 中汇集了很多 tricks,其中 mish 激活函数也在其中。mish 在这篇论文《Mish: A Self Regularized Non-Monotonic Activation Function》里进行了详细介绍,这里我做了一些函数本身的介绍以及 tensorrt 怎么样去实现 mish 算子。
1、mish 函数数学表达
mish 的数学表达式如下:
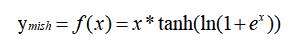
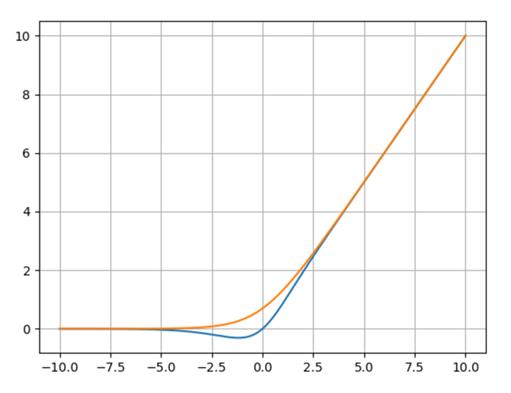
函数的图像表达如下,其中:
- 蓝色曲线为:mish
- 橙色曲线为:ln(1 + e^(x))
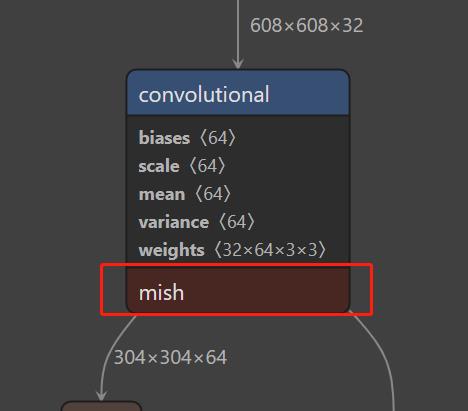
让我们来看看 mish 在 yolov4 里的样子:
也可以把 mish 看成由 tanh 和 softplus 组合起来的。让我们来看下,tanh 的数学表达如下:
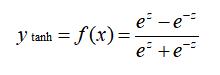
softplus 的数学表达如下,softplus 可以看作是 relu 的平滑。
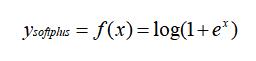
以上对比了 mish、tanh、softplus 的数学表达式,你可以很容易就发现 mish 也可以写成这样:
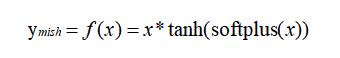
2、mish 对比 relu
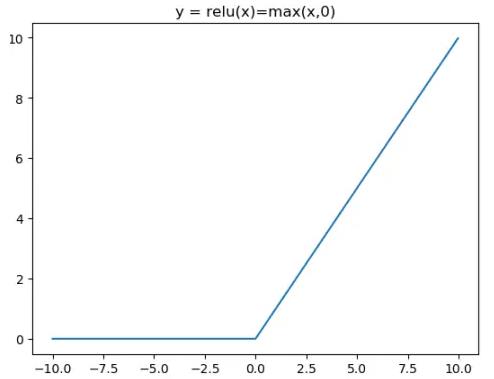
relu 因其能克服梯度消失和加快训练收敛,可以说是最常用的激活函数了,relu 是个分段函数,数学表达式如下:
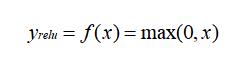
函数图像表达如下:
这里拿 mish 和 relu 作对比,就是有硬碰硬的感觉。拿论文《Mish: A Self Regularized Non-Monotonic Activation Function》的一些实验进行说明。
这是 relu 和 mish 的梯度对比,可以看到 mish 的梯度更加平滑。

精度方面,在 ImageNet-1K 数据集上对 mish、swish、relu、leaky relu 激活函数对网络精度的提升对了对比,数据如下:
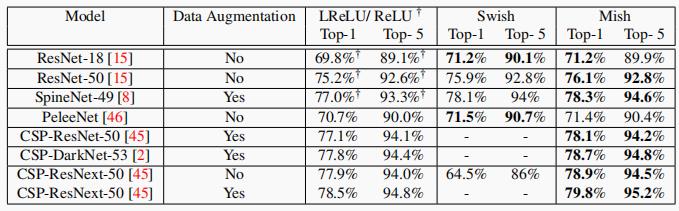
以下是在 MS-COCO 目标检测数据集的对比数据:
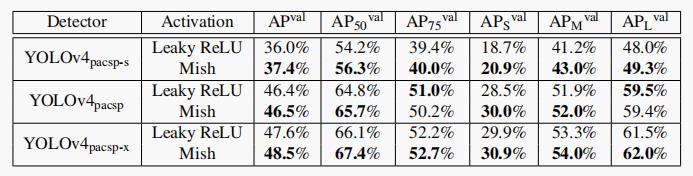
从实测的精度提升数据来看,mish 具有十分明显的优势。
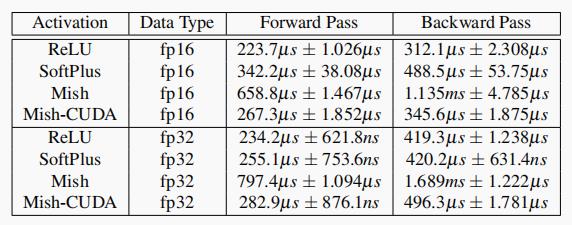
性能方面,在 pytorch 框架中,对 relu、softplus、mish、mish-cuda (RTX-2070) 在 fp32 和 fp16 精度下进行了性能对比,数据如下,可以看到 relu 在推理效率上要比 mish 快,mish-cuda 在用 cuda 进行优化后性能能提升很多。
3、tensorrt 实现 mish 算子
先让我们来看一下 tensorrt API 直接支持的激活函数算子:
//!
//! \\enum ActivationType
//!
//! \\brief Enumerates the types of activation to perform in an activation layer.
//!
enum class ActivationType : int32_t
{
kRELU = 0, //!< Rectified linear activation.
kSIGMOID = 1, //!< Sigmoid activation.
kTANH = 2, //!< TanH activation.
kLEAKY_RELU = 3, //!< LeakyRelu activation: x>=0 ? x : alpha * x.
kELU = 4, //!< Elu activation: x>=0 ? x : alpha * (exp(x) - 1).
kSELU = 5, //!< Selu activation: x>0 ? beta * x : beta * (alpha*exp(x) - alpha)
kSOFTSIGN = 6, //!< Softsign activation: x / (1+|x|)
kSOFTPLUS = 7, //!< Parametric softplus activation: alpha*log(exp(beta*x)+1)
kCLIP = 8, //!< Clip activation: max(alpha, min(beta, x))
kHARD_SIGMOID = 9, //!< Hard sigmoid activation: max(0, min(1, alpha*x+beta))
kSCALED_TANH = 10, //!< Scaled tanh activation: alpha*tanh(beta*x)
kTHRESHOLDED_RELU = 11 //!< Thresholded ReLU activation: x>alpha ? x : 0
};
可以看到像 relu、sigmoid、tanh … 这些你都不用自己去写,直接调 trt 的 api 就好了。我们这里的 mish 不是直接支持的,所以用 trt 来实现的话基本有两种思路:
(1) 用已有算子组合,mish 的话可以用 tanh 和 softplus 组合起来;
(2) 用 cuda kernel 实现,用 plugin 注册进 trt 使用;
下面进行介绍。
3.1 已有算子组合实现
这个其实很好写,看看 mish 的数学表达:
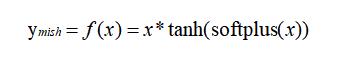
所以基本思路就是先调一个 softplus,再调一个 tanh,把 softplus 的结果传给 tanh,tanh 的输出就等效于一个 mish 的输出。关键代码如下:
########### softplus ############
# 需要注意,trt 里的 softplus 长这样:alpha*log(exp(beta*x)+1)
activationSP = network->addActivation(*Layers[inputName], nvinfer1::ActivationType::kSOFTPLUS);
# 将 alpha 和 beta 设置为 1
activationSP->setAlpha(1);
activationSP->setBeta(1);
############# tanh ##############
nvinfer1::ITensor *activationSP_Out = activationSP->getOutput(0);
mish = network->addActivation(*activationSP_Out, nvinfer1::ActivationType::kTANH);
以上就完成了使用 tensorrt 已有算子组合来实现 mish 操作。
3.2 cuda + plugin 实现
将 mish 进行数学等价转换,转换成如下数学表达:
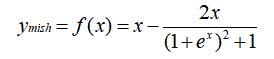
基本思想就是用 cuda 来直接实现,把原来用 tanh 和 softplus 组合需要两个算子变为一个算子。这里不说用 cuda kernel 怎么去实现了,说一下怎么把 .cu 通过 plugin 注册进 tensorrt 把。
首先你需要有个头,类似这样:
/// mish.h
#include<NvInfer.h>
#include<NvInferPlugin.h>
calss MishLayerPlugin : public IPluginExt
{
void mish_infer(...);
}
然后是 .cu,里面是算子 gpu_infer 的实现,差不多像这样:
/// mish.cu
#include "mish.h"
__global__ void mish(...)
{
...;
}
void MishLayerPlugin::mish_infer(...)
{
mish<<<xx, xx>>>(...);
}
最后是 .cpp 里通过 plugin 注册进 tensorrt,差不多像这样:
/// tensort-mish.cpp
#include "mish.h"
void addmish_layer(...)
{
nvinfer1::DataType Dtype;
Dtype = nvinfer1::DataType::kFLOAT;
nvinfer1::IPluginExt *mish = new MishLayerPlugin(xxx, Dtype);
nvinfer1::IPluginLayer *mish_layer = m_network->addPluginExt(&Layers[inputName], 1, *mish);
...
}
好了,收工~
扫描下方二维码即可关注我的微信公众号【极智视界】,获取更多AI经验分享,让我们用极致+极客的心态来迎接AI !

以上是关于模型推理教你 tensorrt 实现 mish 算子的主要内容,如果未能解决你的问题,请参考以下文章