深度学习Attention的原理分类及实现
Posted Better Bench
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习Attention的原理分类及实现相关的知识,希望对你有一定的参考价值。
1 原理
1.1 简介
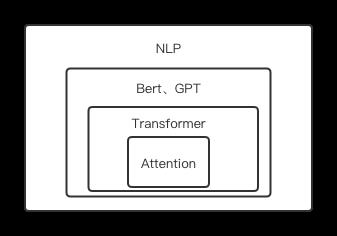
Attention是注意力机制,本质上对关注的多个对象有个不同的权重,从而关注重点不同。Attention是Transformer、Bert、GPT的基础。
引入Attention机制的原因
- 参数少:相对于RNN、CNN复杂度小,参数小
- 速度快:解决了RNN不能并行计算的问题
- 效果好:解决了长距离的信息会被弱化问题,Attention 是挑重点,就算文本比较长,也能从中间抓住重点,不丢失重要的信息。
1.2 原理
(1)术语介绍
在NLP中,有三个关键术语,
- Query:问句,简称Q,如“小明喜欢什么颜色的衣服?”
- Key:问句的关键词,简称K,类似搜索引擎的关键字,用于检索,如“小明 喜欢 颜色 衣服”
- Value:问题对应的答案,简称V,如“小明喜欢红色衣服”
训练神经网络的训练集就由Q、K、V组成
(2)Attention原理解析
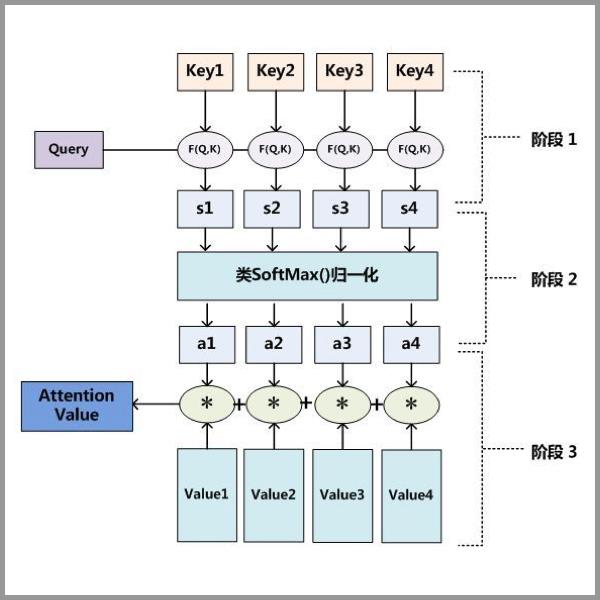
第一步: query 和 key 进行相似度计算,得到权值
第二步:将权值通过softmax进行归一化,得到直接可用的权重
第三步:将权重和 value 进行加权求和
2 分类
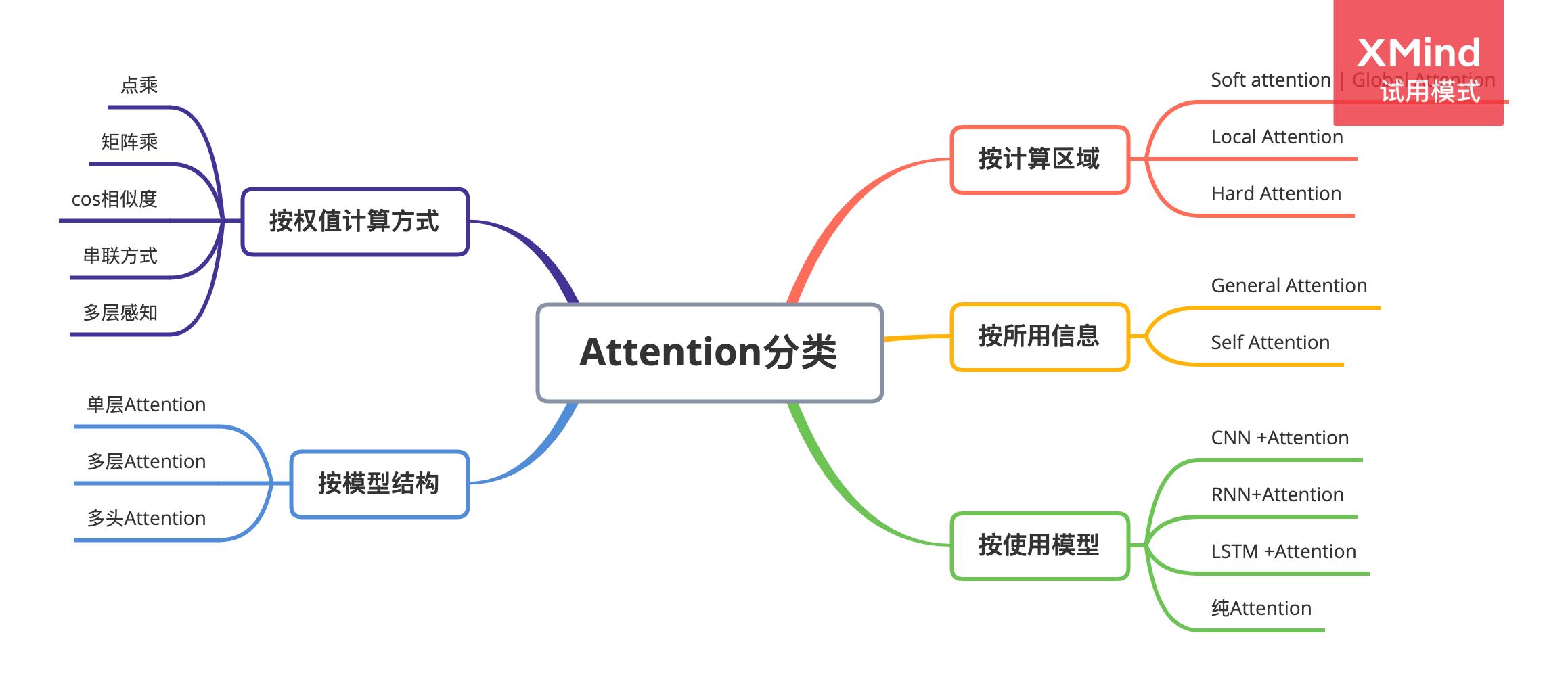
2.1 计算区域
根据Attention的计算区域,可以分成以下几种:
(1)Soft Attention,这是比较常见的Attention方式,对所有key求权重概率,每个key都有一个对应的权重,是一种全局的计算方式(也可以叫Global Attention)。这种方式比较理性,参考了所有key的内容,再进行加权。但是计算量可能会比较大一些。
(2)Hard Attention,这种方式是直接精准定位到某个key,其余key就都不管了,相当于这个key的概率是1,其余key的概率全部是0。因此这种对齐方式要求很高,要求一步到位,如果没有正确对齐,会带来很大的影响。另一方面,因为不可导,一般需要用强化学习的方法进行训练。(或者使用gumbel softmax之类的)
(3)Local Attention,这种方式其实是以上两种方式的一个折中,对一个窗口区域进行计算。先用Hard方式定位到某个地方,以这个点为中心可以得到一个窗口区域,在这个小区域内用Soft方式来算Attention。
2.2 所用信息
假设我们要对一段原文计算Attention,这里原文指的是我们要做attention的文本,那么所用信息包括内部信息和外部信息,内部信息指的是原文本身的信息,而外部信息指的是除原文以外的额外信息。
(1)General Attention,这种方式利用到了外部信息,常用于需要构建两段文本关系的任务,query一般包含了额外信息,根据外部query对原文进行对齐。
比如在阅读理解任务中,需要构建问题和文章的关联,假设现在baseline是,对问题计算出一个问题向量q,把这个q和所有的文章词向量拼接起来,输入到LSTM中进行建模。那么在这个模型中,文章所有词向量共享同一个问题向量,现在我们想让文章每一步的词向量都有一个不同的问题向量,也就是,在每一步使用文章在该步下的词向量对问题来算attention,这里问题属于原文,文章词向量就属于外部信息。
(2)Local Attention,这种方式只使用内部信息,key和value以及query只和输入原文有关,在self attention中,key=value=query。既然没有外部信息,那么在原文中的每个词可以跟该句子中的所有词进行Attention计算,相当于寻找原文内部的关系。
还是举阅读理解任务的例子,上面的baseline中提到,对问题计算出一个向量q,那么这里也可以用上attention,只用问题自身的信息去做attention,而不引入文章信息。
2.3 结构层次
结构方面根据是否划分层次关系,分为单层attention,多层attention和多头attention:
(1)单层Attention,这是比较普遍的做法,用一个query对一段原文进行一次attention。
(2)多层Attention,一般用于文本具有层次关系的模型,假设我们把一个document划分成多个句子,在第一层,我们分别对每个句子使用attention计算出一个句向量(也就是单层attention);在第二层,我们对所有句向量再做attention计算出一个文档向量(也是一个单层attention),最后再用这个文档向量去做任务。
(3)多头Attention,这是Attention is All You Need中提到的multi-head attention,用到了多个query对一段原文进行了多次attention,每个query都关注到原文的不同部分,相当于重复做多次单层attention,最后再把这些结果拼接起来。
2.4 模型方面
从模型上看,Attention一般用在CNN和LSTM上,也可以直接进行纯Attention计算。
(1)CNN+Attention
CNN的卷积操作可以提取重要特征,我觉得这也算是Attention的思想,但是CNN的卷积感受视野是局部的,需要通过叠加多层卷积区去扩大视野。另外,Max Pooling直接提取数值最大的特征,也像是hard attention的思想,直接选中某个特征。
CNN上加Attention可以加在这几方面:
- 在卷积操作前做attention,比如Attention-Based BCNN-1,这个任务是文本蕴含任务需要处理两段文本,同时对两段输入的序列向量进行attention,计算出特征向量,再拼接到原始向量中,作为卷积层的输入。
- 在卷积操作后做attention,比如Attention-Based BCNN-2,对两段文本的卷积层的输出做attention,作为pooling层的输入。
- 在pooling层做attention,代替max pooling。比如Attention pooling,首先我们用LSTM学到一个比较好的句向量,作为query,然后用CNN先学习到一个特征矩阵作为key,再用query对key产生权重,进行attention,得到最后的句向量。
(2)LSTM+Attention
LSTM内部有Gate机制,其中input gate选择哪些当前信息进行输入,forget gate选择遗忘哪些过去信息,我觉得这算是一定程度的Attention了,而且号称可以解决长期依赖问题,实际上LSTM需要一步一步去捕捉序列信息,在长文本上的表现是会随着step增加而慢慢衰减,难以保留全部的有用信息。
LSTM通常需要得到一个向量,再去做任务,常用方式有: - 直接使用最后的hidden state(可能会损失一定的前文信息,难以表达全文)
- 对所有step下的hidden state进行等权平均(对所有step一视同仁)。
- Attention机制,对所有step的hidden state进行加权,把注意力集中到整段文本中比较重要的hidden state信息。性能比前面两种要好一点,而方便可视化观察哪些step是重要的,但是要小心过拟合,而且也增加了计算量。
(3)纯Attention
Attention is all you need,没有用到CNN/RNN,乍一听也是一股清流了,但是仔细一看,本质上还是一堆向量去计算attention。
2.5 相似度计算方式
在做attention的时候,我们需要计算query和某个key的分数(相似度),常用方法有:
(1)点乘
s
(
q
,
k
)
=
q
T
k
s(q,k) = q^Tk
s(q,k)=qTk
(2)矩阵乘
s
(
q
,
k
)
=
q
T
k
s(q,k) = q^Tk
s(q,k)=qTk
(3)cos相似度
s
(
q
,
k
)
=
q
T
k
∣
∣
q
∣
∣
.
∣
∣
k
∣
∣
s(q,k) = \\frac{q^Tk}{||q||.||k||}
s(q,k)=∣∣q∣∣.∣∣k∣∣qTk
(4)串联方式,把q和k拼接起来
s
(
q
,
k
)
=
W
[
q
;
k
]
s(q,k) = W[q;k]
s(q,k)=W[q;k]
(5)用多层感知机
s
(
q
,
k
)
=
v
a
T
t
a
n
h
(
W
q
+
U
k
)
s(q,k) = v_a^Ttanh(Wq+Uk)
s(q,k)=vaTtanh(Wq+Uk)
3 Keras实现
https://github.com/philipperemy/keras-attention-mechanism
from tensorflow.keras.layers import Dense, Lambda, Dot, Activation, Concatenate
from tensorflow.keras.layers import Layer
class Attention(Layer):
def __init__(self, units=128, **kwargs):
self.units = units
super().__init__(**kwargs)
def __call__(self, inputs):
"""
Many-to-one attention mechanism for Keras.
@param inputs: 3D tensor with shape (batch_size, time_steps, input_dim).
@return: 2D tensor with shape (batch_size, 128)
@author: felixhao28, philipperemy.
"""
hidden_states = inputs
hidden_size = int(hidden_states.shape[2])
# Inside dense layer
# hidden_states dot W => score_first_part
# (batch_size, time_steps, hidden_size) dot (hidden_size, hidden_size) => (batch_size, time_steps, hidden_size)
# W is the trainable weight matrix of attention Luong's multiplicative style score
score_first_part = Dense(hidden_size, use_bias=False, name='attention_score_vec')(hidden_states)
# score_first_part dot last_hidden_state => attention_weights
# (batch_size, time_steps, hidden_size) dot (batch_size, hidden_size) => (batch_size, time_steps)
h_t = Lambda(lambda x: x[:, -1, :], output_shape=(hidden_size,), name='last_hidden_state')(hidden_states)
score = Dot(axes=[1, 2], name='attention_score')([h_t, score_first_part])
attention_weights = Activation('softmax', name='attention_weight')(score)
# (batch_size, time_steps, hidden_size) dot (batch_size, time_steps) => (batch_size, hidden_size)
context_vector = Dot(axes=[1, 1], name='context_vector')([hidden_states, attention_weights])
pre_activation = Concatenate(name='attention_output')([context_vector, h_t])
attention_vector = Dense(self.units, use_bias=False, activation='tanh', name='attention_vector')(pre_activation)
return attention_vector
def get_config(self):
return {'units': self.units}
@classmethod
def from_config(cls, config):
return cls(**config)
import numpy as np
from tensorflow.keras import Input
from tensorflow.keras.layers import Dense, LSTM
from tensorflow.keras.models import load_model, Model
from attention import Attention
def main():
# Dummy data. There is nothing to learn in this example.
num_samples, time_steps, input_dim, output_dim = 100, 10, 1, 1
data_x = np.random.uniform(size=(num_samples, time_steps, input_dim))
data_y = np.random.uniform(size=(num_samples, output_dim))
# Define/compile the model.
model_input = Input(shape=(time_steps, input_dim))
x = LSTM(64, return_sequences=True)(model_input)
x = Attention(32)(x)
x = Dense(1)(x)
model = Model(model_input, x)
model.compile(loss='mae', optimizer='adam')
print(model.summary())
# train.
model.fit(data_x, data_y, epochs=10)
# test save/reload model.
pred1 = model.predict(data_x)
model.save('test_model.h5')
model_h5 = load_model('test_model.h5')
pred2 = model_h5.predict(data_x)
np.testing.assert_almost_equal(pred1, pred2)
print('Success.')
if __name__ == '__main__':
main()
以上是关于深度学习Attention的原理分类及实现的主要内容,如果未能解决你的问题,请参考以下文章
深度学习笔记:Encoder-Decoder模型和Attention模型