Python爬虫之链家二手房数据爬取
Posted 在奋斗的大道
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫之链家二手房数据爬取相关的知识,希望对你有一定的参考价值。
Python 依赖模块:
- requests
- parsel
- csv
功能要求:
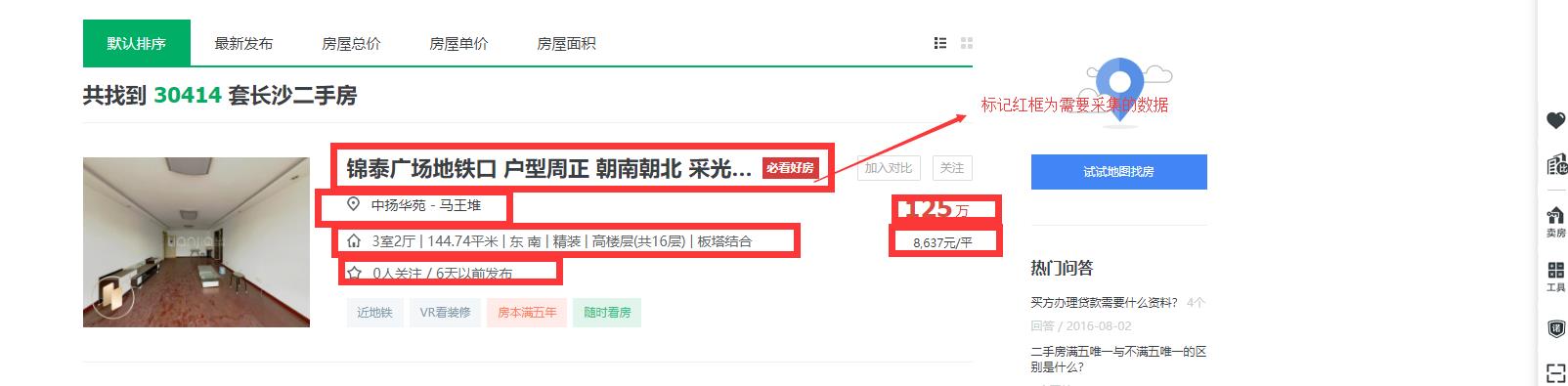
请求网页
打开开发者工具( F12或者鼠标右键点击检查 )选择 notework 查看数据返回的内容。
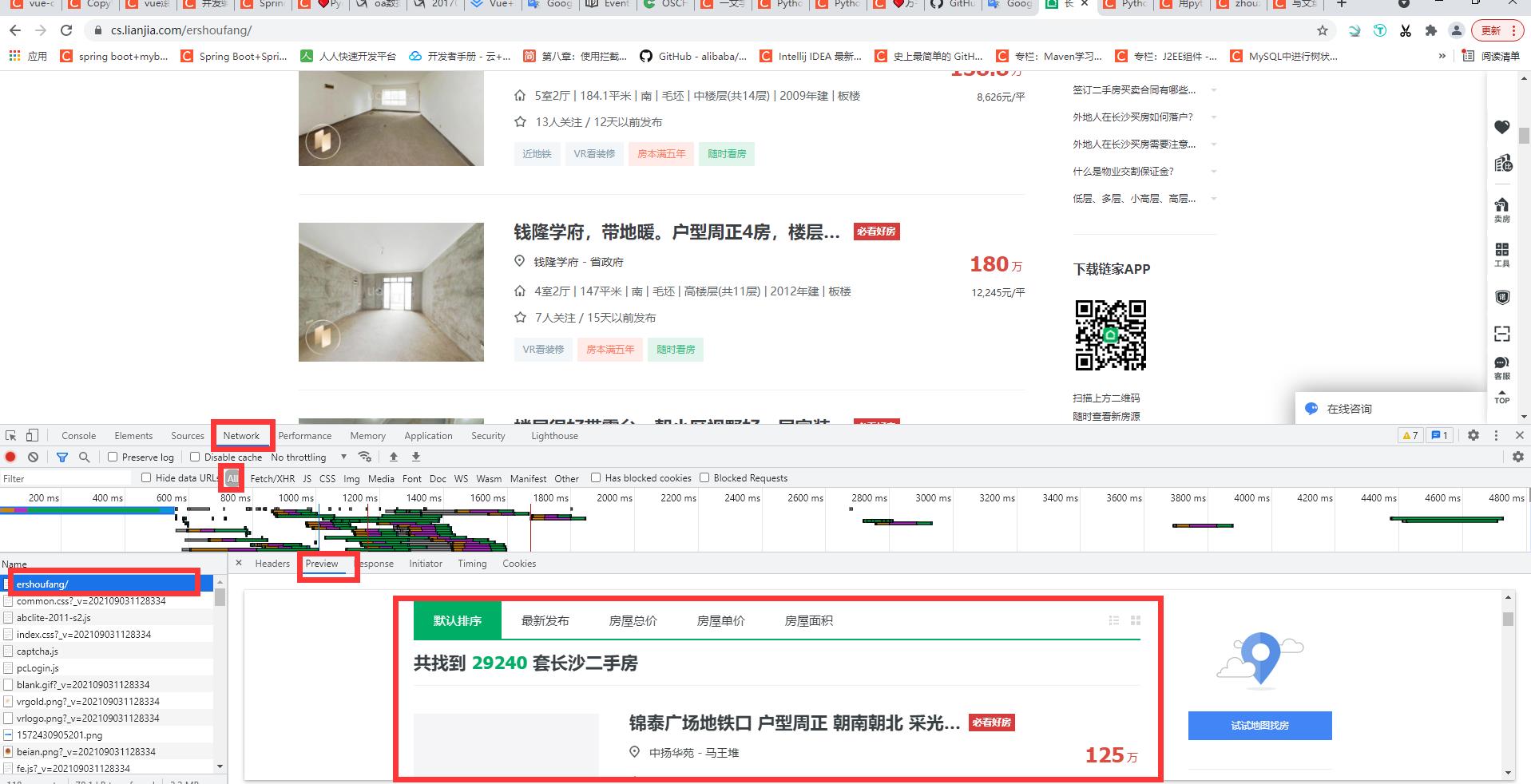
通过开发者工具可以看到,网站是静态网页数据,请求url地址是可以直接获取数据内容的。
url = 'https://cs.lianjia.com/ershoufang/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (Khtml, like Gecko) '
'Chrome/81.0.4044.138 '
'Safari/537.36 '
}
response = requests.get(url=url, headers=headers)
print(response.text)解析数据
网站是静态网页数据,那么就可以直接在开发者工具中 Elements 查看数据在哪
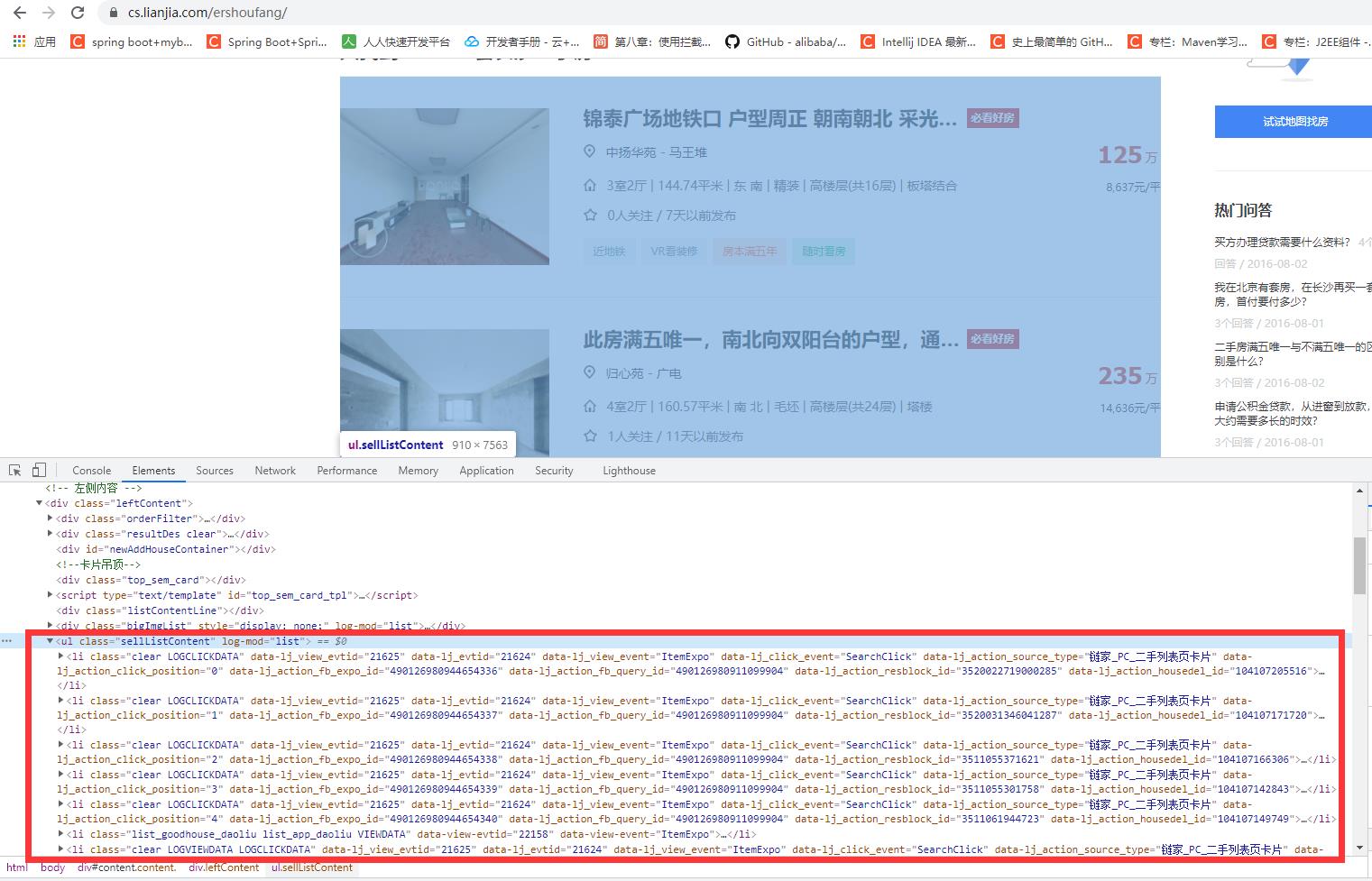
如上图所示,相关的数据内容都包含在 li 标签里面。通过 parsel 解析库,进行解析提取数据就可以了。
selector = parsel.Selector(response.text)
lis = selector.css('.sellListContent li')
for li in lis:
# 标题
title = li.css('.title a::text').get()
# 地址
positionInfo = li.css('.positionInfo a::text').getall()
community = ''
address = ''
if len(positionInfo):
# 小区
community = positionInfo[0]
# 地名
address = positionInfo[1]
# 房子基本信息
houseInfo = li.css('.houseInfo::text').get()
# 房价
print('数据类型:', type(li.css('.totalPrice span::text').get()))
txt = li.css('.totalPrice span::text').get()
Price = ''
if isinstance(txt, str):
Price = li.css('.totalPrice span::text').get() + '万'
# 单价
print('单价数据类型:', type(li.css('.unitPrice span::text').get()))
txt = li.css('.unitPrice span::text').get()
unitPrice = ''
if isinstance(txt, str):
unitPrice = li.css('.unitPrice span::text').get().replace('单价', '')
# 发布信息
followInfo = li.css('.followInfo::text').get()
dit = {
'标题': title,
'小区': community,
'地名': address,
'房子基本信息': houseInfo,
'房价': Price,
'单价': unitPrice,
'发布信息': followInfo,
}
print(dit)
保存数据(数据持久化)
使用csv模块,把数据保存到Excel里面
# 创建文件
f = open('长沙二手房数据.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['标题', '小区', '地名', '房子基本信息',
'房价', '单价', '发布信息'])
# 写入表头
csv_writer.writeheader()
'''
'''
csv_writer.writerow(dit)多页爬取
for page in range(1, 101):
url = 'https://cs.lianjia.com/ershoufang/'
downloadLianjia(url)
def downloadLianjia(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/81.0.4044.138 '
'Safari/537.36 '
}
response = requests.get(url=url, headers=headers)
print(response.text)
selector = parsel.Selector(response.text)
lis = selector.css('.sellListContent li')
for li in lis:
# 标题
title = li.css('.title a::text').get()
# 地址
positionInfo = li.css('.positionInfo a::text').getall()
community = ''
address = ''
if len(positionInfo):
# 小区
community = positionInfo[0]
# 地名
address = positionInfo[1]
# 房子基本信息
houseInfo = li.css('.houseInfo::text').get()
# 房价
print('数据类型:', type(li.css('.totalPrice span::text').get()))
txt = li.css('.totalPrice span::text').get()
Price = ''
if isinstance(txt, str):
Price = li.css('.totalPrice span::text').get() + '万'
# 单价
print('单价数据类型:', type(li.css('.unitPrice span::text').get()))
txt = li.css('.unitPrice span::text').get()
unitPrice = ''
if isinstance(txt, str):
unitPrice = li.css('.unitPrice span::text').get().replace('单价', '')
# 发布信息
followInfo = li.css('.followInfo::text').get()
dit = {
'标题': title,
'小区': community,
'地名': address,
'房子基本信息': houseInfo,
'房价': Price,
'单价': unitPrice,
'发布信息': followInfo,
}
print(dit)
# 创建文件
f = open('长沙二手房数据.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['标题', '小区', '地名', '房子基本信息',
'房价', '单价', '发布信息'])
# 写入表头
csv_writer.writeheader()
'''
'''
csv_writer.writerow(dit)效果展示:
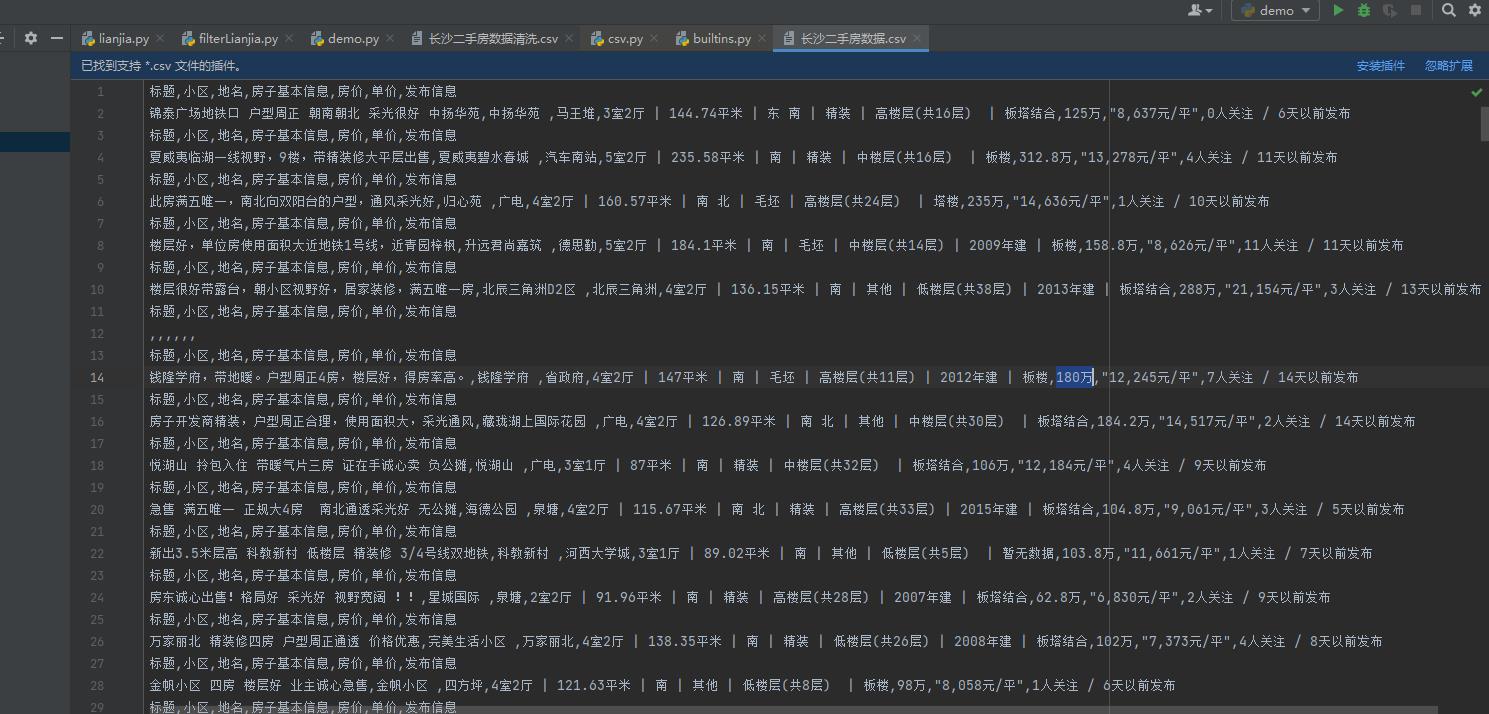
以上是关于Python爬虫之链家二手房数据爬取的主要内容,如果未能解决你的问题,请参考以下文章