基于关系型代数的 SQL 等价改写
Posted dbLenis
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于关系型代数的 SQL 等价改写相关的知识,希望对你有一定的参考价值。
点击蓝色“有关SQL”关注我哟
加个“星标”,天天与10000人一起快乐成长

看过我那篇《SQL 数据库小白,从入门到精通》的朋友,一定不会陌生,SQL 的数学原理,就是集合运算。
集合运算, 排名第一的交换律,是这样的:
交换律(Commutative Laws):
A ∪ B = B∪A,
A ∩ B = B ∩ A
数学就这么妙!她把复杂的逻辑,抽象成简单的符号,收敛住精美。
当然,用纯数学理论来解释SQL,我想我会被骂成狗头。我的目的,是还原精简的符号,用实例来演绎背后的逻辑。
这里的A,B,是集合表达式。可以看成 SQL 的 where 驱动出的数据集。
比如有同学表如下:
CREATE TABLE dbo.STUDENTS(
STUDENT_ID INT
, STUDENT_NAME NVARCHAR(256)
, STUDENT_GENDER NVARCHAR(6)
)
字段分别代表:
STUDENT_ID: 学号
STUDENT_NAME:姓名
STUDENT_GENDER:性别
假使 A 逻辑是 :
SELECT *
FROM dbo.STUDENTS
WHERE STUDENT_GENDER = N'男'
B 逻辑是:
SELECT *
FROM dbo.STUDENTS
WHERE STUDENT_GENDER = N'女'
那么
A ∪ B = B∪A,
则可以表达为 :
--A ∪ B
SELECT *
FROM dbo.STUDENTS
WHERE STUDENT_GENDER = N'男' OR STUDENT_GENDER=N'女'
--B∪A
SELECT *
FROM dbo.STUDENTS
WHERE STUDENT_GENDER=N'女' OR STUDENT_GENDER = N'男'
或者表达为:
--A ∪ B
SELECT *
FROM dbo.STUDENTS
WHERE STUDENT_GENDER = N'男'
UNION
SELECT *
FROM dbo.STUDENTS
WHERE STUDENT_GENDER=N'女'
--B∪A
SELECT *
FROM dbo.STUDENTS
WHERE STUDENT_GENDER=N'女'
UNION
SELECT *
FROM dbo.STUDENTS
WHERE STUDENT_GENDER = N'男'
再或者:
--A ∪ B
SELECT *
FROM dbo.STUDENTS
WHERE STUDENT_GENDER = N'男'
UNION ALL
SELECT *
FROM dbo.STUDENTS
WHERE STUDENT_GENDER=N'女'
--B∪A
SELECT *
FROM dbo.STUDENTS
WHERE STUDENT_GENDER=N'女'
UNION ALL
SELECT *
FROM dbo.STUDENTS
WHERE STUDENT_GENDER = N'男'
这 3 对(Or,Union, All Union ) 2 组,都是用来抓取全部的同学,那么有什么不一样吗?为什么可以有六种写法

聪明如你一定能想到,其实我这么写出来,肯定是有不一样的地方。
本质上,这 6 条语句,完成同一件事,但写法的复杂度,肉眼可见的递增。性能,也是逐个渐好。这一点,与大多数初学者的直觉相反。
没错,这才是本文要讲的重点,基于关系型代数的SQL等价改写
我记得,有一次做报表,肯兹肯兹写了一下午的 SQL ,死抠了各种业务细节,精简了各类逻辑表达,自认为方方面面都考虑周全,无可挑剔。
虽然用了二十多个 UNION ALL, 代码长达 800 多行,但整体代码排版合理,逻辑清晰可见,一是一,二是二,阅读体验特别棒。这么完美的一个报表 SQL,自己看着都要给自己磕头。
但,就怕人比人!直到我看到另一个同事写的SQL,区区2,30行,结果居然一样的。便羞耻得惊掉下巴。怎么会这样?!

我忍不住从 Code Repo 里面 Clone 下来,仔细把玩,哦不,品读。
细看,这段SQL,版面清洁光滑,短小耐看,逻辑还不失完整。我不由得连连佩服,这样清秀的代码,简直把我摁在地上,摩擦了几条街。
从此,我便开始注意代码的凝练,就像写作般克制。于是就有了那篇《如何写好 5000 行的 SQL 代码》。
总体来说,写 SQL 或者其他代码,反复修改或重构,是提升自己的不二之法。
自那以后,我放弃了一遍就写好代码的妄想,刻意在每次写完之后,都反复修改 2-3 遍,直到自己心里说“ 对了,就是这样!”,才敢签入代码库。
就像现在我写文一样,越是害怕,越是难以下笔。唯有鼓足勇气,多读,多修改,内心的纠结与痛苦,才得以缓解。
你猜对了,我为最近的难产,找到一个好借口!
如此小心翼翼,却始终也还担心,再次遇到这位朋友,恐怕他的造诣又上升了几个段位。
有时,真被自己见贤思齐的心态,折腾得够呛。梦回午夜,经常感叹,自己的智商,技艺如此之低,竞争力何在啊。

扯远了,拉回到那 3对2组的 SQL 上来!
组之间,完成的是 A ∪ B 与 B∪A的 转换。所以他们之间并没有不同。但“对之间”,差异就很大。
这就是 SQL 等价改写的魅力所在!
运行第一对,看其执行计划:
SELECT *
FROM dbo.STUDENTS
WHERE STUDENT_GENDER = N'男' OR STUDENT_GENDER=N'女'

Table Scan 这个物理操作,代表的是访问表的方式。在这里,Table Scan 执行了全表扫描的操作。
Table Scan 这是一个非常危险的操作,需要优化
运行第二对,它的执行计划是这样:
SELECT *
FROM dbo.STUDENTS
WHERE STUDENT_GENDER = N'男'
UNION
SELECT *
FROM dbo.STUDENTS
WHERE STUDENT_GENDER=N'女'
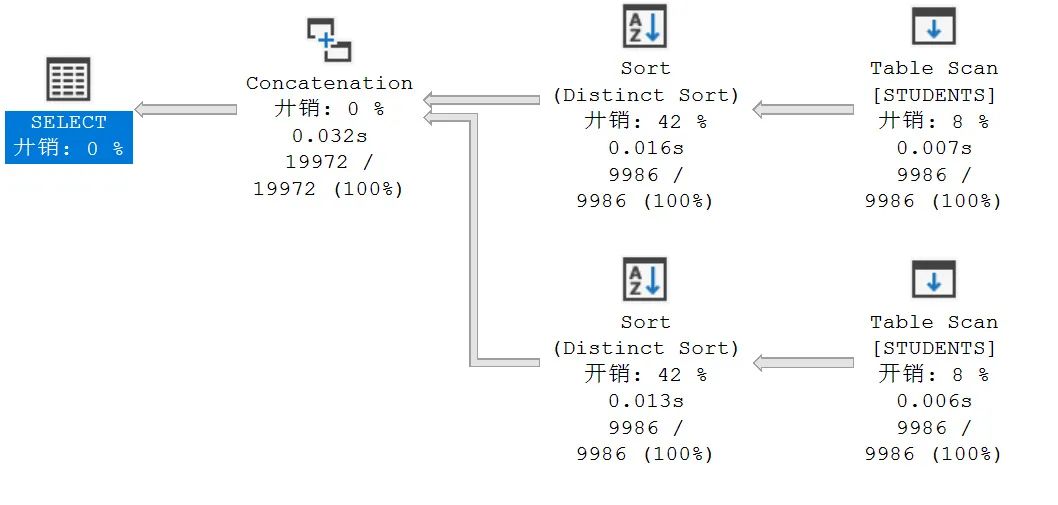
除了第一对里出现的 Table Scan, 这里还出现了 Sort(Distinct Sort) 和 Concatenation 操作符。
这两个操作符,是拜 UNION 所赐,UNION 有一层去重的功能。所以,它的这个功能在本次查询中,是多余的,可去除。
第三对:
SELECT *
FROM dbo.STUDENTS
WHERE STUDENT_GENDER = N'男'
UNION ALL
SELECT *
FROM dbo.STUDENTS
WHERE STUDENT_GENDER=N'女'
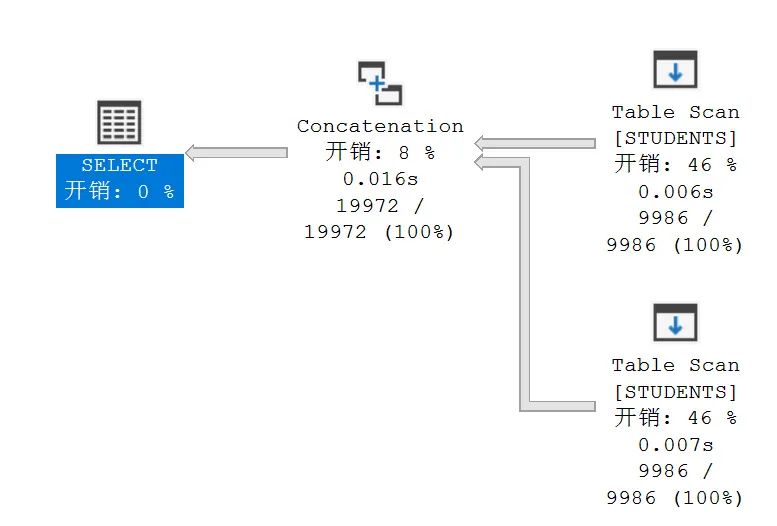
比起第二对,UNION ALL 去掉了去重的功能,即上下两个结果集,如果有同样的一条记录,会在最终的结果集保留下来
虽然,UNION ALL 会在性能上,优于 OR, 需要小心的是,在这里 A 与B 的限制条件互斥,才能改写,一旦两者有重合,则会出现重复记录,这就与实际需求不符了。
比如,往 STUDENTS 表里新建一条未知性别的同学:
INSERT INTO dbo.STUDENTS(STUDENT_NAME,STUDENT_GENDER)
SELECT 'Test Case' , 'UNKWN' AS STUDENT_GENDER
再执行
SELECT *
FROM dbo.STUDENTS
WHERE STUDENT_GENDER = N'男' OR STUDENT_GENDER = N'UNKWN'
UNION ALL
SELECT *
FROM dbo.STUDENTS
WHERE STUDENT_GENDER = N'女' OR STUDENT_GENDER = N'UNKWN'
ORDER BY STUDENT_GENDER
就能看到有两条 UNKWN 性别的记录;
STUDENT_ID STUDENT_NAME STUDENT_GENDER
33815 Test Case UNKWN
33815 Test Case UNKWN
所以,SQL 转换前提,一定是等价.
上面的例子,是日常开发或面试常见操作。底下这例,便是体现优化功底的骚操作,不曾用过,就真不知道还能这么干。
SELECT *
FROM (
SELECT A.*
, B.*
, C.*
, D.*
, E.*
, F.*
FROM A
INNER JOIN B ON B.XXX = A.XXX
INNER JOIN C ON C.ZZZ = B.ZZZ
INNER JOIN D ON D.YYY = C.YYY
INNER JOIN E ON E.III = E.III
INNER JOIN F ON F.PPP = E.PPP
) TMP
LEFT JOIN G ON G.WWW = TMP.WWW
WHERE TMP.FLD1 = 'SAMSUNG'
AND TMP.FLD2 = 'KOREA'
AND TMP.FLDX ='XXXX'
这种多表连接的 SQL,司空见惯。恐怕连接的表,只有更多。
初学者,往往能将逻辑理清楚,就已经非常吃力了。就像我之前的例子,哗哗哗,一通写下来,把数据找正确,就满足了。
但,假如 FLD1, FLD2, FLDX,隶属于 A,B,C,D,E,F,你是否能看出点什么来?
没错, A ∩ B = B ∩ A 交集等价转换:
SELECT *
FROM (
SELECT A.*
, B.*
, C.*
, D.*
, E.*
, F.*
FROM A
INNER JOIN B ON B.XXX = A.XXX
WHERE A.FLD1 = 'SAMSUNG'
AND A.FLD2 = 'KOREA'
AND B.FLDX ='XXXX'
) TMP
INNER JOIN C ON C.ZZZ = B.ZZZ
INNER JOIN D ON D.YYY = C.YYY
INNER JOIN E ON E.III = E.III
INNER JOIN F ON F.PPP = E.PPP
LEFT JOIN G ON G.WWW = TMP.WWW
前提:FLD1, FLD2, FLDX 隶属于 A,B 两表,且不是计算字段
原先的内连接,会抛出一个巨大的矩阵:
SELECT A.*
, B.*
, C.*
, D.*
, E.*
, F.*
FROM A
INNER JOIN B ON B.XXX = A.XXX
INNER JOIN C ON C.ZZZ = B.ZZZ
INNER JOIN D ON D.YYY = C.YYY
INNER JOIN E ON E.III = E.III
INNER JOIN F ON F.PPP = E.PPP
而事实上,基于
WHERE A.FLD1 = 'SAMSUNG'
AND A.FLD2 = 'KOREA'
AND B.FLDX ='XXXX'
这样的条件,只能选出一条或者少量数据。那前期做了很多 Join 操作,就变成了无用功,浪费了计算资源。
驱动表最小化,这是优化的一条方法。如果优化器,做不到谓词推进,那只能人工帮他做选择。
什么是“谓词推进”?
当在 STUDENTS 表上加索引后,
CREATE INDEX IDX_STU_GENDER ON dbo.STUDENTS(STUDENT_GENDER)
执行查询:
SELECT STUDENT_GENDER FROM dbo.STUDENTS
WHERE STUDENT_GENDER = N'UNKWN'

标记为红框的部分,就是谓词表达式。只有谓词靠近原表,才能发挥减少数据访问量的作用。
--完--
往期精彩:

以上是关于基于关系型代数的 SQL 等价改写的主要内容,如果未能解决你的问题,请参考以下文章
SQL优化案例之where exists(col1=xxx or col2=xxx)等价改写