容器HashMap原理(学习)
Posted 牛哥来coding
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了容器HashMap原理(学习)相关的知识,希望对你有一定的参考价值。
一、概述
基于哈希表的 Map 接口的非同步实现,允许使用 null 值和 null 键,不保证映射的顺序
二、数据结构
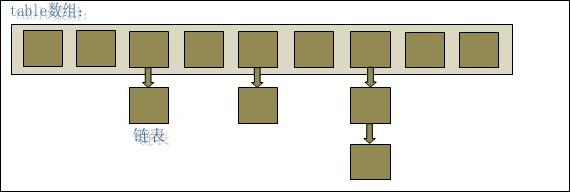
HashMap实际上是一个“链表散列”的数据结构,即数组和链表的结合体;HashMap 底层就是一个数组结构,数组中的每一项又是一个链表。当新建一个 HashMap 的时候,就会初始化一个数组。
三、源码解读
put =>
当我们往 HashMap 中 put 元素的时候,先根据 key 的 hashCode 重新计算 hash 值,根据 hash 值得到这个元素在数组中的位置(即下标),如果数组该位置上已经存放有其他元素了,那么在这个位置上的元素将以链表的形式存放,新加入的放在链头,最先加入的放在链尾。如果数组该位置上没有元素,就直接将该元素放到此数组中的该位置上。
get=>
在 HashMap 中要找到某个元素,需要根据 key 的 hash 值来求得对应数组中的位置。
对于任意给定的对象,只要它的 hashCode() 返回值相同,那么程序调用 hash(int h) 方法所计算得到的 hash 码值总是相同的。我们首先想到的就是把 hash 值对数组长度取模运算,这样一来,元素的分布相对来说是比较均匀的。
而 HashMap 底层数组的长度总是 2 的 n 次方,这是 HashMap 在速度上的优化;
归纳:
HashMap 在底层将 key-value 当成一个整体进行处理,这个整体就是一个 Entry 对象。HashMap 底层采用一个 Entry[] 数组来保存所有的 key-value 对,当需要存储一个 Entry 对象时,会根据 hash 算法来决定其在数组中的存储位置,在根据 equals 方法决定其在该数组位置上的链表中的存储位置;当需要取出一个Entry 时,也会根据 hash 算法找到其在数组中的存储位置,再根据 equals 方法从该位置上的链表中取出该Entry。
四、HashMap 什么时候进行扩容呢(resize)
当 HashMap 中的元素个数超过数组大小 *loadFactor时,就会进行数组扩容,loadFactor的默认值为 0.75,默认情况下,数组大小为 16,那么当 HashMap 中元素个数超过 16*0.75=12 的时候,就把数组的大小扩展为 2*16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常消耗性能的操作,所以如果我们已经预知 HashMap 中元素的个数,那么预设元素的个数能够有效的提高 HashMap 的性能。
五、Fail-Fast 机制
java.util.HashMap 不是线程安全的,因此如果在使用迭代器的过程中有其他线程修改了 map,那么将抛出 ConcurrentModificationException,这就是所谓 fail-fast 策略,迭代器的快速失败行为应该仅用于检测程序错误
六、遍历方式
效率较高的:
Map map = new HashMap(); Iterator iter = map.entrySet().iterator(); while (iter.hasNext()) { Map.Entry entry = (Map.Entry) iter.next(); Object key = entry.getKey(); Object val = entry.getValue(); }
效率较低的:
Map map = new HashMap();
Iterator iter = map.keySet().iterator();
while (iter.hasNext()) {
Object key = iter.next();
Object val = map.get(key);
}foreach方式:
for(Entry<String, String> entry:hashmap.entrySet()){
System.out.println(entry.getKey()+"-->"+entry.getValue());
}
以上是关于容器HashMap原理(学习)的主要内容,如果未能解决你的问题,请参考以下文章