Python深度学习12——Keras实现注意力机制(self-attention)中文的文本情感分类(详细注释)
Posted 阡之尘埃
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python深度学习12——Keras实现注意力机制(self-attention)中文的文本情感分类(详细注释)相关的知识,希望对你有一定的参考价值。
Keras封装性比较高,现在的注意力机制都是用pytorch较为多。但是使用函数API也可以实现,Keras处理文本并且转化为词向量也很方便。
本文使用了一个外卖评价的数据集,标签是0和1,1代表好评,0代表差评。并且构建了12种模型,即 MLP,1DCNN,RNN,GRU,LSTM, CNN+LSTM,TextCNN,BiLSTM, Attention, BiLSTM+Attention,BiGRU+Attention,Attention*3(3个注意力层堆叠)
大家也可以在此基础上参考改进,组合出更好的模型。(需要数据集和停用词可以留言)
本文的注释算是我写博客最详细的一篇了。
中文数据预处理
由于中文不像英文中间有空白可以直接划分词语,需要依靠jieba库切词,然后把没有用的标点符号,或者是“了”,‘的’,‘也’,‘就’,‘很’.....等等没有用的虚词去掉。这就需要一个停用词库,大家可以网上找常用的停用词文本,也可以留言找博主要。我这有一个比较全的停用词,我还有一个简化版的。本次使用的是简化版的停用词。
首先看数据长这样

导入包和数据,读取停用词,用jieba库划分词汇并处理
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.sans-serif'] = ['KaiTi'] #指定默认字体 SimHei黑体
plt.rcParams['axes.unicode_minus'] = False #解决保存图像是负号'
import jieba
stop_list = pd.read_csv("stopwords_简略版.txt",index_col=False,quoting=3,
sep="\\t",names=['stopword'], encoding='utf-8')
#Jieba分词函数
def txt_cut(juzi):
lis=[w for w in jieba.lcut(juzi) if w not in stop_list.values]
return " ".join(lis)
df=pd.read_excel('外卖.xlsx')
data=pd.DataFrame()
data['label']=df['label']
data['cutword']=df['review'].astype('str').apply(txt_cut)
data词汇切割好了,得到如下结果

查看标签y的分布
data['label'].value_counts().plot(kind='bar')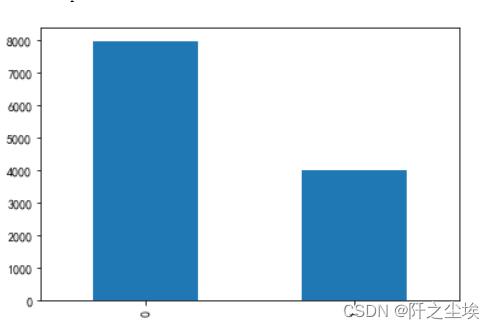
负面评价0有将近8000个,正面评价1有4000个,不平衡,划分训练测试集时要分层抽样。
下面将文本变为数组,利用Keras里面的Tokenizer类实现,首先将词汇都索引化。这里有个参数num_words=6000很重要,意思是选择6000个词汇作为索引字典,也就是这个模型里面最多只有6000个词。
from os import listdir
from keras.preprocessing import sequence
from keras.preprocessing.text import Tokenizer
from tensorflow.keras.utils import to_categorical
from sklearn.model_selection import train_test_split
# 将文件分割成单字, 建立词索引字典
tok = Tokenizer(num_words=6000)
tok.fit_on_texts(data['cutword'].values)
print("样本数 : ", tok.document_count)
print(k: tok.word_index[k] for k in list(tok.word_index)[:10])
由于每个评论的词汇长度不一样,我们训练时需要弄成一样长的张量(多剪少补),需要确定这个词汇最大长度为多少,也就是max_words参数,这个是循环神经网络的时间步的长度,也是注意力机制的维度。如果max_words过小则很多语句的信息损失了,而max_words过大数据矩阵又会过于稀疏,并且计算量过大。我们查看一下X的长度的分布频率:
# 建立训练和测试数据集
X= tok.texts_to_sequences(data['cutword'].values)
#查看x的长度的分布
length=[]
for i in X:
length.append(len(i))
v_c=pd.Series(length).value_counts()
print(v_c[v_c>20]) #频率大于20才展现
v_c[v_c>20].plot(kind='bar',figsize=(12,5))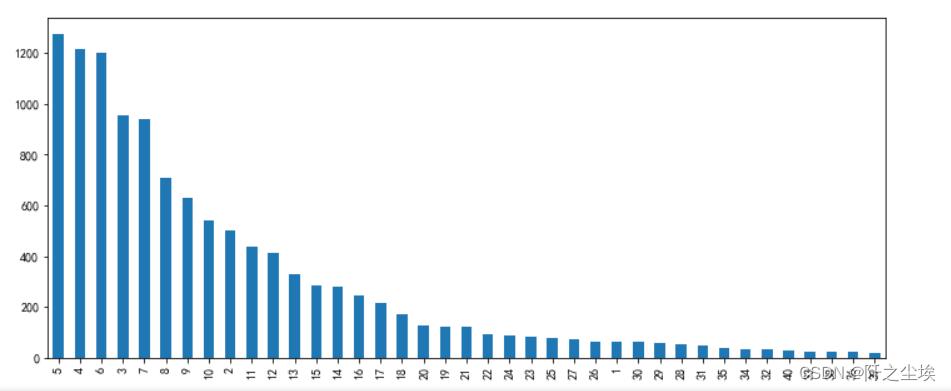 可以看出绝大多数的句子单词长度不超过10....长度为5的评论是最多的,本次选择max_words=20,将句子都裁剪为长为20 的向量。并取出y
可以看出绝大多数的句子单词长度不超过10....长度为5的评论是最多的,本次选择max_words=20,将句子都裁剪为长为20 的向量。并取出y
# 将序列数据填充成相同长度
X= sequence.pad_sequences(X, maxlen=20)
Y=data['label'].values
print("X.shape: ", X.shape)
print("Y.shape: ", Y.shape)
#X=np.array(X)
#Y=np.array(Y)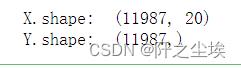
然后划分训练测试集,查看形状:
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, stratify=Y, random_state=0)
X_train.shape,X_test.shape,Y_train.shape, Y_test.shape
将y进行独立热编码,并且保留原始的测试集y_test,方便后面做评价。查看x和y前3个
Y_test_original=Y_test.copy()
Y_train = to_categorical(Y_train)
Y_test = to_categorical(Y_test)
print(X_train[:3])
print(Y_test[:3])
开始构建神经网络
由于Keras里面没有封装好的注意力层,需要我们自己定义一个:
#自定义注意力层
from keras import initializers, constraints,activations,regularizers
from keras import backend as K
from keras.layers import Layer
class Attention(Layer):
#返回值:返回的不是attention权重,而是每个timestep乘以权重后相加得到的向量。
#输入:输入是rnn的timesteps,也是最长输入序列的长度
def __init__(self, step_dim,
W_regularizer=None, b_regularizer=None,
W_constraint=None, b_constraint=None,
bias=True, **kwargs):
self.supports_masking = True
self.init = initializers.get('glorot_uniform')
self.W_regularizer = regularizers.get(W_regularizer)
self.b_regularizer = regularizers.get(b_regularizer)
self.W_constraint = constraints.get(W_constraint)
self.b_constraint = constraints.get(b_constraint)
self.bias = bias
self.step_dim = step_dim
self.features_dim = 0
super(Attention, self).__init__(**kwargs)
def build(self, input_shape):
assert len(input_shape) == 3
self.W = self.add_weight(shape=(input_shape[-1],),initializer=self.init,name='_W'.format(self.name),
regularizer=self.W_regularizer,constraint=self.W_constraint)
self.features_dim = input_shape[-1]
if self.bias:
self.b = self.add_weight(shape=(input_shape[1],),initializer='zero', name='_b'.format(self.name),
regularizer=self.b_regularizer,constraint=self.b_constraint)
else:
self.b = None
self.built = True
def compute_mask(self, input, input_mask=None):
return None ## 后面的层不需要mask了,所以这里可以直接返回none
def call(self, x, mask=None):
features_dim = self.features_dim ## 这里应该是 step_dim是我们指定的参数,它等于input_shape[1],也就是rnn的timesteps
step_dim = self.step_dim
# 输入和参数分别reshape再点乘后,tensor.shape变成了(batch_size*timesteps, 1),之后每个batch要分开进行归一化
# 所以应该有 eij = K.reshape(..., (-1, timesteps))
eij = K.reshape(K.dot(K.reshape(x, (-1, features_dim)),K.reshape(self.W, (features_dim, 1))), (-1, step_dim))
if self.bias:
eij += self.b
eij = K.tanh(eij) #RNN一般默认激活函数为tanh, 对attention来说激活函数差别不大,因为要做softmax
a = K.exp(eij)
if mask is not None: ## 如果前面的层有mask,那么后面这些被mask掉的timestep肯定是不能参与计算输出的,也就是将他们attention权重设为0
a *= K.cast(mask, K.floatx()) ## cast是做类型转换,keras计算时会检查类型,可能是因为用gpu的原因
a /= K.cast(K.sum(a, axis=1, keepdims=True) + K.epsilon(), K.floatx())
a = K.expand_dims(a) # a = K.expand_dims(a, axis=-1) , axis默认为-1, 表示在最后扩充一个维度。比如shape = (3,)变成 (3, 1)
## 此时a.shape = (batch_size, timesteps, 1), x.shape = (batch_size, timesteps, units)
weighted_input = x * a
# weighted_input的shape为 (batch_size, timesteps, units), 每个timestep的输出向量已经乘上了该timestep的权重
# weighted_input在axis=1上取和,返回值的shape为 (batch_size, 1, units)
return K.sum(weighted_input, axis=1)
def compute_output_shape(self, input_shape): ## 返回的结果是c,其shape为 (batch_size, units)
return input_shape[0], self.features_dim别管这个类多复杂.....不用看,后面直接当成函数用就行。
下面导入Keras里面的常用的神经网络层,定义一些参数
from keras.preprocessing import sequence
from keras.models import Sequential,Model
from keras.layers import Dense,Input, Dropout, Embedding, Flatten,MaxPooling1D,Conv1D,SimpleRNN,LSTM,GRU,Multiply
from keras.layers import Bidirectional,Activation,BatchNormalization
from keras.layers.merge import concatenate
seed = 10
np.random.seed(seed) # 指定随机数种子
#单词索引的最大个数6000,单句话最大长度20
top_words=6000
max_words=20
num_labels=2 #2分类下面构建模型函数,这个函数较为复杂,因为是12个模型一起定义的,方便代码的复用。但每个模型对应的那一块都写的很清楚:
def build_model(top_words=top_words,max_words=max_words,num_labels=num_labels,mode='LSTM',hidden_dim=[32]):
if mode=='RNN':
model = Sequential()
model.add(Embedding(top_words, 32, input_length=max_words))
model.add(Dropout(0.25))
model.add(SimpleRNN(32))
model.add(Dropout(0.25))
model.add(Dense(num_labels, activation="softmax"))
elif mode=='MLP':
model = Sequential()
model.add(Embedding(top_words, 32, input_length=max_words))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(256, activation="relu"))
model.add(Dropout(0.25))
model.add(Dense(num_labels, activation="softmax"))
elif mode=='LSTM':
model = Sequential()
model.add(Embedding(top_words, 32, input_length=max_words))
model.add(Dropout(0.25))
model.add(LSTM(32))
model.add(Dropout(0.25))
model.add(Dense(num_labels, activation="softmax"))
elif mode=='GRU':
model = Sequential()
model.add(Embedding(top_words, 32, input_length=max_words))
model.add(Dropout(0.25))
model.add(GRU(32))
model.add(Dropout(0.25))
model.add(Dense(num_labels, activation="softmax"))
elif mode=='CNN': #一维卷积
model = Sequential()
model.add(Embedding(top_words, 32, input_length=max_words))
model.add(Dropout(0.25))
model.add(Conv1D(filters=32, kernel_size=3, padding="same",activation="relu"))
model.add(MaxPooling1D(pool_size=2))
model.add(Flatten())
model.add(Dense(256, activation="relu"))
model.add(Dropout(0.25))
model.add(Dense(num_labels, activation="softmax"))
elif mode=='CNN+LSTM':
model = Sequential()
model.add(Embedding(top_words, 32, input_length=max_words))
model.add(Dropout(0.25))
model.add(Conv1D(filters=32, kernel_size=3, padding="same",activation="relu"))
model.add(MaxPooling1D(pool_size=2))
model.add(LSTM(64))
model.add(Dropout(0.25))
model.add(Dense(num_labels, activation="softmax"))
elif mode=='BiLSTM':
model = Sequential()
model.add(Embedding(top_words, 32, input_length=max_words))
model.add(Bidirectional(LSTM(64)))
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.25))
model.add(Dense(num_labels, activation='softmax'))
#下面的网络采用Funcional API实现
elif mode=='TextCNN':
inputs = Input(name='inputs',shape=[max_words,], dtype='float64')
## 词嵌入使用预训练的词向量
layer = Embedding(top_words, 32, input_length=max_words, trainable=False)(inputs)
## 词窗大小分别为3,4,5
cnn1 = Conv1D(32, 3, padding='same', strides = 1, activation='relu')(layer)
cnn1 = MaxPooling1D(pool_size=2)(cnn1)
cnn2 = Conv1D(32, 4, padding='same', strides = 1, activation='relu')(layer)
cnn2 = MaxPooling1D(pool_size=2)(cnn2)
cnn3 = Conv1D(32, 5, padding='same', strides = 1, activation='relu')(layer)
cnn3 = MaxPooling1D(pool_size=2)(cnn3)
# 合并三个模型的输出向量
cnn = concatenate([cnn1,cnn2,cnn3], axis=-1)
flat = Flatten()(cnn)
drop = Dropout(0.2)(flat)
main_output = Dense(num_labels, activation='softmax')(drop)
model = Model(inputs=inputs, outputs=main_output)
elif mode=='Attention':
inputs = Input(name='inputs',shape=[max_words,], dtype='float64')
layer = Embedding(top_words, 32, input_length=max_words, trainable=False)(inputs)
attention_probs = Dense(32, activation='softmax', name='attention_vec')(layer)
attention_mul = Multiply()([layer, attention_probs])
mlp = Dense(64)(attention_mul) #原始的全连接
fla=Flatten()(mlp)
output = Dense(num_labels, activation='softmax')(fla)
model = Model(inputs=[inputs], outputs=output)
elif mode=='Attention*3':
inputs = Input(name='inputs',shape=[max_words,], dtype='float64')
layer = Embedding(top_words, 32, input_length=max_words, trainable=False)(inputs)
attention_probs = Dense(32, activation='softmax', name='attention_vec')(layer)
attention_mul = Multiply()([layer, attention_probs])
mlp = Dense(32,activation='relu')(attention_mul)
attention_probs = Dense(32, activation='softmax', name='attention_vec1')(mlp)
attention_mul = Multiply()([mlp, attention_probs])
mlp2 = Dense(32,activation='relu')(attention_mul)
attention_probs = Dense(32, activation='softmax', name='attention_vec2')(mlp2)
attention_mul = Multiply()([mlp2, attention_probs])
mlp3 = Dense(32,activation='relu')(attention_mul)
fla=Flatten()(mlp3)
output = Dense(num_labels, activation='softmax')(fla)
model = Model(inputs=[inputs], outputs=output)
elif mode=='BiLSTM+Attention':
inputs = Input(name='inputs',shape=[max_words,], dtype='float64')
layer = Embedding(top_words, 32, input_length=max_words, trainable=False)(inputs)
bilstm = Bidirectional(LSTM(64, return_sequences=True))(layer) #参数保持维度3
bilstm = Bidirectional(LSTM(64, return_sequences=True))(bilstm)
layer = Dense(256, activation='relu')(bilstm)
layer = Dropout(0.2)(layer)
## 注意力机制
attention = Attention(step_dim=max_words)(layer)
layer = Dense(128, activation='relu')(attention)
output = Dense(num_labels, activation='softmax')(layer)
model = Model(inputs=inputs, outputs=output)
elif mode=='BiGRU+Attention':
inputs = Input(name='inputs',shape=[max_words,], dtype='float64')
layer = Embedding(top_words, 32, input_length=max_words, trainable=False)(inputs)
attention_probs = Dense(32, activation='softmax', name='attention_vec')(layer)
attention_mul = Multiply()([layer, attention_probs])
mlp = Dense(64,activation='relu')(attention_mul) #原始的全连接
#bat=BatchNormalization()(mlp)
#act=Activation('relu')
gru=Bidirectional(GRU(32))(mlp)
mlp = Dense(16,activation='relu')(gru)
output = Dense(num_labels, activation='softmax')(mlp)
model = Model(inputs=[inputs], outputs=output)
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
return model前几个简单的单一模型使用的是搭积木一样最简单的定义方式。后面复杂一点的模型都是使用的Functional API实现的。
下面再定义损失和精度的图,和混淆矩阵指标等等评价体系的函数
#定义损失和精度的图,和混淆矩阵指标等等
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
from sklearn.metrics import cohen_kappa_score
def plot_loss(history):
# 显示训练和验证损失图表
plt.subplots(1,2,figsize=(10,3))
plt.subplot(121)
loss = history.history["loss"]
epochs = range(1, len(loss)+1)
val_loss = history.history["val_loss"]
plt.plot(epochs, loss, "bo", label="Training Loss")
plt.plot(epochs, val_loss, "r", label="Validation Loss")
plt.title("Training and Validation Loss")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend()
plt.subplot(122)
acc = history.history["accuracy"]
val_acc = history.history["val_accuracy"]
plt.plot(epochs, acc, "b-", label="Training Acc")
plt.plot(epochs, val_acc, "r--", label="Validation Acc")
plt.title("Training and Validation Accuracy")
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.legend()
plt.tight_layout()
plt.show()
def plot_confusion_matrix(model,X_test,Y_test_original):
#预测概率
prob=model.predict(X_test)
#预测类别
pred=np.argmax(prob,axis=1)
#数据透视表,混淆矩阵
table = pd.crosstab(Y_test_original, pred, rownames=['Actual'], colnames=['Predicted'])
#print(table)
sns.heatmap(table,cmap='Blues',fmt='.20g', annot=True)
plt.tight_layout()
plt.show()
#计算混淆矩阵的各项指标
print(classification_report(Y_test_original, pred))
#科恩Kappa指标
print('科恩Kappa'+str(cohen_kappa_score(Y_test_original, pred)))定义训练函数
#定义训练函数
def train_fuc(max_words=max_words,mode='BiLSTM+Attention',batch_size=32,epochs=10,hidden_dim=[32],show_loss=True,show_confusion_matrix=True):
#构建模型
model=build_model(max_words=max_words,mode=mode)
print(model.summary())
history=model.fit(X_train, Y_train,batch_size=batch_size,epochs=epochs,validation_split=0.2, verbose=1)
print('————————————训练完毕————————————')
# 评估模型
loss, accuracy = model.evaluate(X_test, Y_test)
print("测试数据集的准确度 = :.4f".format(accuracy))
if show_loss:
plot_loss(history)
if show_confusion_matrix:
plot_confusion_matrix(model=model,X_test=X_test,Y_test_original=Y_test_original)设定一些参数
top_words=6000
max_words=20
batch_size=32
epochs=4
show_confusion_matrix=True
show_loss=True
mode='MLP' 训练轮数为4,比较少,因为这个数据集少,而且太简单了,每个句子很短,所以前面单一模型很容易过拟合,就只训练个4轮,也能节约时间。
下面开始一个个模型去训练并且评价:
MLP
train_fuc(mode='MLP',batch_size=batch_size,epochs=epochs)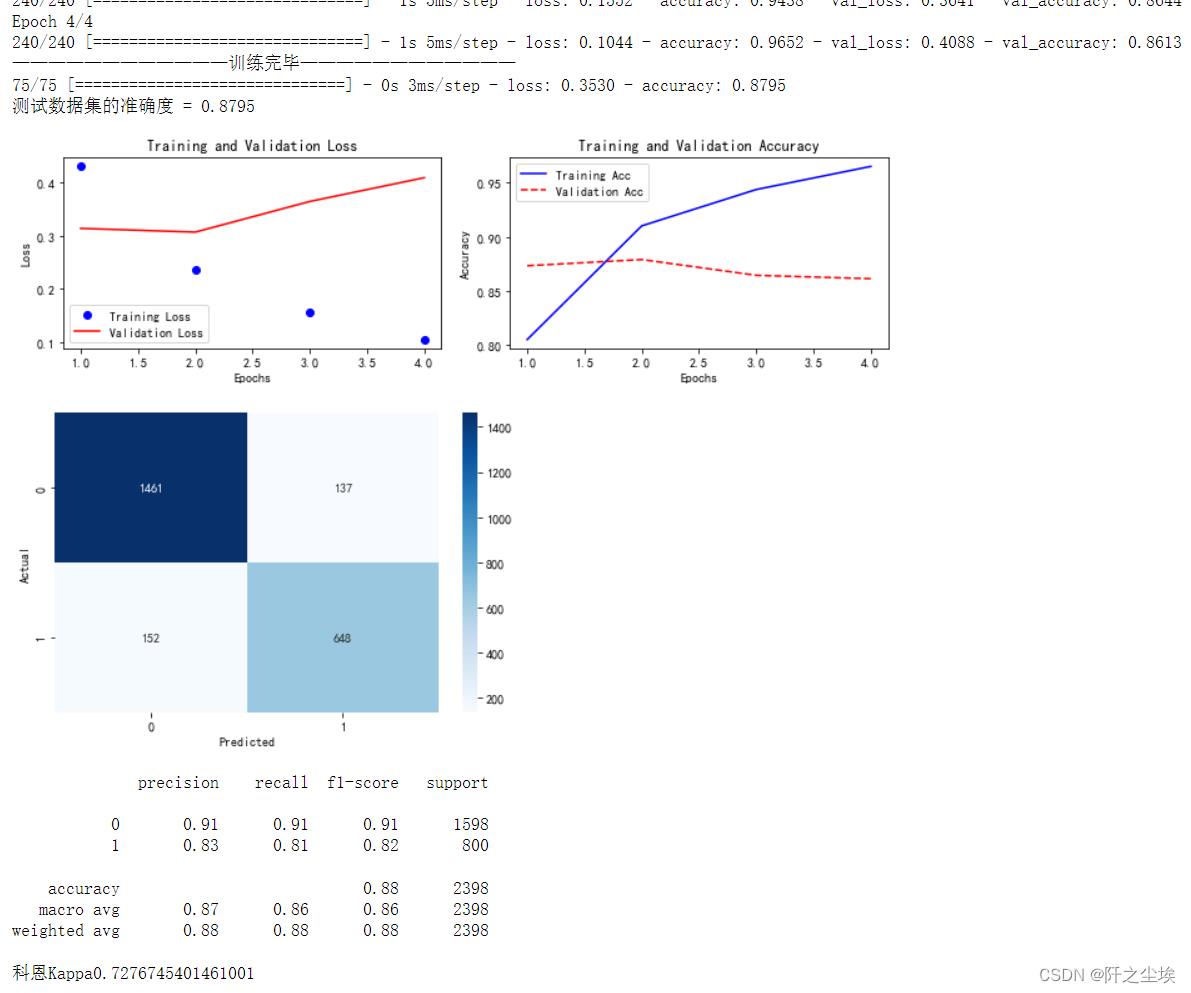
如图,给出了训练每一轮的损失精度,和验证集的损失精度。并且画图,然后测试集的精度,画出的混淆矩阵,计算了混淆矩阵的一些指标,还有科恩系数。MLP测试集精度为0.8795
1DCNN
#下面模型都是接受三维数据输入,先把X变个形状
X_train= X_train.reshape((X_train.shape[0], X_train.shape[1], 1))
X_test= X_test.reshape((X_test.shape[0], X_test.shape[1], 1))
train_fuc(mode='CNN',batch_size=batch_size,epochs=epochs)
也差不多,精度为0.8882
RNN
model='RNN'
train_fuc(mode=model,epochs=epochs)
结果类似,不展示那么多了,测试集精度为0.8912
LSTM
train_fuc(mode='LSTM',epochs=epochs)结果类似,不展示了,测试集精度为0.8966 (目前来看最高)
GRU
train_fuc(mode='GRU',epochs=epochs)测试集精度为0.8912
CNN+LSTM
train_fuc(mode='CNN+LSTM',epochs=epochs)测试集精度为0.8916
BiLSTM
train_fuc(mode='BiLSTM',epochs=epochs)测试数据集的准确度 0.8816
TextCNN
train_fuc(mode='TextCNN',epochs=30)这里加大了训练轮数,因为下面的模型都开始比较复杂,不容易过拟合,而且需要更多的训练轮数
测试集精度为0.8474
Attention
train_fuc(mode='Attention',epochs=100)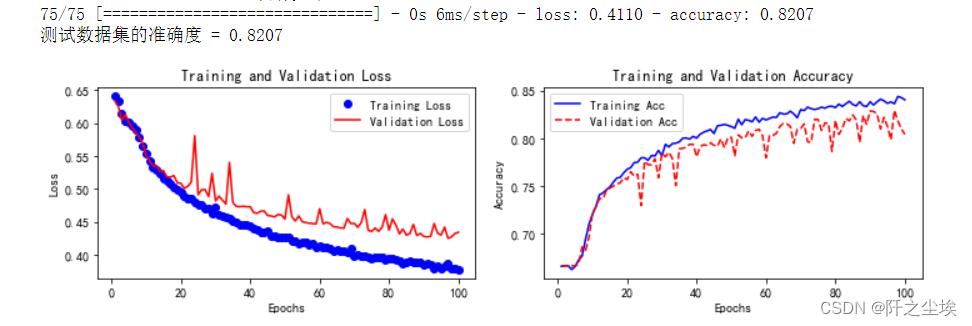
测试集精度为0.8207
BiLSTM+Attention
train_fuc(mode='BiLSTM+Attention',epochs=30)测试集精度0.8236
BiGRU+Attention
train_fuc(mode='BiGRU+Attention',epochs=100)
测试集精度0.8607
Attention*3
train_fuc(mode='Attention*3',epochs=50)测试集精度0.8057
很明显,加了注意力机制的模型训练更加不容易过拟合。单一的循环网络才四轮就会过拟合,而注意力机制同时需要的训练轮数也更多,可以看到验证集精度一直在上升,损失一直在下降。
虽然最后整体的测试集的准确率不如前面的单一网络,但我猜测这应该是训练轮数不够和数据量过小的原因。
这个外卖的数据集实在是太短了,比较简单,而且样本量也不大。
而且和Transform比起来,这里的注意力机制没有采用残差连接,批量归一化等技巧,没有使用编码解码器,也没有堆叠很多层(Transform有18个注意力层)
以后可以在更复杂,更多的数据集上进行测试和训练注意力机制,把网络做大做深一点,多调参尝试,当然前提是需要有更多的计算资源(买台好电脑).....
万字总结Keras深度学习中文文本分类
摘要:文章将详细讲解Keras实现经典的深度学习文本分类算法,包括LSTM、BiLSTM、BiLSTM+Attention和CNN、TextCNN。
本文分享自华为云社区《Keras深度学习中文文本分类万字总结(CNN、TextCNN、BiLSTM、注意力)》,作者: eastmount。
一.文本分类概述
文本分类旨在对文本集按照一定的分类体系或标准进行自动分类标记,属于一种基于分类体系的自动分类。文本分类最早可以追溯到上世纪50年代,那时主要通过专家定义规则来进行文本分类;80年代出现了利用知识工程建立的专家系统;90年代开始借助于机器学习方法,通过人工特征工程和浅层分类模型来进行文本分类。现在多采用词向量以及深度神经网络来进行文本分类。

牛亚峰老师将传统的文本分类流程归纳如下图所示。在传统的文本分类中,基本上大部分机器学习方法都在文本分类领域有所应用。主要包括:
- Naive Bayes
- KNN
- SVM
- 集合类方法
- 最大熵
- 神经网络

利用Keras框架进行文本分类的基本流程如下:
步骤 1:文本的预处理,分词->去除停用词->统计选择top n的词做为特征词
步骤 2:为每个特征词生成ID
步骤 3:将文本转化成ID序列,并将左侧补齐
步骤 4:训练集shuffle
步骤 5:Embedding Layer 将词转化为词向量
步骤 6:添加模型,构建神经网络结构
步骤 7:训练模型
步骤 8:得到准确率、召回率、F1值
注意,如果使用TFIDF而非词向量进行文档表示,则直接分词去停后生成TFIDF矩阵后输入模型。
深度学习文本分类方法包括:
- 卷积神经网络(TextCNN)
- 循环神经网络(TextRNN)
- TextRNN+Attention
- TextRCNN(TextRNN+CNN)
- BiLSTM+Attention
- 迁移学习

推荐牛亚峰老师的文章:
- 基于 word2vec 和 CNN 的文本分类 :综述 & 实践
二.数据预处理及分词
这篇文章主要以代码为主,算法原理知识前面的文章和后续文章再继续补充。数据集如下图所示:
- 训练集:news_dataset_train.csv
游戏主题(10000)、体育主题(10000)、文化主题(10000)、财经主题(10000)
- 测试集:news_dataset_test.csv
游戏主题(5000)、体育主题(5000)、文化主题(5000)、财经主题(5000)
- 验证集:news_dataset_val.csv
游戏主题(5000)、体育主题(5000)、文化主题(5000)、财经主题(5000)

首先需要进行中文分词预处理,调用Jieba库实现。代码如下:
- data_preprocess.py
# -*- coding:utf-8 -*-
# By:Eastmount CSDN 2021-03-19
import csv
import pandas as pd
import numpy as np
import jieba
import jieba.analyse
#添加自定义词典和停用词典
jieba.load_userdict("user_dict.txt")
stop_list = pd.read_csv(stop_words.txt,
engine=python,
encoding=utf-8,
delimiter="\\n",
names=[t])[t].tolist()
#-----------------------------------------------------------------------
#Jieba分词函数
def txt_cut(juzi):
return [w for w in jieba.lcut(juzi) if w not in stop_list]
#-----------------------------------------------------------------------
#中文分词读取文件
def fenci(filename,result):
#写入分词结果
fw = open(result, "w", newline = ,encoding = gb18030)
writer = csv.writer(fw)
writer.writerow([label,cutword])
#使用csv.DictReader读取文件中的信息
labels = []
contents = []
with open(filename, "r", encoding="UTF-8") as f:
reader = csv.DictReader(f)
for row in reader:
#数据元素获取
labels.append(row[label])
content = row[content]
#中文分词
seglist = txt_cut(content)
#空格拼接
output = .join(list(seglist))
contents.append(output)
#文件写入
tlist = []
tlist.append(row[label])
tlist.append(output)
writer.writerow(tlist)
print(labels[:5])
print(contents[:5])
fw.close()
#-----------------------------------------------------------------------
#主函数
if __name__ == __main__:
fenci("news_dataset_train.csv", "news_dataset_train_fc.csv")
fenci("news_dataset_test.csv", "news_dataset_test_fc.csv")
fenci("news_dataset_val.csv", "news_dataset_val_fc.csv")
运行结果如下图所示:


接着我们尝试简单查看数据的长度分布情况及标签可视化。
- data_show.py
# -*- coding: utf-8 -*-
"""
Created on 2021-03-19
@author: xiuzhang Eastmount CSDN
"""
import pandas as pd
import numpy as np
from sklearn import metrics
import matplotlib.pyplot as plt
import seaborn as sns
#---------------------------------------第一步 数据读取------------------------------------
## 读取测数据集
train_df = pd.read_csv("news_dataset_train_fc.csv")
val_df = pd.read_csv("news_dataset_val_fc.csv")
test_df = pd.read_csv("news_dataset_test_fc.csv")
print(train_df.head())
## 解决中文显示问题
plt.rcParams[font.sans-serif] = [KaiTi] #指定默认字体 SimHei黑体
plt.rcParams[axes.unicode_minus] = False #解决保存图像是负号
## 查看训练集都有哪些标签
plt.figure()
sns.countplot(train_df.label)
plt.xlabel(Label,size = 10)
plt.xticks(size = 10)
plt.show()
## 分析训练集中词组数量的分布
print(train_df.cutwordnum.describe())
plt.figure()
plt.hist(train_df.cutwordnum,bins=100)
plt.xlabel("词组长度", size = 12)
plt.ylabel("频数", size = 12)
plt.title("训练数据集")
plt.show()
输出结果如下图所示,后面的文章我们会介绍论文如何绘制好看的图表。

注意,如果报错“UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xce in position 17: invalid continuation byte”,需要将CSV文件保存为UTF-8格式,如下图所示。

三.CNN中文文本分类
1.原理介绍
卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),是深度学习(deep learning)的代表算法之一。它通常应用于图像识别和语音识等领域,并能给出更优秀的结果,也可以应用于视频分析、机器翻译、自然语言处理、药物发现等领域。著名的阿尔法狗让计算机看懂围棋就是基于卷积神经网络的。
- 卷积是指不在对每个像素做处理,而是对图片区域进行处理,这种做法加强了图片的连续性,看到的是一个图形而不是一个点,也加深了神经网络对图片的理解。
- 通常卷积神经网络会依次经历“图片->卷积->持化->卷积->持化->结果传入两层全连接神经层->分类器”的过程,最终实现一个CNN的分类处理。

2.代码实现
Keras实现文本分类的CNN代码如下:
- Keras_CNN_cnews.py
# -*- coding: utf-8 -*-
"""
Created on 2021-03-19
@author: xiuzhang Eastmount CSDN
CNN Model
"""
import os
import time
import pickle
import pandas as pd
import numpy as np
from sklearn import metrics
import matplotlib.pyplot as plt
import seaborn as sns
import tensorflow as tf
from sklearn.preprocessing import LabelEncoder,OneHotEncoder
from keras.models import Model
from keras.layers import LSTM, Activation, Dense, Dropout, Input, Embedding
from keras.layers import Convolution1D, MaxPool1D, Flatten
from keras.preprocessing.text import Tokenizer
from keras.preprocessing import sequence
from keras.callbacks import EarlyStopping
from keras.models import load_model
from keras.models import Sequential
## GPU处理 读者如果是CPU注释该部分代码即可
## 指定每个GPU进程中使用显存的上限 0.9表示可以使用GPU 90%的资源进行训练
os.environ["CUDA_DEVICES_ORDER"] = "PCI_BUS_IS"
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.8)
sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options))
start = time.clock()
#----------------------------第一步 数据读取----------------------------
## 读取测数据集
train_df = pd.read_csv("news_dataset_train_fc.csv")
val_df = pd.read_csv("news_dataset_val_fc.csv")
test_df = pd.read_csv("news_dataset_test_fc.csv")
print(train_df.head())
## 解决中文显示问题
plt.rcParams[font.sans-serif] = [KaiTi] #指定默认字体 SimHei黑体
plt.rcParams[axes.unicode_minus] = False #解决保存图像是负号
#--------------------------第二步 OneHotEncoder()编码--------------------
## 对数据集的标签数据进行编码
train_y = train_df.label
val_y = val_df.label
test_y = test_df.label
print("Label:")
print(train_y[:10])
le = LabelEncoder()
train_y = le.fit_transform(train_y).reshape(-1,1)
val_y = le.transform(val_y).reshape(-1,1)
test_y = le.transform(test_y).reshape(-1,1)
print("LabelEncoder")
print(train_y[:10])
print(len(train_y))
## 对数据集的标签数据进行one-hot编码
ohe = OneHotEncoder()
train_y = ohe.fit_transform(train_y).toarray()
val_y = ohe.transform(val_y).toarray()
test_y = ohe.transform(test_y).toarray()
print("OneHotEncoder:")
print(train_y[:10])
#-----------------------第三步 使用Tokenizer对词组进行编码--------------------
max_words = 6000
max_len = 600
tok = Tokenizer(num_words=max_words) #最大词语数为6000
print(train_df.cutword[:5])
print(type(train_df.cutword))
## 防止语料中存在数字str处理
train_content = [str(a) for a in train_df.cutword.tolist()]
val_content = [str(a) for a in val_df.cutword.tolist()]
test_content = [str(a) for a in test_df.cutword.tolist()]
tok.fit_on_texts(train_content)
print(tok)
#当创建Tokenizer对象后 使用fit_on_texts()函数识别每个词
#tok.fit_on_texts(train_df.cutword)
## 保存训练好的Tokenizer和导入
with open(tok.pickle, wb) as handle: #saving
pickle.dump(tok, handle, protocol=pickle.HIGHEST_PROTOCOL)
with open(tok.pickle, rb) as handle: #loading
tok = pickle.load(handle)
## 使用word_index属性查看每个词对应的编码
## 使用word_counts属性查看每个词对应的频数
for ii,iterm in enumerate(tok.word_index.items()):
if ii < 10:
print(iterm)
else:
break
print("===================")
for ii,iterm in enumerate(tok.word_counts.items()):
if ii < 10:
print(iterm)
else:
break
#---------------------------第四步 数据转化为序列-----------------------------
## 使用sequence.pad_sequences()将每个序列调整为相同的长度
## 对每个词编码之后,每句新闻中的每个词就可以用对应的编码表示,即每条新闻可以转变成一个向量了
train_seq = tok.texts_to_sequences(train_content)
val_seq = tok.texts_to_sequences(val_content)
test_seq = tok.texts_to_sequences(test_content)
## 将每个序列调整为相同的长度
train_seq_mat = sequence.pad_sequences(train_seq,maxlen=max_len)
val_seq_mat = sequence.pad_sequences(val_seq,maxlen=max_len)
test_seq_mat = sequence.pad_sequences(test_seq,maxlen=max_len)
print("数据转换序列")
print(train_seq_mat.shape)
print(val_seq_mat.shape)
print(test_seq_mat.shape)
print(train_seq_mat[:2])
#-------------------------------第五步 建立CNN模型--------------------------
## 类别为4个
num_labels = 4
inputs = Input(name=inputs,shape=[max_len], dtype=float64)
## 词嵌入使用预训练的词向量
layer = Embedding(max_words+1, 128, input_length=max_len, trainable=False)(inputs)
## 卷积层和池化层(词窗大小为3 128核)
cnn = Convolution1D(128, 3, padding=same, strides = 1, activation=relu)(layer)
cnn = MaxPool1D(pool_size=4)(cnn)
## Dropout防止过拟合
flat = Flatten()(cnn)
drop = Dropout(0.3)(flat)
## 全连接层
main_output = Dense(num_labels, activation=softmax)(drop)
model = Model(inputs=inputs, outputs=main_output)
## 优化函数 评价指标
model.summary()
model.compile(loss="categorical_crossentropy",
optimizer=adam, # RMSprop()
metrics=["accuracy"])
#-------------------------------第六步 模型训练和预测--------------------------
## 先设置为train训练 再设置为test测试
flag = "train"
if flag == "train":
print("模型训练")
## 模型训练 当val-loss不再提升时停止训练 0.0001
model_fit = model.fit(train_seq_mat, train_y, batch_size=128, epochs=10,
validation_data=(val_seq_mat,val_y),
callbacks=[EarlyStopping(monitor=val_loss,min_delta=0.0001)]
)
## 保存模型
model.save(my_model.h5)
del model # deletes the existing model
## 计算时间
elapsed = (time.clock() - start)
print("Time used:", elapsed)
print(model_fit.history)
else:
print("模型预测")
## 导入已经训练好的模型
model = load_model(my_model.h5)
## 对测试集进行预测
test_pre = model.predict(test_seq_mat)
## 评价预测效果,计算混淆矩阵
confm = metrics.confusion_matrix(np.argmax(test_y,axis=1),np.argmax(test_pre,axis=1))
print(confm)
## 混淆矩阵可视化
Labname = ["体育", "文化", "财经", "游戏"]
print(metrics.classification_report(np.argmax(test_y,axis=1),np.argmax(test_pre,axis=1)))
plt.figure(figsize=(8,8))
sns.heatmap(confm.T, square=True, annot=True,
fmt=d, cbar=False, linewidths=.6,
cmap="YlGnBu")
plt.xlabel(True label,size = 14)
plt.ylabel(Predicted label, size = 14)
plt.xticks(np.arange(4)+0.5, Labname, size = 12)
plt.yticks(np.arange(4)+0.5, Labname, size = 12)
plt.savefig(result.png)
plt.show()
#----------------------------------第七 验证算法--------------------------
## 使用tok对验证数据集重新预处理,并使用训练好的模型进行预测
val_seq = tok.texts_to_sequences(val_df.cutword)
## 将每个序列调整为相同的长度
val_seq_mat = sequence.pad_sequences(val_seq,maxlen=max_len)
## 对验证集进行预测
val_pre = model.predict(val_seq_mat)
print(metrics.classification_report(np.argmax(val_y,axis=1),np.argmax(val_pre,axis=1)))
## 计算时间
elapsed = (time.clock() - start)
print("Time used:", elapsed)
GPU运行如下图所示。注意,如果您的电脑是CPU版本,只需要将上述代码第一部分注释掉即可,后面LSTM部分使用GPU对应的库函数。

训练输出模型如下图所示:

训练输出结果如下:
模型训练
Train on 40000 samples, validate on 20000 samples
Epoch 1/10
40000/40000 [==============================] - 15s 371us/step - loss: 1.1798 - acc: 0.4772 - val_loss: 0.9878 - val_acc: 0.5977
Epoch 2/10
40000/40000 [==============================] - 4s 93us/step - loss: 0.8681 - acc: 0.6612 - val_loss: 0.8167 - val_acc: 0.6746
Epoch 3/10
40000/40000 [==============================] - 4s 92us/step - loss: 0.7268 - acc: 0.7245 - val_loss: 0.7084 - val_acc: 0.7330
Epoch 4/10
40000/40000 [==============================] - 4s 93us/step - loss: 0.6369 - acc: 0.7643 - val_loss: 0.6462 - val_acc: 0.7617
Epoch 5/10
40000/40000 [==============================] - 4s 96us/step - loss: 0.5670 - acc: 0.7957 - val_loss: 0.5895 - val_acc: 0.7867
Epoch 6/10
40000/40000 [==============================] - 4s 92us/step - loss: 0.5074 - acc: 0.8226 - val_loss: 0.5530 - val_acc: 0.8018
Epoch 7/10
40000/40000 [==============================] - 4s 93us/step - loss: 0.4638 - acc: 0.8388 - val_loss: 0.5105 - val_acc: 0.8185
Epoch 8/10
40000/40000 [==============================] - 4s 93us/step - loss: 0.4241 - acc: 0.8545 - val_loss: 0.4836 - val_acc: 0.8304
Epoch 9/10
40000/40000 [==============================] - 4s 92us/step - loss: 0.3900 - acc: 0.8692 - val_loss: 0.4599 - val_acc: 0.8403
Epoch 10/10
40000/40000 [==============================] - 4s 93us/step - loss: 0.3657 - acc: 0.8761 - val_loss: 0.4472 - val_acc: 0.8457
Time used: 52.203992899999996
预测及验证结果如下:

[[3928 472 264 336]
[ 115 4529 121 235]
[ 151 340 4279 230]
[ 145 593 195 4067]]
precision recall f1-score support
0 0.91 0.79 0.84 5000
1 0.76 0.91 0.83 5000
2 0.88 0.86 0.87 5000
3 0.84 0.81 0.82 5000
avg / total 0.85 0.84 0.84 20000
precision recall f1-score support
0 0.90 0.77 0.83 5000
1 0.78 0.92 0.84 5000
2 0.88 0.85 0.86 5000
3 0.84 0.85 0.85 5000
avg / total 0.85 0.85 0.85 20000
四.TextCNN中文文本分类
1.原理介绍
TextCNN 是利用卷积神经网络对文本进行分类的算法,由 Yoon Kim 于2014年在 “Convolutional Neural Networks for Sentence Classification” 一文中提出的算法。
卷积神经网络的核心思想是捕捉局部特征,对于文本来说,局部特征就是由若干单词组成的滑动窗口,类似于N-gram。卷积神经网络的优势在于能够自动地对N-gram特征进行组合和筛选,获得不同抽象层次的语义信息。下图是该论文中用于文本分类的卷积神经网络模型架构。

另一篇TextCNN比较经典的论文是《A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification》,其模型结果如下图所示。主要用于文本分类任务的TextCNN结构描述,详细解释了TextCNN架构及词向量矩阵是如何做卷积的。

假设我们有一些句子需要对其进行分类。句子中每个词是由n维词向量组成的,也就是说输入矩阵大小为m*n,其中m为句子长度。CNN需要对输入样本进行卷积操作,对于文本数据,filter不再横向滑动,仅仅是向下移动,有点类似于N-gram在提取词与词间的局部相关性。
图中共有三种步长策略,分别是2、3、4,每个步长都有两个filter(实际训练时filter数量会很多)。在不同词窗上应用不同filter,最终得到6个卷积后的向量。然后对每一个向量进行最大化池化操作并拼接各个池化值,最终得到这个句子的特征表示,将这个句子向量丢给分类器进行分类,最终完成整个文本分类流程。
最后真心推荐下面这些大佬关于TextCNN的介绍,尤其是CSDN的Asia-Lee大佬,很喜欢他的文章,真心棒!
- 《Convolutional Neural Networks for Sentence Classification2014》
- 《A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification》
- https://blog.csdn.net/asialee_bird/article/details/88813385
- https://zhuanlan.zhihu.com/p/77634533
2.代码实现
Keras实现文本分类的TextCNN代码如下:
- Keras_TextCNN_cnews.py
# -*- coding: utf-8 -*-
"""
Created on 2021-03-19
@author: xiuzhang Eastmount CSDN
TextCNN Model
"""
import os
import time
import pickle
import pandas as pd
import numpy as np
from sklearn import metrics
import matplotlib.pyplot as plt
import seaborn as sns
import tensorflow as tf
from sklearn.preprocessing import LabelEncoder,OneHotEncoder
from keras.models import Model
from keras.layers import LSTM, Activation, Dense, Dropout, Input, Embedding
from keras.layers import Convolution1D, MaxPool1D, Flatten
from keras.preprocessing.text import Tokenizer
from keras.preprocessing import sequence
from keras.callbacks import EarlyStopping
from keras.models import load_model
from keras.models import Sequential
from keras.layers.merge import concatenate
## GPU处理 读者如果是CPU注释该部分代码即可
## 指定每个GPU进程中使用显存的上限 0.9表示可以使用GPU 90%的资源进行训练
os.environ["CUDA_DEVICES_ORDER"] = "PCI_BUS_IS"
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.8)
sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options))
start = time.clock()
#----------------------------第一步 数据读取----------------------------
## 读取测数据集
train_df = pd.read_csv("news_dataset_train_fc.csv")
val_df = pd.read_csv("news_dataset_val_fc.csv")
test_df = pd.read_csv("news_dataset_test_fc.csv")
## 解决中文显示问题
plt.rcParams[font.sans-serif] = [KaiTi] #指定默认字体 SimHei黑体
plt.rcParams[axes.unicode_minus] = False #解决保存图像是负号
#--------------------------第二步 OneHotEncoder()编码--------------------
## 对数据集的标签数据进行编码
train_y = train_df.label
val_y = val_df.label
test_y = test_df.label
print("Label:")
print(train_y[:10])
le = LabelEncoder()
train_y = le.fit_transform(train_y).reshape(-1,1)
val_y = le.transform(val_y).reshape(-1,1)
test_y = le.transform(test_y).reshape(-1,1)
print("LabelEncoder")
print(train_y[:10])
print(len(train_y))
## 对数据集的标签数据进行one-hot编码
ohe = OneHotEncoder()
train_y = ohe.fit_transform(train_y).toarray()
val_y = ohe.transform(val_y).toarray()
test_y = ohe.transform(test_y).toarray()
print("OneHotEncoder:")
print(train_y[:10])
#-----------------------第三步 使用Tokenizer对词组进行编码--------------------
max_words = 6000
max_len = 600
tok = Tokenizer(num_words=max_words) #最大词语数为6000
print(train_df.cutword[:5])
print(type(train_df.cutword))
## 防止语料中存在数字str处理
train_content = [str(a) for a in train_df.cutword.tolist()]
val_content = [str(a) for a in val_df.cutword.tolist()]
test_content = [str(a) for a in test_df.cutword.tolist()]
tok.fit_on_texts(train_content)
print(tok)
## 保存训练好的Tokenizer和导入
with open(tok.pickle, wb) as handle: #saving
pickle.dump(tok, handle, protocol=pickle.HIGHEST_PROTOCOL)
with open(tok.pickle, rb) as handle: #loading
tok = pickle.load(handle)
#---------------------------第四步 数据转化为序列-----------------------------
train_seq = tok.texts_to_sequences(train_content)
val_seq = tok.texts_to_sequences(val_content)
test_seq = tok.texts_to_sequences(test_content)
## 将每个序列调整为相同的长度
train_seq_mat = sequence.pad_sequences(train_seq,maxlen=max_len)
val_seq_mat = sequence.pad_sequences(val_seq,maxlen=max_len)
test_seq_mat = sequence.pad_sequences(test_seq,maxlen=max_len)
print("数据转换序列")
print(train_seq_mat.shape)
print(val_seq_mat.shape)
print(test_seq_mat.shape)
print(train_seq_mat[:2])
#-------------------------------第五步 建立TextCNN模型--------------------------
## 类别为4个
num_labels = 4
inputs = Input(name=inputs,shape=[max_len], dtype=float64)
## 词嵌入使用预训练的词向量
layer = Embedding(max_words+1, 256, input_length=max_len, trainable=False)(inputs)
## 词窗大小分别为3,4,5
cnn1 = Convolution1D(256, 3, padding=same, strides = 1, activation=relu)(layer)
cnn1 = MaxPool1D(pool_size=4)(cnn1)
cnn2 = Convolution1D(256, 4, padding=same, strides = 1, activation=relu)(layer)
cnn2 = MaxPool1D(pool_size=4)(cnn2)
cnn3 = Convolution1D(256, 5, padding=same, strides = 1, activation=relu)(layer)
cnn3 = MaxPool1D(pool_size=4)(cnn3)
# 合并三个模型的输出向量
cnn = concatenate([cnn1,cnn2,cnn3], axis=-1)
flat = Flatten()(cnn)
drop = Dropout(0.2)(flat)
main_output = Dense(num_labels, activation=softmax)(drop)
model = Model(inputs=inputs, outputs=main_output)
model.summary()
model.compile(loss="categorical_crossentropy",
optimizer=adam, # RMSprop()
metrics=["accuracy"])
#-------------------------------第六步 模型训练和预测--------------------------
## 先设置为train训练 再设置为test测试
flag = "train"
if flag == "train":
print("模型训练")
## 模型训练 当val-loss不再提升时停止训练 0.0001
model_fit = model.fit(train_seq_mat, train_y, batch_size=128, epochs=10,
validation_data=(val_seq_mat,val_y),
callbacks=[EarlyStopping(monitor=val_loss,min_delta=0.0001)]
)
model.save(my_model.h5)
del model
elapsed = (time.clock() - start)
print("Time used:", elapsed)
print(model_fit.history)
else:
print("模型预测")
## 导入已经训练好的模型
model = load_model(my_model.h5)
## 对测试集进行预测
test_pre = model.predict(test_seq_mat)
## 评价预测效果,计算混淆矩阵
confm = metrics.confusion_matrix(np.argmax(test_y,axis=1),np.argmax(test_pre,axis=1))
print(confm)
## 混淆矩阵可视化
Labname = ["体育", "文化", "财经", "游戏"]
print(metrics.classification_report(np.argmax(test_y,axis=1),np.argmax(test_pre,axis=1)))
plt.figure(figsize=(8,8))
sns.heatmap(confm.T, square=True, annot=True,
fmt=d, cbar=False, linewidths=.6,
cmap="YlGnBu")
plt.xlabel(True label,size = 14)
plt.ylabel(Predicted label, size = 14)
plt.xticks(np.arange(4)+0.5, Labname, size = 12)
plt.yticks(np.arange(4)+0.5, Labname, size = 12)
plt.savefig(result.png)
plt.show()
#----------------------------------第七 验证算法--------------------------
## 使用tok对验证数据集重新预处理,并使用训练好的模型进行预测
val_seq = tok.texts_to_sequences(val_df.cutword)
## 将每个序列调整为相同的长度
val_seq_mat = sequence.pad_sequences(val_seq,maxlen=max_len)
## 对验证集进行预测
val_pre = model.predict(val_seq_mat)
print(metrics.classification_report(np.argmax(val_y,axis=1),np.argmax(val_pre,axis=1)))
elapsed = (time.clock() - start)
print("Time used:", elapsed)
训练模型如下所示:
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
inputs (InputLayer) (None, 600) 0
__________________________________________________________________________________________________
embedding_1 (Embedding) (None, 600, 256) 1536256 inputs[0][0]
__________________________________________________________________________________________________
conv1d_1 (Conv1D) (None, 600, 256) 196864 embedding_1[0][0]
__________________________________________________________________________________________________
conv1d_2 (Conv1D) (None, 600, 256) 262400 embedding_1[0][0]
__________________________________________________________________________________________________
conv1d_3 (Conv1D) (None, 600, 256) 327936 embedding_1[0][0]
__________________________________________________________________________________________________
max_pooling1d_1 (MaxPooling1D) (None, 150, 256) 0 conv1d_1[0][0]
__________________________________________________________________________________________________
max_pooling1d_2 (MaxPooling1D) (None, 150, 256) 0 conv1d_2[0][0]
__________________________________________________________________________________________________
max_pooling1d_3 (MaxPooling1D) (None, 150, 256) 0 conv1d_3[0][0]
__________________________________________________________________________________________________
concatenate_1 (Concatenate) (None, 150, 768) 0 max_pooling1d_1[0][0]
max_pooling1d_2[0][0]
max_pooling1d_3[0][0]
__________________________________________________________________________________________________
flatten_1 (Flatten) (None, 115200) 0 concatenate_1[0][0]
__________________________________________________________________________________________________
dropout_1 (Dropout) (None, 115200) 0 flatten_1[0][0]
__________________________________________________________________________________________________
dense_1 (Dense) (None, 4) 460804 dropout_1[0][0]
==================================================================================================
Total params: 2,784,260
Trainable params: 1,248,004
Non-trainable params: 1,536,256
__________________________________________________________________________________________________
预测结果如下:

[[4448 238 182 132]
[ 151 4572 124 153]
[ 185 176 4545 94]
[ 181 394 207 4218]]
precision recall f1-score support
0 0.90 0.89 0.89 5000
1 0.85 0.91 0.88 5000
2 0.90 0.91 0.90 5000
3 0.92 0.84 0.88 5000
avg / total 0.89 0.89 0.89 20000
precision recall f1-score support
0 0.90 0.88 0.89 5000
1 0.86 0.93 0.89 5000
2 0.91 0.89 0.90 5000
3 0.92 0.88 0.90 5000
avg / total 0.90 0.90 0.90 20000
五.LSTM中文文本分类
1.原理介绍
Long Short Term 网络(LSTM)是一种RNN(Recurrent Neural Network)特殊的类型,可以学习长期依赖信息。LSTM 由Hochreiter & Schmidhuber (1997)提出,并在近期被Alex Graves进行了改良和推广。在很多问题,LSTM都取得相当巨大的成功,并得到了广泛的使用。
由于RNN存在梯度消失的问题,人们对于序列索引位置t的隐藏结构做了改进,通过一些技巧让隐藏结构复杂起来,来避免梯度消失的问题,这样的特殊RNN就是我们的LSTM。LSTM的全称是Long Short-Term Memory。LSTM由于其设计的特点,非常适合用于对时序数据的建模,如文本数据。LSTM的结构如下图:

LSTM 通过刻意的设计来避免长期依赖问题。记住长期的信息在实践中是 LSTM 的默认行为,而非需要付出很大代价才能获得的能力。LSTM是在普通的RNN上面做了一些改进,LSTM RNN多了三个控制器,即:
- 输入控制器
- 输出控制器
- 忘记控制器
左边多了个条主线,例如电影的主线剧情,而原本的RNN体系变成了分线剧情,并且三个控制器都在分线上。

- 输入控制器(write gate): 在输入input时设置一个gate,gate的作用是判断要不要写入这个input到我们的内存Memory中,它相当于一个参数,也是可以被训练的,这个参数就是用来控制要不要记住当下这个点。
- 输出控制器(read gate): 在输出位置的gate,判断要不要读取现在的Memory。
- 忘记控制器(forget gate): 处理位置的忘记控制器,判断要不要忘记之前的Memory。
LSTM工作原理为:如果分支内容对于最终结果十分重要,输入控制器会将这个分支内容按重要程度写入主线内容,再进行分析;如果分线内容改变了我们之前的想法,那么忘记控制器会将某些主线内容忘记,然后按比例替换新内容,所以主线内容的更新就取决于输入和忘记控制;最后的输出会基于主线内容和分线内容。通过这三个gate能够很好地控制我们的RNN,基于这些控制机制,LSTM是延缓记忆的良药,从而带来更好的结果。
2.代码实现
Keras实现文本分类的LSTM代码如下:
- Keras_LSTM_cnews.py
"""
Created on 2021-03-19
@author: xiuzhang Eastmount CSDN
LSTM Model
"""
import os
import time
import pickle
import pandas as pd
import numpy as np
from sklearn import metrics
import matplotlib.pyplot as plt
import seaborn as sns
import tensorflow as tf
from sklearn.preprocessing import LabelEncoder,OneHotEncoder
from keras.models import Model
from keras.layers import LSTM, Activation, Dense, Dropout, Input, Embedding
from keras.layers import Convolution1D, MaxPool1D, Flatten
from keras.preprocessing.text import Tokenizer
from keras.preprocessing import sequence
from keras.callbacks import EarlyStopping
from keras.models import load_model
from keras.models import Sequential
#GPU加速 CuDNNLSTM比LSTM快
from keras.layers import CuDNNLSTM, CuDNNGRU
## GPU处理 读者如果是CPU注释该部分代码即可
## 指定每个GPU进程中使用显存的上限 0.9表示可以使用GPU 90%的资源进行训练
os.environ["CUDA_DEVICES_ORDER"] = "PCI_BUS_IS"
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.8)
sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options))
start = time.clock()
#----------------------------第一步 数据读取----------------------------
## 读取测数据集
train_df = pd.read_csv("news_dataset_train_fc.csv")
val_df = pd.read_csv("news_dataset_val_fc.csv")
test_df = pd.read_csv("news_dataset_test_fc.csv")
print(train_df.head())
## 解决中文显示问题
plt.rcParams[font.sans-serif] = [KaiTi] #指定默认字体 SimHei黑体
plt.rcParams[axes.unicode_minus] = False #解决保存图像是负号
#--------------------------第二步 OneHotEncoder()编码--------------------
## 对数据集的标签数据进行编码
train_y = train_df.label
val_y = val_df.label
test_y = test_df.label
print("Label:")
print(train_y[:10])
le = LabelEncoder()
train_y = le.fit_transform(train_y).reshape(-1,1)
val_y = le.transform(val_y).reshape(-1,1)
test_y = le.transform(test_y).reshape(-1,1)
print("LabelEncoder")
print(train_y[:10])
print(len(train_y))
## 对数据集的标签数据进行one-hot编码
ohe = OneHotEncoder()
train_y = ohe.fit_transform(train_y).toarray()
val_y = ohe.transform(val_y).toarray()
test_y = ohe.transform(test_y).toarray()
print("OneHotEncoder:")
print(train_y[:10])
#-----------------------第三步 使用Tokenizer对词组进行编码--------------------
max_words = 6000
max_len = 600
tok = Tokenizer(num_words=max_words) #最大词语数为6000
print(train_df.cutword[:5])
print(type(train_df.cutword))
## 防止语料中存在数字str处理
train_content = [str(a) for a in train_df.cutword.tolist()]
val_content = [str(a) for a in val_df.cutword.tolist()]
test_content = [str(a) for a in test_df.cutword.tolist()]
tok.fit_on_texts(train_content)
print(tok)
## 保存训练好的Tokenizer和导入
with open(tok.pickle, wb) as handle: #saving
pickle.dump(tok, handle, protocol=pickle.HIGHEST_PROTOCOL)
with open(tok.pickle, rb) as handle: #loading
tok = pickle.load(handle)
#---------------------------第四步 数据转化为序列-----------------------------
train_seq = tok.texts_to_sequences(train_content)
val_seq = tok.texts_to_sequences(val_content)
test_seq = tok.texts_to_sequences(test_content)
## 将每个序列调整为相同的长度
train_seq_mat = sequence.pad_sequences(train_seq,maxlen=max_len)
val_seq_mat = sequence.pad_sequences(val_seq,maxlen=max_len)
test_seq_mat = sequence.pad_sequences(test_seq,maxlen=max_len)
print("数据转换序列")
print(train_seq_mat.shape)
print(val_seq_mat.shape)
print(test_seq_mat.shape)
print(train_seq_mat[:2])
#-------------------------------第五步 建立LSTM模型--------------------------
## 定义LSTM模型
inputs = Input(name=inputs,shape=[max_len],dtype=float64)
## Embedding(词汇表大小,batch大小,每个新闻的词长)
layer = Embedding(max_words+1, 128, input_length=max_len)(inputs)
#layer = LSTM(128)(layer)
layer = CuDNNLSTM(128)(layer)
layer = Dense(128, activation="relu", name="FC1")(layer)
layer = Dropout(0.1)(layer)
layer = Dense(4, activation="softmax", name="FC2")(layer)
model = Model(inputs=inputs, outputs=layer)
model.summary()
model.compile(loss="categorical_crossentropy",
optimizer=adam, # RMSprop()
metrics=["accuracy"])
#-------------------------------第六步 模型训练和预测--------------------------
## 先设置为train训练 再设置为test测试
flag = "train"
if flag == "train":
print("模型训练")
## 模型训练 当val-loss不再提升时停止训练 0.0001
model_fit = model.fit(train_seq_mat, train_y, batch_size=128, epochs=10,
validation_data=(val_seq_mat,val_y),
callbacks=[EarlyStopping(monitor=val_loss,min_delta=0.0001)]
)
model.save(my_model.h5)
del model
elapsed = (time.clock() - start)
print("Time used:", elapsed)
print(model_fit.history)
else:
print("模型预测")
## 导入已经训练好的模型
model = load_model(my_model.h5)
## 对测试集进行预测
test_pre = model.predict(test_seq_mat)
## 评价预测效果,计算混淆矩阵
confm = metrics.confusion_matrix(np.argmax(test_y,axis=1),np.argmax(test_pre,axis=1))
print(confm)
## 混淆矩阵可视化
Labname = ["体育", "文化", "财经", "游戏"]
print(metrics.classification_report(np.argmax(test_y,axis=1),np.argmax(test_pre,axis=1)))
plt.figure(figsize=(8,8))
sns.heatmap(confm.T, square=True, annot=True,
fmt=d, cbar=False, linewidths=.6,
cmap="YlGnBu")
plt.xlabel(True label,size = 14)
plt.ylabel(Predicted label, size = 14)
plt.xticks(np.arange(4)+0.8, Labname, size = 12)
plt.yticks(np.arange(4)+0.4, Labname, size = 12)
plt.savefig(result.png)
plt.show()
#----------------------------------第七 验证算法--------------------------
## 使用tok对验证数据集重新预处理,并使用训练好的模型进行预测
val_seq = tok.texts_to_sequences(val_df.cutword)
## 将每个序列调整为相同的长度
val_seq_mat = sequence.pad_sequences(val_seq,maxlen=max_len)
## 对验证集进行预测
val_pre = model.predict(val_seq_mat)
print(metrics.classification_report(np.argmax(val_y,axis=1),np.argmax(val_pre,axis=1)))
elapsed = (time.clock() - start)
print("Time used:", elapsed)
训练输出模型如下所示:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
inputs (InputLayer) (None, 600) 0
_________________________________________________________________
embedding_1 (Embedding) (None, 600, 128) 768128
_________________________________________________________________
cu_dnnlstm_1 (CuDNNLSTM) (None, 128) 132096
_________________________________________________________________
FC1 (Dense) (None, 128) 16512
_________________________________________________________________
dropout_1 (Dropout) (None, 128) 0
_________________________________________________________________
FC2 (Dense) (None, 4) 516
=================================================================
Total params: 917,252
Trainable params: 917,252
Non-trainable params: 0
预测结果如下所示:
[[4539 153 188 120]
[ 47 4628 181 144]
[ 113 133 4697 57]
[ 101 292 157 4450]]
precision recall f1-score support
0 0.95 0.91 0.93 5000
1 0.89 0.93 0.91 5000
2 0.90 0.94 0.92 5000
3 0.93 0.89 0.91 5000
avg / total 0.92 0.92 0.92 20000
precision recall f1-score support
0 0.96 0.89 0.92 5000
1 0.89 0.94 0.92 5000
2 0.90 0.93 0.92 5000
3 0.94 0.92 0.93 5000
avg / total 0.92 0.92 0.92 20000
六.BiLSTM中文文本分类
1.原理介绍
BiLSTM是Bi-directional Long Short-Term Memory的缩写,是由前向LSTM与后向LSTM组合而成。它和LSTM在自然语言处理任务中都常被用来建模上下文信息。前向的LSTM与后向的LSTM结合成BiLSTM。比如,我们对“我爱中国”这句话进行编码,模型如图所示。

由于利用LSTM对句子进行建模还存在一个问题:无法编码从后到前的信息。在更细粒度的分类时,如对于强程度的褒义、弱程度的褒义、中性、弱程度的贬义、强程度的贬义的五分类任务需要注意情感词、程度词、否定词之间的交互。举一个例子,“这个餐厅脏得不行,没有隔壁好”,这里的“不行”是对“脏”的程度的一种修饰,通过BiLSTM可以更好的捕捉双向的语义依赖。
- 参考文章:https://zhuanlan.zhihu.com/p/47802053
2.代码实现
Keras实现文本分类的BiLSTM代码如下:
- Keras_BiLSTM_cnews.py
"""
Created on 2021-03-19
@author: xiuzhang Eastmount CSDN
BiLSTM Model
"""
import os
import time
import pickle
import pandas as pd
import numpy as np
from sklearn import metrics
import matplotlib.pyplot as plt
import seaborn as sns
import tensorflow as tf
from sklearn.preprocessing import LabelEncoder,OneHotEncoder
from keras.models import Model
from keras.layers import LSTM, Activation, Dense, Dropout, Input, Embedding
from keras.layers import Convolution1D, MaxPool1D, Flatten
from keras.preprocessing.text import Tokenizer
from keras.preprocessing import sequence
from keras.callbacks import EarlyStopping
from keras.models import load_model
from keras.models import Sequential
#GPU加速 CuDNNLSTM比LSTM快
from keras.layers import CuDNNLSTM, CuDNNGRU
from keras.layers import Bidirectional
## GPU处理 读者如果是CPU注释该部分代码即可
## 指定每个GPU进程中使用显存的上限 0.9表示可以使用GPU 90%的资源进行训练
os.environ["CUDA_DEVICES_ORDER"] = "PCI_BUS_IS"
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.8)
sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options))
start = time.clock()
#----------------------------第一步 数据读取----------------------------
## 读取测数据集
train_df = pd.read_csv("news_dataset_train_fc.csv")
val_df = pd.read_csv("news_dataset_val_fc.csv")
test_df = pd.read_csv("news_dataset_test_fc.csv")
print(train_df.head())
## 解决中文显示问题
plt.rcParams[font.sans-serif] = [KaiTi] #指定默认字体 SimHei黑体
plt.rcParams[axes.unicode_minus] = False #解决保存图像是负号
#--------------------------第二步 OneHotEncoder()编码--------------------
## 对数据集的标签数据进行编码
train_y = train_df.label
val_y = val_df.label
test_y = test_df.label
print("Label:")
print(train_y[:10])
le = LabelEncoder()
train_y = le.fit_transform(train_y).reshape(-1,1)
val_y = le.transform(val_y).reshape(-1,1)
test_y = le.transform(test_y).reshape(-1,1)
print("LabelEncoder")
print(train_y[:10])
print(len(train_y))
## 对数据集的标签数据进行one-hot编码
ohe = OneHotEncoder()
train_y = ohe.fit_transform(train_y).toarray()
val_y = ohe.transform(val_y).toarray()
test_y = ohe.transform(test_y).toarray()
print("OneHotEncoder:")
print(train_y[:10])
#-----------------------第三步 使用Tokenizer对词组进行编码--------------------
max_words = 6000
max_len = 600
tok = Tokenizer(num_words=max_words) #最大词语数为6000
print(train_df.cutword[:5])
print(type(train_df.cutword))
## 防止语料中存在数字str处理
train_content = [str(a) for a in train_df.cutword.tolist()]
val_content = [str(a) for a in val_df.cutword.tolist()]
test_content = [str(a) for a in test_df.cutword.tolist()]
tok.fit_on_texts(train_content)
print(tok)
## 保存训练好的Tokenizer和导入
with open(tok.pickle, wb) as handle: #saving
pickle.dump(tok, handle, protocol=pickle.HIGHEST_PROTOCOL)
with open(tok.pickle, rb) as handle: #loading
tok = pickle.load(handle)
#---------------------------第四步 数据转化为序列-----------------------------
train_seq = tok.texts_to_sequences(train_content)
val_seq = tok.texts_to_sequences(val_content)
test_seq = tok.texts_to_sequences(test_content)
## 将每个序列调整为相同的长度
train_seq_mat = sequence.pad_sequences(train_seq,maxlen=max_len)
val_seq_mat = sequence.pad_sequences(val_seq,maxlen=max_len)
test_seq_mat = sequence.pad_sequences(test_seq,maxlen=max_len)
print("数据转换序列")
print(train_seq_mat.shape)
print(val_seq_mat.shape)
print(test_seq_mat.shape)
print(train_seq_mat[:2])
#-------------------------------第五步 建立BiLSTM模型--------------------------
num_labels = 4
model = Sequential()
model.add(Embedding(max_words+1, 128, input_length=max_len))
model.add(Bidirectional(CuDNNLSTM(128)))
model.add(Dense(128, activation=relu))
model.add(Dropout(0.3))
model.add(Dense(num_labels, activation=softmax))
model.summary()
model.compile(loss="categorical_crossentropy",
optimizer=adam, # RMSprop()
metrics=["accuracy"])
#-------------------------------第六步 模型训练和预测--------------------------
## 先设置为train训练 再设置为test测试
flag = "train"
if flag == "train":
print("模型训练")
## 模型训练 当val-loss不再提升时停止训练 0.0001
model_fit = model.fit(train_seq_mat, train_y, batch_size=128, epochs=10,
validation_data=(val_seq_mat,val_y),
callbacks=[EarlyStopping(monitor=val_loss,min_delta=0.0001)]
)
model.save(my_model.h5)
del model
elapsed = (time.clock() - start)
print("Time used:", elapsed)
print(model_fit.history)
else:
print("模型预测")
## 导入已经训练好的模型
model = load_model(my_model.h5)
## 对测试集进行预测
test_pre = model.predict(test_seq_mat)
## 评价预测效果,计算混淆矩阵
confm = metrics.confusion_matrix(np.argmax(test_y,axis=1),np.argmax(test_pre,axis=1))
print(confm)
## 混淆矩阵可视化
Labname = ["体育", "文化", "财经", "游戏"]
print(metrics.classification_report(np.argmax(test_y,axis=1),np.argmax(test_pre,axis=1)))
plt.figure(figsize=(8,8))
sns.heatmap(confm.T, square=True, annot=True,
fmt=d, cbar=False, linewidths=.6,
cmap="YlGnBu")
plt.xlabel(True label,size = 14)
plt.ylabel(Predicted label, size = 14)
plt.xticks(np.arange(4)+0.5, Labname, size = 12)
plt.yticks(np.arange(4)+0.5, Labname, size = 12)
plt.savefig(result.png)
plt.show()
#----------------------------------第七 验证算法--------------------------
## 使用tok对验证数据集重新预处理,并使用训练好的模型进行预测
val_seq = tok.texts_to_sequences(val_df.cutword)
## 将每个序列调整为相同的长度
val_seq_mat = sequence.pad_sequences(val_seq,maxlen=max_len)
## 对验证集进行预测
val_pre = model.predict(val_seq_mat)
print(metrics.classification_report(np.argmax(val_y,axis=1),np.argmax(val_pre,axis=1)))
elapsed = (time.clock() - start)
print("Time used:", elapsed)
训练输出模型如下所示,GPU时间还是非常快。
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_1 (Embedding) (None, 600, 128) 768128
_________________________________________________________________
bidirectional_1 (Bidirection (None, 256) 264192
_________________________以上是关于Python深度学习12——Keras实现注意力机制(self-attention)中文的文本情感分类(详细注释)的主要内容,如果未能解决你的问题,请参考以下文章