基于AOP和HashMap原理学习,开发Mysql分库分表路由组件!
Posted 小傅哥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于AOP和HashMap原理学习,开发Mysql分库分表路由组件!相关的知识,希望对你有一定的参考价值。

作者:小傅哥
博客:https://bugstack.cn
沉淀、分享、成长,让自己和他人都能有所收获!😄
一、前言
什么?Java 面试就像造火箭🚀

单纯了! 以前我也一直想 Java 面试就好好面试呗,嘎哈么总考一些工作中也用不到的玩意,会用 Spring、MyBatis、Dubbo、MQ,把业务需求实现了不就行了!
但当工作几年后,需要提升自己(要加钱)的时候,竟然开始觉得自己只是一个调用 API 攒接口的工具人。没有知识宽度,没有技术纵深,也想不出来更没有意识,把日常开发的业务代码中通用的共性逻辑提炼出来,开发成公用的组件,更没有去思考日常使用的一些组件是用什么技术实现的。
所以有时候你说面试好像就是在造火箭,这些技术日常根本用不到,其实很多时候不是这个技术用不到,而是因为你没用(嗯,以前我也没用)。当你有这个想法想突破自己的薪资待遇瓶颈时,就需要去了解了解必备的数据结构、学习学习Java的算法逻辑、熟悉熟悉通用的设计模式、再结合像 Spring、ORM、RPC,这样的源码实现逻辑,把相应的技术方案赋能到自己的日常业务开发中,把共性的问题用聚焦和提炼的方式进行解决,这些才是你在 CRUD 之外的能力体现(加薪筹码)。
怎么? 好像听上去有道理,那么举个栗子,来一场数据库路由的需求分析和逻辑实现!
二、需求分析
如果要做一个数据库路由,都需要做什么技术点?
首先我们要知道为什么要用分库分表,其实就是由于业务体量较大,数据增长较快,所以需要把用户数据拆分到不同的库表中去,减轻数据库压力。
分库分表操作主要有垂直拆分和水平拆分:
- 垂直拆分:指按照业务将表进行分类,分布到不同的数据库上,这样也就将数据的压力分担到不同的库上面。最终一个数据库由很多表的构成,每个表对应着不同的业务,也就是专库专用。
- 水平拆分:如果垂直拆分后遇到单机瓶颈,可以使用水平拆分。相对于垂直拆分的区别是:垂直拆分是把不同的表拆到不同的数据库中,而水平拆分是把同一个表拆到不同的数据库中。如:user_001、user_002
而本章节我们要实现的也是水平拆分的路由设计,如图 1-1
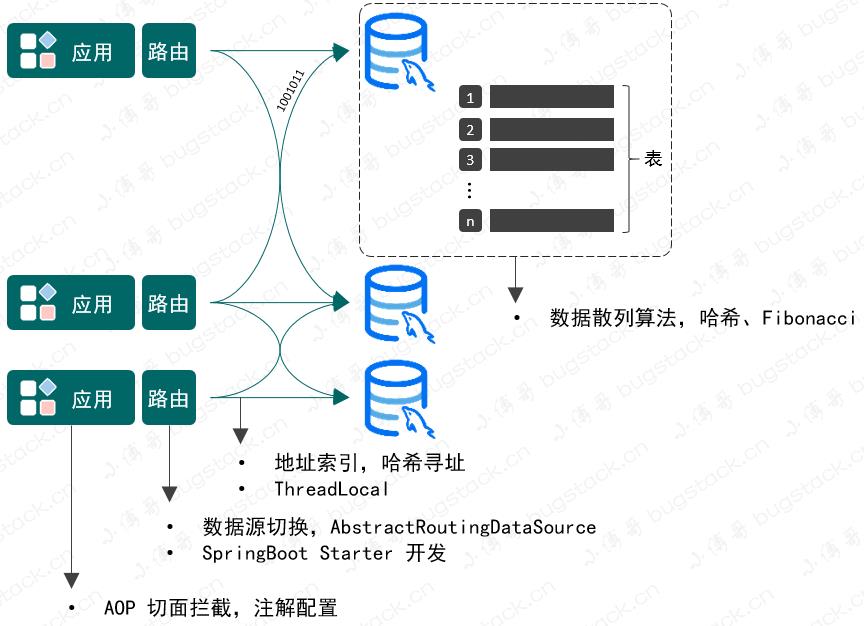
那么,这样的一个数据库路由设计要包括哪些技术知识点呢?
- 是关于 AOP 切面拦截的使用,这是因为需要给使用数据库路由的方法做上标记,便于处理分库分表逻辑。
- 数据源的切换操作,既然有分库那么就会涉及在多个数据源间进行链接切换,以便把数据分配给不同的数据库。
- 数据库表寻址操作,一条数据分配到哪个数据库,哪张表,都需要进行索引计算。在方法调用的过程中最终通过 ThreadLocal 记录。
- 为了能让数据均匀的分配到不同的库表中去,还需要考虑如何进行数据散列的操作,不能分库分表后,让数据都集中在某个库的某个表,这样就失去了分库分表的意义。
综上,可以看到在数据库和表的数据结构下完成数据存放,我需要用到的技术包括:AOP、数据源切换、散列算法、哈希寻址、ThreadLocal以及SpringBoot的Starter开发方式等技术。而像哈希散列、寻址、数据存放,其实这样的技术与 HashMap 有太多相似之处,那么学完源码造火箭的机会来了 如果你有过深入分析和学习过 HashMap 源码、Spring 源码、中间件开发,那么在设计这样的数据库路由组件时一定会有很多思路的出来。接下来我们一起尝试下从源码学习到造火箭!
三、技术调研
在 JDK 源码中,包含的数据结构设计有:数组、链表、队列、栈、红黑树,具体的实现有 ArrayList、LinkedList、Queue、Stack,而这些在数据存放都是顺序存储,并没有用到哈希索引的方式进行处理。而 HashMap、ThreadLocal,两个功能则用了哈希索引、散列算法以及在数据膨胀时候的拉链寻址和开放寻址,所以我们要分析和借鉴的也会集中在这两个功能上。
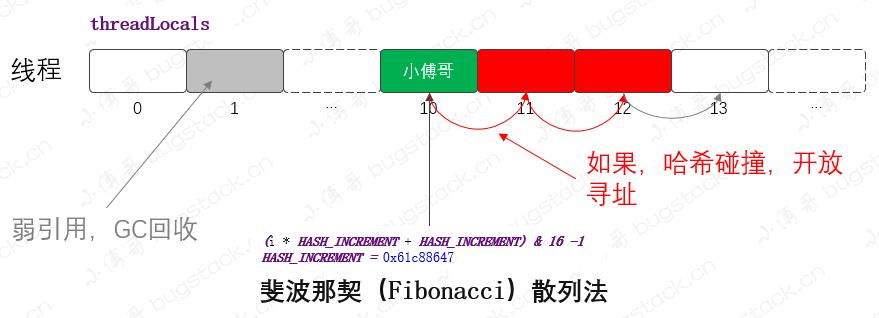
1. ThreadLocal
@Test
public void test_idx() {
int hashCode = 0;
for (int i = 0; i < 16; i++) {
hashCode = i * 0x61c88647 + 0x61c88647;
int idx = hashCode & 15;
System.out.println("斐波那契散列:" + idx + " 普通散列:" + (String.valueOf(i).hashCode() & 15));
}
}
斐波那契散列:7 普通散列:0
斐波那契散列:14 普通散列:1
斐波那契散列:5 普通散列:2
斐波那契散列:12 普通散列:3
斐波那契散列:3 普通散列:4
斐波那契散列:10 普通散列:5
斐波那契散列:1 普通散列:6
斐波那契散列:8 普通散列:7
斐波那契散列:15 普通散列:8
斐波那契散列:6 普通散列:9
斐波那契散列:13 普通散列:15
斐波那契散列:4 普通散列:0
斐波那契散列:11 普通散列:1
斐波那契散列:2 普通散列:2
斐波那契散列:9 普通散列:3
斐波那契散列:0 普通散列:4
- 数据结构:散列表的数组结构
- 散列算法:斐波那契(Fibonacci)散列法
- 寻址方式:Fibonacci 散列法可以让数据更加分散,在发生数据碰撞时进行开放寻址,从碰撞节点向后寻找位置进行存放元素。公式:
f(k) = ((k * 2654435769) >> X) << Y对于常见的32位整数而言,也就是 f(k) = (k * 2654435769) >> 28,黄金分割点:(√5 - 1) / 2 = 0.61803398871.618:1 == 1:0.618 - 学到什么:可以参考寻址方式和散列算法,但这种数据结构与要设计实现作用到数据库上的结构相差较大,不过 ThreadLocal 可以用于存放和传递数据索引信息。
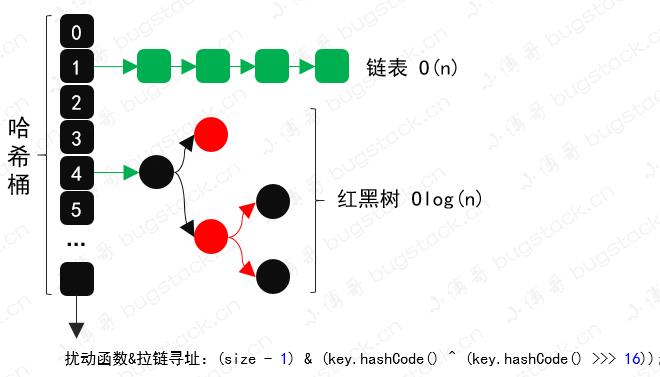
2. HashMap
public static int disturbHashIdx(String key, int size) {
return (size - 1) & (key.hashCode() ^ (key.hashCode() >>> 16));
}
- 数据结构:哈希桶数组 + 链表 + 红黑树
- 散列算法:扰动函数、哈希索引,可以让数据更加散列的分布
- 寻址方式:通过拉链寻址的方式解决数据碰撞,数据存放时会进行索引地址,遇到碰撞产生数据链表,在一定容量超过8个元素进行扩容或者树化。
- 学到什么:可以把散列算法、寻址方式都运用到数据库路由的设计实现中,还有整个数组+链表的方式其实库+表的方式也有类似之处。
四、设计实现
1. 定义路由注解
定义
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE, ElementType.METHOD})
public @interface DBRouter {
String key() default "";
}
使用
@Mapper
public interface IUserDao {
@DBRouter(key = "userId")
User queryUserInfoByUserId(User req);
@DBRouter(key = "userId")
void insertUser(User req);
}
- 首先我们需要自定义一个注解,用于放置在需要被数据库路由的方法上。
- 它的使用方式是通过方法配置注解,就可以被我们指定的 AOP 切面进行拦截,拦截后进行相应的数据库路由计算和判断,并切换到相应的操作数据源上。
2. 解析路由配置
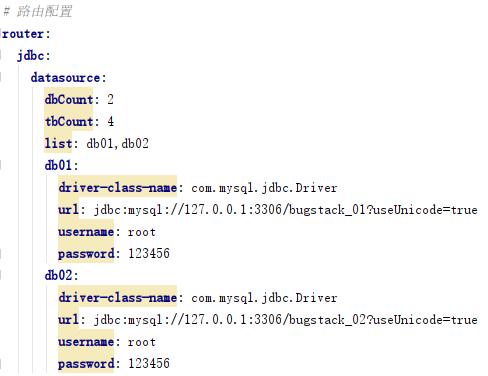
- 以上就是我们实现完数据库路由组件后的一个数据源配置,在分库分表下的数据源使用中,都需要支持多数据源的信息配置,这样才能满足不同需求的扩展。
- 对于这种自定义较大的信息配置,就需要使用到
org.springframework.context.EnvironmentAware接口,来获取配置文件并提取需要的配置信息。
数据源配置提取
@Override
public void setEnvironment(Environment environment) {
String prefix = "router.jdbc.datasource.";
dbCount = Integer.valueOf(environment.getProperty(prefix + "dbCount"));
tbCount = Integer.valueOf(environment.getProperty(prefix + "tbCount"));
String dataSources = environment.getProperty(prefix + "list");
for (String dbInfo : dataSources.split(",")) {
Map<String, Object> dataSourceProps = PropertyUtil.handle(environment, prefix + dbInfo, Map.class);
dataSourceMap.put(dbInfo, dataSourceProps);
}
}
- prefix,是数据源配置的开头信息,你可以自定义需要的开头内容。
- dbCount、tbCount、dataSources、dataSourceProps,都是对配置信息的提取,并存放到 dataSourceMap 中便于后续使用。
3. 数据源切换
在结合 SpringBoot 开发的 Starter 中,需要提供一个 DataSource 的实例化对象,那么这个对象我们就放在 DataSourceAutoConfig 来实现,并且这里提供的数据源是可以动态变换的,也就是支持动态切换数据源。
创建数据源
@Bean
public DataSource dataSource() {
// 创建数据源
Map<Object, Object> targetDataSources = new HashMap<>();
for (String dbInfo : dataSourceMap.keySet()) {
Map<String, Object> objMap = dataSourceMap.get(dbInfo);
targetDataSources.put(dbInfo, new DriverManagerDataSource(objMap.get("url").toString(), objMap.get("username").toString(), objMap.get("password").toString()));
}
// 设置数据源
DynamicDataSource dynamicDataSource = new DynamicDataSource();
dynamicDataSource.setTargetDataSources(targetDataSources);
return dynamicDataSource;
}
- 这里是一个简化的创建案例,把基于从配置信息中读取到的数据源信息,进行实例化创建。
- 数据源创建完成后存放到
DynamicDataSource中,它是一个继承了 AbstractRoutingDataSource 的实现类,这个类里可以存放和读取相应的具体调用的数据源信息。
4. 切面拦截
在 AOP 的切面拦截中需要完成;数据库路由计算、扰动函数加强散列、计算库表索引、设置到 ThreadLocal 传递数据源,整体案例代码如下:
@Around("aopPoint() && @annotation(dbRouter)")
public Object doRouter(ProceedingJoinPoint jp, DBRouter dbRouter) throws Throwable {
String dbKey = dbRouter.key();
if (StringUtils.isBlank(dbKey)) throw new RuntimeException("annotation DBRouter key is null!");
// 计算路由
String dbKeyAttr = getAttrValue(dbKey, jp.getArgs());
int size = dbRouterConfig.getDbCount() * dbRouterConfig.getTbCount();
// 扰动函数
int idx = (size - 1) & (dbKeyAttr.hashCode() ^ (dbKeyAttr.hashCode() >>> 16));
// 库表索引
int dbIdx = idx / dbRouterConfig.getTbCount() + 1;
int tbIdx = idx - dbRouterConfig.getTbCount() * (dbIdx - 1);
// 设置到 ThreadLocal
DBContextHolder.setDBKey(String.format("%02d", dbIdx));
DBContextHolder.setTBKey(String.format("%02d", tbIdx));
logger.info("数据库路由 method:{} dbIdx:{} tbIdx:{}", getMethod(jp).getName(), dbIdx, tbIdx);
// 返回结果
try {
return jp.proceed();
} finally {
DBContextHolder.clearDBKey();
DBContextHolder.clearTBKey();
}
}
- 简化的核心逻辑实现代码如上,首先我们提取了库表乘积的数量,把它当成 HashMap 一样的长度进行使用。
- 接下来使用和 HashMap 一样的扰动函数逻辑,让数据分散的更加散列。
- 当计算完总长度上的一个索引位置后,还需要把这个位置折算到库表中,看看总体长度的索引因为落到哪个库哪个表。
- 最后是把这个计算的索引信息存放到 ThreadLocal 中,用于传递在方法调用过程中可以提取到索引信息。
5. 测试验证
5.1 库表创建
create database `bugstack_01`;
DROP TABLE user_01;
CREATE TABLE user_01 ( id bigint NOT NULL AUTO_INCREMENT COMMENT '自增ID', userId varchar(9) COMMENT '用户ID', userNickName varchar(32) COMMENT '用户昵称', userHead varchar(16) COMMENT '用户头像', userPassword varchar(64) COMMENT '用户密码', createTime datetime COMMENT '创建时间', updateTime datetime COMMENT '更新时间', PRIMARY KEY (id) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
DROP TABLE user_02;
CREATE TABLE user_02 ( id bigint NOT NULL AUTO_INCREMENT COMMENT '自增ID', userId varchar(9) COMMENT '用户ID', userNickName varchar(32) COMMENT '用户昵称', userHead varchar(16) COMMENT '用户头像', userPassword varchar(64) COMMENT '用户密码', createTime datetime COMMENT '创建时间', updateTime datetime COMMENT '更新时间', PRIMARY KEY (id) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
DROP TABLE user_03;
CREATE TABLE user_03 ( id bigint NOT NULL AUTO_INCREMENT COMMENT '自增ID', userId varchar(9) COMMENT '用户ID', userNickName varchar(32) COMMENT '用户昵称', userHead varchar(16) COMMENT '用户头像', userPassword varchar(64) COMMENT '用户密码', createTime datetime COMMENT '创建时间', updateTime datetime COMMENT '更新时间', PRIMARY KEY (id) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
DROP TABLE user_04;
CREATE TABLE user_04 ( id bigint NOT NULL AUTO_INCREMENT COMMENT '自增ID', userId varchar(9) COMMENT '用户ID', userNickName varchar(32) COMMENT '用户昵称', userHead varchar(16) COMMENT '用户头像', userPassword varchar(64) COMMENT '用户密码', createTime datetime COMMENT '创建时间', updateTime datetime COMMENT '更新时间', PRIMARY KEY (id) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
- 创建相同表结构的多个库存信息,bugstack_01、bugstack_02
5.2 语句配置
<select id="queryUserInfoByUserId" parameterType="cn.bugstack.middleware.test.infrastructure.po.User"
resultType="cn.bugstack.middleware.test.infrastructure.po.User">
SELECT id, userId, userNickName, userHead, userPassword, createTime
FROM user_${tbIdx}
where userId = #{userId}
</select>
<insert id="insertUser" parameterType="cn.bugstack.middleware.test.infrastructure.po.User">
insert into user_${tbIdx} (id, userId, userNickName, userHead, userPassword,createTime, updateTime)
values (#{id},#{userId},#{userNickName},#{userHead},#{userPassword},now(),now())
</insert>
- 在 MyBatis 的语句使用上,唯一变化的需要在表名后面添加一个占位符,
${tbIdx}用于写入当前的表ID。
5.3 注解配置
@DBRouter(key = "userId")
User queryUserInfoByUserId(User req);
@DBRouter(key = "userId")
void insertUser(User req);
- 在需要使用分库分表的方法上添加注解,添加注解后这个方法就会被 AOP 切面管理。
5.4 单元测试
22:38:20.067 INFO 19900 --- [ main] c.b.m.db.router.DBRouterJoinPoint : 数据库路由 method:queryUserInfoByUserId dbIdx:2 tbIdx:3
22:38:20.594 INFO 19900 --- [ main] cn.bugstack.middleware.test.ApiTest : 测试结果:{"createTime":1615908803000,"id":2,"userHead":"01_50","userId":"980765512","userNickName":"小傅哥","userPassword":"123456"}
22:38:20.620 INFO 19900 --- [extShutdownHook] o.s.s.concurrent.ThreadPoolTaskExecutor : Shutting down ExecutorService 'applicationTaskExecutor'1
- 以上就是我们使用自己的数据库路由组件执行时的一个日志信息,可以看到这里包含了路由操作,在2库3表:
数据库路由 method:queryUserInfoByUserId dbIdx:2 tbIdx:3
五、总结
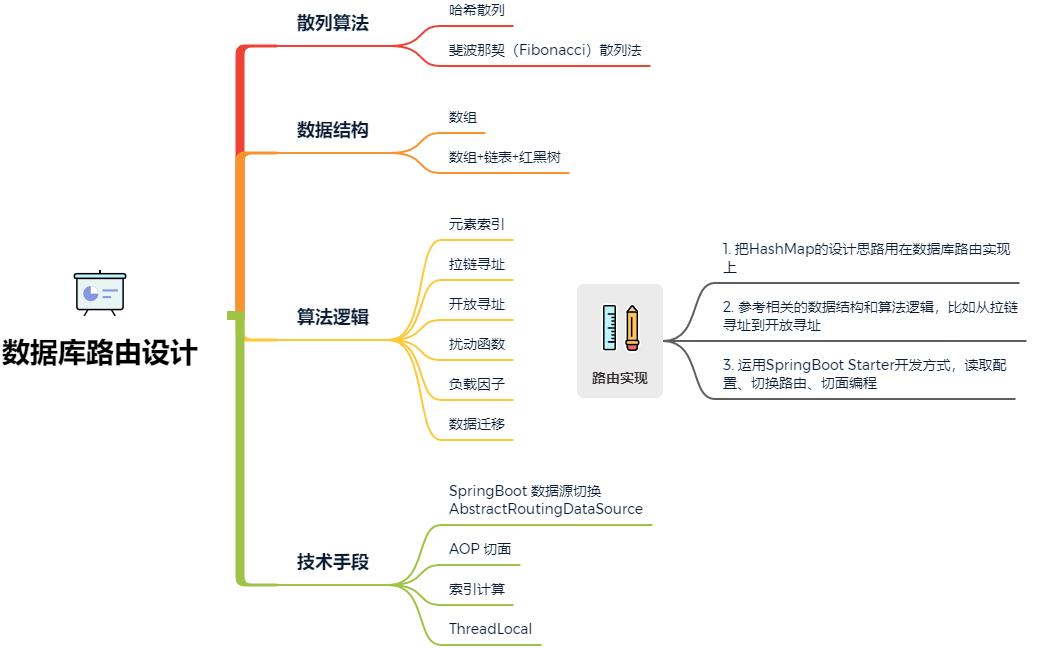
综上 就是我们从 HashMap、ThreadLocal、Spring等源码学习中了解到技术内在原理,并把这样的技术用在一个数据库路由设计上。如果没有经历过这些总被说成造火箭的技术沉淀,那么几乎也不太可能顺利开发出一个这样一个中间件,所有很多时候根本不是技术没用,而是自己没用上没机会用而已。不要总惦记那一片片重复的 CRUD,看看还有哪些知识是真的可以提升个人能力的!参考资料:https://codechina.csdn.net/MiddlewareDesign
六、系列推荐
以上是关于基于AOP和HashMap原理学习,开发Mysql分库分表路由组件!的主要内容,如果未能解决你的问题,请参考以下文章