深度学习笔记:Encoder-Decoder模型和Attention模型
Posted multiangle
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习笔记:Encoder-Decoder模型和Attention模型相关的知识,希望对你有一定的参考价值。
深度学习笔记(一):logistic分类
深度学习笔记(二):简单神经网络,后向传播算法及实现
深度学习笔记(三):激活函数和损失函数
深度学习笔记:优化方法总结(BGD,SGD,Momentum,AdaGrad,RMSProp,Adam)
深度学习笔记(四):循环神经网络的概念,结构和代码注释
深度学习笔记(五):LSTM
深度学习笔记(六):Encoder-Decoder模型和Attention模型
这两天在看attention模型,看了下知乎上的几个回答,很多人都推荐了一篇文章Neural Machine Translation by Jointly Learning to Align and Translate 我看了下,感觉非常的不错,里面还大概阐述了encoder-decoder(编码)模型的概念,以及传统的RNN实现。然后还阐述了自己的attention模型。我看了一下,自己做了一些摘录,写在下面
1.Encoder-Decoder模型及RNN的实现
所谓encoder-decoder模型,又叫做编码-解码模型。这是一种应用于seq2seq问题的模型。
那么seq2seq又是什么呢?简单的说,就是根据一个输入序列x,来生成另一个输出序列y。seq2seq有很多的应用,例如翻译,文档摘取,问答系统等等。在翻译中,输入序列是待翻译的文本,输出序列是翻译后的文本;在问答系统中,输入序列是提出的问题,而输出序列是答案。
为了解决seq2seq问题,有人提出了encoder-decoder模型,也就是编码-解码模型。所谓编码,就是将输入序列转化成一个固定长度的向量;解码,就是将之前生成的固定向量再转化成输出序列。
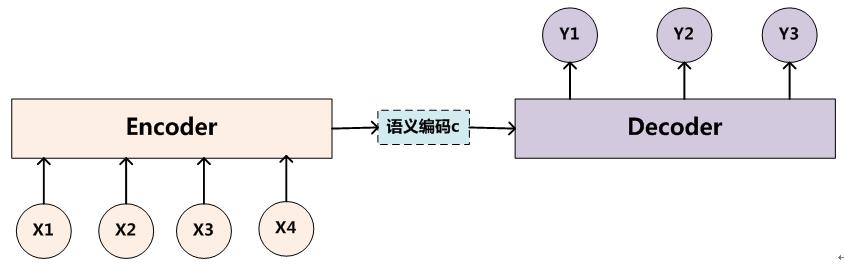
当然了,这个只是大概的思想,具体实现的时候,编码器和解码器都不是固定的,可选的有CNN/RNN/BiRNN/GRU/LSTM等等,你可以自由组合。比如说,你在编码时使用BiRNN,解码时使用RNN,或者在编码时使用RNN,解码时使用LSTM等等。
这边为了方便阐述,选取了编码和解码都是RNN的组合。在RNN中,当前时间的隐藏状态是由上一时间的状态和当前时间输入决定的,也就是
获得了各个时间段的隐藏层以后,再将隐藏层的信息汇总,生成最后的语义向量
一种简单的方法是将最后的隐藏层作为语义向量C,即
解码阶段可以看做编码的逆过程。这个阶段,我们要根据给定的语义向量C和之前已经生成的输出序列
y1,y2,…yt−1
来预测下一个输出的单词
yt
,即
也可以写作
而在RNN中,上式又可以简化成
其中
s
是输出RNN中的隐藏层,C代表之前提过的语义向量,
encoder-decoder模型虽然非常经典,但是局限性也非常大。最大的局限性就在于编码和解码之间的唯一联系就是一个固定长度的语义向量C。也就是说,编码器要将整个序列的信息压缩进一个固定长度的向量中去。但是这样做有两个弊端,一是语义向量无法完全表示整个序列的信息,还有就是先输入的内容携带的信息会被后输入的信息稀释掉,或者说,被覆盖了。输入序列越长,这个现象就越严重。这就使得在解码的时候一开始就没有获得输入序列足够的信息, 那么解码的准确度自然也就要打个折扣了
2.Attention模型
为了解决这个问题,作者提出了Attention模型,或者说注意力模型。简单的说,这种模型在产生输出的时候,还会产生一个“注意力范围”表示接下来输出的时候要重点关注输入序列中的哪些部分,然后根据关注的区域来产生下一个输出,如此往复。模型的大概示意图如下所示
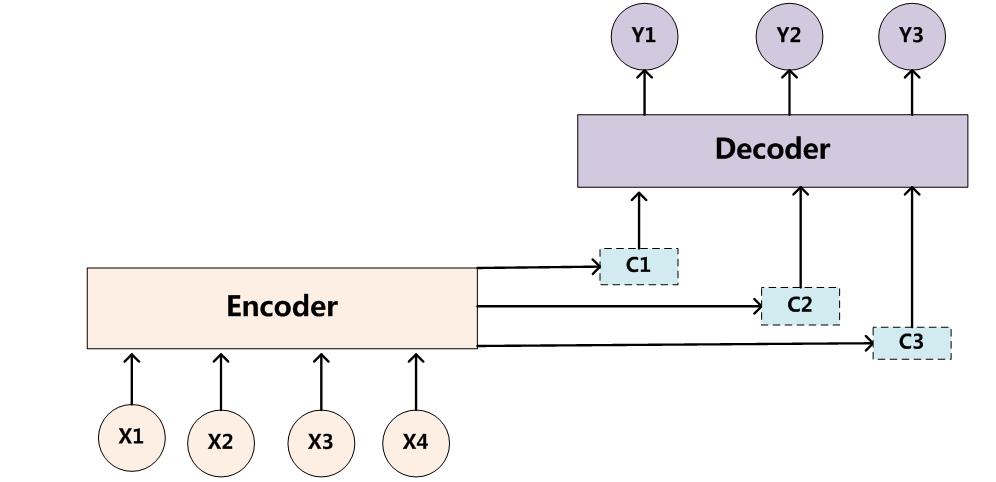
相比于之前的encoder-decoder模型,attention模型最大的区别就在于它不在要求编码器将所有输入信息都编码进一个固定长度的向量之中。相反,此时编码器需要将输入编码成一个向量的序列,而在解码的时候,每一步都会选择性的从向量序列中挑选一个子集进行进一步处理。这样,在产生每一个输出的时候,都能够做到充分利用输入序列携带的信息。而且这种方法在翻译任务中取得了非常不错的成果。
在这篇文章中,作者提出了一个用于翻译任务的结构。解码部分使用了attention模型,而在编码部分,则使用了BiRNN(bidirectional RNN,双向RNN)
2.1 解码
我们先来看看解码。解码部分使用了attention模型。类似的,我们可以将之前定义的条件概率写作
上式
si
表示解码器i时刻的隐藏状态。计算公式是
注意这里的条件概率与每个目标输出 yi