爬虫练习三:爬取链家二手房信息
Posted xingyucn
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫练习三:爬取链家二手房信息相关的知识,希望对你有一定的参考价值。
在坐地铁通勤的时候看到了一些售房广告,所以这次想要尝试爬取链家发布的各个城市二手房信息,并将其写入本地数据库
1. 网页查看
1)以北京为例
我们要访问的url是https://bj.lianjia.com/ershoufang/。
越过页面上方的筛选区域,就下来就是我们想要爬取的数据。
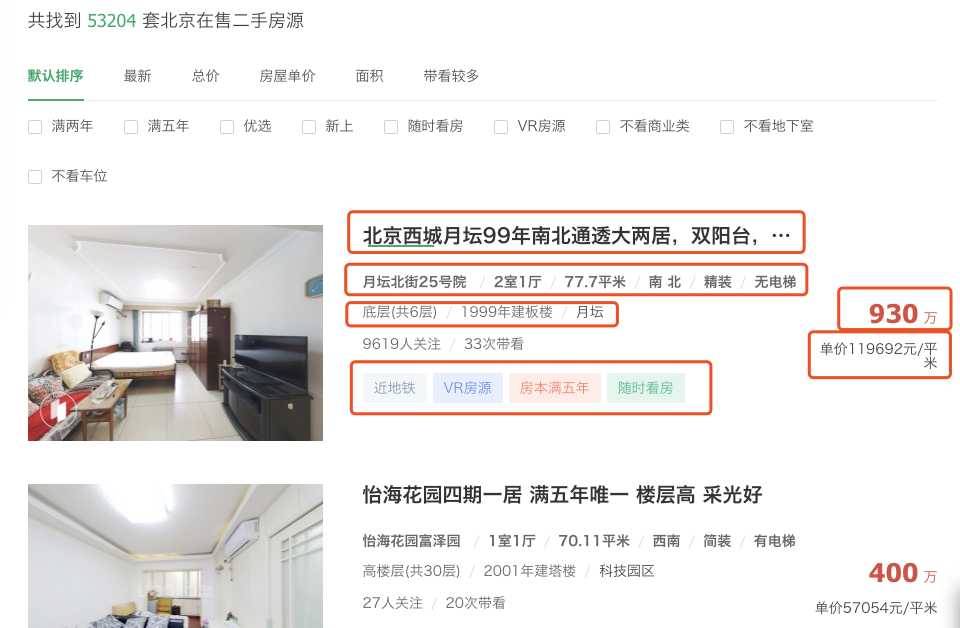
F12检查网页:
a. 发现房屋的基本信息并不是通过异步加载来获取的,直接通过html代码就可以拿到。所以我们只要访问url就可以爬取到房屋基本信息。
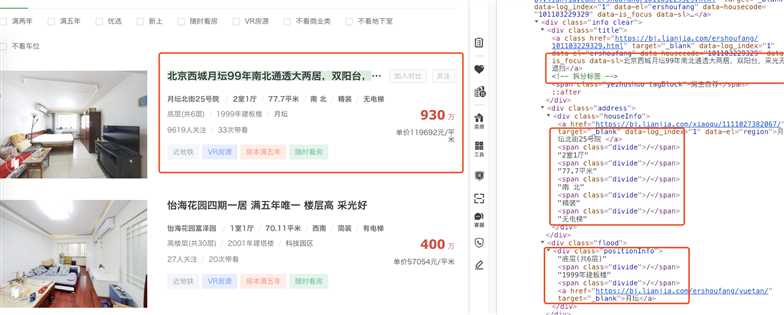
b. 每一页只显示30条记录,进行翻页后发现:第二页url为https://bj.lianjia.com/ershoufang/pg2/,第三页url为https://bj.lianjia.com/ershoufang/pg3/
所以我们只需要对url进行修改即可实现翻页。但是最多只显示100页,将url修改为pg101访问结果是错误。
c. 同时,随着页面的不断下拉,发现有一些jpg是通过异步加载获取的,对应到主页面就是每个房屋对应的图片。因为图片信息不在我们这次要抓取的范围内,所以就不管它了。
2)拓展至全国各城市
北京二手房对应的url是https://bj.lianjia.com/ershoufang/,由此猜测,lianjia前的bj就是城市拼音首字母,修改bj就可以切换成其他城市。
比如修改后深圳二手房对应的url就是https://sz.lianjia.com/ershoufang/,而这个修改后的url也确实是正确的。
然后,问题来了,并不是链家上每个城市都有二手房服务,也不是每个城市的拼音首字母都是唯一的,比如深圳和苏州。
所以我们需要知道,在链家上都有提供哪些城市的服务,这些城市对应的url各是什么。
发现链家有一个切换城市的页面,跳转入新页面后,新页面陈列了各个城市,检查元素中也发现了每个城市对应的url。

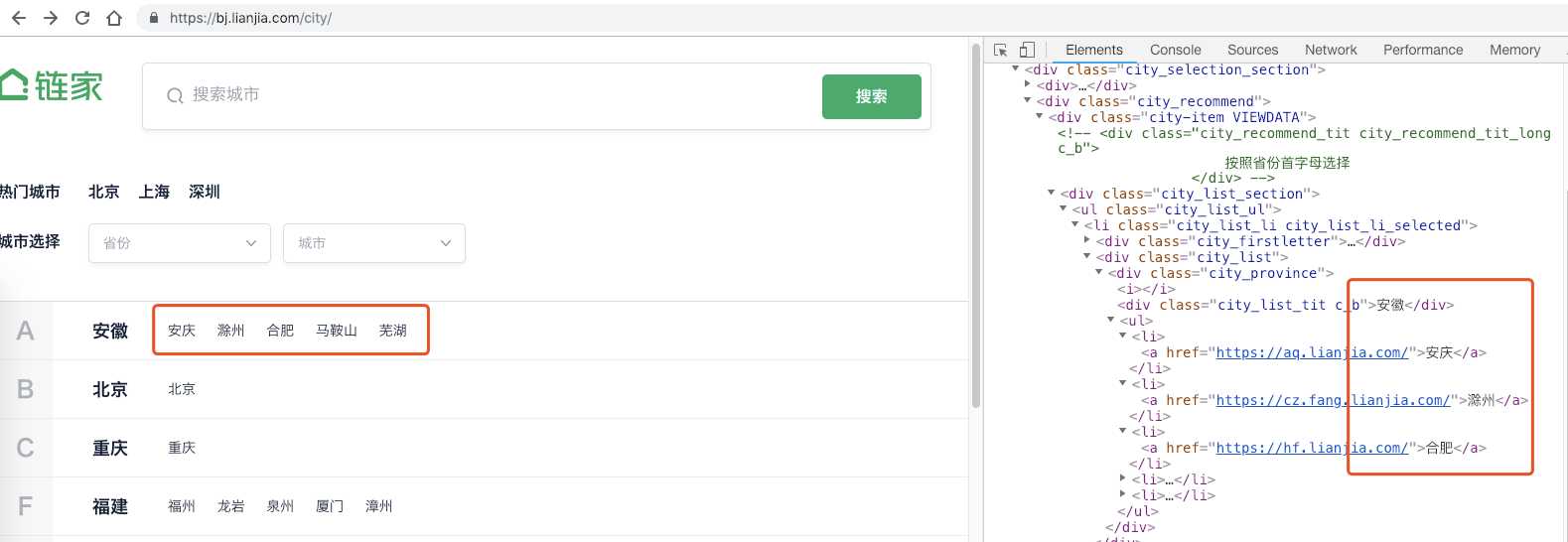
在拿到的url后加上ershoufang就得到了每个城市二手房的url。
2. 关于反爬
链家反爬难度还是比较小的,主要在于:
1)Headers请求头信息:使用requests进行请求时如果没有附上请求头,就会返回403错误
2)Referer信息:每次请求时请求头都包含上一请求url,如果这个地方不对就容易被反爬机制介入
解决方法:
伪造Headers信息,爬取每个城市的二手房信息都使用一个单独的session。cookies通过session维持,Referer指向上一访问url,Host为该城市首页url
3. 代码实现
import requests from bs4 import BeautifulSoup import time import random import pymysql # 从首页获取所有城市的url def get_city_url(): url = ‘https://aq.lianjia.com/city/‘ header = { ‘Accept‘: ‘text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8‘, ‘Accept-Encoding‘: ‘gzip, deflate, br‘, ‘Accept-Language‘: ‘zh-CN,zh;q=0.9‘, ‘Connection‘: ‘keep-alive‘, ‘Cookie‘: ‘lianjia_uuid=07e69a53-d612-4caa-9145-b31c2e9410f4; _smt_uid=5c2b6394.297c1ea9; UM_distinctid=168097cfb8db98-058790b6b3796c-10306653-13c680-168097cfb8e3fa; Hm_lvt_9152f8221cb6243a53c83b956842be8a=1546347413; _ga=GA1.2.1249021892.1546347415; _gid=GA1.2.1056168444.1546347415; all-lj=c60bf575348a3bc08fb27ee73be8c666; TY_SESSION_ID=d35d074b-f4ff-47fd-9e7e-8b9500e15a82; CNZZDATA1254525948=1386572736-1546352609-https%253A%252F%252Fbj.lianjia.com%252F%7C1546363071; CNZZDATA1255633284=2122128546-1546353480-https%253A%252F%252Fbj.lianjia.com%252F%7C1546364280; CNZZDATA1255604082=1577754458-1546353327-https%253A%252F%252Fbj.lianjia.com%252F%7C1546366122; lianjia_ssid=087352e7-de3c-4505-937e-8827e808c2ee; select_city=440700; Hm_lpvt_9152f8221cb6243a53c83b956842be8a=1546391853‘, ‘DNT‘: ‘1‘, ‘Host‘: ‘aq.lianjia.com‘, ‘Referer‘: ‘https://aq.lianjia.com/‘, ‘Upgrade-Insecure-Requests‘: ‘1‘, ‘User-Agent‘: ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36‘ } index_response = requests.get(url=url, headers=header) if index_response.status_code!=200: print(‘connect index False‘) index_soup = BeautifulSoup(index_response.text, ‘lxml‘) city_url_dict = {} for each_province in index_soup.findAll(‘div‘, class_=‘city_list‘): for each_city in each_province.findAll(‘li‘): city_url_dict[each_city.get_text()] = each_city.find(‘a‘)[‘href‘] return city_url_dict def get_house_info(city_url, city_name): session0_header = { ‘Accept‘: ‘text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8‘, ‘Accept-Encoding‘: ‘gzip, deflate, br‘, ‘Accept-Language‘: ‘zh-CN,zh;q=0.9‘, ‘Connection‘: ‘keep-alive‘, ‘DNT‘: ‘1‘, ‘Host‘: city_url.split(‘/‘)[-2], ‘Upgrade-Insecure-Requests‘: ‘1‘, ‘User-Agent‘: ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36‘ } # 会话构建,首先访问该城市首页url,获取cookies信息 session0 = requests.session() session0.get(url=city_url, headers=session0_header) # 没想到一个方便的方法来保存上一访问的url,用于填入Referer。 # 直接生成一个列表,列表内包含该城市所有待访问的url page_url = [city_url, city_url+‘ershoufang‘]+[city_url+‘ershoufang/pg{}/‘.format(str(i)) for i in range(2, 101)] all_house_list = [] for i in range(1, 101): # 为每一个页面构建不同的Referer信息 header = { ‘Accept‘: ‘text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8‘, ‘Accept-Encoding‘: ‘gzip, deflate, br‘, ‘Accept-Language‘: ‘zh-CN,zh;q=0.9‘, ‘Connection‘: ‘keep-alive‘, ‘DNT‘: ‘1‘, ‘Host‘: city_url.split(‘/‘)[-2], ‘Referer‘: page_url[i-1], ‘Upgrade-Insecure-Requests‘: ‘1‘, ‘User-Agent‘: ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36‘ } index_response = session0.get(url=page_url[i], headers=header) # 有些城市可能没有100页的二手房信息,因此执行完最后一页就需要跳出循环 # 或者没有成功访问页面,返回的状态码不是200,跳出循环 if index_response.status_code!=200: print(city_name, ‘page‘, str(i), ‘pass‘) break time.sleep(random.uniform(2, 4)) index_soup = BeautifulSoup(index_response.text, ‘lxml‘) try: for each_house in index_soup.findAll(‘li‘, class_=‘clear LOGCLICKDATA‘): each_house_dict = { ‘house_code‘: each_house.find(‘div‘, class_=‘title‘).find(‘a‘)[‘data-housecode‘], ‘house_url‘: each_house.find(‘div‘, class_=‘title‘).find(‘a‘)[‘href‘], ‘house_name‘: each_house.find(‘div‘, class_=‘title‘).find(‘a‘).get_text(), ‘house_desc‘: each_house.find(‘div‘, class_=‘houseInfo‘).get_text().replace(‘ ‘, ‘‘), ‘xiaoqu_info‘: each_house.find(‘div‘, class_=‘positionInfo‘).get_text().replace(‘ ‘, ‘‘), ‘house_tag‘: each_house.find(‘div‘, class_=‘tag‘).get_text(‘/‘), #房屋标签 ‘house_totalPrice‘: each_house.find(‘div‘, class_=‘totalPrice‘).get_text(), #总价 ‘house_unitPrice‘: each_house.find(‘div‘, class_=‘unitPrice‘).get_text(), #单价 ‘city‘: city_name } all_house_list.append(each_house_dict) print(city_name, ‘page‘, str(i), ‘done‘, len(all_house_list)) except: print(city_name, ‘done, no other left.‘)
break
# 因为发现有些城市可能会没有二手房界面,比如滁州。因此加入一个条件判别,如果没有就跳出循环 if i>4 and len(all_house_list)==0: print(city_name, ‘获取失败‘) break return all_house_list # MySQL中创建表 def create_table_mysql(): db = pymysql.connect(host=‘localhost‘, user=‘root‘, password=‘mysqlkey‘, db=‘test_db‘, port=3306) cursor = db.cursor() cursor.execute(‘DROP TABLE IF EXISTS ljesf‘) # 链家二手房 create_table_sql = ‘‘‘ CREATE TABLE ljesf( house_code CHAR(30) COMMENT ‘房屋编号‘, house_url CHAR(100) COMMENT ‘房屋url‘, house_name CHAR(100) COMMENT ‘房屋名字‘, house_desc CHAR(100) COMMENT ‘房屋描述‘, xiaoqu_info CHAR(100) COMMENT ‘小区描述‘, house_tag CHAR(100) COMMENT ‘房屋标签‘, house_total_price CHAR(20) COMMENT ‘总价‘, house_unit_price CHAR(40) COMMENT ‘单价‘, city CHAR(40) COMMENT ‘城市‘ ) ‘‘‘ try: cursor.execute(create_table_sql) db.commit() print(‘create table done‘) except: db.rollback() # 数据库回滚 print(‘create table not done‘) return db, cursor # 插入到数据库 def insert_into_mysql(db, cursor, all_house_list): insert_sql = ‘‘‘ INSERT INTO ljesf( house_code, house_url, house_name, house_desc, xiaoqu_info, house_tag, house_total_price, house_unit_price, city) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s) ‘‘‘ for each in all_house_list: insert_data = [values for key, values in each.items()] cursor.execute(insert_sql, insert_data) try: db.commit() print(‘insert done‘) except: db.rollback() print(‘insert not done‘) city_url_dict = get_city_url() # 获取每个城市对应的二手房url db, cursor = create_table_mysql() # 连接数据库 for key, values in city_url_dict.items(): all_house_list = get_house_info(city_url=values, city_name=key) # 获取每个房屋的信息 insert_into_mysql(db, cursor, all_house_list) # 插入到mysql print(key, ‘done‘) cursor.close() # 关闭游标 db.close() # 关闭数据库连接
4. 实现效果
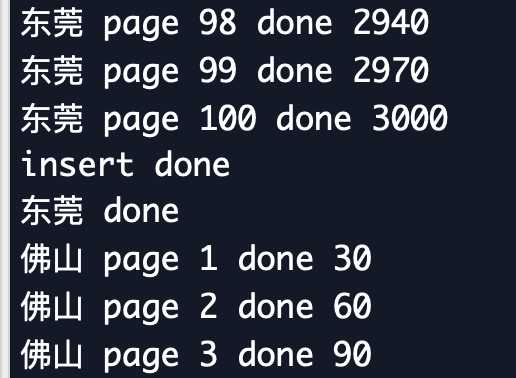
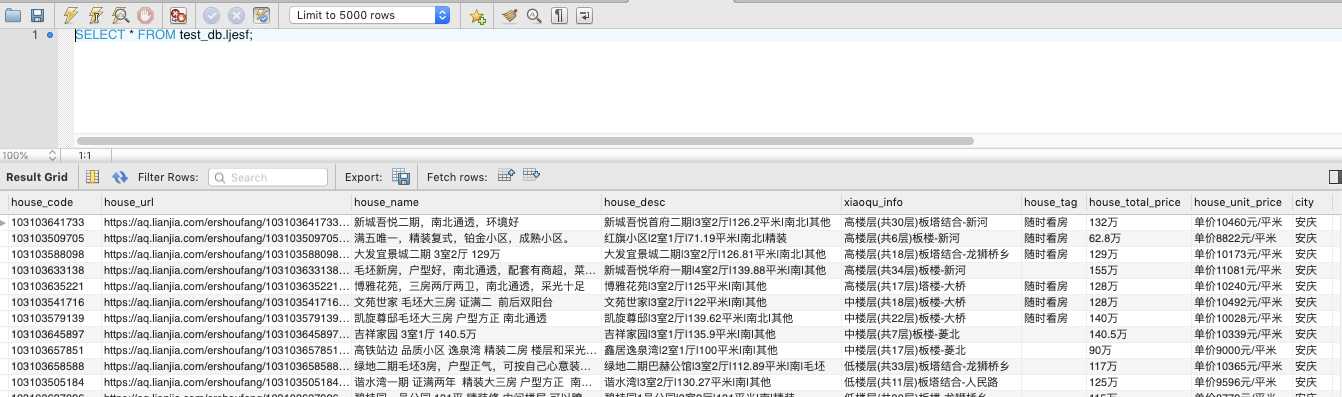
以上是关于爬虫练习三:爬取链家二手房信息的主要内容,如果未能解决你的问题,请参考以下文章