43.scrapy爬取链家网站二手房信息-1
Posted lvjing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了43.scrapy爬取链家网站二手房信息-1相关的知识,希望对你有一定的参考价值。
首先分析:
目的:采集链家网站二手房数据
1.先分析一下二手房主界面信息,显示情况如下:
url = https://gz.lianjia.com/ershoufang/pg1/
显示总数据量为27589套,但是页面只给返回100页的数据,每页30条数据,也就是只给返回3000条数据。
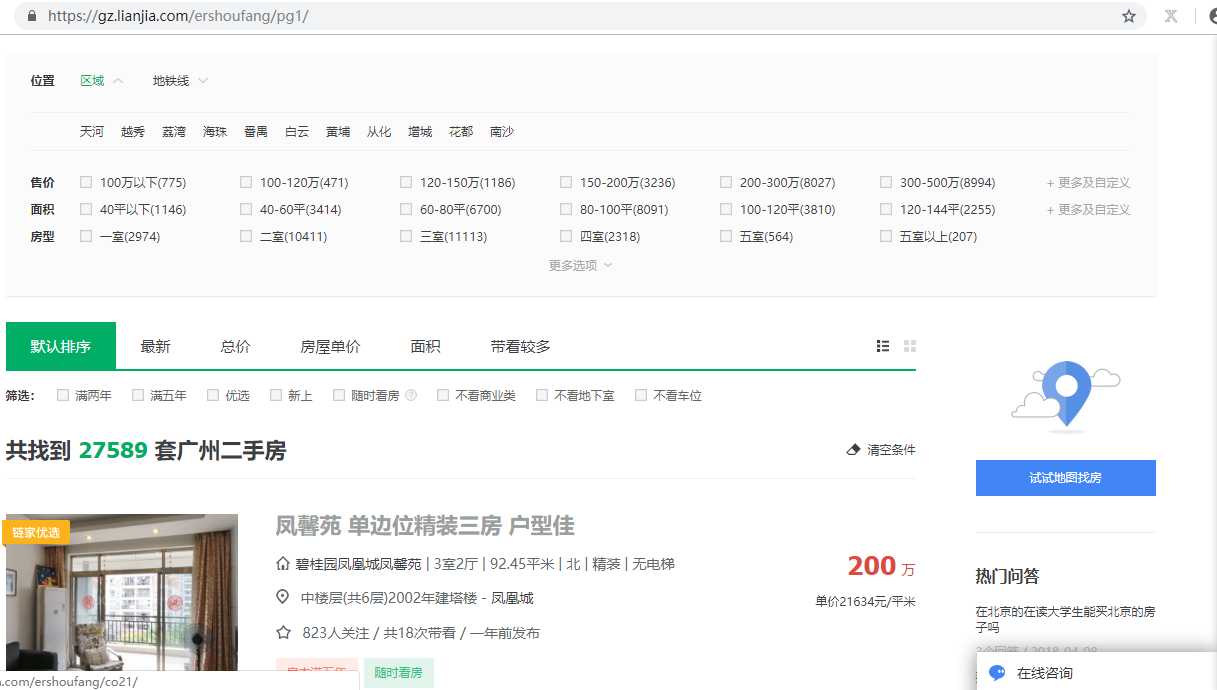
2.再看一下筛选条件的情况:
100万以下(775):https://gz.lianjia.com/ershoufang/pg1p1/(p1是筛选条件参数,pg1是页面参数) 页面返回26页信息
100万-120万(471):https://gz.lianjia.com/ershoufang/pg1p2/ 页面返回16页信息
以此类推也就是网站只给你返回查看最多100页,3000条的数据,登陆的话情况也是一样的情况。
3.采集代码如下:
这个是 linjia.py 文件,这里需要注意的问题就是 setting里要设置
ROBOTSTXT_OBEY = False,不然页面不给返回数据。
# -*- coding: utf-8 -*- import scrapy class LianjiaSpider(scrapy.Spider): name = ‘lianjia‘ allowed_domains = [‘gz.lianjia.com‘] start_urls = [‘https://gz.lianjia.com/ershoufang/pg1/‘] def parse(self, response): #获取当前页面url link_urls = response.xpath("//div[@class=‘info clear‘]/div[@class=‘title‘]/a/@href").extract() for link_url in link_urls: # print(link_url) yield scrapy.Request(url=link_url,callback=self.parse_detail) print(‘*‘*100) #翻页 for i in range(1,101): url = ‘https://gz.lianjia.com/ershoufang/pg{}/‘.format(i) # print(url) yield scrapy.Request(url=url,callback=self.parse) def parse_detail(self,response): title = response.xpath("//div[@class=‘title‘]/h1[@class=‘main‘]/text()").extract_first() print(‘标题: ‘+ title) dist = response.xpath("//div[@class=‘areaName‘]/span[@class=‘info‘]/a/text()").extract_first() print(‘所在区域: ‘+ dist) contents = response.xpath("//div[@class=‘introContent‘]/div[@class=‘base‘]") # print(contents) house_type = contents.xpath("./div[@class=‘content‘]/ul/li[1]/text()").extract_first() print(‘房屋户型: ‘+ house_type) floor = contents.xpath("./div[@class=‘content‘]/ul/li[2]/text()").extract_first() print(‘所在楼层: ‘+ floor) built_area = contents.xpath("./div[@class=‘content‘]/ul/li[3]/text()").extract_first() print(‘建筑面积: ‘+ built_area) family_structure = contents.xpath("./div[@class=‘content‘]/ul/li[4]/text()").extract_first() print(‘户型结构: ‘+ family_structure) inner_area = contents.xpath("./div[@class=‘content‘]/ul/li[5]/text()").extract_first() print(‘套内面积: ‘+ inner_area) architectural_type = contents.xpath("./div[@class=‘content‘]/ul/li[6]/text()").extract_first() print(‘建筑类型: ‘+ architectural_type) house_orientation = contents.xpath("./div[@class=‘content‘]/ul/li[7]/text()").extract_first() print(‘房屋朝向: ‘+ house_orientation) building_structure = contents.xpath("./div[@class=‘content‘]/ul/li[8]/text()").extract_first() print(‘建筑结构: ‘+ building_structure) decoration_condition = contents.xpath("./div[@class=‘content‘]/ul/li[9]/text()").extract_first() print(‘装修状况: ‘+ decoration_condition) proportion = contents.xpath("./div[@class=‘content‘]/ul/li[10]/text()").extract_first() print(‘梯户比例: ‘+ proportion) elevator = contents.xpath("./div[@class=‘content‘]/ul/li[11]/text()").extract_first() print(‘配备电梯: ‘+ elevator) age_limit =contents.xpath("./div[@class=‘content‘]/ul/li[12]/text()").extract_first() print(‘产权年限: ‘+ age_limit) try: house_label = response.xpath("//div[@class=‘content‘]/a/text()").extract_first() except: house_label = ‘‘ print(‘房源标签: ‘ + house_label) # decoration_description = response.xpath("//div[@class=‘baseattribute clear‘][1]/div[@class=‘content‘]/text()").extract_first() # print(‘装修描述 ‘+ decoration_description) # community_introduction = response.xpath("//div[@class=‘baseattribute clear‘][2]/div[@class=‘content‘]/text()").extract_first() # print(‘小区介绍: ‘+ community_introduction) # huxing_introduce = response.xpath("//div[@class=‘baseattribute clear‘]3]/div[@class=‘content‘]/text()").extract_first() # print(‘户型介绍: ‘+ huxing_introduce) # selling_point = response.xpath("//div[@class=‘baseattribute clear‘][4]/div[@class=‘content‘]/text()").extract_first() # print(‘核心卖点: ‘+ selling_point) # 以追加的方式及打开一个文件,文件指针放在文件结尾,追加读写! with open(‘text‘, ‘a‘, encoding=‘utf-8‘)as f: f.write(‘ ‘.join( [title,dist,house_type,floor,built_area,family_structure,inner_area,architectural_type,house_orientation,building_structure,decoration_condition,proportion,elevator,age_limit,house_label])) f.write(‘ ‘ + ‘=‘ * 50 + ‘ ‘) print(‘-‘*100)
4.这里采集的是全部,没设置筛选条件,只返回100也数据。
采集数据情况如下:
这里只采集了15个字段信息,其他的数据没采集。
采集100页,算一下拿到了2704条数据。


4.这个是上周写的,也没做修改完善,之后会对筛选条件url进行整理,尽量采集网站多的数据信息。
以上是关于43.scrapy爬取链家网站二手房信息-1的主要内容,如果未能解决你的问题,请参考以下文章